牛客笔试算法必刷TOP101系列,每日更新中~
1.合并有序链表2023.9.3
合并两个排序的链表_牛客题霸_牛客网 (nowcoder.com)
题意大致为:
将两个链表中的元素按照从小到大的顺序合并成为一个链表.
所给予的条件:
给出的所要合并的链表都是从小到大顺序排列的.
思路:
创建一个新的头节点来方便组装新的链表.分别用两个指针遍历两个链表,比较两个指针所在的节点,较小的节点先一步存放到新链表中,并且相应的指针向后移动一位.
移动后的指针所在的节点再与先前较大的未移动的节点进行比较,循环进行上面的操作.
直到任一链表遍历完毕,再把另一没遍历完的链表剩下的节点连接到新链表的尾巴.
错解:
public ListNode Merge (ListNode pHead1, ListNode pHead2) {// write code hereListNode fakeHead = new ListNode(-1);ListNode cur = fakeHead;while(pHead1.next != null || pHead2.next != null){//我怎么用了或呢!!!//明明是把链表都遍历一遍不要管他nextif(pHead1.val <= pHead2.val){cur.next = pHead1;cur = cur.next;pHead1 = pHead1.next;}else{cur.next = pHead2;cur = cur.next;pHead2 = pHead2.next;}}if(pHead1.next == null){//上面错,下面跟着错了.cur.next = pHead2;}if(pHead2.next == null){cur.next = pHead1;}return fakeHead.next;}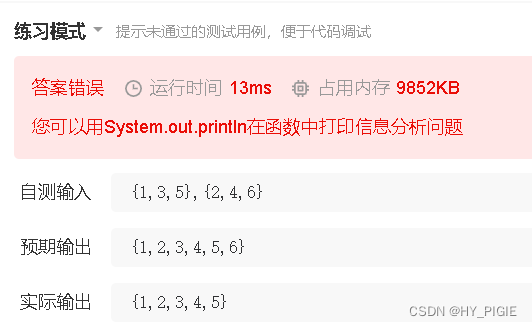
刚开始,可能脑袋真的不好使了.
明明想的是,要把链表都遍历完整一遍,分别拿每一个节点跟另一个链表的节点进行比较.结果while循环中写的却是.next.还想不出问题在哪里真的是罪过.
还有while循环条件中的连接符号居然用的||.
只要有一个链表遍历完了就结束循环,所以要用&&啊啊啊!!!
真的是出师未捷身先死,下面好好加油吧.
正确题解:
起码脑子里的思路是对的,就是想的跟写的对不太上...
import java.util.*;/** public class ListNode {* int val;* ListNode next = null;* public ListNode(int val) {* this.val = val;* }* }*/public class Solution {/*** 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可** * @param pHead1 ListNode类 * @param pHead2 ListNode类 * @return ListNode类*/public ListNode Merge (ListNode pHead1, ListNode pHead2) {// write code hereif(pHead1 == null){return pHead2;}if(pHead2 == null){return pHead1;}ListNode fakeHead = new ListNode(-1);ListNode cur = fakeHead;while(pHead1 != null && pHead2 != null){//这里之前用了||if(pHead1.val <= pHead2.val){cur.next = pHead1;pHead1 = pHead1.next;}else{cur.next = pHead2;pHead2 = pHead2.next;}cur = cur.next;}if(pHead1 == null){cur.next = pHead2;}else{cur.next = pHead1;}return fakeHead.next;}
}2.链表是否有环2023.9.4
判断链表中是否有环_牛客题霸_牛客网 (nowcoder.com)
题意:
判断链表中是否有环,环所指的是:链表中节点的next存放此节点先前节点的地址.
给予的条件:
普通链表一个
思路:
这道题先前有学习过,我学到了两种解法.
①:用快慢指针的方法,快指针的速度是慢指针的两倍.在完全遍历完链表先前,如果快指针与慢指针相遇了,则证明此链表中含有环.反之,证明没有.(闭环追及问题)
②:用HashSet的方法,将链表进行遍历,把遍历到的节点的地址存放到set当中.如果链表有环则必定会有节点重复存放第二次,就可以用contains来判断有没有环.
public static boolean hasCycle(ListNode head) {ListNode fast = head;ListNode slow = head;//因为fast一次走两步,在while循环中就要判断能否有足够的位置够一次走两步//首先要判断fast!=null,看是否遍历完成,如果没有再看其后面有没有节点while(fast != null && fast.next != null){fast = fast.next.next;slow = slow.next;if(slow == fast){return true;}}return false;}3.判断链表中环的入口点
链表中环的入口结点_牛客题霸_牛客网 (nowcoder.com)
思路:首先是要判断链表有没有环,有环才能进行后面的操作
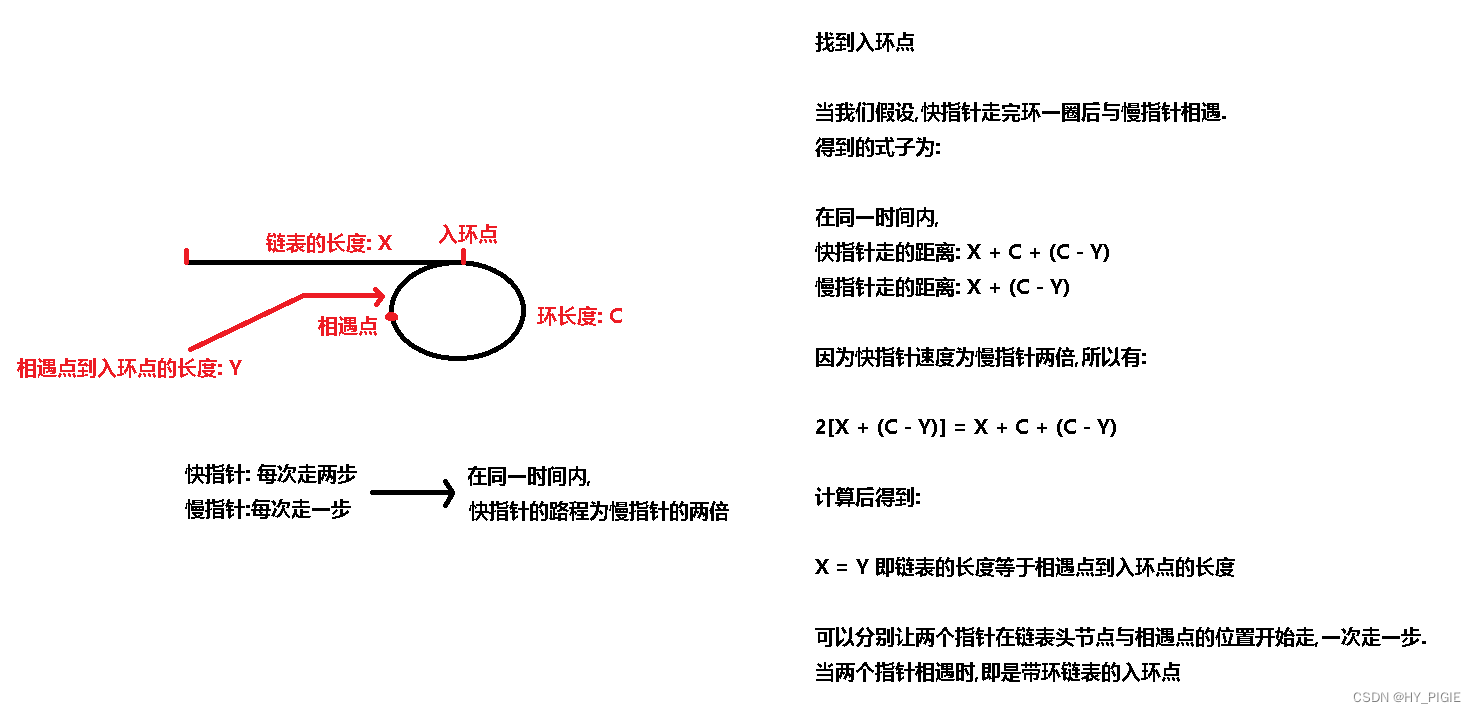
public ListNode EntryNodeOfLoop(ListNode pHead) {ListNode fast = pHead;ListNode slow = pHead;boolean check = false;//首先要判断链表有没有环while(fast != null && fast.next != null){fast = fast.next.next;slow = slow.next;if(fast == slow){check = true;break;}}if(!check){//证明没有环return null;}slow = pHead;while(slow != fast){slow = slow.next;fast = fast.next;}return fast;}4.链表中倒数最后K个节点2023.9.5
链表中倒数最后k个结点_牛客题霸_牛客网 (nowcoder.com)
题意:
根据给出的K,来返回链表中倒数第K个节点及其往后的所有节点.
思路:(有误)
这个题目以前写过了.
用的是快慢指针的方式,倒数第一个与倒数第K个节点之间相差K-1个节点.
所以,可以先让快指针从头节点走k-1步,再让慢指针从头节点开始,与快指针一齐一次走一步,直到快指针到达了末尾节点,此时慢指针所在的节点就是倒数第K个节点.
将慢指针所在的节点返回即可.
纠正:
其实这里的本质是,控制两端的距离,再平行的进行移动.
快指针其实移动k个节点会好一点,
错解:
这里写的是移动k个节点了,跟想的时候不一样.如果是移动k个节点,看的是末尾后一个位置即空节点与倒数第K个节点的位置距离.
例如,倒数第三个节点,与空节点相差的距离是3.即倒数第三个节点要移动3次才能到达空节点的位置.
先判定再移动是为了能预防出现快指针走过头,走到了null,直接返回null却没有返回slow的情况
如果链表长5,求倒数第6个节点的时候,就会出现.
public ListNode FindKthToTail (ListNode pHead, int k) {if(pHead == null){return null;}// write code hereListNode fast = pHead;ListNode slow = pHead;for(int i = 0; i < k; i++){fast = fast.next;if(fast == null){return null;//主要是这里的问题,//因为倒数的k刚好为链表的长度,而fast是从头节点1开始//走到空指针之后就直接返回了//其实应该把if判定条件放到移动指针的上面//而且在外面加一个判断k是否合法的条件//当k小于0或等于0时返回null.}}while(fast != null){//fast要在尾巴节点停下来fast = fast.next;slow = slow.next;}return slow;}正解:
2023.9.7补充一下,for循环里面的if主要是为了防止越界的,证明当前fast指针指向的节点不为空,可以继续往下走.是作为条件而不是判断,所以要放在上面而不是下面.
public ListNode FindKthToTail (ListNode pHead, int k) {if(pHead == null){return null;}// write code hereListNode fast = pHead;ListNode slow = pHead;for(int i = 0; i < k; i++){if(fast == null){return null;}fast = fast.next;}while(fast != null){//fast要在尾巴节点停下来fast = fast.next;slow = slow.next;}return slow;}5.删除链表的倒数第n个节点
删除链表的倒数第n个节点_牛客题霸_牛客网 (nowcoder.com)
嗨呀,这个跟上面一起写的.简单啦,我就不信我会错.
思路(否决):
既然是删除,肯定要找到被删除的节点的前驱与后驱.再将他们连接起来.
找到倒数第n个节点,继续用快慢指针的方式来找.
有一个问题,slow的位置恰好倒数第n个的位置,那么其前驱我们就不能知道了.
所以要找倒数第n个位置的前一个,那么slow与fast之间的距离就会增加一位.变成了fast走n+1
还想到了,可能会删除头节点这种情况,想在fast移动之后加上一个判定条件
思路(第二版):
觉得上面的太麻烦了,还容易出错.因为上面的思路会存在越界的行为.
头节点会变动的题型还是创建一个假的头节点来存放比较好.再加上一个新的指针在slow指针的前一位变动,tmp就是前驱slow是倒数第n个fast是后驱.将tmp与fast连接起来就好了
public ListNode removeNthFromEnd (ListNode head, int n) {// write code hereListNode fast = head;ListNode slow = head;ListNode fakeHead = new ListNode(-1);fakeHead.next = head;ListNode tmp = fakeHead;// if(n <= 0){// return null;// } 写完才看到,题目保证n一定有效for(int i = 0; i < n; i++){if(fast == null){//走过头了return null;}fast = fast.next;}while(fast != null){fast = fast.next;slow = slow.next;tmp = tmp.next;}tmp.next = slow.next;return fakeHead.next;}6.两个链表的第一个公共节点2023.9.6
两个链表的第一个公共结点_牛客题霸_牛客网 (nowcoder.com)
思路:
也是炒冷饭了.想到的是先遍历链表,分别得到他们的长度.
用双指针的方式,对于较长的链表先走两个链表长度差的距离.
再让两个指针分别从链表出发,一次走一步直到null,如果其中两指针相对,则证明有公共节点,
然后还学到了第二个方法.
对比上面的方法的优点是:不用考虑哪一个链表比较长,也不用额外写代码来得到链表的长度.虽然他们的本质都是双指针的方式.
就像下图的一样,直接让两个指针从两个链表的头节点开始一起往下走,任一一个指针遍历完所在的链表后,来到空节点时则会跳转到另一条链表的头节点开始遍历.
观察下面的图我们可以发现,这样就能消除链表长度导致的长度差.
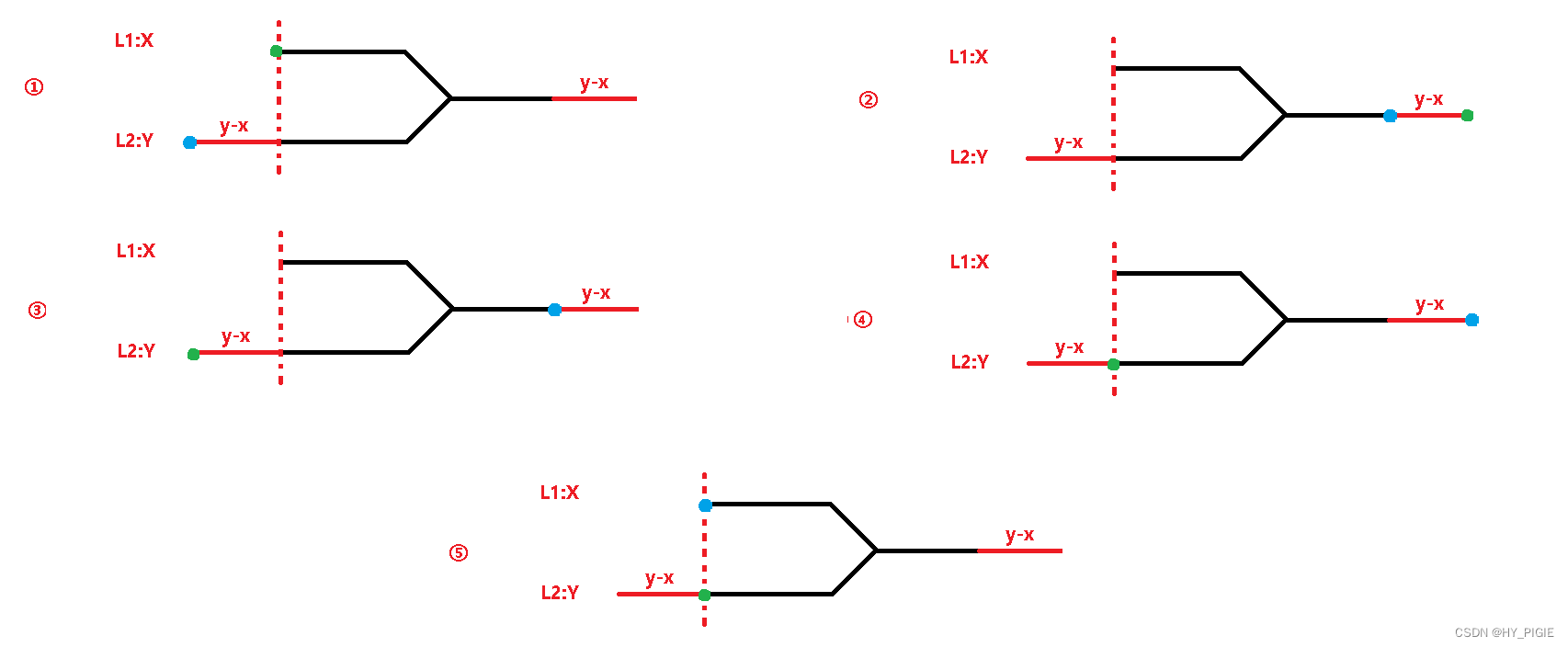
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {ListNode l1 = pHead1;ListNode l2 = pHead2;while(l1 != l2){if(l1 == null){l1 = pHead2;}else{l1 = l1.next;}if(l2 == null){l2 = pHead1;}else{l2 = l2.next;}}return l1;}7.链表相加
链表相加(二)_牛客题霸_牛客网 (nowcoder.com)
思路:
我只能想到把链表都给翻转了才进行后面的操作.
然后创建一个新的头节点,创建新的节点.如果现在相加的节点个位溢出了就要移动到下一位去.
先写写看吧.
错解(愚蠢的错误):
最后一个例子没过去,好可惜.
努力找找看哪里错了吧...我看别人的代码好优雅噢.我的有点不堪.
public ListNode addInList (ListNode head1, ListNode head2) {// write code here//先翻转两个链表head1 = rever(head1);head2 = rever(head2);ListNode fakeHead = new ListNode(-1);//创建两个指针来遍历链表ListNode l1 = head1;ListNode l2 = head2;ListNode cur = fakeHead;//遍历新链表//存储溢出int count = 0;while(l1 != null && l2 != null){int tmp = l1.val + l2.val + count;if(tmp >= 10){tmp -= 10;//溢出了,得留到下一个.count = 1;}else{count = 0;}ListNode node = new ListNode(tmp);cur.next = node;cur = node;l1 = l1.next;l2 = l2.next;}while(l1 != null){int tmp = l1.val + count;if(tmp >= 10){tmp -= 10;count = 1;}else{count = 0;}ListNode node = new ListNode(tmp); cur.next = node;cur = node;l1 = l1.next;}while(l2 != null){int tmp = l2.val + count;if(tmp >= 10){tmp -= 10;count = 1;}else{count = 0;}ListNode node = new ListNode(tmp); cur.next = node;cur = node;l1 = l1.next;//什么东西啊,什么东西啊.对自己无语啦.,把这里改成l2就好了}if(count != 0){ListNode node = new ListNode(count);cur.next = node;cur = node;}return rever(fakeHead.next);}public ListNode rever(ListNode head){ListNode cur = head.next;ListNode pre = head;while(cur != null){ListNode curNext = cur.next;cur.next = pre;pre = cur;cur = curNext;}head.next = null;return pre;}
正解:
在错解里的代码改了.糊涂啊糊涂
8.单链表的排序23.9.7
单链表的排序_牛客题霸_牛客网 (nowcoder.com)
思路(没想到):
一开始我只想到了把链表放到数组里面,在数组中进行排序之后再赋值到链表上.但是感觉不怎么好,又看到了题解里面说的用分治的思想,其实就是归并排序嘛.但是我内心会对递归有一定的抵触心理...但还是认真看了一遍题解,也自己动手画了一遍图.思路是清晰了,但不知道代码写得怎么样.先动手看看吧.
public ListNode sortInList (ListNode head) {// write code here//既然是用归并排序递归的思路://递归首先要考虑的是其结束的条件.//当只剩一个节点或没有节点的时候结束拆链表的递归操作if(head == null || head.next == null){return head;//返回当前节点}//先找到链表的中间点,进行拆.//找中间点用到了快慢指针的思想,再加上一个中间点的前驱节点才能进行拆除ListNode left = head;ListNode mid = head.next;ListNode right = mid.next;while(right != null || right.next != null){//因为要考虑链表节点个数的奇偶情况//奇数个的时候right指针走到尾巴节点就该停下来了,再继续走两步会越界//所以是right.next!=null的情况//偶数个的时候right指针可以走到尾巴节点的后一个空节点//还有就是因为right一次走两步的关系,需要判断能否还有足够的节点left = left.next;mid = mid.next;right = right.next.next;}//走完了,此时mid来到了中间节点的位置,left是mid的前驱节点的位置//别忘了head//此时前半段链表就被head和left所包裹//后半段链表就被mid与right所包裹//就要将他们分开了left.next = null;//继续调用来递归ListNode lhead = sortInList(head);//递归前半段ListNode rhead = sortInList(mid);//递归后半段//将他们进行排序//写一个排序的方法return sort(lhead,rhead);}public ListNode sort(ListNode p1,ListNode p2){//此处用双指针的方式,来分别遍历两个链表//就跟归并排序里的一样了//还要判断谁空了就返回另一半if(p1 == null){return p2;}if(p2 == null){return p1;}//重新创建一个新的链表来存储ListNode cur = new ListNode(-1);while(p1 != null && p2 != null){if(p1.val > p2.val){cur.next = p2;p2 = p2.next;}else{cur.next = p1;p1 = p1.next;}}//如果有剩余的节点没有遍历到,就直接加上去if(p1 != null){cur.next = p1;}else{cur.next = p2;}return cur.next;//最后返回排好序的链表}
正解:
都没有什么大错误,就是有一些逻辑上的不清楚.
也算是对递归这个心魔没那么恐惧了吧...
public ListNode sortInList (ListNode head) {// write code here//既然是用归并排序递归的思路://递归首先要考虑的是其结束的条件.//当只剩一个节点或没有节点的时候结束拆链表的递归操作if(head == null || head.next == null){return head;//返回当前节点}//先找到链表的中间点,进行拆.//找中间点用到了快慢指针的思想,再加上一个中间点的前驱节点才能进行拆除ListNode left = head;ListNode mid = head.next;ListNode right = mid.next;while(right != null && right.next != null){//错误1:调试后发现错误了||//因为要考虑链表节点个数的奇偶情况//奇数个的时候right指针走到尾巴节点就该停下来了,再继续走两步会越界//所以是right.next!=null的情况//偶数个的时候right指针可以走到尾巴节点的后一个空节点//还有就是因为right一次走两步的关系,需要判断能否还有足够的节点left = left.next;mid = mid.next;right = right.next.next;}//走完了,此时mid来到了中间节点的位置,left是mid的前驱节点的位置//别忘了head//此时前半段链表就被head和left所包裹//后半段链表就被mid与right所包裹//就要将他们分开了left.next = null;//继续调用来递归ListNode lhead = sortInList(head);//递归前半段ListNode rhead = sortInList(mid);//递归后半段//将他们进行排序//写一个排序的方法return sort(lhead,rhead);}public ListNode sort(ListNode p1,ListNode p2){//此处用双指针的方式,来分别遍历两个链表//就跟归并排序里的一样了//还要判断谁空了就返回另一半if(p1 == null){return p2;}if(p2 == null){return p1;}//重新创建一个新的链表来存储ListNode head = new ListNode(-1);//补充3:这里忘记加一个遍历的指针了//直接用头节点去接了怪不得返回只有一个节点ListNode cur = head;while(p1 != null && p2 != null){if(p1.val >= p2.val){//补充2 加一个=cur.next = p2;p2 = p2.next;}else{cur.next = p1;p1 = p1.next;}cur = cur.next;//补充1}//如果有剩余的节点没有遍历到,就直接加上去if(p1 != null){cur.next = p1;}else{cur.next = p2;}return head.next;//最后返回排好序的链表}9.判断一个链表是否为回文结构
判断一个链表是否为回文结构_牛客题霸_牛客网 (nowcoder.com)
思路:
找到中间的节点,将后半段链表进行翻转.
用双指针的形式,从开头与中间开始遍历节点.如果两者不一样,则证明为不是回文结构.
错解:
不是很明白出什么问题了,先放到idea调试看看
主要是翻转之后与前半段的链接没有处理好.
我想实现的是指针分别遍历,没有给他们设null,直到他们相遇或者在偶数情况下在相邻的时候结束循环.
错的原因写在相应的注释里了,链表题还是要好好画图啊.还有记得理清一下循环结束的条件,是用||还是&&
public boolean isPail (ListNode head) {// write code here//先用双指针的形式找到中间节点,如果是偶数个节点,就找中间靠右的节点if(head == null || head.next == null){return true;//如果只有一个节点或者为空则}ListNode slow = head;ListNode fast = head;boolean count = true;while(fast != null && fast.next != null){slow = slow.next;fast = fast.next.next;}//此时slow为中间节点//这里本质上还是多此一举了,如果是奇数个直接从中间开始翻转就好了//这里的想法也是想把中间节点与翻转后的末尾进行连接,让两个指针能够相遇//但是顺序错了,而且这样就会太复杂if(fast != null){//证明为奇数个数,中间节点向后走一个ListNode mid = slow;slow = slow.next;slow.next = mid;}//翻转后半段slow = reverse(slow);while(head != slow || head.next != slow){//还要你,我最近怎么老是用错||与&&if(head.val != slow.val){count = false;break;}head = head.next;slow = slow.next;}return count;}public ListNode reverse(ListNode head){ListNode cur = head.next;ListNode pre = head;while(cur != null){ListNode curNext = cur.next;cur.next = pre;pre = cur;cur = curNext;}return pre;}
正解:
还是得自己调试和画图才能写出来,下次加油嗷.
public boolean isPail (ListNode head) {// write code here//先用双指针的形式找到中间节点,如果是偶数个节点,就找中间靠右的节点if(head == null || head.next == null){return true;//如果只有一个节点或者为空则}ListNode slow = head;ListNode fast = head;boolean count = true;while(fast != null && fast.next != null){slow = slow.next;fast = fast.next.next;}//此时slow为中间节点//翻转后半段slow = reverse(slow);//是这里,翻转之后成一个环了,没有给nullwhile(head != slow && head.next != slow){if(head.val != slow.val){count = false;break;}head = head.next;slow = slow.next;}return count;}public ListNode reverse(ListNode head){ListNode cur = head.next;ListNode pre = head;while(cur != null){ListNode curNext = cur.next;cur.next = pre;pre = cur;cur = curNext;}return pre;}