语言模型:从Word Embedding到ELMo
- ELMo原理
- Bi-LM
- 总结
- 参考资料
本文主要介绍一种建立在LSTM基础上的ELMo预训练模型。2013年的Word2Vec及2014年的GloVe的工作中,每个词对应一个vector,对于多义词无能为力。ELMo的工作对于此,提出了一个较好的解决方案。不同于以往的一个词对应一个向量,是固定的。 在ELMo世界里,预训练好的模型不再只是向量对应关系,而是一个训练好的模型。使用时, 将一句话或一段话输入模型,模型会根据上线文来推断每个词对应的词向量。这样做之后明显的好处之一就是对于多义词,可以结合前后语境对多义词进行理解。比如apple,可以根据前后文语境理解为苹果公司或一种水果。可以说,ELMo的提出意味着从词嵌入(Word Embedding)时代进入了语境词嵌入(Contextualized Word-Embedding)时代。
ELMo原理
ELMo来自论文Deep contextualized word representations,它是”Embeddings from Language Models“的简称。从论文题目看,ELMo的核心思想主要体现在深度上下文(Deep Contextualized )上。与静态的词嵌入不同,ELMo除提供临时词嵌入之外,还提供生成这些词嵌入的预训练模型,所以在实际使用时,ELMo可以基于预训练模型,根据实际上下文场景动态调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,自然也就解决了多义词的问题。所以ELMo实现了一个由静态到动态的飞跃。
ELMo的实现主要涉及语言模型,当然,它使用的语言模型有点特别,因为它首先把输入转换为字符级别的Embedding,根据字符级别的Embedding来生成上下文无关的Word Embedding,然后使用双向语言模型(如Bi-LM)生成上下文相关的Word Embedding。
ELMo的整体模型结果如下图所示:

从上图中可以看出,ELMo模型的处理流程可分为如下
-
输入句子
句子维度为 B × W × C B\times W\times C B×W×C,其中B表示批量大小(batch_size),W表示一句话中的单词数num_words,C表示每个单词的最大字符数目(max_characters_per_token),可设置为某个固定值(如50或60)。在一个批量中,语句有长短,可以采用Padding方法对齐。 -
字符编码层
输入语句首先经过一个字符编码层(Char Encoder Layer),ELMo实际是对字符进行编码,它会对每个单词中所有字符进行编码,得到这个单词的表示。输入维度是 B × W × C B\times W\times C B×W×C,经过字符编码层后的数据维度为 B × W × D B\times W\times D B×W×D。这里展开进一步说明:
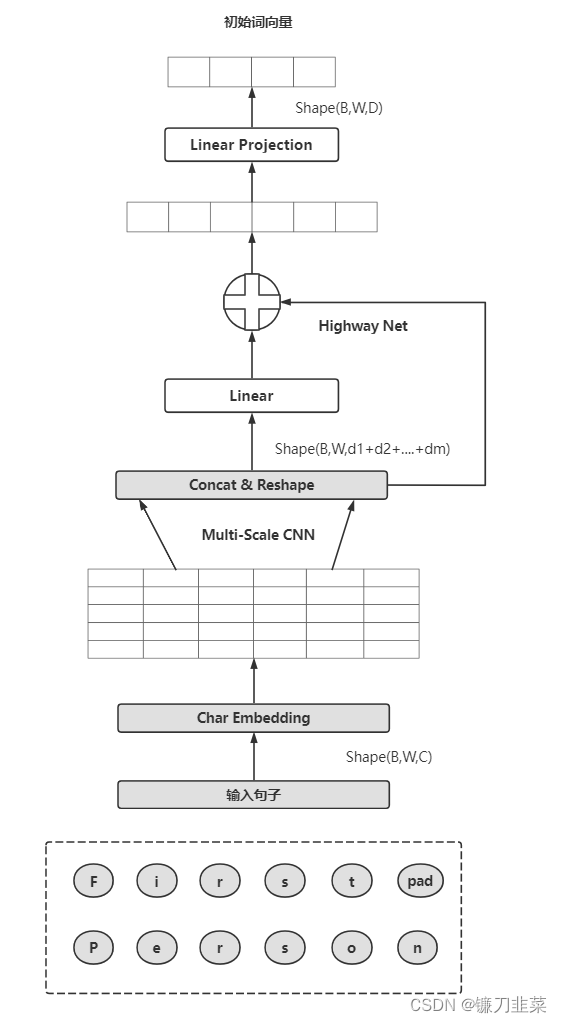
如上图所示:- Char Embedding
对每个字符进行编码,包括一些特殊字符,如单词的开始<bow>、单词的结束<eow>、句子的开始符<bos>、句子的结束符<eos>、单词补齐符<pow>和句子补齐符<pos>等,维度会变为 B ∗ W ∗ C ∗ d B*W*C*d B∗W∗C∗d,这里d表示字符的Embedding维度(char_embed_dim) - Multi-Scale CNN
Char Embedding通过不同规模的一维卷积、池化等作用后,再经过激活层,最后进入拼接和修改状态层(Concat&Reshape) - Concat&Reshape
把卷积后的结果进行拼接,使其形状变为 ( B , W , d 1 + . . . + d m ) (B,W,d1+...+dm) (B,W,d1+...+dm),di表示第i个卷积的通道数 - Highway Net
Highway Net类似残差连接,这里有2个Highway层 - Linear Projection
该层为线性映射层:上一层得到的维度d1+…+dm比较长,经过该层后将维度映射到D,作为词嵌入输入后续的层中,这里输出维度为 B ∗ W ∗ D B*W*D B∗W∗D
- Char Embedding
注意:输入度量是字符而不是词汇,以便模型能捕捉词的内部结构信息。比如beauty和beautiful,即使不了解这两个词的上下文,双向语言模型也能够识别出它们在一定程度上的相关性。
- 双向语言模型
对字符级语句编码后,该句子会经过双向语言模型(Bi-LM),模型内部先分开训练了两个正向和反向的语言模型,而后将其表征进行拼接,最终得到输出维度 ( L + 1 ) ∗ B ∗ W ∗ 2 D (L+1)*B*W*2D (L+1)∗B∗W∗2D,这里+1是加上最初的Embedding层,类似残差连接。
ELMo采用双向语言模型,即同时结合正向和反向的语言模型,其目标是最大化如下的log似然值:
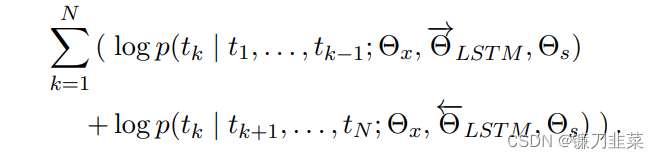

然后,分别训练正向和反向的两个LM,最后把结果拼接起来。词向量层的参数 Θ x \Theta_x Θx和Softmax层参数 Θ \Theta Θ在前向和后向语言模型中是共享的,但LM正向与反向的参数是分开的。如下图所示:
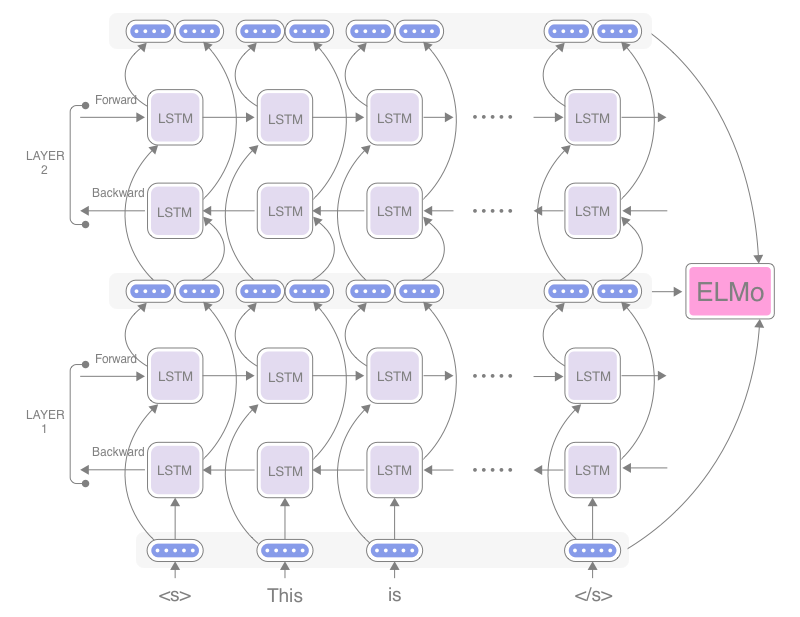
ELMo 利用正向和反向扫描句子计算单词的词向量,并通过级联的方式产生一个中间向量(下面会给出具体的级联方式)。通过这种方式得到的词向量可以捕获到当前句子的结构和该单词的使用方式。
值得注意是,ELMo 使用的 Bi-LM 与 Bi-LSTM 不同,虽然长得相似,但是 Bi-LM 是两个 LM 模型的串联,一个向前,一个向后;而 Bi-LSTM 不仅仅是两个 LSTM 串联,Bi-LSTM 模型中来自两个方向的内部状态在被送到下层时进行级联(注意下图的 out 部分,在 out 中进行级联),而在 Bi-LM 中,两个方向的内部状态仅从两个独立训练的 LM 中进行级联。

- 混合层
得到各层的表征后,会经过一个混合层(Scalar Mixer),它会对前面这些层的表示进行线性融合,得出最终的ELMo向量,维度为 B ∗ W ∗ 2 D B*W*2D B∗W∗2D。·
Bi-LM
设一个序列有N个 token ( t 1 , t 2 , . . . , t N ) (t_1,t_2,...,t_N) (t1,t2,...,tN)(这里说 token 是为了兼容字符和单词,如上文所说,EMLo使用的是字符级别的Embedding)
对于一个前向语言模型来说,是基于先前的序列来预测当前 token: p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , t 2 , . . . , t k − 1 ) p (t_1 ,t_2 ,...,t_N )=\prod_{k=1}^{N}{p( t_k|t_1 ,t_2 ,...,t_{k-1} )} p(t1,t2,...,tN)=k=1∏Np(tk∣t1,t2,...,tk−1)
而对于一个后向语言模型来说,是基于后面的序列来预测当前 token: p ( t 1 , t 2 , . . . , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , t k + 2 , . . . , t N ) p (t_1 ,t_2 ,...,t_N )=\prod_{k=1}^{N}{p( t_k|t_{k+1} ,t_{k+2} ,...,t_{N} )} p(t1,t2,...,tN)=k=1∏Np(tk∣tk+1,tk+2,...,tN)可以用 h k , j → \overrightarrow{h_{k,j}} hk,j 和 h k , j ← \overleftarrow{h_{k,j}} hk,j分别表示前向和后向语言模型。
ELMo 用的是多层双向的 LSTM,所以我们联合前向模型和后向模型给出对数似然估计:
∑ k = 1 N ( log p ( t k ∣ t 1 , . . . , t k − 1 ; Θ x , Θ → L S T M , Θ s ) + log p ( t k ∣ t k + 1 , . . . , t N ; Θ x , Θ ← L S T M , Θ s ) ) \sum_{k=1}^{N}(\log p(t_k | t_1,...,t_{k-1}; \Theta_x, \overrightarrow{\Theta}_{LSTM},\Theta_s) + \log p(t_k | t_{k+1},...,t_{N}; \Theta_x, \overleftarrow{\Theta}_{LSTM},\Theta_s)) k=1∑N(logp(tk∣t1,...,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,...,tN;Θx,ΘLSTM,Θs))其中, Θ x \Theta_x Θx表示 token 的向量, Θ s \Theta_s Θs表示 Softmax 层对的参数, Θ → L S T M \overrightarrow{\Theta}_{LSTM} ΘLSTM和 Θ ← L S T M \overleftarrow{\Theta}_{LSTM} ΘLSTM表示前向和后向的LSTM 的参数。
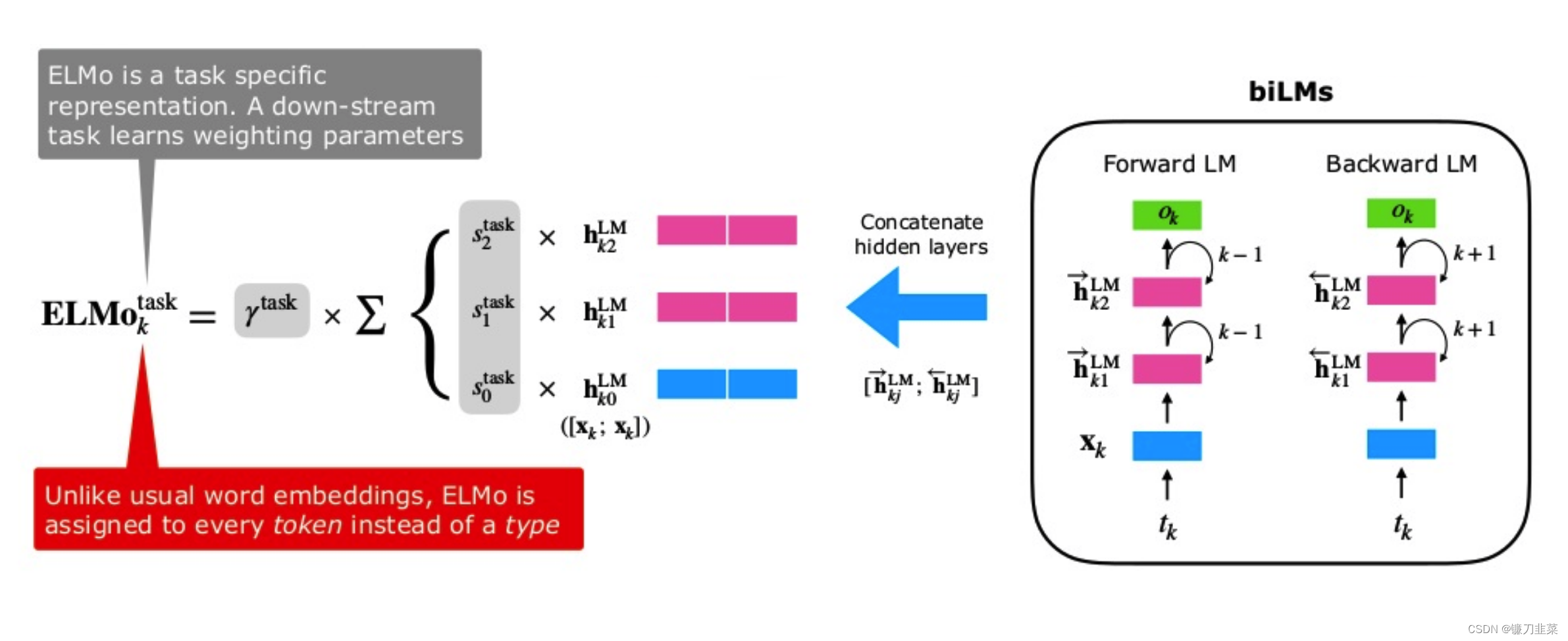
我们刚说 ELMo 通过级联的方式给出中间向量(这边要注意两个地方:一个是级联,一个是中间向量),现在给出符号定义:对每一个 token t k t_k tk来说,一个 L 层的 ELMo 的 2L + 1 个表征: R k = { x k L M , h k , j → , h k , j ← ∣ j = 1 , . . , L } = { h k , j ∣ j = 0 , . . . , L } R_k=\{x_k^{LM},\overrightarrow{h_{k,j}},\overleftarrow{h_{k,j}} | j=1,..,L\} \\ =\{h_{k,j}| j=0,...,L\} Rk={xkLM,hk,j,hk,j∣j=1,..,L}={hk,j∣j=0,...,L}其中, h k , 0 h_{k,0} hk,0表示输入层, h k , j = [ h k , j → ; h k , j ← ] h_{k,j} = [\overrightarrow{h_{k,j}}; \overleftarrow{h_{k,j}}] hk,j=[hk,j;hk,j]。(之所以是 2L + 1 是因为把输入层加了进来)
对于下游任务来说,ELMo 会将所有的表征加权合并为一个中间向量:
E L M o k = E ( R k ; Θ ) = γ ∑ j = 0 L s j h k , j L M ELMo_k=E(R_k;\Theta) = \gamma\sum_{j=0}^{L}s_jh_{k,j}^{LM} ELMok=E(Rk;Θ)=γj=0∑Lsjhk,jLM其中, s s s 是 Softmax 的结果,用作权重; γ \gamma γ 是常量参数,允许模型缩放整个 ELMo 向量,考虑到各个 Bi-LSTM 层分布不同,某些情况下对网络的 Layer Normalization 会有帮助。
总结
ELMo预训练模型采用双向语言模型,该预训练模型能够随着具体语言环境更新词向量表示,即更新对应词的Embedding。当然,由于ELMo采用LSTM架构,因此,模型的并发能力、关注语句的长度等在大的语料库面前,不能完全适用。而且通过拼接(word embedding,Forward hidden state,backward hidden state)方式融合特征的方式,削弱了语言模型特征抽取的能力。
参考资料
- ELMo (Embeddings from Language Models)
- ELMo原理解析及简单上手使用
- Deep contextualized word representations(ELMO词向量理解)