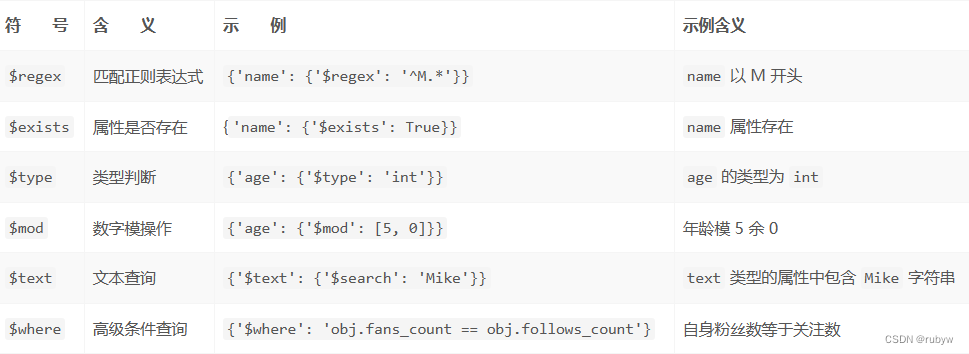
一 Sharding-JDBC介绍

1 背景
随着通信技术的革新,全新领域的应用层出不穷,数据存量随着应用的探索不断增加,数据的存储和计算模式无时无刻不面临着创 新。面向交易、大数据、关联分析、物联网等场景越来越细分,单 一数据库再也无法适用于所有的应用场景。 与此同时,场景内部也愈加细化,相似场景使用不同数据库已成为常态。 由此可见,数据库碎片化的趋势已经不可逆转。
2 ShardingJDBC是什么

Sharding-JDBC是Apache ShardingSphere生态圈中一款开源的分布式数据库第三方组件。ShardingSphere它由Sharding-JDBC、 Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立的产品组成。 它们均提供标准化的数据分片、分布式事务和数据库治理功能,适用于Java同构、异构语言、容器、云原生等各种多样化的应用场景。
Sharding-JDBC定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库, 以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM 框架的使用。
适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
支持任意实现JDBC规范的数据库,目前支持MySQL,Oracle, SQLServer和PostgreSQL。
3 主要功能
- 数据分片分库
分表
读写分离
分片策略
分布式主键
- 分布式事务
标准化的事务接口
XA强一致性事务
柔性事务
- 数据库治理
配置动态化
编排和治理
数据脱敏
可视化链路追踪
4 内部结构

-
图中黄色部分表示的是Sharding-JDBC的入口API,采用工厂方法的形式提供。 目前有 ShardingDataSourceFactory支持分库分表,读写分离操作 MasterSlaveDataSourceFactory支持读写分离操作
-
图中蓝色部分表示的是Sharding-JDBC的配置对象,提供灵活多 变的配置方式。 TableRuleConfiguration,它包含分片配置规则 MasterSlaveRuleConfiguration,它包含的是读写分离的配置规则 ShardingRuleConfuguration,主入口,它包含多个 TableRuleConfiguration,也可以包含多个 MasterSlaveRuleConfiguration
-
图中红色部分表示的是内部对象,由Sharding-JDBC内部使用, 应用开发者无需关注。 Shardingjdbc通过ShardingRuleConfuguration和 MasterSlaveRuleConfiguration生成真正的规则对象,最终生成我们要使用的Datasource。
Sharding-JDBC初始化流程:
根据配置信息生成configuration对象
通过Factory将configuration对象转化成Rule对象
通过Factory将Rule对象与DataSource对象进行封装
使用shardingjdbc进行分库分表操作
5 Sharding-JDBC使用过程
-
引入maven依赖
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbccore</artifactId><version>4.1.1</version> </dependency> -
规则配置
Sharding-JDBC可以通过Java,YAML,Spring命名空间和 Spring Boot Starter四种方式配置,开发者可根据场景选择适合的配置方式。
-
创建DataSource
通过ShardingDataSourceFactory工厂和规则配置对象获取 ShardingDataSource,然后即可通过DataSource选择使用原生 JDBC开发,或者使用JPA, MyBatis等ORM工具。
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, props);
二 数据分片剖析实战

1 核心概念
-
真实表
数据库中真实存在的物理表。例如b_order0、b_order1
-
逻辑表
在分片之后,同一类表结构的名称(总称)。例如b_order。
-
数据节点
在分片之后,由数据源和数据表组成。例如ds0.b_order1
-
绑定表
指的是分片规则一致的关系表(主表、子表),例如b_order和b_order_item,均按照 order_id分片,则此两个表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联, 可以提升关联查询效率。
b_order:b_order0,b_order1 b_order_item: b_order_item0,b_order_item1没有配置绑定关系,采用笛卡尔积关联查询4条sql语句
select * from b_order0 o left join b_order_item0 i on o.order_id = i.order_id where o.order_id in(10,11) select * from b_order0 o left join b_order_item1 i on o.order_id = i.order_id where o.order_id in(10,11) select * from b_order1 o left join b_order_item0 i on o.order_id = i.order_id where o.order_id in(10,11) select * from b_order1 o left join b_order_item1 i on o.order_id = i.order_id where o.order_id in(10,11)配置了绑定关系,只需要查2条sql语句
select * from b_order0 o left join b_order_item0 i on o.order_id = i.order_id where o.order_id in(10,11) select * from b_order1 o left join b_order_item1 i on o.order_id = i.order_id where o.order_id in(10,11) -
广播表
在使用中,有些表没必要做分片,例如字典表、省份信息等,因为他们数据量不大,而且这种表可能需要与海量数据的表进行关联查询。广播表会在不同的数据节点上进行存储,存储的表结构和数据完全相同。
2 数据分片流程解析

SQL解析
分为词法解析和语法解析。 先通过词法解析器将SQL拆分为一个个不可再分的单词。再使用语法解析器对SQL进行理解,并最终提炼出解析上下文。
Sharding-JDBC采用不同的解析器对SQL进行解析,解析器类型如下:
Mysql解析器
Oracle解析器
SQLSERVER解析器
PostgreSql解析器
默认解析器 sql-92标准
查询优化
负责合并和优化分片条件,如OR等。
SQL路由
根据解析上下文匹配用户配置的分片策略,并生成路由路径。目前支持分片路由和广播路由。
SQL改写
将SQL改写为在真实数据库中可以正确执行的语句。SQL改写分为 正确性改写和优化改写。
SQL执行
通过多线程执行器异步执行SQL。
结果归并
将多个执行结果集归并以便于通过统一的JDBC接口输出。结果归并 包括流式归并、内存归并和使用装饰者模式的追加归并这几种方式。
3 SQL使用规范
兼容全部常用的路由至单数据节点的SQL; 路由至多数据节点的SQL由于场景复杂,分为稳定支持、实验性支持和不支持这三种情况
-
稳定支持
全面支持 DQL、DML、DDL、DCL、TCL 和常用 DAL。 支持分 页、去重、排序、分组、聚合、表关联等复杂查询。
常规查询:
SELECT 主语句
SELECT select_expr [, select_expr ...] FROM table_reference [, table_reference ...] [WHERE predicates] [GROUP BY {col_name | position} [ASC | DESC], ...] [ORDER BY {col_name | position} [ASC | DESC], ...] [LIMIT {[offset,] row_count | row_count OFFSET offset}]select_expr
* | [DISTINCT] COLUMN_NAME [AS] [alias] | (MAX | MIN | SUM | AVG)(COLUMN_NAME | alias) [AS] [alias] | COUNT(* | COLUMN_NAME | alias) [AS] [alias]table_reference
tbl_name [AS] alias] [index_hint_list] | table_reference ([INNER] | {LEFT|RIGHT} [OUTER]) JOIN table_factor [JOIN ON conditional_expr | USING (column_list)]子查询:
子查询和外层查询同时指定分片键,且分片键的值保持一致时,由内核提供稳定支持。
SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id = 1; -
实验性支持
实验性支持特指使用 Federation 执行引擎提供支持。 该引擎处 于快速开发中,用户虽基本可用,但仍需大量优化,是实验性产品。
子查询:
子查询和外层查询未同时指定分片键,或分片键的值不一致时, 由 Federation 执行引擎提供支持,例如:
SELECT * FROM (SELECT * FROM t_order) o; SELECT * FROM (SELECT * FROM t_order) o WHERE o.order_id = 1; SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o; SELECT * FROM (SELECT * FROM t_order WHERE order_id = 1) o WHERE o.order_id = 2;跨库关联查询:
当关联查询中的多个表分布在不同的数据库实例上时,由 Federation 执行引擎提供支持。 假设 t_order 和 t_order_item 是多数据节点的分片表,并且未配置绑定表规则,t_user和 t_user_role是分布在不同的数据库实例上的单表,那么 Federation 执行引擎能够支持如下常用的关联查询。
SELECT * FROM t_order o INNER JOIN t_order_item i ON o.order_id = i.order_id WHERE o.order_id = 1; SELECT * FROM t_order o INNER JOIN t_user u ON o.user_id = u.user_id WHERE o.user_id = 1; SELECT * FROM t_order o LEFT JOIN t_user_role r ON o.user_id = r.user_id WHERE o.user_id = 1; SELECT * FROM t_order_item i LEFT JOIN t_user u ON i.user_id = u.user_id WHERE i.user_id = 1; SELECT * FROM t_order_item i RIGHT JOIN t_user_role r ON i.user_id = r.user_id WHERE i.user_id = 1; SELECT * FROM t_user u RIGHT JOIN t_user_role r ON u.user_id = r.user_id WHERE u.user_id = 1; -
不支持
以下 CASE WHEN 语句不支持:
CASE WHEN 中包含子查询
CASE WHEN 中使用逻辑表名(请使用表别名)
不支持的 SQL 原因 解决方案 INSERT INTO tbl_name (col1, col2, …) SELECT * FROM tbl_name WHERE col3 = ? SELECT 子句不支持 * 和内置 分布式主键生成器 无 REPLACE INTO tbl_name (col1, col2, …) SELECT * FROM tbl_name WHERE col3 = ? SELECT 子句不支持 * 和内置 分布式主键生成器 无 SELECT MAX(tbl_name.col1) FROM tbl_name 查询列是函数表达式时,查询 列前不能使用表名 使用 表别 名
4 行表达式(Inline)

Inline是可以简化数据节点和分片算法配置信息,主要是解决配置简化、配置一体化。
-
inline 表达式说明
${begin…end} 表示范围区间,${[unit1, unit2, unitX]} 表示枚举 值。inline 表达式中连续多个 ${⋯} 表达式,整个 inline 最终的 结果将会根据每个子表达式的结果进行笛卡尔组合,例如正式表 inline 表达式如下:
dbtbl_${['online', 'offline']}_${1..3} dbtbl_$->{['online','offline']}_$->{1..3}最终会解析为 dbtbl_online_1,dbtbl_online_2, dbtbl_online_3,dbtbl_offline_1,dbtbl_offline_2和 dbtbl_offline_3 这 6 张表。
-
数据节点配置
字符串中使用 ${} 来嵌入 groovy 代码,下面的表达式中 data_source_ 是字符串前缀,id % 2 + 1 是 groovy 代码。
data_source_${id % 2 + 1}结果为:data_source_1、data_source_2
-
db0,db1,每个库下面都有order0,order1两张表,行表达式配置如下
db${0..1}.order${0..1}db0下面有order0,order1两张表,db1下面有 order2,order3,order4四张表,配置如下
db0.order${0..1},db1.order${2..4}
5 案例
1 SpringBoot+MP环境搭建
- 新建数据库itbaizhan1,itbaizhan2,分别在两个数据库中分别创建表
CREATE TABLE `position` (`id` bigint(11) NOT NULL AUTO_INCREMENT,`name` varchar(256) DEFAULT NULL,`salary` varchar(50) DEFAULT NULL,`city` varchar(256) DEFAULT NULL,PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- 整合SpringBoot与mybatis-plus

创建SpringBoot项目,添加MyBatisPlus起步依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.11</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.lxx</groupId><artifactId>sharding-jdbc-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>sharding-jdbc-demo</name><description>sharding-jdbc-demo</description><properties><java.version>11</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- MyBatisPlus --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.0</version></dependency><!-- mysql驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.48</version></dependency><!-- lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>在SpringBoot配置文件中配置数据源
# 数据源
spring:datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/itbaizhan1?characterEncoding=utf-8username: rootpassword: 123456# mybatis-plus配置
mybatis-plus:# 映射文件位置mapper-locations: com/lxx/mapper/*Mapper.xml# 别名type-aliases-package: com.lxx.pojo# 配置文件开启SQL日志打印configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
编写实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("position")
@Builder
public class Position {@TableId(value = "id", type = IdType.AUTO)private Long id;@TableField("name")private String name;@TableField("salary")private String salary;@TableField("city")private String city;
}
编写Mapper接口,继承BaseMapper
public interface PositionMapper extends BaseMapper<Position> {List<Position> findAll();
}
编写Mapper映射文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mappernamespace="com.lxx.mapper.PositionMapper"><select id="findAll" resultType="position">select id, name, salary, cityfrom position</select>
</mapper>在 SpringBoot启动类中添加 @MapperScan 注解,扫描Mapper文件夹
@SpringBootApplication
@MapperScan("com.lxx.mapper")
public class ShardingJdbcDemoApplication {public static void main(String[] args) {SpringApplication.run(ShardingJdbcDemoApplication.class, args);}}
测试Mapper方法
// 测试类注解,可以在运行测试代码时加载Spring容器
@SpringBootTest
public class PositionMapperTest {@Autowiredprivate PositionMapper positionMapper;//Mapper映射文件中自定义的查询方法@Testpublic void testFindAll() {positionMapper.findAll().stream().forEach(System.out::println);}//MP内置查询方法@Testpublic void testFindById() {Position position = positionMapper.selectById(1);System.out.println(position);}}
2 Sharding-JDBC分库实战
- 新建数据库itbaizhan1,itbaizhan2,分别在两个数据库中创建表
CREATE TABLE `position` (`id` bigint(11) NOT NULL AUTO_INCREMENT,`name` varchar(256) DEFAULT NULL,`salary` varchar(50) DEFAULT NULL,`city` varchar(256) DEFAULT NULL,PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `position_detail` (`id` bigint(11) NOT NULL AUTO_INCREMENT,`pid` bigint(11) NOT NULL DEFAULT '0',`description` text DEFAULT NULL,PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;CREATE TABLE `city` (`id` bigint(11) NOT NULL AUTO_INCREMENT,`name` varchar(256) DEFAULT NULL,`province` varchar(256) DEFAULT NULL,PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.11</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.lxx</groupId><artifactId>sharding-jdbc-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>sharding-jdbc-demo</name><description>sharding-jdbc-demo</description><properties><java.version>11</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency><!-- MyBatisPlus --><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.5.0</version></dependency><!-- mysql驱动 --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.48</version></dependency><!-- lombok --><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><!-- sharding-jdbc --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.0</version></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>- pojo实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("position")
@Builder
public class Position {@TableId(value = "id", type = IdType.AUTO)private Long id;@TableField("name")private String name;@TableField("salary")private String salary;@TableField("city")private String city;//一对一关联private PositionDetail positionDetail;
}@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("position_detail")
@Builder
public class PositionDetail {@TableId(value = "id", type = IdType.AUTO)private Long id;@TableField("pid")private Long pid;@TableField("description")private String description;
}@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("city")
@Builder
public class City {@TableId(value = "id", type = IdType.AUTO)private Long id;@TableField("name")private String name;@TableField("province")private String province;
}
- 编写Mapper接口
public interface PositionMapper extends BaseMapper<Position> {List<Position> findAll();Position findPositionById(Long id);
}public interface PositionDetailMapper extends BaseMapper<PositionDetail> {
}public interface CityMapper extends BaseMapper<City> {
}
- 编写Mapper映射文件
com/lxx/mapper/PositionMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.lxx.mapper.PositionMapper"><select id="findAll" resultType="position">select id, name, salary, cityfrom position</select><resultMap id="positionMap" type="com.lxx.pojo.Position"><!-- 主键列 --><id property="id" column="pid"></id><!-- 普通列 --><result property="name" column="name"></result><result property="salary" column="salary"></result><result property="city" column="city"></result><!-- 一对一对象列 property:属性名 column:关联列名 javaType:对象类型--><association property="positionDetail" column="pid" javaType="com.lxx.pojo.PositionDetail"><!-- 关联对象主键列 --><id property="id" column="pdid"></id><!-- 关联对象普通列 --><result property="pid" column="pid"></result><result property="description" column="description"></result></association></resultMap><select id="findPositionById" resultMap="positionMap" parameterType="long">select p.id pid, p.name, p.salary, p.city, pd.id pdid, pd.descriptionfrom position pleft join position_detail pdon p.id = pd.pidwhere p.id = #{id};</select></mapper>- SpringBoot启动类
@SpringBootApplication
@MapperScan("com.lxx.mapper")
public class ShardingJdbcDemoApplication {public static void main(String[] args) {SpringApplication.run(ShardingJdbcDemoApplication.class, args);}}
- SpringBoot配置文件
src/main/resources/application.yaml
spring:profiles:# 配置激活sharding-jdbc配置文件active: sharding-databaseshardingsphere:props:sql:show: true# mybatis-plus配置
mybatis-plus:# 映射文件位置mapper-locations: com/lxx/mapper/*Mapper.xml# 别名type-aliases-package: com.lxx.pojo# 配置文件开启SQL日志打印configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplsrc/main/resources/application-sharding-database.yaml
# 数据源
spring:shardingsphere:# 配置数据源,给数据源起名ds0,ds1...此处可配置多数据源datasource:names: ds0,ds1# 数据源ds0ds0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/itbaizhan1?characterEncoding=utf-8username: rootpassword: 123456# 数据源ds1ds1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/itbaizhan2?characterEncoding=utf-8username: rootpassword: 123456sharding:# 表策略配置tables:# position是逻辑表position:# 分库策略配置database-strategy:inline:# 根据哪列分表(分片键)sharding-column: id# 分表算法(分片表达式)# 例如:id为奇数,则为ds1;id为偶数,则为ds0;algorithm-expression: ds$->{id%2}# 主键生成器key-generator:# 指定生成的主键列column: id# 指定生成主键的算法(雪花片算法)type: SNOWFLAKEposition_detail:database-strategy:inline:sharding-column: pidalgorithm-expression: ds$->{pid%2}key-generator:column: idtype: SNOWFLAKEcity:key-generator:column: idtype: SNOWFLAKE# 配置广播表broadcast-tables: city- 测试
@SpringBootTest
public class MapperTest {@Autowiredprivate PositionMapper positionMapper;@Autowiredprivate PositionDetailMapper positionDetailMapper;@AutowiredCityMapper cityMapper;//测试position表的分库效果@Testpublic void testAdd() {for (int i = 0; i < 20; i++) {Position position = Position.builder().name("lxx" + i).city("昆明").salary("20000").build();System.out.println(position);positionMapper.insert(position);}}//测试position表与其子表position_detail的分库效果@Testpublic void testAdd2() {for (int i = 0; i < 20; i++) {Position position = Position.builder().name("lxx" + i).city("昆明").salary("20000").build();positionMapper.insert(position);PositionDetail positionDetail = PositionDetail.builder().pid(position.getId()).description("this is desc " + i).build();positionDetailMapper.insert(positionDetail);}}//测试手写的一对一联合查询方法@Testpublic void testFindPositionById() {Position position = positionMapper.findPositionById(856565814726230017L);System.out.println(position);}//测试city广播表@Testpublic void testBroadCast() {City city = City.builder().name("昆明").province("嵩明").build();cityMapper.insert(city);}}三 读写分离剖析实战

1 读写分离概念
读写分离是通过主从的配置方式,将查询请求均匀的分散到多个数据副本,进一步的提升系统的处理能力。

主库:添加、更新以及删除数据操作所使用的数据库
从库:查询数据操作所使用的数据库
主从架构:读写分离,目的是高可用、读写扩展。主从库内容相同,根据SQL语义进行路由。
分库分表架构:数据分片,目的读写扩展、存储扩容,库和表内容不同,根据分片配置进行路由。
将水平分片和读写分离联合使用,能够更加有效的提升系统性能, 下图展现了将分库分表与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系。

读写分离虽然可以提升系统的吞吐量和可用性,但同时也带来了数据不一致的问题,包括多个主库之间的数据一致性,以及主库与从库之间的数据一致性的问题。 并且,读写分离也带来了与数据分片同样的问题,它同样会使得应用开发和运维人员对数据库的操作和运维变得更加复杂。
2 读写分离配置
首先拉取Docker镜像
docker pull mysql:5.7
启动两个容器
#启动Master
docker run -p 3350:3306 --name master -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
#启动Slave
docker run -p 3340:3306 --name slave -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7配置Master
进入master容器内部
docker exec -it master /bin/bash
修改mysqld.cnf配置
#切换目录
vim /etc/mysql/mysql.conf.d/mysqld.cnf
#修改配置文件加入
[mysqld]
## 同一局域网内注意要唯一
server-id=100
## 开启二进制日志功能,可以随便取(关键)
log-bin=mysql-bin
重启mysql服务
service mysql restart
docker start master
在Master数据库创建数据同步用户
mysql> GRANT replication SLAVE ON *.* TO 'slave' @'%' IDENTIFIED BY '123456';
配置Slave
和配置Master(主)一样,在Slave配置文件mysqld.cnf中添加如下配置
#切换目录
vim /etc/mysql/mysql.conf.d/mysqld.cnf
[mysqld]
## 设置server_id,注意要唯一
server-id=101
## 开启二进制日志功能,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
连接接Master(主)和Slave(从)
在Master进入mysql
show master status;
目的是查看File和Position
在Slave 中进入 mysql
mysql>change master to master_host='172.17.0.2',master_user='slave',master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=443;
在Slave中开启主从复制
mysql> start slave;
在 Slave 的 MySQL 终端执行查看主从同步状态
show slave status \G;
查看Slave_IO_Running和Slave_SQL_Running都为yes则主从复制配置完成。
3 读写分离方案剖析
- 分库+读写分离
在数据量不多的情况下,我们可以将数据库进行读写分离,以应 对高并发的需求,通过水平扩展从库,来缓解查询的压力。

- 分表+读写分离
在数据量达到500万的时候,这时数据量预估千万级别,我们可以将数据进行分表存储。

- 分库分表+读写分离
在数据量继续扩大,这时可以考虑分库分表,将数据存储在不同数据库的不同表中

透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库集群,是ShardingSphere读写分离模块的主要设计目标。
核心功能
提供一主多从的读写分离配置。仅支持单主库,可以支持独立使 用,也可以配合分库分表使用
独立使用读写分离,支持SQL透传。不需要SQL改写流程
同一线程且同一数据库连接内,能保证数据一致性。如果有写入 操作,后续的读操作均从主库读取。
基于Hint的强制主库路由。可以强制路由走主库查询实时数据, 避免主从同步数据延迟。
不支持项
主库和从库的数据同步
主库和从库的数据同步延迟
主库双写或多写
跨主库和从库之间的事务的数据不一致。建议在主从架构中,事务中的读写均用主库操作。
4 案例
- 在配置了主从复制的数据库中创建city表
CREATE TABLE `city` (`id` bigint(11) NOT NULL AUTO_INCREMENT,`name` varchar(256) DEFAULT NULL,`province` varchar(256) DEFAULT NULL,PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- SpringBoot配置文件
src/main/resources/application.yaml
spring:profiles:# 激活配置文件active: master-slaveshardingsphere:props:sql:show: true# mybatis-plus配置
mybatis-plus:# 映射文件位置mapper-locations: com/lxx/mapper/*Mapper.xml# 别名type-aliases-package: com.lxx.pojo# 配置文件开启SQL日志打印configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplsrc/main/resources/application-master-slave.yaml
# 数据源
spring:shardingsphere:datasource:names: master,slavemaster:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.66.113:3350/test?serverTimezone=GMT%2b8&characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456slave:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://192.168.66.113:3340/test?serverTimezone=GMT%2b8&characterEncoding=UTF-8&useSSL=falseusername: rootpassword: 123456# master-slavemasterslave:#集群名字name: ms# 主数据库名字,对应第一行的配置master-data-source-name: master# 多个从数据名字,逗号分隔slave-data-source-names: slave# 负载均衡load-balance-algorithm-type: ROUND_ROBINsharding:tables:city:key-generator:column: idtype: SNOWFLAKE
- 测试
@Testpublic void testAddCity() {City city = City.builder().name("昆明").province("嵩明").build();cityMapper.insert(city);}@Testpublic void findCity() {List<Object> objects = cityMapper.selectObjs(null);objects.stream().forEach(System.out::println);}
四 强制路由剖析实战

在一些应用场景中,分片条件并不存在于SQL,而存在于外部业务逻辑。因此需要提供一种通过在外部业务代码中指定路由配置的一 种方式,在ShardingSphere中叫做Hint。如果使用hint强制路由, 那么sql将无视原有的分片逻辑,直接将路由到指定的数据节点上操作。
1 应用场景
Hint使用场景:
数据分片操作,如果分片键没有在SQL或数据表中,而是在业务逻辑代码中;
读写分离操作,如果强制在主库进行某些数据操作;
2 应用过程
- 编写分库或分表路由策略,实现HintShardingAlgorithm接口
public class MyHintShardingAlgorithm implements
HintShardingAlgorithm<Integer> {@Overridepublic Collection<String>
doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {//添加分库或分表路由逻辑}
}
- 在配置文件指定分库或分表策略
#强制路由库
spring.shardingsphere.sharding.tables.t_user.database-strategy.hint.algorithm-classname=com.lxx.hint.MyHintShardingAlgorithm
#强制路由库和表
spring.shardingsphere.sharding.tables.b_order.database-strategy.hint.algorithm-classname=com.lxx.hint.MyHintShardingAlgorithm
spring.shardingsphere.sharding.tables.b_order.table-strategy.hint.algorithm-classname=com.lxx.hint.MyHintShardingAlgorithm
spring.shardingsphere.sharding.tables.b_order.actual-data-nodes=ds$->{0..1}.b_order$->{0..1}
- 在代码执行查询前使用HintManager指定执行策略值
@Test//路由库和表
public void test(){HintManager hintManager = HintManager.getInstance();hintManager.addDatabaseShardingValue("b_order",1);hintManager.addTableShardingValue("b_order",1);List<Order> list = orderRepository.findAll();hintManager.close();list.forEach(o -> {System.out.println(o.getOrderId()+""+o.getUserId()+" "+o.getOrderPrice());});
}
在读写分离结构中,为了避免主从同步数据延迟及时获取刚添加或更新的数据,可以采用强制路由走主库查询实时数据,使用 hintManager.setMasterRouteOnly设置主库路由即可。
3 案例
- SpringBoot配置文件
src/main/resources/application.yaml
spring:profiles:# 激活配置文件active: hint-databaseshardingsphere:props:sql:show: true# mybatis-plus配置
mybatis-plus:# 映射文件位置mapper-locations: com/lxx/mapper/*Mapper.xml# 别名type-aliases-package: com.lxx.pojo# 配置文件开启SQL日志打印configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplsrc/main/resources/application-hint-database.yaml
spring:shardingsphere:datasource:names: ds0,ds1ds0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/itbaizhan1?characterEncoding=utf-8username: rootpassword: 123456ds1:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/itbaizhan2?characterEncoding=utf-8username: rootpassword: 123456sharding:tables:city:database-strategy:hint:algorithm-class-name: com.lxx.hint.MyHintShardingAlgorithm
- MyHintShardingAlgorithm
public class MyHintShardingAlgorithm implements HintShardingAlgorithm<Integer> {@Overridepublic Collection<String> doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {ArrayList<String> result = new ArrayList<>();// collection => ds0,ds1for (String each : collection) {// hintShardingValue.getValues() => 分片键for (Integer value : hintShardingValue.getValues()) {if (each.endsWith(String.valueOf(value % 2))) {result.add(each);}}}return result;}
}- 测试
@SpringBootTest
public class HintTest {@AutowiredCityMapper cityMapper;@Testpublic void testHint() {HintManager hintManager = HintManager.getInstance();hintManager.setDatabaseShardingValue(1); //强制路由到ds$->{id%2}List<City> cities = cityMapper.selectList(null);cities.stream().forEach(System.out::println);}}
五 数据脱敏剖析实战
数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现 敏感隐私数据的可靠保护。涉及客户安全数据或者一些商业性敏感数据,如身份证号、手机号、卡号、客户号等个人信息按照规定, 都需要进行数据脱敏。数据脱敏模块属于ShardingSphere分布式治理这一核心功能下的子功能模块功能。
- 在更新操作时,它通过对用户输入的SQL进行解析,并依据用户提供的脱敏配置对SQL进行改写, 从而实现对原文数据进行加密,并将密文数据存储到底层数据库。
- 在查询数据时,它又从数据库中取出密文数据并对其解密,最终将解密后的原始数据返回给用户。
1 整体架构

Encrypt-JDBC将用户发起的SQL进行拦截,并通过SQL语法解析器进行解析、理解SQL行为,再依据用户传入的脱敏规则,找出需要脱敏的字段和所使用的加解密器对目标字段进行加解密处理后,再与底层数据库进行交互。
2 脱敏规则
脱敏配置主要分为四部分:数据源配置,加密器配置,脱敏表配置以及查询属性配置,其详情如下图所示:

- 数据源配置:指数据源配置。
- 加密算法配置:指使用什么加密算法进行加解密。目前ShardingSphere内置了三种加解密算法: AES,MD5 和 RC4。用户还可以通过实现ShardingSphere提供的接口,自行实现一套加解密算法。
- 脱敏表配置:用于告诉ShardingSphere数据表里哪个列用于存储密文数据(cipherColumn)、哪 个列用于存储明文数据(plainColumn)以及用户想使用哪个列进行SQL编写(logicColumn)。
3 脱敏处理流程
举例说明,假如数据库里有一张表叫做 t_user,这张表里有两个字 段 pwd_plain,用于存放明文数据、pwd_cipher,用于存放密文数 据,同时定义 logicColumn为 pwd。 那么,用户在编写 SQL 时应该面向 logicColumn 进行编写,即 INSERT INTO t_user SET pwd = ‘123’。 Apache ShardingSphere 接收到该SQL,通过用户提供的加密配置,发现 pwd是 logicColumn,于是便对逻辑列及其对应的明文数据进行加密处理。 Apache ShardingSphere 将面向用户的逻辑列与面向底层数据库的明文列和密文列进行了列名以及数据的加密映射转换。 如下图所示:

即依据用户提供的加密规则,将用户 SQL 与底层数据表结构割裂开来,使得用户的 SQL 编写不再依赖于真实的数据库表结构。 而用户与底层数据库之间的衔接、映射、转换交由 Apache ShardingSphere 进行处理。
下方图片展示了使用加密模块进行增删改查时,其中的处理流程和转换逻辑,如下图所示,

4 加密策略
ShardingSphere提供了两种加密策略用于数据脱敏,该两种策略分 别对应ShardingSphere的两种加解密的接口,即Encryptor和 QueryAssistedEncryptor。
一方面,Apache ShardingSphere 为用户提供了内置的加解密实现类,用户只需进行配置即可使用; 另一方面,为了满足用户不同场景的需求,我们还开放了相关加解密接口,用户可依据这两种类型的接口提供具体实现类。 再进行简单配置,即可让 Apache ShardingSphere 调用用户自定义的加解密方案进行数据加密。
5 案例
- 在数据库itbaizhan1中创建表c_user
CREATE TABLE `c_user` (`Id` bigint(11) NOT NULL AUTO_INCREMENT,`name` varchar(256) DEFAULT NULL,`pwd_plain` varchar(256) DEFAULT NULL,`pwd_cipher` varchar(256) DEFAULT NULL,PRIMARY KEY (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
- CUser实体类
@Data
@NoArgsConstructor
@AllArgsConstructor
@TableName("c_user")
@Builder
public class CUser {@TableId(value = "id", type = IdType.AUTO)private Long id;@TableField("name")private String name;@TableField("pwd") //逻辑名private String pwd;
}
- 编写持久层接口
public interface CUserMapper extends BaseMapper<CUser> {}
- 编写配置文件
src/main/resources/application.yaml
spring:profiles:# 激活配置文件active: encrypt-databaseshardingsphere:props:sql:show: true #是否开启SQL显示,默认值: false# mybatis-plus配置
mybatis-plus:# 映射文件位置mapper-locations: com/lxx/mapper/*Mapper.xml# 别名type-aliases-package: com.lxx.pojo# 配置文件开启SQL日志打印configuration:log-impl: org.apache.ibatis.logging.stdout.StdOutImplsrc/main/resources/application-encrypt-database.yaml
spring:shardingsphere:datasource:names: ds0ds0:type: com.zaxxer.hikari.HikariDataSourcedriver-class-name: com.mysql.jdbc.Driverjdbc-url: jdbc:mysql://localhost:3306/itbaizhan1?characterEncoding=utf-8username: rootpassword: 123456encrypt:tables:c_user:columns:pwd:plain-column: pwd_plain #存储明文的字段cipher-column: pwd_cipher #存储密文的字段encryptor: my_pwd #使用的加密器encryptors:my_pwd:type: aes #加解密器类型,可自定义或选择内置类型:MD5/AESprops:aes.key.value: 1234 #属性配置, 注意:使用AES加密器,需要配置AES加密器的KEY属性:aes.key.valuesharding:tables:c_user:key-generator:column: idtype: SNOWFLAKEprops:query:with:cipher:column: true #是否使用密文列查询(默认为true)# true => Actual SQL: ds ::: SELECT id,name,pwd_cipher AS pwd FROM c_user WHERE pwd_cipher = ? ::: [urfTcCrgkt2aQnnS7QaaNQ==]# false=> Actual SQL: ds ::: SELECT id,name,pwd_plain AS pwd FROM c_user WHERE pwd_plain = ? ::: [abc]- 测试
@SpringBootTest
public class EncryptTest {@AutowiredCUserMapper cUserMapper;@Testpublic void testEncrypt() {CUser cUser = CUser.builder().name("lxx").pwd("abc").build();cUserMapper.insert(cUser);}@Testpublic void testFindByPwd() {HashMap<String, Object> map = new HashMap<>();map.put("pwd", "abc");List<CUser> list = cUserMapper.selectByMap(map);list.stream().forEach(System.out::println);}}
六 分布式事务剖析实战
1 分布式事务理论
-
CAP(强一致性)
一致性(C):在分布式系统中的所有数据备份能够保证一致(意味着所有节点访问读到的就像是“同一份数据副本”)
可用性(A):保证每个请求不管成功或者失败都有响应,换句话说,是只要收到用户的请求,服务器就必须给出回应。
分区容错性(P):系统中任意信息的丢失或失败不会影响系统的继续运作。
-
BASE理论(最终一致性)
Basically Available(基本可用):指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
Soft-state(软状态):指允许系统中的数据存在CAP 理论中的数据不一致,称为中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
Eventually Consistent(最终一致性):最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
2 分布式事务模式
了解了分布式事务中的强一致性和最终一致性理论,下面介绍几种常见的分布式事务的解决方案。
- 2PC模式(强一致性)
2PC是Two-Phase Commit缩写,即两阶段提交,就是将事务的 提交过程分为两个阶段来进行处理。事务的发起者称协调者,事 务的执行者称参与者。协调者统一协调参与者执行。
阶段1:准备阶段,协调者向所有参与者发送事务内容,询问是 否可以提交事务,并等待所有参与者答复。各参与者执行事务操作,但不提交事务,将 undo 和 redo 信息记入事务日志中。如参与者执行成功,给协调者反馈 yes;如执行失败,给协调者反馈 no。
阶段2:提交阶段,如果协调者收到了参与者的失败消息或者超时,直接给每个参与者发送回滚(rollback)消息;否则,发送提交(commit)消息。
2PC 方案实现起来简单,实际项目中使用比较少,主要因为以下问题:
性能问题:所有参与者在事务提交阶段处于同步阻塞状态,占用 系统资源,容易导致性能瓶颈。
可靠性问题:如果协调者存在单点故障问题,如果协调者出现故障,参与者将一直处于锁定状态。
数据一致性问题:在阶段 2 中,如果发生局部网络问题,一部分事务参与者收到了提交消息,另一部分事务参与者没收到提交消息,那么就导致了节点之间数据的不一致。
- 3PC模式(强一致性)
3PC (三阶段提交),是两阶段提交的改进版本,与两阶段提交不同的是,引入超时机制。同时在协调者和参与者中都引入超时机制。三阶段提交将两阶段的准备阶段拆分为 2 个阶段,插入了一 个preCommit 阶段,解决了原先在两阶段提交中,参与者在准备之后,由于协调者或参与者发生崩溃或错误,而导致参与者无法知晓处于长时间等待的问题。如果在指定的时间内协调者没有收到参与者的消息则默认失败。
阶段1:canCommit,协调者向参与者发送 commit 请求,参与者如果可以提交就返回 yes 响应,否则返回 no 响应。
阶段2:preCommit,协调者根据阶段 1 canCommit 参与者的反应情况执行预提交事务或中断事务操作。 参与者均反馈 yes:协调者向所有参与者发出 preCommit 请 求,参与者收到 preCommit 请求后,执行事务操作,但不提交;将 undo 和 redo 信息记入事务日志中;各参与者向协调者反馈 ack 响应或 no 响应,并等待最终指令。任何一个参与者反馈 no或等待超时:协调者向所有参与者 发出 abort 请求,无论收到协调者发出的 abort 请求,或者在等待协调者请求过程中出现超时,参与者均会中断事务。
阶段3:do Commit 该阶段进行真正的事务提交,根据阶段 2 preCommit反馈的结果完成事务提交或中断操作。
相比2PC模式,3PC模式降低了阻塞范围,在等待超时后协调者或参与者会中断事务。避免了协调者单点问题,阶段 3 中协调者出现问题时(比如网络中断等),参与者会继续提交事务。
- XA(强一致性)
XA是由X/Open组织提出的分布式事务的规范,是基于两阶段提交协议。 XA规范主要定义了全局事务管理器(TM)和局部资源管理器(RM)之间的接口。目前主流的关系型数据库产品都是实现了XA接口。

XA之所以需要引入事务管理器,是因为在分布式系统中,从理 论上讲两台机器理论上无法达到一致的状态,需要引入一个单点 进行协调。由全局事务管理器管理和协调的事务,可以跨越多个资源(数据库)和进程
事务管理器用来保证所有的事务参与者都完成了准备工作(第一 阶段)。如果事务管理器收到所有参与者都准备好的消息,就会通知所有的事务都可以提交了(第二阶段)。MySQL 在这个XA 事务中扮演的是参与者的角色,而不是事务管理器。
- TCC模式(最终一致性)
TCC(Try-Confirm-Cancel)的概念,最早是由 Pat Helland 于 2007 年发表的一篇名为《Lifebeyond Distributed Transactions:an Apostate’s Opinion》的论文提出。TCC 是服 务化的两阶段编程模型,其 Try、Confirm、Cancel 3 个方法均 由业务编码实现:
Try 操作作为一阶段,负责资源的检查和预留;
Confirm 操作作为二阶段提交操作,执行真正的业务;
Cancel 是预留资源的取消;

TCC 模式相比于 XA,解决了如下几个缺点:
解决了协调者单点,由业务应用发起并完成这个业务活动。业务 活动管理器可以变成多点,引入集群。
同步阻塞:引入超时机制,超时后进行补偿,并且不会锁定整个 资源,将资源转换为业务逻辑形式,粒度变小。
数据一致性,有了补偿机制之后,由业务活动管理器控制一致 性。
3 Sharding-JDBC整合XA数据源
XAShardingSphereTransactionManager为Apache ShardingSphere 的分布式事务的 XA 实现类。它主要负责对多数据 源进行管理和适配,并且将相应事务的开启、提交和回滚操作委托 给具体的 XA 事务管理器。ShardingSphere整合XA事务时,分离了 XA事务管理和连接池管理,这样接入XA时,可以做到对业务的零侵 入。
ShardingSphere支持以下功能:
支持数据分片后的跨库XA事务;
两阶段提交保证操作的原子性和数据的强一致性;
服务宕机重启后,提交/回滚中的事务可自动恢复;
SPI机制整合主流的XA事务管理器,默认Atomikos;
同时支持XA和非XA的连接池;
提供spring-boot和namespace的接入端。

- 开启全局事务
XAShardingSphereTransactionManager将调用具体的 XA 事务 管理器开启 XA 全局事务,以 XID 的形式进行标记。
- 执行真实分片SQL
XAShardingSphereTransactionManager将数据库连接所对应 的 XAResource注册到当前 XA 事务中之后,事务管理器会在此 阶段发送XAResource.start命令至数据库。数据库在收到 XAResource.end命令之前的所有 SQL 操作,会被标记为 XA 事 务。
XAResource1.start ## Enlist阶段执行
statement.execute("sql1"); ## 模拟执行一个分片
SQL1
statement.execute("sql2"); ## 模拟执行一个分片
SQL2
XAResource1.end ## 提交阶段执行
示例中的sql1和sql2将会被标记为 XA 事务。
- 提交或回滚事务
XAShardingSphereTransactionManager在接收到接入端的提 交命令后,会委托实际的 XA 事务管理进行提交动作, 事务管理 器将收集到的当前线程中所有注册的 XAResource,并发送 XAResource.end指令,用以标记此 XA 事务边界。 接着会依次 发送prepare指令,收集所有参与 XAResource 投票。 若所有 XAResource 的反馈结果均为正确,则调用commit指令进行最 终提交; 若有任意 XAResource 的反馈结果不正确,则调用 rollback指令进行回滚。 在事务管理器发出提交指令后,任何 XAResource 产生的异常都会通过恢复日志进行重试,以保证提 交阶段的操作原子性,和数据强一致性。
XAResource1.prepare ## ack: yes
XAResource2.prepare ## ack: yes
XAResource1.commit
XAResource2.commitXAResource1.prepare ## ack: yes
XAResource2.prepare ## ack: no
XAResource1.rollback
XAResource2.rollback
4 Sharding-JDBC分布式事务实战
ShardingSphere整合了XA、为分布式事务控制提供了极大的便利,我们可以在应用程序编程时,采用以下统一模式进行使用。
- 引入Maven依赖
//XA模式
<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-transaction-xa-core</artifactId>
</dependency>
- JAVA编码方式设置事务类型
TransactionTypeHolder.set(TransactionType.XA);
- 参数配置
ShardingSphere默认的XA事务管理器为Atomikos,通过在项目的classpath中添加jta.properties来定制化Atomikos配置项。具 体的配置规则如下:
#指定是否启动磁盘日志,默认为true。在生产环境下一定要保证为true,否则数据的完整性无法保证
com.atomikos.icatch.enable_logging=true
#JTA/XA资源是否应该自动注册com.atomikos.icatch.automatic_resource_regis
tration=true
#JTA事务的默认超时时间,默认为10000ms
com.atomikos.icatch.default_jta_timeout=10000
#事务的最大超时时间,默认为300000ms。这表示事务超时时间由
#UserTransaction.setTransactionTimeout()较大者决定。4.x版本之后,指定为0的话则表示不设置超时时间
com.atomikos.icatch.max_timeout=300000
#指定在两阶段提交时,是否使用不同的线程(意味着并行)。3.7版本之后默认为false,更早的版本默认为true。如果为false,则提交将按照事务中访问资源的顺序进行。
com.atomikos.icatch.threaded_2pc=false
#指定最多可以同时运行的事务数量,默认值为50,负数表示没有数量限制。在调用
#UserTransaction.begin()方法时,可能会抛出一个”Max number of activetransactionsreached”异常信息,表示超出最大事务数限制
com.atomikos.icatch.max_actives=50
#是否支持subtransaction,默认为true
com.atomikos.icatch.allow_subtransactions=true
#指定在可能的情况下,是否应该join子事务(subtransactions),默认值为true。如果设置为false,对于有关联的不同subtransactions,不会调用XAResource.start(TM_JOIN)
com.atomikos.icatch.serial_jta_transactions=true
#指定JVM关闭时是否强制(force)关闭事务管理器,默认为false
com.atomikos.icatch.force_shutdown_on_vm_exit=false
#在正常关闭(no-force)的情况下,应该等待事务执行完成的时间,默认为Long.MAX_VALUE
com.atomikos.icatch.default_max_wait_time_on_shutdown=9223372036854775807
========= 日志记录配置=======
#事务日志目录,默认为./。
com.atomikos.icatch.log_base_dir=./
#事务日志文件前缀,默认为tmlog。事务日志存储在文件中,文件名包含一个数字后缀,日志文件以.log为扩展名,如tmlog1.log。遇到checkpoint时,新的事务日志文件会被创建,数字增加。
com.atomikos.icatch.log_base_name=tmlog
#指定两次checkpoint的时间间隔,默认为500
com.atomikos.icatch.checkpoint_interval=500
=========日志恢复配置=============
#指定在多长时间后可以清空无法恢复的事务日志(orphaned),默认86400000ms
com.atomikos.icatch.forget_orphaned_log_entries_delay=86400000
#指定两次恢复扫描之间的延迟时间。默认值为与com.atomikos.icatch.default_jta_timeout相同
com.atomikos.icatch.recovery_delay=${com.atomikos.icatch.default_jta_timeout}
#提交失败时,再抛出一个异常之前,最多可以重试几次,默认值为5
com.atomikos.icatch.oltp_max_retries=5
#提交失败时,每次重试的时间间隔,默认10000ms
com.atomikos.icatch.oltp_retry_interval=10000
5 案例
- 添加依赖
<!-- sharding-jdbc --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.1.0</version></dependency><!-- 使用 Sharding-JDBC 下的 XA 事务 --><!-- 因为使用Sharding-JDBC配置读写分离数据源后,Spring自带的事务会失效,需配合使用 --><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-transaction-xa-core</artifactId><version>4.1.0</version></dependency>
- 业务层
@Service
public class PositionService {@Autowiredprivate PositionMapper positionMapper;@Autowiredprivate PositionDetailMapper positionDetailMapper;@Transactional@ShardingTransactionType(TransactionType.XA)public void add() {for (int i = 0; i < 20; i++) {Position position = Position.builder().name("lxx" + i).city("昆明").salary("20000").build();positionMapper.insert(position);if (i == 3) {throw new RuntimeException("人为制作的异常");}PositionDetail positionDetail = PositionDetail.builder().pid(position.getId()).description("this is desc " + i).build();positionDetailMapper.insert(positionDetail);}}
}
- 测试
@SpringBootTest
public class PositionServiceTest {@Autowiredprivate PositionService positionService;@Testpublic void testAdd() {positionService.add();}
}