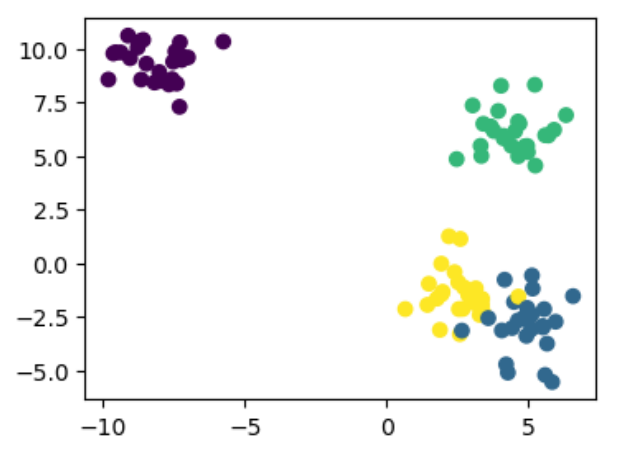
sklearn中make_blobs()方法参数:
-
n_samples:表示数据样本点个数,默认值100 -
n_features:是每个样本的特征(或属性)数,也表示数据的维度,默认值是2。默认为 2 维数据,测试选取 2 维数据也方便进行可视化展示。 -
centers:表示类别数(标签的种类数),默认值3 -
cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比- 另一类具有更大的方差,可以将cluster_std设置为[1.0,3.0],浮点数或者浮点数序列,默认值1.0 -
center_box:中心确定之后的数据边界,默认值(-10.0, 10.0) -
shuffle:将数据进行洗乱,默认值是True -
random_state:官网解释是随机生成器的种子,可以固定生成的数据,给定数之后,每次生成的数据集就是固定的。
X, y = make_blobs(n_samples=100, n_features=2,centers=4, cluster_std=1.0, center_box=(-10.0, 10.0), shuffle=True, random_state=47)
plt.figure(figsize=(4, 3))
plt.scatter(X[:,0],X[:,1],c=y)