课程资源:(林子雨)Spark编程基础(Python版)_哔哩哔哩_bilibili
第8章 Spark MLlib(6节)
机器学习算法库
(一)MLlib简介
1、机器学习
机器学习可以看做是一门人工智能的科学,该领域的主要研究对象是人工智能。机器学习利用数据或以往的经验,优化计算机程序的性能标准。强调三个关键词:算法、经验、性能
- 模型:用数据对算法进行训练后得到的
- 算法:区别于模型
(1)传统机器学习算法
由于技术和单机存储的限制,只能在少量数据上使用,依赖于数据抽样

(2)Spark机器学习
大数据技术的出现可以支持在全量数据上进行机器学习
- 使用MapReduce对机器学习算法进行编写:MapReduce是基于磁盘的计算框架,机器学习算法涉及大量迭代计算,涉及反复读写磁盘的开销,有磁盘IO开销比较大的缺陷
- 而Spark是基于内存的计算框架,由于DAG机制避免频繁读写磁盘开销,适合大量迭代计算
2、MLlib-机器学习库
(1)简介
提供了常用机器学习算法的分布式实现。且PySpark的即席查询也是一个关键,算法工程师边写代码、边运行、边看结果
不是所有的机器学习算法都能用在Spark中,有的算法无法做成并行
- MLlib中只包含能够在集群上运行良好的并行算法,有些经典的机器学习算法没有包含在其中,因为它们不能并行执行
- 相反地,一些较新研究得出的算法因为适用于集群,也被包含在MLlib中,例如分布式随机森林算法、最小交替二乘算法。这样的选择使得MLlib中的每一个算法都适用于大规模数据集
- 如果是小规模数据集上训练各机器学习模型,最好还是在各个节点上使用单节点的机器学习算法库(比如Weka)
(2)内容
MLlib是Spark机器学习库,旨在简化机器学习的工程实践工作
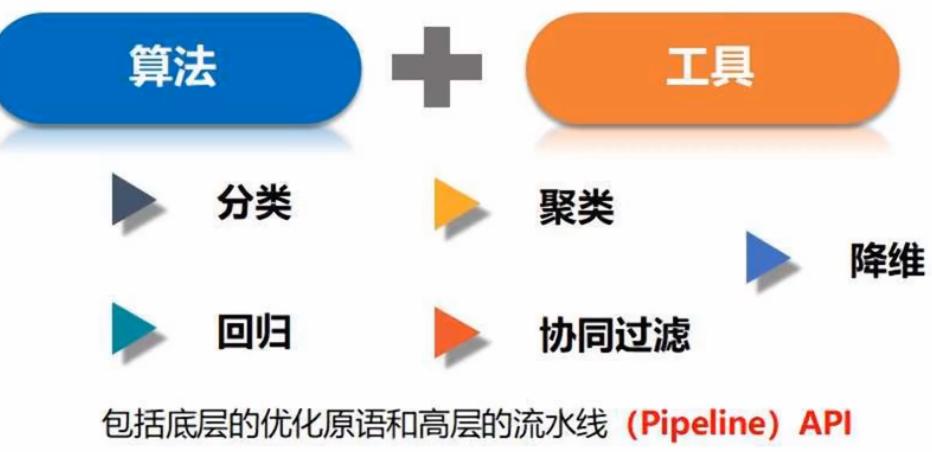
- 算法工具:分类、回归、聚类、协同过滤
- 特征化工具:特征提取、转换、降维、选择
- 流水线(Pineline)工具:构建+评估,调整机器学习工作流
- 持久性:保存、加载算法、模型、管道
- 实用性工具:线性代数、统计、数据处理

(3)与 spark.ml 的区别
是机器学习库不同的包
- spark.mllib 是基于RDD的数据抽象,包含基于RDD的原始算法API。在1.0以前的版本已经包含,提供的算法实现都是基于原始RDD
- spark.ml 是基于DataFrame的数据抽象,提供基于DataFrame高层次的API,可以用来构建机器学习工作流Pipeline(与Spark SQL完美融合),弥补了原始mllib库的不足,向用户提供了一个基于DataFrame的机器学习工作流式API套件
(二)机器学习流水线
1、概念
(1)DataFrame:结构化数据封装
使用Spark SQL中的DataFrame作为数据集,可以容纳各种数据类型。较之RDD,DataFrame包含了schema信息,更类似传统数据库中的二维表格。它被ML Pipeline用来存储源数据,例如,DataFrame中的列可以是存储的文本、特征向量、真实标签和预测标签等
(2)转换器:Transformer
将一个DataFrame转换为另一个DataFrame。比如一个模型就是一个Transformer,它可以把一个不包含预测标签的测试数据集DataFrame打上标签,转换成另一个包含预测标签的DataFrame。技术上,Transformer实现了一个方法 transform(),它通过附加一个或多个列,将一个DataFrame转换为另一个DataFrame
(3)评估器(算法):Estimator
用数据对评估器训练得到模型,调用 .fit(DataFrame) 即可。它是学习算法或在训练数据上的训练方法的概念抽象,在Pipeline里通常是被用来操作DataFrame数据并生成一个Transformer。从技术上,Estimator实现了一个方法fit(),它接收一个DataFrame并产生一个转换器。比如,一个随机森林算法就是一个Estimator,它可以调用fit(),通过训练特征数据得到一个随机森林模型
(4)参数:Parameter
被用来设置Transformer或Estimator的参数。所有转换器和评估器可共享用于指定参数的公共API。ParamMap是一组 (参数, 值) 对
(5)流水线/管道:PipeLine
将多个工作流阶段(即转换器和评估器)连接起来形成机器学习工作流并获得输出结果
2、构建
- 定义Pipeline中的各个流水线阶段PipelineStage(包含转换器、评估器)
- 按照处理逻辑,转换器和评估器有序地组织起来构建成Pipeline
把训练数据集作为输入参数,调用fit()方法,返回一个PipelineModel类实例,输出被用来预测测试数据的标签
pipeline = Pipeline(stages = [stage1, stage2, stage3])流水线各阶段运行,输入的DataFrame在它通过每个阶段时被转换:
- Tokenizer:分词
- HashingTF:把单词转换为特征向量

一个流水线,若一开始就包含了算法或评估器,那么它整体就是评估器,就可以调用 .fit() 对流水线进行训练,得到流水线模型PipelineModel。即:流水线本身也可以看做是一个评估器,在流水线的fit()方法运行之后,它产生一个PipelineModel,是一个Transformer,这个管道模型将在测试数据的时候使用
3、逻辑斯蒂回归案例
任务:查找所有包含Spark的句子,1即包含Spark,0即没有包含Spark
- 使用SparkSession对象(Spark2.0以上版本,PySpark在启动时会自动创建名为spark的SparkSession对象;但在编写独立代码时需自己生成)
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("WordCount").master("local").getOrCreate()
# SparkSession由其伴生对象的builder()方法创建- pyspark.ml 依赖numpy包,Ubuntu自带Python3是没有numpy的,执行命令安装:sudo pip3 install numpy
(1)引入要包含的包并构建训练数据集
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import HashingTF, Tokenizer
from pyspark.ml import Pipelinetraining = spark.createDataFrame([(0, "a b c d e spark", 1.0),(1, "b d", 0.0),(2, "spark f g h", 1.0),(3, "hadoop mapreduce", 0.0)],["id", "text", "label"])(2)定义Pipeline中各个流水线阶段PipelineStage
每个阶段是一个评估器或转换器

tokenizer = Tokenizer(inputCol="text", outputCol="words") # 分词器,words列是新生成的,会追加到DataFrame中
hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features")
lr = LogisticRegression(maxIter=10, regParam=0.001)(3)按照处理逻辑有序地组织PipelineStage,创建Pipeline
pipline = Pipeline(stages=[tokenizer, hashingTF, lr]) # 现在构建的Pipeline本质上是一个estimator,在它的fit()方法运行后,将产生一个PipelineModel,它是一个Transformer
model = pipline.fit(training) # model类型是一个PipelineModel,这个流水线模型将在测试数据的时候使用(4)构建测试数据
test = spark.createDataFrame([(4, "spark i j k"),(5, "l m n"),(6, "spark hadoop spark"),(7, "apache hadoop")], ["id", "text"] # 不包含label列)(5)生成预测结果
prediction = model.transform(test)
selected = prediction.select("id", "text", "probability", "prediction") # probability属于0/1的概率for row in selected.collect():rid, text, prob, prediction = row# %d代表int占位符,%s代表字符串占位符,%f代表浮点数占位符print("(%d, %s) --> prob=%s, prediction=%f" % (rid, text, str(prob), prediction))
(三)特征抽取:TF-IDF
1、TF-IDF(词频-逆向文件频率)
文本挖掘中使用的特征向量化方法,体现一个文档中的词语在语料库中的重要程度

在Spark中,TF-IDF被分为两个部分:
- TF(转换器):HashingTF(哈希)。接收词条的集合,把这些集合转化成固定长度的特征向量,这个算法在哈希的同时会统计各个词条的词频
- IDF(评估器):在一个数据集上应用 fit() 方法,产生一个IDFModel。该IDFModel接收特征向量(由HashingTF产生),计算每一个词在文档中出现的频次。IDF会减少那些在语料库中出现频率较高的词的权重(因为这些词的区分度低,不重要)
2、代码
从一组句子开始,首先使用分词器Tokenizer把句子划分为单个词语,对每一个句子(词袋)使用HashingTF将句子转换为特征向量,最后使用IDF重新调整特征向量,以体现每个单词真正的重要性
# 导入TF-IDF所需包
from pyspark.ml.feature import HashingTF, IDF, Tokenizer# 创建一个DataFrame,每一个句子代表一个文档
sentenceData = spark.createDataFrame([(0, "I heard about Spark and I love Spark"),(0, "I wish Java could use case classes"),(1, "Logistic regression models are neat")]).toDF("label", "sentence")# 得到文档集合后即可用tokenizer对句子进行分词
tokenizer = Tokenizer(inputCol="sentence", outputCol="words")
wordsData = tokenizer.transform(sentenceData) # 转换后新增一列words,为分词结果
wordsData.show()+-----+--------------------+--------------------+
|label| sentence| words|
+-----+--------------------+--------------------+
| 0|I heard about Spa...|[i, heard, about,...|
| 0|I wish Java could...|[i, wish, java, c...|
| 1|Logistic regressi...|[logistic, regres...|
+-----+--------------------+--------------------+每次转换 .transform() 就会不断增加新的列
# 使用HashingTF的transform()把句子哈希成特征向量
hashingTF = HashingTF(inputCol="words", outputCol="rawfeatures", numFeatures=2000) # 设置哈希表的桶数为2000
featurizedData = hashingTF.transform(wordsData)
featurizedData.select("words", "rawfeatures").show(truncate = False)+---------------------------------------------+---------------------------------------------------------------------+
|words |rawfeatures |
+---------------------------------------------+---------------------------------------------------------------------+
|[i, heard, about, spark, and, i, love, spark]|(2000,[240,673,891,956,1286,1756],[1.0,1.0,1.0,1.0,2.0,2.0]) |
|[i, wish, java, could, use, case, classes] |(2000,[80,342,495,1133,1307,1756,1967],[1.0,1.0,1.0,1.0,1.0,1.0,1.0])|
|[logistic, regression, models, are, neat] |(2000,[286,763,1059,1604,1871],[1.0,1.0,1.0,1.0,1.0]) |
+---------------------------------------------+---------------------------------------------------------------------+(2000,[240,673,891,956,1286,1756],[1.0,1.0,1.0,1.0,2.0,2.0])
- 2000个哈希桶
- 240表示单词i被扔到了第240个哈希桶
- 1.0表示对应单词的出现次数
# 使用IDF评估器来对单纯的词频特征向量进行构造
idf = IDF(inputCol="rawfeatures", outputCol="features")
idfModel = idf.fit(featurizedData) # 对评估器进行训练# 调用IDFModel的transform()方法调权重
rescaledData = idfModel.transform(featurizedData)
rescaledData.select("features", "label").show(truncate = False)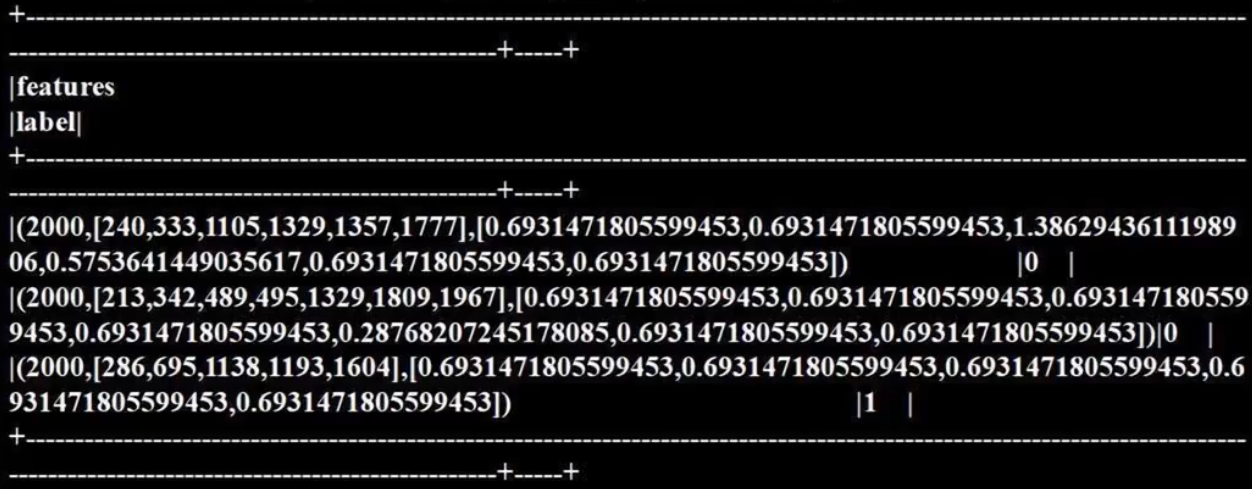
(四)特征转换:Word2Vec(标签和索引的转换)
在机器学习处理过程中,为了方便相关算法的实现,经常需要把标签数据(一般是字符串)转换为整数索引,或是在计算结束后将整数索引还原为相应的标签
Spark ML包提供了几个相关的转换器,如:StringIndexer、IndexToString、OneHotEncoder、VectorIndexer,它们提供了十分方便的特征转换功能,这些转换器类都位于org.apache.spark.ml.feature包下
用于特征转换的转换器和其他机器学习算法一样,也属于ML Pipeline模型的一部分,可以用来构建机器学习流水线。以StringIndexer为例,其存储着进行标签数值化过程的相关超参数,是一个Estimator,对其调用fit()方法即可生成相应的模型StringIndexerModel类。很显然,它存储了用于DataFrame进行相关处理的参数,是一个Transformer(其他转换器也是同一原理)
1、StringIndexer
可以把一列类别型特征(或标签)进行编码,使其数值化。索引的范围从0开始,该过程可以使相应的特征索引化,使得某些无法接受类别型特征的算法可以使用,并提高诸如决策树等机器学习算法的效率
- 索引构建的顺序为标签的频率,优先编码频率较大的标签,所以出现频率最高的标签为0号
- 如果输入数值型的,会先把它转化成字符型,再对其进行编码
from pyspark.ml.feature import StringIndexer# 构建DataFrame,设置StringIndexer的输入列和输出列
df = spark.createDataFrame([(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")],["id", "category"])# 构建转换器,字符串类型转为整型
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")# 通过fit()进行模型训练,用训练出的模型对原数据集进行处理
model = indexer.fit(df)
indexed = model.transform(df)
indexed.show() # 频率最高的会被转化为0+---+--------+--------------+
| id|category| categoryIndex|
+---+--------+--------------+
| 0| a| 0.0|
| 1| b| 2.0|
| 2| c| 1.0|
| 3| a| 0.0|
| 4| a| 0.0|
| 5| c| 1.0|
+---+--------+--------------+
a出现3次,故为0.0
c出现2次,故为1.0
b出现1次,故为2.02、IndexToString(与 StringIndexer 相反)
把标签索引的一列重新映射回原有的字符型标签。其主要使用场景一般都是和 StringIndexer 配合,先用StringIndexer将标签转换成标签索引,进行模型训练,然后在预测标签时再把标签索引转换成原有的字符标签
from pyspark.ml.feature import IndexToString, StringIndexertoString = IndexToString(inputCol="categoryIndex", outputCol="originalCategory")
indexString = toString.transform(indexed)
indexString.select("id", "originalCategory").show()+---+----------------+
| id|originalCategory|
+---+----------------+
| 0| a|
| 1| b|
| 2| c|
| 3| a|
| 4| a|
| 5| c|
+---+----------------+3、VectorIndexer
之前介绍的 StringIndexer 是针对单个类别型特征进行转换。倘若所有特征都已经被组织在一个向量中,又想对其中某些单个分量进行处理时,Spark ML提供了 VectorIndexer类 来解决向量数据集中的类别型特征转换。通过为其提供 maxCategories 超参数,它可以自动识别哪些特征是类别型并将原始值转换为类别索引。它基于不同特征值的数量来识别哪些特征需要被类别化,那些取值可能性最多不超过 maxCategories 的特征会被认为是类别型
from pyspark.ml.feature import VectorIndexer
from pyspark.ml.linalg import Vector, Vectors# 每一个vector是一个样本的特征向量,纵向编码
df = spark.createDataFrame([(Vectors.dense(-1.0, 1.0, 1.0),), (Vectors.dense(-1.0, 3.0, 1.0),), (Vectors.dense(0.0, 5.0, 1.0), )], ["features"])# 构建VectorIndexer转换器,设置输入输出列,并进行模型训练
indexer = VectorIndexer(maxCategories=2, inputCol="features", outputCol="indexed") # maxCategories表示超过此值后,不进行类别编码
indexerModel = indexer.fit(df)# 通过categoryMaps成员来获得被转换的特征及其映射
categoricalFeatures = indexerModel.categoryMaps.keys()
print("Choose" + str(len(categoricalFeatures)) + "categorical features:" + str(categoricalFeatures)) # Choose 2 categorical features:[0,2]# 把模型应用于原有数据,并打印结果
indexed = indexerModel.transform(df)
indexed.show()+--------------+-------------+
| features| indexed|
+--------------+-------------+
|[-1.0,1.0,1.0]|[1.0,1.0,0.0]|
|[-1.0,3.0,1.0]|[1.0,3.0,0.0]|
| [0.0,5.0,1.0]|[0.0,5.0,0.0]|
+--------------+-------------+# 第一列 [-1.0,-1.0,0.0] 不同值个数为2个=2,类别型特征,转换
# 第二列 [1.0,3.0,5.0] 不同值个数为3个>2,不转换
# 第三列 [1.0,1.0,1.0] 不同值个数为1个<2,类别型特征,转换(五)逻辑斯蒂回归分类器
逻辑斯蒂回归(Logistic Regression)是统计学习中的经典分类方法,属于对数线性模型。logistic回归的因变量可以是二分类的,也可以是多分类的
1、iris数据集介绍
https://dblab.xmu.edu.cn/blog/wp-content/uploads/2017/03/iris.txt

iris 以鸢尾花的特征作为数据来源,数据集包含150个数据,分为3类,每类50个数据,每个数据包含4个属性,是在数据挖掘、数据分类中常用的训练集测试集
2、iris数据集分类实例
(1)导入需要的包
# 1 导入需要的包
from pyspark.ml.linalg import Vector, Vectors
from pyspark.sql import Row, functions
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml import Pipeline
from pyspark.ml.feature import IndexToString, StringIndexer, VectorIndexer, HashingTF, Tokenizer
from pyspark.ml.classification import LogisticRegression, LogisticRegressionModel, BinaryLogisticRegressionSummary, LogisticRegression(2)定制函数返回数据字典
读取文本文件,第一个map把每行数据用逗号隔开。每行被分成5个部分,前4部分是鸢尾花的4个特征,最后一部分是鸢尾花的类别。把特征存储在Vector中,创建一个iris模式的RDD,然后转换为DataFrame
# 2 定制一个函数,来返回一个指定的数据字典
def f(x): # 传入x为一个列表(4个特征+分类label)rel = {}rel['features'] = Vectors.dense(float(x[0]), float(x[1]), float(x[2]), float(x[3]))rel['label'] = str(x[4])return rel # 两个键值对data = spark.sparkContext. \textFile("file:///usr/local/spark/iris.txt"). \map(lambda line: line.split(',')). \map(lambda p: Row(**f(p))). \ # 根据数据字典封装成Row对象toDF()
data.show()+-----------------+-----------+
| features| label|
+-----------------+-----------+
|[5.1,3.5,1.4,0.2]|Iris-setosa|
|[4.9,3.0,1.4,0.2]|Iris-setosa|
|[4.7,3.2,1.3,0.2]|Iris-setosa|
|[4.6,3.1,1.5,0.2]|Iris-setosa|
|[5.0,3.6,1.4,0.2]|Iris-setosa|(3)分别获取标签列和特征列
# 3 分别获取标签列和特征列,进行索引并进行重命名
labelIndexer = StringIndexer(). \ # 把字符串标签转换为数值型索引setInputCol("label"). \setOutputCol("indexedLabel"). \fit(data) # 评估器->转换器featureIndexer = VectorIndexer(). \ # 把数值型特征向量转换为索引数值型特征向量setInputCol("features"). \setOutputCol("indexedFeatures"). \fit(data) # 评估器->转换器(4)设置LogisticRegression算法的参数
# 具体可以设置的参数,可以通过explainParams()来获取,还能看到程序已经设置的参数的结果
lr = LogisticRegression(). \setLabelCol("indexedLabel"). \setFeaturesCol("indexedFeatures"). \setMaxIter(100). \ # 循环次数为100次setRegParam(0.3). \ # 规范化项为0.3setElasticNetParam(0.8)
print("LogisticRegression parameters:\n" + lr.explainParams())(5)设置一个IndexToString的转换器
构建一个机器学习流水线,设置各个阶段。上一个阶段的输出将是本阶段的输入
# 5 把预测的类别(数值型prediction) 转化成字符型的predictedLabel
labelConverter = IndexToString(). \setInputCol("prediction"). \ # 预测得到的分类setOutputCol("predictedLabel"). \setLabels(labelIndexer.labels) # 标签来源# 6 构建机器学习流水线(Pipeline)
lrPipeline = Pipeline().setStages([labelIndexer, featureIndexer, lr, labelConverter])(6)训练+预测
Pipeline本质上是一个评估器,当Pipeline调用fit()的时候就产生了一个PipelineModel,它是一个转换器。然后,这个PipelineModel就可以调用transform()来进行预测,生成一个新的DataFrame,即利用训练得到的模型对测试集进行验证
# 把数据集随机分成训练集和测试集,其中训练集占70%
trainingData, testData = data.randomSplit([0.7, 0.3])
lrPipelineModel = lrPipeline.fit(trainingData)
lrPredictions = lrPipelineModel.transform(testData) # testData只包含4个特征,不包含label(7)输出预测的结果
# 7 select选择要输出的列
# collect获取所有行的数据
# 用foreach把每行打印出来
preRows = lrPredictions.select("label", "features", "probability", "predictedLabel").collect()
for row in preRows:label, features, probability, predictedLabel = rowprint("%s,%s --> prob=%s,predictedLabel:%s" % (label, features, probability, predictedLabel))Iris-setosa,[4.3,3.0,1.1,0.1] --> prob=[0.5243322260103365,0.2807261844423659,0.1949415895472976],predictedLabel:Iris-setosa
Iris-setosa,[4.4,2.9,1.4,0.2] --> prob=[0.49729174541655624,0.2912406744481094,0.2114675801353344],predictedLabel:Iris-setosa
Iris-setosa,[4.4,3.2,1.3,0.2] --> prob=[0.5033392716254922,0.28773708047332464,0.20892364790118315],predictedLabel:Iris-setosa
Iris-setosa,[4.6,3.2,1.4,0.2] --> prob=[0.49729174541655624,0.2912406744481094,0.2114675801353344],predictedLabel:Iris-setosa(8)对训练的模型进行评估
用set方法把预测分类的列名和真实分类的列名进行设置,然后计算预测准确率
# 8 创建一个MulticlassClassificationEvaluator实例
evaluator = MulticlassClassificationEvaluator(). \setLabelCol("indexedLabel"). \ # 真实字符串标签被转换为数值型标签的结果setPredictionCol("prediction")
lrAccuracy = evaluator.evaluate(lrPredictions)
print("lrAccuracy=%f" % lrAccuracy) # 0.7774712643678161(9)通过model来获取训练得到的逻辑斯蒂模型
# 9 lrPipelineModel是一个PipelineModel,因此可以通过调用它的stages方法来获取lr模型
lrModel = lrPipelineModel.stages[2] # .stages是一个列表,lr是封装在机器学习流水线里
print("\nCoefficients: \n " + str(lrModel.coefficientMatrix) +"\nIntercept: " + str(lrModel.interceptVector) +"\n numClasses: " + str(lrModel.numClasses) +"\n numFeatures: " + str(lrModel.numFeatures)Coefficients: 3 X 4 CSRMatrix
(0,2) -0.2419
(0,3) -0.1715
(1,3) 0.446
Intercept: [0.7417523479805953,-0.16623552721353418,-0.575516820767061]numClasses: 3numFeatures: 4(六)决策树分类器
决策树是一种基本的分类和回归方法,这里主要介绍分类。
1、决策树
决策树模型呈树型结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。学习时利用训练数据,根据损失函数最小化的原则建立决策树模型;预测时对新的数据利用决策树模型进行分类
决策树学习步骤:特征选择 - 决策树生成 - 决策树剪枝
2、iris数据集分类实例
(1)导入需要的包
from pyspark.ml.linalg import Vector, Vectors
from pyspark.sql import Row
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
from pyspark.ml import Pipeline, PipelineModel
from pyspark.ml.feature import IndexToString, StringIndexer, VectorIndexer
from pyspark.ml.classification import DecisionTreeClassificationModel, DecisionTreeClassifier(2)读取文本文件
def f(x): # 传入x为一个列表(4个特征+分类label)rel = {}rel['features'] = Vectors.dense(float(x[0]), float(x[1]), float(x[2]), float(x[3]))rel['label'] = str(x[4])return rel # 两个键值对data = spark.sparkContext. \textFile("file:///usr/local/spark/iris.txt"). \map(lambda line: line.split(',')). \ # 把每行的数据用逗号隔开map(lambda p: Row(**f(p))). \ # 根据数据字典封装成Row对象toDF()(3)处理特征和标签,以及数据分组
# 3 分别获取标签列和特征列,进行索引并进行重命名
labelIndexer = StringIndexer(). \ # 把字符串标签转换为数值型索引setInputCol("label"). \setOutputCol("indexedLabel"). \fit(data) # 评估器->转换器featureIndexer = VectorIndexer(). \ # 把原始特征向量转换为索引值特征向量setInputCol("features"). \setOutputCol("indexedFeatures"). \setMaxCategories(4). \ # 不同数值个数≤4才转换成数值型标签fit(data) # 评估器->转换器labelConverter = IndexToString(). \setInputCol("prediction"). \ # 预测得到的分类(数值型分类标签)setOutputCol("predictedLabel"). \ # 转换为字符串类型标签列setLabels(labelIndexer.labels) # 原来的字符串类型标签来源trainingData, testData = data.randomSplit([0.7, 0.3])(4)构建决策树分类模型,设置决策树的参数
通过set的方法来设置决策树的参数,也可以用ParamMap来设置。这里仅需设置特征列(FeaturesCol)和待预测列(LabelCol)。具体可以设置的参数可以通过 explainParams() 获取
dtClassifier = DecisionTreeClassifier(). \setLabelCol("indexedLabel"). \setFeaturesCol("indexedFeatures")(5)构建机器学习流水线Pipeline,调用fit()进行模型训练
对评估器训练后得到模型,即转换器,即可对测试数据进行转换,得到预测结果
dtPipeline = Pipeline().setStages([labelIndexer, featureIndexer, dtClassifier, labelConverter])
dtPipelineModel = dtPipeline.fit(trainingData)
dtPredictions = dtPipelineModel.transform(testData)
dtPredictions.select("predictedLabel", "label", "features").show(20)
模型的预测准确率:
evaluator = MulticlassClassificationEvaluator(). \setLabelCol("indexedLabel"). \ # 真实字符串标签被转换为数值型标签的结果setPredictionCol("prediction")
dtAccuracy = evaluator.evaluate(dtPredictions)
print("dtAccuracy=%f" % dtAccuracy) # 0.9726976552103888(6)调用toDebugString方法查看训练的决策树模型结构
treeModelClassifier = dtPipelineModel.stages[2] # .stages是一个列表,dt是封装在机器学习流水线里
print("Learned classification tree model:\n" + str(treeModelClassifier.toDebugString))