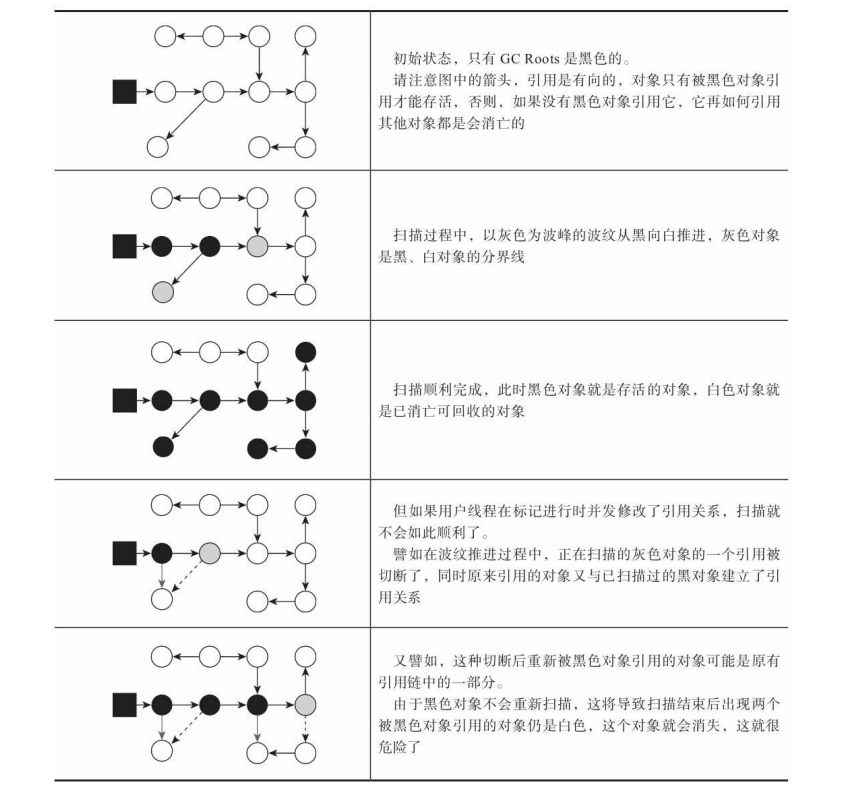
背景
在flink中,有几个比较重要的概念,逻辑DataFlow图,物理DataFlow图以及处理槽执行任务,本文就来讲解下这几个概念
概念详解
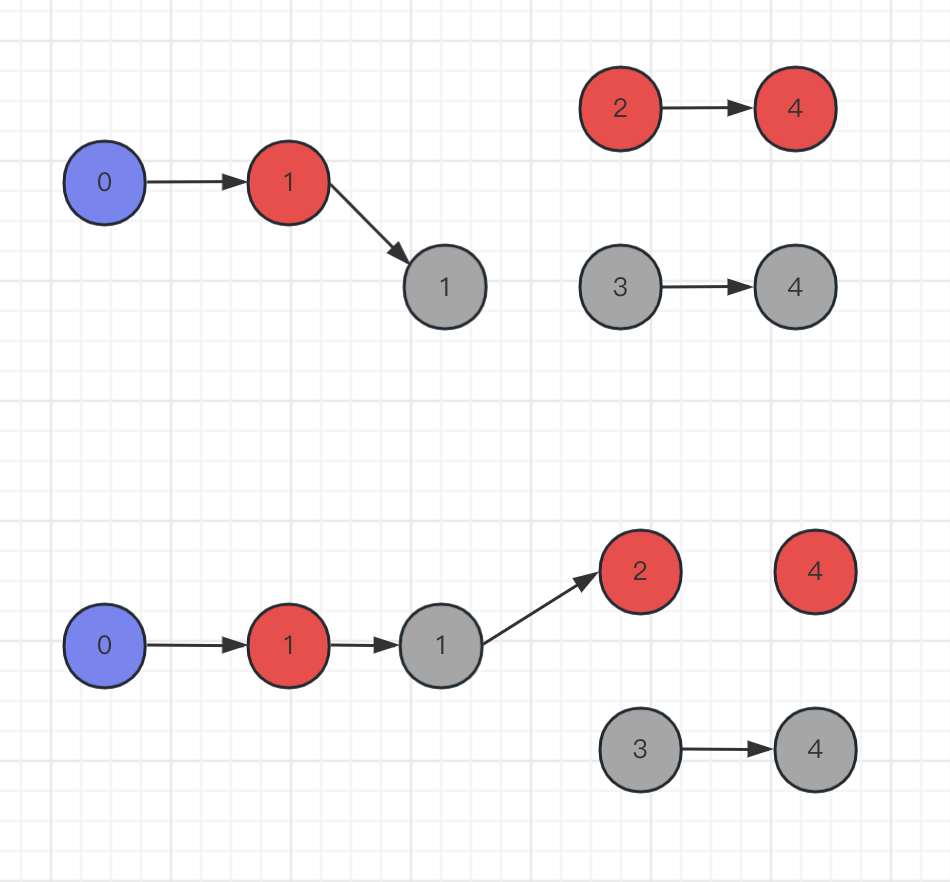
假设有以下代码:数据源和统计单词算子的并行度是2,数据汇算子的并行度是1,当前集群有100个空闲的处理槽(分别从SLOT_{A,B,C…})

可以看到最终我们只使用了两个处理槽,分别是SLOT_A和SLOT_B,使用的处理槽的数量和设置的算子最大并行度一样,然后在每个处理槽内,对于每个任务,处理槽会分别开启一个Thread线程进行处理,这里你会不会觉得很奇怪,我还有这么多空闲的处理槽,为何只用了其中的两个?
这其实是由flink的任务调度策略决定的,其决定的依据这样分配当有很多job在同时执行时,可以达到最佳的资源分配,详见官方文档的解释