前言
当前教程使用的playwright版本为1.37.0,selenium版本为3.141.0
官方文档:https://playwright.dev/python/docs/screenshots
本教程目录如下
文章目录
- 前言
- playwright各类截图源码阅读
- ElementHandle类下的截图
- Page类下的截图
- Locator类下的截图
- Playwright快速使用截图功能
- 两大框架标签页切换对比
- selenium切换标签页
- playwright切换标签页
- playwright切换标签页代码封装
- JS注入
- selenium使用js注入
- playwright使用js注入
- 综合实战
- **实战需求**
- **难点**
- **解决方案**
- 图像拼接封装
- 实战完整代码
playwright各类截图源码阅读
通过阅读源码:playwright -> sync_api -> _generated.py可知,可以在以下三种方式下进行screenshots截图。
返回值均为字节bytes
class ElementHandle(JSHandle):(官方不建议或弃用)def screenshotclass Page(SyncContextManager):(官方推荐整个页面截图)def screenshotclass Locator(SyncBase):(官方推荐元素定位截图)def screenshot
ElementHandle类下的截图
官方建议不要用此方式,请使用Locator对象进行操作,后续可能会弃用此方式。
该方法会截取页面的屏幕截图,并根据该特定元素的大小和位置进行裁剪。如果该元素被其他元素覆盖,则在截图上实际上不可见。如果该元素是可滚动容器,则截图上只会显示当前滚动的内容。该方法在进行屏幕截图之前会等待 可操作性 检查,然后将元素滚动到视图中。如果该元素从 DOM 中分离,该方法将抛出错误。
用法
element_handle.screenshot()
element_handle.screenshot(**kwargs)
参数
| 参数 | 类型 | 含义 |
|---|---|---|
| timeout | Union[float, None] | 最大等待时间,以毫秒为单位。默认为30000(30秒)。传入0以禁用超时。browser_context.set_default_timeout()或page.set_default_timeout()方法更改默认值。 |
| type | Union[“jpeg”, “png”, None] | 指定截图的类型,默认为png。 |
| path | Union[pathlib.Path, str, None] | 图像保存的文件路径。截图类型将根据文件扩展名进行推断。如果path是相对路径,则相对于当前工作目录解析。如果不提供路径,则图像将不会保存到磁盘。 |
| quality | Union[int, None] | 图像的质量,介于0到100之间。不适用于png图像。 |
| omit_background | Union[bool, None] | 隐藏默认的白色背景,允许使用透明度进行截图。不适用于jpeg图像。默认为false。 |
| animations | Union[“allow”, “disabled”, None] | 设置为"disabled"时,停止CSS动画、CSS过渡和Web动画。动画的处理方式取决于其持续时间:有限动画将快进到完成状态,因此它们会触发transitionend事件。 无限动画将取消到初始状态,然后在截图后重新播放。默认为"allow",即保持动画不变。 |
| caret | Union[“hide”, “initial”, None] | 设置为"hide"时,截图将隐藏文本插入符。设置为"initial"时,文本插入符的行为不会改变。默认为"hide"。 |
| scale | Union[“css”, “device”, None] | 设置为"css"时,截图上每个CSS像素将具有一个实际像素。对于高DPI设备,这将使截图保持较小的大小。使用"device"选项将使每个设备像素有一个实际像素,因此高DPI设备的截图将是两倍或更大。默认为"device"。 |
| mask | Union[List[Locator], None] | 指定在截图时应隐藏的定位符。被隐藏的元素将被叠加一个粉色框#FF00FF(由maskColor自定义),完全覆盖其边界框。 |
| mask_color | Union[str, None] | 指定被隐藏元素的覆盖框的颜色,以CSS颜色格式表示。默认颜色为粉色#FF00FF。 |
Page类下的截图
用法
page.screenshot()
page.screenshot(**kwargs)
参数
| 参数 | 类型 | 含义 |
|---|---|---|
| timeout | Union[float, None] | 最大等待时间,以毫秒为单位。默认为30000(30秒)。传入0以禁用超时。browser_context.set_default_timeout()或page.set_default_timeout()方法更改默认值。 |
| type | Union[“jpeg”, “png”, None] | 指定截图的类型,默认为png。 |
| path | Union[pathlib.Path, str, None] | 图像保存的文件路径。截图类型将根据文件扩展名进行推断。如果path是相对路径,则相对于当前工作目录解析。如果不提供路径,则图像将不会保存到磁盘。 |
| quality | Union[int, None] | 图像的质量,介于0到100之间。不适用于png图像。 |
| omit_background | Union[bool, None] | 隐藏默认的白色背景,允许使用透明度进行截图。不适用于jpeg图像。默认为false。 |
| full_page | Union[bool, None] | 为true时,截取完整可滚动页面的屏幕截图,而不是当前可见的视口。默认为false。 |
| clip | Union[{x: float, y: float, width: float, height: float}, None] | 指定结果图像的裁剪区域的对象。 |
| animations | Union[“allow”, “disabled”, None] | 设置为"disabled"时,停止CSS动画、CSS过渡和Web动画。动画的处理方式取决于其持续时间:有限动画将快进到完成状态,因此它们会触发transitionend事件。 无限动画将取消到初始状态,然后在截图后重新播放。默认为"allow",即保持动画不变。 |
| caret | Union[“hide”, “initial”, None] | 设置为"hide"时,截图将隐藏文本插入符。设置为"initial"时,文本插入符的行为不会改变。默认为"hide"。 |
| scale | Union[“css”, “device”, None] | 设置为"css"时,截图上每个CSS像素将具有一个实际像素。对于高DPI设备,这将使截图保持较小的大小。使用"device"选项将使每个设备像素有一个实际像素,因此高DPI设备的截图将是两倍或更大。默认为"device"。 |
| mask | Union[List[Locator], None] | 指定在截图时应隐藏的定位符。被隐藏的元素将被叠加一个粉色框#FF00FF(由maskColor自定义),完全覆盖其边界框。 |
| mask_color | Union[str, None] | 指定被隐藏元素的覆盖框的颜色,以CSS颜色格式表示。默认颜色为粉色#FF00FF。 |
Locator类下的截图
该方法将截取页面的屏幕截图,并根据定位符匹配的特定元素的大小和位置进行裁剪。如果该元素被其他元素覆盖,则在截图上实际上不可见。如果该元素是可滚动容器,则截图上只会显示当前滚动的内容。
该方法会等待可操作性检查,然后将元素滚动到视图中,然后再进行截图。如果该元素已从 DOM 中移除,则该方法会抛出一个错误。
用法
page.get_by_role("link").screenshot()
page.locator("#main-content").screenshot()
参数
| 参数 | 类型 | 含义 |
|---|---|---|
| timeout | Union[float, None] | 最大等待时间,以毫秒为单位。默认为30000(30秒)。传入0以禁用超时。browser_context.set_default_timeout()或page.set_default_timeout()方法更改默认值。 |
| type | Union[“jpeg”, “png”, None] | 指定截图的类型,默认为png。 |
| path | Union[pathlib.Path, str, None] | 图像保存的文件路径。截图类型将根据文件扩展名进行推断。如果path是相对路径,则相对于当前工作目录解析。如果不提供路径,则图像将不会保存到磁盘。 |
| quality | Union[int, None] | 图像的质量,介于0到100之间。不适用于png图像。 |
| omit_background | Union[bool, None] | 隐藏默认的白色背景,允许使用透明度进行截图。不适用于jpeg图像。默认为false。 |
| animations | Union[“allow”, “disabled”, None] | 设置为"disabled"时,停止CSS动画、CSS过渡和Web动画。动画的处理方式取决于其持续时间:有限动画将快进到完成状态,因此它们会触发transitionend事件。 无限动画将取消到初始状态,然后在截图后重新播放。默认为"allow",即保持动画不变。 |
| caret | Union[“hide”, “initial”, None] | 设置为"hide"时,截图将隐藏文本插入符。设置为"initial"时,文本插入符的行为不会改变。默认为"hide"。 |
| scale | Union[“css”, “device”, None] | 设置为"css"时,截图上每个CSS像素将具有一个实际像素。对于高DPI设备,这将使截图保持较小的大小。使用"device"选项将使每个设备像素有一个实际像素,因此高DPI设备的截图将是两倍或更大。默认为"device"。 |
| mask | Union[List[Locator], None] | 指定在截图时应隐藏的定位符。被隐藏的元素将被叠加一个粉色框#FF00FF(由maskColor自定义),完全覆盖其边界框。 |
| mask_color | Union[str, None] | 指定被隐藏元素的覆盖框的颜色,以CSS颜色格式表示。默认颜色为粉色#FF00FF。 |
注意点
locator类下的截图方法,是比page类下的截图方法少了两个可选参数。
full_page:对于元素截图不支持全页面滚动长截图。
clip:对于元素截图不支持裁剪。
Playwright快速使用截图功能
当前页面截图
page.screenshot(path="screenshot.png")
当前页面长截图
page.screenshot(path="screenshot.png", full_page=True)
将截图转为字节存储在缓存中
screenshot_bytes = page.screenshot()
print(base64.b64encode(screenshot_bytes).decode())
根据元素截图
page.locator(".header").screenshot(path="screenshot.png")
两大框架标签页切换对比
在Web UI测试中,我们点击某个带有超链接的元素,可能会在新的标签页打开。
实际上有时候浏览器还是停留在当前页面,并没有自己切到新页面,这时候就需要切换到新的标签页进行元素定位等相关操作。
selenium切换标签页
在selenium是通过handles句柄的方式进行切换。每个页面都有唯一的句柄,最新的页面可通过下标[-1]获取。
driver.switch_to.window(driver.window_handles[-1])
playwright切换标签页
在playwright的page类下有个将页面置于最前面(激活选项卡)方法,可以将目标标签页激活,并且在目标标签页进行元素定位等相关操作。
官方文档:https://playwright.dev/python/docs/api/class-page#page-bring-to-front
# 用法如下
Page.bring_to_front()
如何激活我们所需要激活的页面?
1、通过url
page.url
2、通过title
page.title
playwright切换标签页代码封装
个人感觉切换标签页selenium更方便一点,playwright需要我们自己封装一下。我封装的代码如下:
def switch_to_page(context: BrowserContext, url: str = None, title: str = None) -> Page:"""切换到指定url:param context:传入一个浏览器上下文:param title: 当前标签页的标题:param url: 当前标签页的url:return: label_page:Page对象 返回对应的标签页,如果没找到则返回最新的标签页"""for label_page in context.pages:if url:if url in label_page.url:label_page.bring_to_front()return label_pageelif title:if title in label_page.title():label_page.bring_to_front()return label_pageelse:if title:print(f"没有找到【{title}】标题的标签页")if url:print(f"没有找到【{url}】网址的标签页")return context.pages[-1]
代码注释都写的很清楚了,这里就不单独做解析了。
JS注入
在一些特殊的情况下,我们需要执行原生js,从而达到我们一些框架无法完成的操作。
selenium使用js注入
使用execute_script方法
def execute_script(self, script, *args):"""在当前窗口/框架中同步执行JavaScript。:参数:- script: 可执行的JavaScript脚本.- \*args: 任何适用的JavaScript参数.:使用方法:driver.execute_script('return document.title;')"""
实战示列
我要通过js在浏览器创建一个新标签并打开我博客首页。
from selenium import webdriver
driver = webdriver.Chrome()
driver.execute_script(f'window.open("https://blog.csdn.net/qq_46158060", "_blank");')
playwright使用js注入
官方文档:https://playwright.dev/python/docs/api/class-page#page-evaluate
使用evaluate方法或evaluate_handle方法。
page.evaluate() 和 page.evaluate_handle() 之间的唯一区别是 page.evaluate_handle() 返回 JSHandle。
def evaluate(self, expression: str, arg: typing.Optional[typing.Any] = None) -> typing.Any:
传入的是一个表达式,返回一个序列化值。
官方有挺多个示列。
```py
result = await page.evaluate(\"([x, y]) => Promise.resolve(x * y)\", [7, 8])
print(result) # prints \"56\"
``````py
result = page.evaluate(\"([x, y]) => Promise.resolve(x * y)\", [7, 8])
print(result) # prints \"56\"
```A string can also be passed in instead of a function:```py
print(await page.evaluate(\"1 + 2\")) # prints \"3\"
x = 10
print(await page.evaluate(f\"1 + {x}\")) # prints \"11\"
``````py
print(page.evaluate(\"1 + 2\")) # prints \"3\"
x = 10
print(page.evaluate(f\"1 + {x}\")) # prints \"11\"
```
实战示列(1)
我要通过js在浏览器创建一个新标签并打开我博客首页。
page.evaluate(f'window.open("https://blog.csdn.net/qq_46158060", "_blank");')
实战示列(2)
通过js定位一个id为main-content的元素,并且滚动该元素。
js = 'document.getElementById("main-content").scrollTo(600,800)'
page.evaluate(js)
# 或
# page.evaluate_handle(js)
综合实战
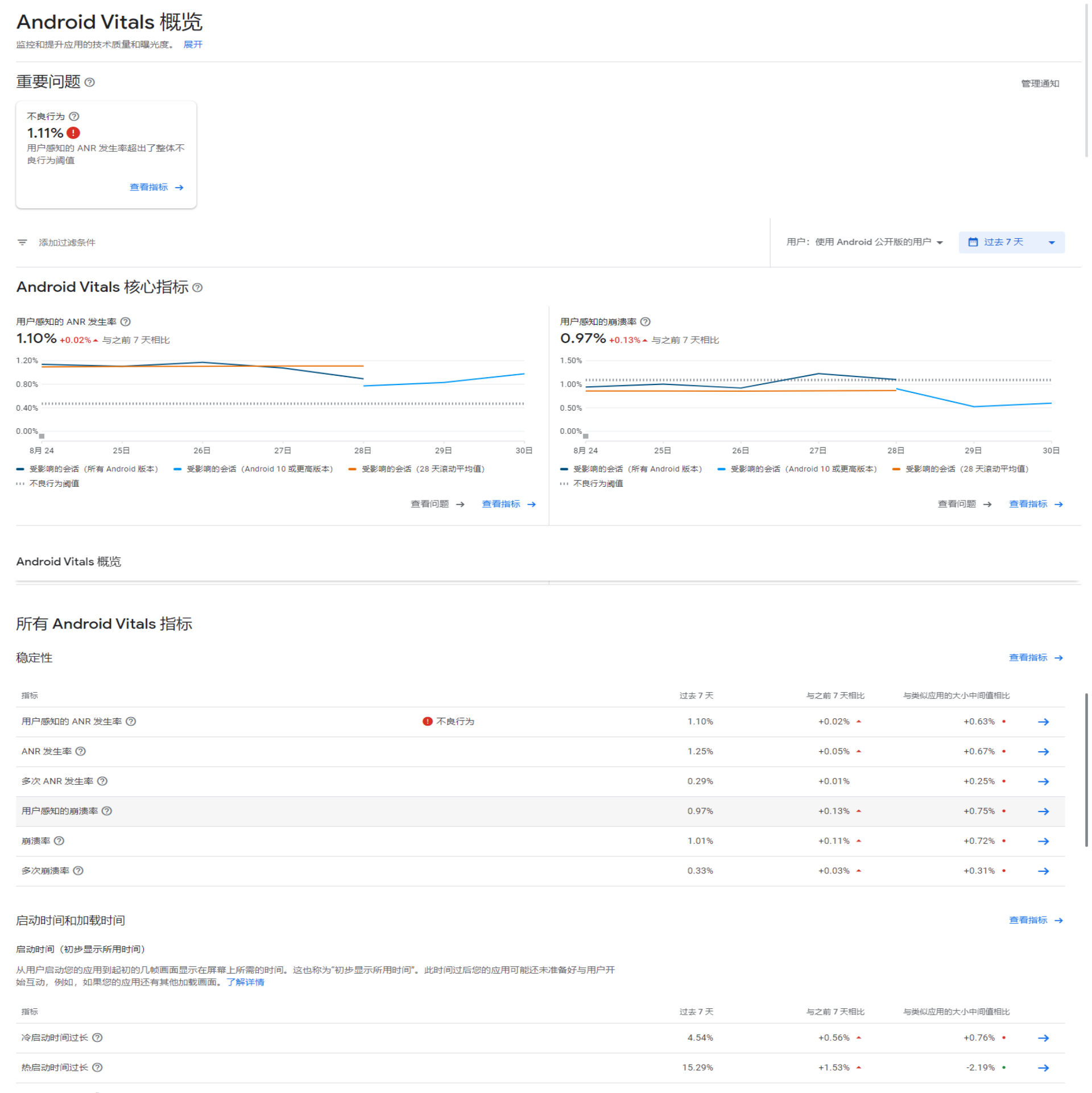
需要操作的页面如下

实战需求
1、使用playwright连接本地指定端口浏览器
2、通过浏览器在新标签页打开指定项目ID下的相关页面
3、页面分为左右两栏,可以分别滚动,需要滚动右侧栏,并且进行长截图
4、要求一个页面只能有一张图
难点
1、playwright如何连接本地指定端口浏览器进行操作
2、前文中提到,页面截图,默认是第一个滚动条(暂未找到切换滚动条方案),这里需要定位右侧栏,也就是第二个滚动条
3、执行playwright按键操作进行滚动,默认是第一个滚动条,需要结合多种定位和键位,操作复杂
4、前文中提到,如果通过定位右侧栏大框元素进行截图,只能固定截图,无法长截图
解决方案
1、playwright连接本地浏览器详细教程参考我之前写过的文章:playwright连接已有浏览器操作
2、使用js定位右侧框的元素
3、使用js定位右侧框的元素进而执行滚动操作
4、通过js滚动进行多次截图。每滚动一次截图一次,至于滚动的范围需要自己先进行调试,最后将多张图进行拼接成一张图片。
图片拼接技术参考之前文章:web自动化之selenium的特殊用法汇总篇 , 这篇文章的特殊网页无法长截图,使用多图拼接技术章节。
图像拼接封装
下载三方库
pip install pillow==8.4.0
封装代码
from PIL import Image
# 拼接图片的代码
def stitch_images(imgPath_1: str, imgPath_2: str, newImgPath: str) -> str:""":param imgPath_1: 第一张图片的路径,:param imgPath_2: 第二张图片的路径,:param newImgPath: 拼接图片的路径,:return: newImgPath"""# 获取JPG、png图像的路径im_list_1 = [imgPath_1, imgPath_2]im_list = [Image.open(fn) for fn in im_list_1]# 图片转化为相同的尺寸ims = []for i in im_list:new_img = i.resize((1920, 961), Image.BILINEAR)ims.append(new_img)# 单幅图像尺寸width, height = ims[0].size# 创建空白长图result = Image.new(ims[0].mode, (width, height * len(ims)))# 拼接图片for i, im in enumerate(ims):result.paste(im, box=(0, i * height))# 保存图片result.save(newImgPath)return newImgPath
实战完整代码
步骤:
1、使用playwright连接本地浏览器(含用户数据,免登陆,懒加载)
2、使用js在新标签页打开相关网址
3、切换至指定标签页
4、定位右侧栏,结合js滚动进行多图截取
5、使用PIL库进行多图拼接
注:本教程为示列代码,业务代码为方便阅读未进行封装,相关代码都进行了注释。
# -*- coding: utf-8 -*-
"""
@Time : 2023/6/25 14:50
@Email : Lvan826199@163.com
@公众号 : 梦无矶的测试开发之路
@File : PW_001_截图.py
"""
__author__ = "梦无矶小仔"import timefrom playwright.sync_api import sync_playwright, BrowserContext, Page
from PIL import Imagedef switch_to_page(context: BrowserContext, url: str = None, title: str = None) -> Page:"""切换到指定url:param context:传入一个浏览器上下文:param title: 当前标签页的标题:param url: 当前标签页的url:return: label_page:Page对象 返回对应的标签页,如果没找到则返回最新的标签页"""for label_page in context.pages:if url:if url in label_page.url:label_page.bring_to_front()return label_pageelif title:if title in label_page.title():label_page.bring_to_front()return label_pageelse:if title:print(f"没有找到【{title}】标题的标签页")if url:print(f"没有找到【{url}】网址的标签页")return context.pages[-1]# 拼接图片的代码
def images_stitch(imgPath_1: str, imgPath_2: str, newImgPath: str) -> str:""":param imgPath_1: 第一张图片的路径,:param imgPath_2: 第二张图片的路径,:param newImgPath: 拼接图片的路径,:return: newImgPath"""# 获取JPG、png图像的路径im_list_1 = [imgPath_1, imgPath_2]im_list = [Image.open(fn) for fn in im_list_1]# 图片转化为相同的尺寸ims = []for i in im_list:new_img = i.resize((1920, 961), Image.BILINEAR)ims.append(new_img)# 单幅图像尺寸width, height = ims[0].size# 创建空白长图result = Image.new(ims[0].mode, (width, height * len(ims)))# 拼接图片for i, im in enumerate(ims):result.paste(im, box=(0, i * height))# 保存图片result.save(newImgPath)return newImgPath# 主代码playwright = sync_playwright().start()
# 连接已经打开的浏览器,找好端口
browser = playwright.chromium.connect_over_cdp("http://127.0.0.1:9223")
default_context = browser.contexts[0]
print(type(default_context))
page = default_context.pages[0]projectID = 6691166666666666666
gameID = 497566666666666666
timeRange = 7# 官方教程 https://playwright.dev/python/docs/api/class-page#page-evaluateurl123 = f'https://play.google.com/console/u/0/developers/{projectID}/app/{gameID}/vitals/metrics/overview?days={timeRange}'page.evaluate(f'window.open("https://play.google.com/console/u/0/developers/{projectID}/app/{gameID}/vitals/metrics/overview?days={timeRange}", "_blank");'
) # 执行js代码page.wait_for_timeout(5000)page = switch_to_page(default_context, url123)### 进行截图
# 官方教程 https://playwright.dev/python/docs/screenshots#full-page-screenshots
now_time = time.time_ns()
page.wait_for_timeout(1000)
page.locator("#main-content").click()
page.wait_for_timeout(1000)image_path_1 = f'./img-{now_time}.png'
page.locator("#main-content").screenshot(path=f'img-{now_time}.png')
print("截图成功001")page.wait_for_timeout(1000)
js = 'document.getElementById("main-content").scrollTo(600,800)'
# page.evaluate_handle(js)
page.evaluate(js)
print("执行了js滚动")
page.wait_for_timeout(1000)
now_time = time.time_ns()
image_path_2 = f'./img-{now_time}.png'
page.locator("#main-content").screenshot(path=f'img-{now_time}.png')
print("截图成功002")# 截图拼接
new_image_path = './image_result.png'
result_img_path = images_stitch(image_path_1,image_path_2,new_image_path)
print(f"完整长截图路径:{result_img_path}")
最终长截图效果展示






![CUDA说明和安装[window]](https://img-blog.csdnimg.cn/img_convert/bebf45183e54509b2d7ba66fecd63ba1.png)