pandas库主要有两种数据结构DataFrames和Series。这些数据结构在内部用索引数组和数据数组表示,索引数组标记数据,数据数组包含实际数据。现在,当我们试图复制这些数据结构(DataFrames和Series)时,我们实际上是复制对象的索引和数据,有两种方法可以做到这一点,即浅复制和深复制。
这些操作是在库函数pandas.DataFrame.copy(deep=False)(用于浅拷贝)和pandas.DataFrame.copy(deep=True)(用于DataFrames和Series中的深拷贝)的帮助下完成的。
现在,让我们了解一下什么是浅拷贝。
浅拷贝
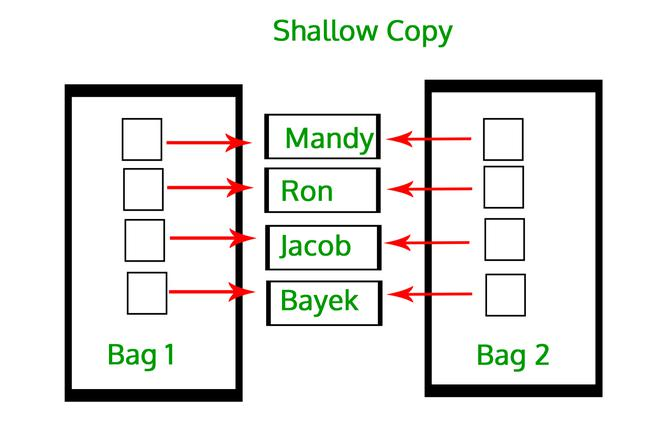
当创建DataFrame或Series对象的浅层副本时,它不会复制原始对象的索引和数据,而只是复制对其索引和数据的引用。因此,对一个对象所做的更改将反映在另一个对象中。
它指的是构造一个新的集合对象,然后用对原始集合中的子对象的引用填充它。复制过程不会递归,因此不会创建子对象本身的副本。
比如:
import pandas as pd# assign dataframe
df = pd.DataFrame({'index': [1, 2, 3, 4],'GFG': ['Mandy', 'Ron', 'Jacob', 'Bayek']})# shallow copy
copydf = df.copy(deep=False)# comparing shallow copied dataframe
# and original dataframe
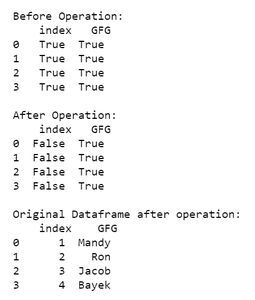
print('\nBefore Operation:\n', copydf == df)# assignment operation
copydf['index'] = [0, 0, 0, 0]# comparing shallow copied dataframe
# and original dataframe
print('\nAfter Operation:\n', copydf == df)print('\nOriginal Dataframe after operation:\n', df)
输出

从上面程序的输出可以看出,应用于浅层复制数据帧的更改会自动应用于原始数据帧。
深拷贝
DataFrame或Series对象的深层副本具有自己的索引和数据副本。这是一个复制过程递归发生的过程。这意味着首先构造一个新的集合对象,然后用在原始集合中找到的子对象的副本递归地填充它。在深度复制的情况下,对象的副本被复制到另一个对象中。这意味着对对象副本所做的任何更改都不会反映在原始对象中。
例如

import pandas as pd# assign dataframe
df = pd.DataFrame({'index': [1, 2, 3, 4],'GFG': ['Mandy', 'Ron', 'Jacob', 'Bayek']})# deep copy
copydf = df.copy(deep=True)# comparing shallow copied dataframe
# and original dataframe
print('\nBefore Operation:\n', copydf == df)# assignment operation
copydf['index'] = [0, 0, 0, 0]# comparing shallow copied dataframe
# and original dataframe
print('\nAfter Operation:\n', copydf == df)print('\nOriginal Dataframe after operation:\n', df)
输出
在这里,原始对象中的数据不会被递归复制。也就是说,原始对象的数据中的数据仍然指向相同的存储单元。例如,如果Dataframe或Series对象中的数据包含任何可变数据,那么它将在它和它的深层副本之间共享,并且对其中一个的任何修改都将反映在另一个中。
浅拷贝与深拷贝的区别
| 浅拷贝 | 深拷贝 |
|---|---|
| 它是集合结构的副本,而不是元素的副本。 | 它是集合的副本,其中复制了原始集合中的所有元素。 |
| 影响初始数据帧。 | 不影响初始数据帧。 |
| 浅拷贝不会复制子对象。 | 深拷贝递归地复制子对象。 |
| 创建浅拷贝比创建深拷贝快。 | 与浅拷贝相比,创建深拷贝速度较慢。 |
| 副本依赖于原件。 | 副本并不完全依赖于原件。 |