Pandas 是在 Numpy 上的封装。 继承了 Numpy 的所有优点,但是这种封装有好有坏
我们对比一下两者创建的形式和效果
import pandas as pd
import numpy as np
a=np.array([[1,2],[3,4]])
b=pd.DataFrame({"a":[1,2],"b":[3,4]}
)
print(a,"\n",b)

Pandas 就像字典一样,还记录着数据的外围信息, 比如标签(Column 名)和索引(Row index)
可以简单理解为Numpy 是 Python 里的列表,而 Pandas 是 Python 里的字典
Pandas 和 NumPy 都是Python中用于数据处理和分析的重要库,但它们具有不同的优点和缺点,适用于不同类型的任务和应用场景。
Pandas的优点:
-
表格数据处理: Pandas以DataFrame的形式支持表格型数据处理,这种结构非常适合处理多维数据,例如SQL数据库或电子表格。DataFrame允许你轻松地执行各种操作,如筛选、合并、聚合、透视等。
-
标签: Pandas提供了丰富的标签,可以用于行和列,使得数据的访问和操作更加直观和容易理解。
-
缺失数据处理: Pandas提供了有效的方法来处理缺失数据,这在实际数据分析中非常常见。你可以轻松地填充、删除或插入缺失的数据。
-
时间序列数据: Pandas对时间序列数据的支持非常强大,包括日期范围生成、滚动窗口、时间重采样等功能。
-
数据可视化: Pandas可以与其他数据可视化库(如Matplotlib和Seaborn)结合使用,以便快速生成图表和可视化数据。
Pandas的缺点:
-
性能: 对于大型数据集,Pandas的性能可能不如NumPy,因为Pandas的DataFrame会消耗更多的内存和计算资源。
-
学习曲线: 对于初学者来说,Pandas的学习曲线可能较陡峭,因为需要了解各种函数和概念,如索引、层次化索引、多级列等。
NumPy的优点:
-
性能: NumPy是一个高性能的数值计算库,它用C语言编写,并且对数组操作进行了优化。对于大型数据集和数值计算任务,NumPy通常比Pandas更快。
-
多维数组: NumPy的核心数据结构是多维数组(ndarray),它非常适合进行数学和科学计算,如线性代数、统计分析和信号处理。
-
广泛的数学函数: NumPy提供了大量的数学和统计函数,包括线性代数、傅立叶变换、随机数生成等。
-
与其他库的集成: NumPy与许多其他科学计算库(如SciPy、scikit-learn)以及数据可视化库(如Matplotlib)紧密集成,使得它成为构建复杂数据分析和科学计算应用的基础。
NumPy的缺点:
-
缺少表格数据结构: NumPy主要关注多维数组,缺少直接支持表格数据的数据结构。这使得处理类似数据库表格或电子表格的数据时,需要使用较多的代码。
-
不适用于非数值数据: NumPy主要用于数值数据,不太适用于处理文本或混合类型的数据。
综上所述,Pandas和NumPy在数据处理和分析中各有其优点和缺点,通常会根据任务的性质和需求来选择使用哪个库,甚至可以同时使用它们以发挥各自的优势。如果需要处理表格型数据、进行数据清洗和转换,通常会首选Pandas。如果需要进行数值计算、线性代数运算或高性能的科学计算,NumPy可能更适合。
基本操作
从文件读取数据
excel文件
我们先创建一个excel文件

import pandas as pd
# 读取
a=pd.read_excel("体检数据.xlsx")
print(a)
# index_col=0,把第一个 column(学号)的数据当做 row 索引
a=pd.read_excel("体检数据.xlsx",index_col=0)
print(a)# 修改(此时原始数据并没有被修改)
a.loc[2,"体重"]=1
print(a)# 保存(此时新保存的excel里的数据是被修改后的)
a.to_excel("保存的体检数据.xlsx")

-
.loc[]是pandas库用于选择DataFrame中特定行和列的方法。在这里,它被用来定位特定的行和列。 -
[2, "体重"]是.loc[]的参数,这里表示选择第2行(索引为2的行)和名为"体重"的列。
csv或txt等纯文本文件
我们先创建一个csv文件

# 用python方法打开
with open("体检数据.csv","r",encoding="utf-8") as f:print(f.read())# 用pandas打开,sep表示分割符号,如果别人给你的数据不走常规用+分割,那么你的sep就要是+
a=pd.read_csv("体检数据.csv",index_col=0,sep=",")
print(a)# 保存
a.to_csv("保存的体检数据.csv")
a.to_excel("保存的体检数据.xlsx")

其他有趣的方法
后面再补上
Pandas 中的数据是什么
数据序列Series(一维)
Pandas 中的 Series 的核心其实就是一串类似于 Python List 的序列。只是它要比 Python List 丰富很多, 有更多的功能属性
# list和pd的Series的区别
a=[11,22,33]
b=pd.Series(a)
print(a)
print(b)# 自定义索引
b=pd.Series(a,index=["a","b","c"])
print(b)
b=pd.Series({"a":11,"b":22,"c":33})
print(b)# 将列表换成numpy数组
import numpy as np
b=pd.Series(np.random.rand(3),index=["a","b","c"])
print(b)# 把Series返回成numpy数组或list
print(b.to_numpy())
print(b.values.tolist())

b.to_numpy() 和 b.values 功能基本上是相同的,它们都用于将 pandas DataFrame 中的数据转换为 NumPy 数组,但有一些微小的差异:
-
命名不同:
b.to_numpy()是一个方法,而b.values是一个属性。使用方法时需要添加括号,而属性不需要。 -
版本兼容性:在较旧版本的 pandas 中,可能没有
to_numpy()方法,因此b.values是更通用的选择。 -
潜在性能:在某些情况下,
b.to_numpy()可能会在性能上略优于b.values,因为它可以更好地处理某些特殊情况,例如,当 DataFrame 包含不同数据类型的列时,to_numpy()可以将数据类型更好地匹配到 NumPy 数组的数据类型,而b.values会将所有列都强制转换为一种通用数据类型。
总的来说,功能上它们是相同的,可以根据个人偏好选择使用哪个,但在大多数情况下,它们都会产生相似的结果。
数据表DataFrame(二维)
a=pd.DataFrame([[1,2],[3,4]])
print(a)
# 第一行,第0列的数字
print(a.at[1,0])# 通过字典的方式创建,修改的是列索引
a=pd.DataFrame({"col1":[1,3],"col2":[2,4]})
print(a)# 由DataFrame创建Series
print(a["col1"])
print(type(a["col1"]))# 由Series创建DataFrame
print(pd.DataFrame({"col1":pd.Series([1,3]),"col2":pd.Series([2,4])},index=["a","b"]))# 获取行索引和列索引
print(a.index,"\n",a.columns)#json格式转换成DataFrame
json=[{"age":18,"weight":"60"},{"age":20,"weight":"70"},
]
print(pd.DataFrame(json,index=["jack","rose"]))#DataFrame转换成numpy
print(a.to_numpy())

我们发现有一处的值都是Nan,这是什么原因,我们先定位到是哪个语句出了问题
# 由Series创建DataFrame
print(pd.DataFrame({"col1":pd.Series([1,3]),"col2":pd.Series([2,4])},index=["a","b"]))
在这段代码中,创建了一个新的 pandas DataFrame,但在创建过程中似乎存在一个问题,导致数据出现NaN(Not a Number)。让我来解释问题所在:
你尝试创建一个DataFrame,其中包含两列(“col1"和"col2”),并且给定了index参数来指定行的索引,索引为[“a”, “b”]。但是,问题在于,你的数据中包含的是pd.Series对象,并且这两个Series对象的索引与你的DataFrame的索引不匹配。
默认情况下,pandas会根据索引来对齐数据。由于你的两个Series对象没有与DataFrame索引[“a”, “b”]匹配的索引标签,所以在对齐数据时,会导致所有值都变成NaN。
要解决这个问题,你可以通过确保你的pd.Series对象具有与DataFrame索引匹配的索引标签,或者使用NumPy数组等其他数据结构来创建DataFrame。以下是两种可能的解决方法:
- 确保索引匹配:
import pandas as pddata = {"col1": pd.Series([1, 3], index=["a", "b"]),"col2": pd.Series([2, 4], index=["a", "b"])}df = pd.DataFrame(data)
print(df)
- 使用NumPy数组创建DataFrame:
import pandas as pd
import numpy as npdata = {"col1": np.array([1, 3]),"col2": np.array([2, 4])}df = pd.DataFrame(data, index=["a", "b"])
print(df)
这样,你将能够创建一个包含正确数据的DataFrame,而不会出现NaN值。
选取数据
我们先准备一个DataFrame
import pandas as pd
import numpy as np
data=np.arange(-12,12).reshape(6,4)
a=pd.DataFrame(data,index=list("abcdef"),columns=list("ABCD"))
print(a)

选Column
看到了上面这份数据后,我们发现,DataFrame 会分 Column 和 Row(index)。如果你搞机器学习,通常我们的 Column 是特征,Row 是数据样本, 在要对某个特征进行分析的时候,比如要做特征数值分布的分析,我们得把特征取出来吧。 那么你可以这么做。
#选取一个特征
print(a["B"])#选取多个特征
print("选取多个特征","\n",a[["B","C"]])

loc(通过自定义的序号索引)
# loc选择指定行和列
print(a.loc["a":"c","B":"C"])
# loc选定指定行所有内容
print(a.loc[["a","c"],:])

iloc(通过默认的序号索引)
# iloc选择指定行列
print(a.iloc[2:3,1:3])#iloc选择指定行所有内容
print(a.iloc[[3,1],:])

loc和iloc混搭
有时候,我们需要混搭 loc 和 iloc 的方式,比如我想要选取第 2 到第 4 位数据的 A C 两个特征,采用索引转换的方式,比如我在 .loc 模式下,将序号索引转换成 .loc 的标签索引。
# 转换成loc,即把索引都转成默认数字索引
row_labels=a.index[2:4]
print(row_labels)
print(a.loc[row_labels,["A","C"]])col_labels = a.columns[[0, 3]]
print(col_labels)
print(a.loc[row_labels,col_labels])# 转换成iloc,即把索引都转成自定义的索引
col_index=a.columns.get_indexer(col_labels)
print(col_index)
row_index=a.index.get_indexer(row_labels)
print(row_index)
print(a.iloc[row_index,col_index])

条件过滤筛选
选在 A Column 中小于 0 的那些数据
print(a["A"]<0)
print(a[a["A"]<0])

选在第一行数据不小于 -10 的数据
print(a.loc[:,~(a.iloc[0]<-10)])
#等价于
print(a.loc[:,a.iloc[0]>=-10])

选在第一行数据不小于 -10 或小于 -11 的数据
i0=a.iloc[0]
print(i0)
print(a.loc[:,~(i0<-10)|(i0<-11)])

小插曲
print(a.iloc[:,~(a.iloc[0]<-10)])
如果用的是iloc,即上面这段代码执行时,就会报错
loc 的行索引可以接受布尔值,用于筛选行数据。当你传递一个布尔Series给 loc 的行索引时,它将返回满足条件为True的行。这是一种非常有用的功能,可以用来根据某些条件选择DataFrame中的行。
例如,假设你有一个DataFrame df,你可以使用布尔索引来选择满足某些条件的行,如下所示:
# 创建一个布尔Series,选择年龄大于30的行
condition = df['年龄'] > 30# 使用布尔索引选择满足条件的行
selected_rows = df.loc[condition]# 打印满足条件的行
print(selected_rows)
在上面的示例中,condition 是一个布尔Series,它选择了DataFrame中年龄大于30的行,然后通过 df.loc[condition] 来选择这些行。这将返回一个包含满足条件的行的新DataFrame。
所以,loc 的行索引可以接受布尔值,用于基于条件选择行。
iloc 通常不用于接受布尔值来选择行。它主要用于基于整数位置来选择数据,而不是基于条件或布尔值来选择数据。
如果你想使用布尔值来选择行,通常应该使用 loc。使用布尔索引和 loc 结合可以方便地根据条件筛选行数据,如我在前面的回答中所示。对于 iloc,通常使用整数索引或整数切片来选择行和列,而不是布尔值索引。
例如,以下是一个使用 iloc 来选择前三行的示例:
selected_rows = df.iloc[0:3, :]
在这个示例中,iloc 使用整数切片选择了前三行,而不是基于布尔条件选择。如果你想基于条件选择行,请使用 loc。
总而言之,loc的行索引可以用布尔值,但是iloc不可以,这也就是出错的原因
因为当我们执行这段代码时,会发现结果是布尔值
print(~(a.iloc[0]<-10))

Series和DataFrame类似
我们同样先建一个Series
list_data=list(range(-4,4))
a=pd.Series(list_data,index=list("abcdefgh"))
print(a)

#按照标签选择数据loc
print(a.loc["a":"c"])
print(a.loc[["a","b"]])
#按照index选择数据iloc
print(a.iloc[2:4])
print(a.iloc[[3,1]])
#iloc和loc混用
print(a.iloc[a.index.get_indexer(["a","b"])])
print(a.index.get_indexer(["a","b"]))
print(a.loc[a.index[[3,2]]])
print(a.index[[3,2]])
#按照条件过滤筛选
print(a.loc[a<-3])
print(a.loc[(a>-3)&(a<3)])
print(a.loc[(a<-3)|(a>2)])

统计展示
基础统计方法
数据
import pandas as pd
import numpy as np
data=np.array([[1.39, 1.77, None],[0.34, 1.91, -0.05],[0.34, 1.47, 1.22],[None, 0.27, -0.61]
])
a=pd.DataFrame(data,index=["r0","r1","r2","r3"],columns=["c0","c1","c2"])
print(a)

快速总结
print(a.describe())
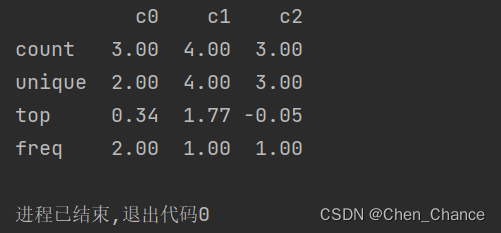
这里,会显示出来 count 计数(剔除掉 None 或者 NAN 这种无效数据),所以你在结果中能看到 c0,c2 两个的有效数是 3 个,而 c1 有效数有 4 个。
unique 表示的是每个 column 中有多少独特的数据。这个在初步感知数据丰富度上会有一定的作用。
top 表示出现最多的数据是哪一个,这组数据在 c0 column 处,我们能观察到 0.34 出现了两次,所以它选的 top 是 0.34,如果出现的数字概率相同,则选最先出现的数字
freq 是继续了 top,表述的是这个出现频率最多的数据,出现的次数有多少次。
上面这份数据还不是纯数据,如果是存数值型的数据,我们跑 describe() 还能看到统计学的信息。
a=pd.DataFrame(np.random.random((4,3)),columns=["c0","c1","c2"])
print(a)
print(a.describe())
创建了一个包含4行和3列的DataFrame,其中每个元素都是从0到1之间的随机数。然后,你使用 a.describe() 方法来生成关于这个DataFrame中数值列的统计摘要。以下是你的代码输出和结果的解释:
首先,创建了一个DataFrame a,它包含4行和3列的随机数。这是你的DataFrame的内容:
c0 c1 c2
0 0.412172 0.409382 0.289723
1 0.289591 0.943983 0.319834
2 0.834625 0.394380 0.121346
3 0.592600 0.340653 0.239218
接下来,使用 a.describe() 来生成统计摘要,结果如下:
c0 c1 c2
count 4.000000 4.000000 4.000000
mean 0.532997 0.522849 0.242030
std 0.229065 0.272370 0.102891
min 0.289591 0.340653 0.121346
25% 0.386007 0.389205 0.221967
50% 0.502386 0.401881 0.264471
75% 0.649376 0.535525 0.284533
max 0.834625 0.943983 0.319834
解释每一行统计信息:
count表示每列的非缺失值数量,由于这是随机生成的数据,因此每列都有4个非缺失值。mean表示每列的平均值。例如,‘c0’ 列的平均值约为0.533。std表示每列的标准差,衡量数据的离散程度。例如,‘c1’ 列的标准差约为0.272。min和max分别表示每列的最小值和最大值,即数据范围。25%、50%和75%分别表示第25、50和75百分位数,它们对应于数据的第一四分位数、中位数和第三四分位数。这些百分位数可用于了解数据的分布。
均值中位数
累加累乘
最大最小
处理空值
获取索引