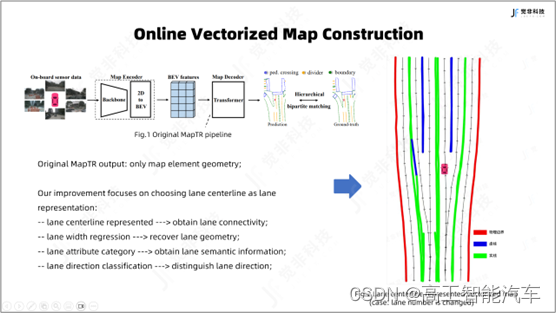
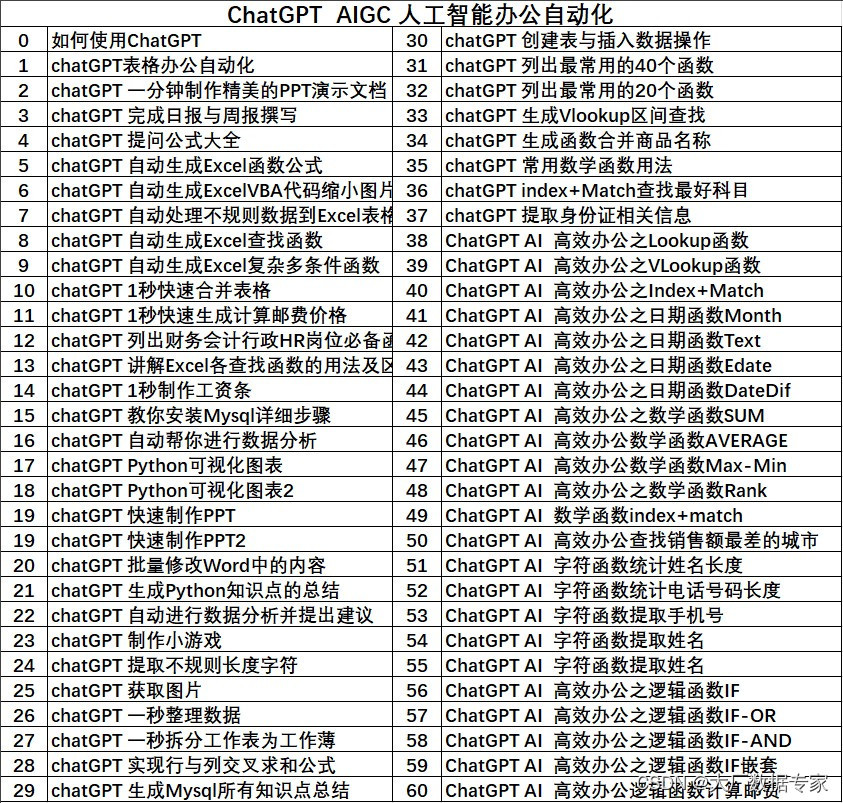
一、 TCP协议格式
![]() TCP如何将报头与有效载荷进行分离?
TCP如何将报头与有效载荷进行分离?
![]() 当TCP从底层获取到一个报文后,虽然TCP不知道报头的具体长度,但报文的前20个字节是TCP的基本报头,并且这20字节当中涵盖了4位的首部长度。
当TCP从底层获取到一个报文后,虽然TCP不知道报头的具体长度,但报文的前20个字节是TCP的基本报头,并且这20字节当中涵盖了4位的首部长度。
因此TCP是这样分离报头与有效载荷的:
1) 当TCP获取到一个报文后,首先读取报文的前20个字节,并从中提取出4位的首部长度,此时便获得了TCP报头的大小size。
2)如size的值大于20字节,则需要继续从报文当中读取s i z e − 20 size-20size−20字节的数据,这部分数据就是TCP报头当中的选项字段。
3)读取完TCP的基本报头和选项字段后,剩下的就是有效载荷了。
需要注意的是,TCP报头当中的4位首部长度描述的基本单位是4字节,这也恰好是报文的宽度。4为首部长度的取值范围是0000 ~ 1111,因此TCP报头最大长度为15 × 4 = 60 字节,因为基本报头的长度是20字节,所以报头中选项字段的长度最多是40字节。
如果TCP报头当中不携带选项字段,那么TCP报头的长度就是20字节,此时报头当中的4位首部长度的值就为20 ÷ 4 = 5,转为二进制也就是0101
1. 序号和确认序号
确认序号表示序号对应的数字,确认序号被设置表示之前所有的报文都一斤全部收到了,告诉对方下次从确认序号知名的序号开始发送。(往往给对方发送消息就是应答)
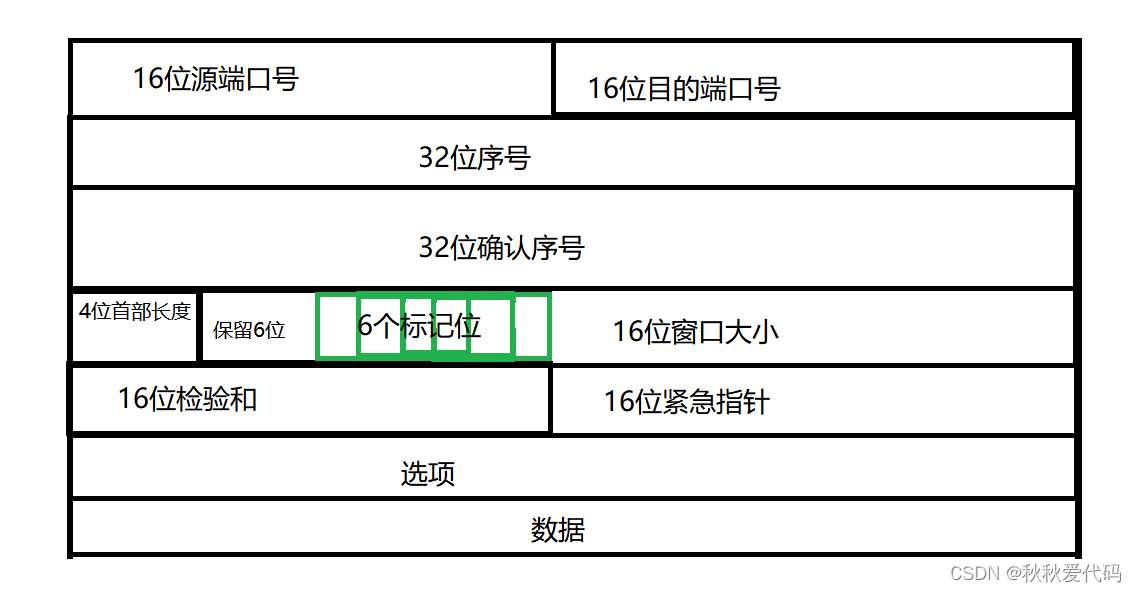
![]() client依次可能会向服务器发送多个报文,就有一个问题:发送顺序和接受顺序不同(数据包乱序问题),client如何确认那个应答对应那个发送嘞?
client依次可能会向服务器发送多个报文,就有一个问题:发送顺序和接受顺序不同(数据包乱序问题),client如何确认那个应答对应那个发送嘞?
![]() 序号和确认序号的作用就在此很好的发挥了,首先 序号和确认序号可以将请求和应答一 一对应,收到的报文如果是乱序的,可以对序号进行排序(解决乱序问题),其次 确认序号表示序号确认之前的序号全部收到,也就允许部分确认丢失是或者不给应答。
序号和确认序号的作用就在此很好的发挥了,首先 序号和确认序号可以将请求和应答一 一对应,收到的报文如果是乱序的,可以对序号进行排序(解决乱序问题),其次 确认序号表示序号确认之前的序号全部收到,也就允许部分确认丢失是或者不给应答。
![]() 既然给对方发送信息本身就是一种应答,为什么要有两个字段?
既然给对方发送信息本身就是一种应答,为什么要有两个字段?
![]() 因为TCP是全双工的,任何一方技能发送也能接收,所以必须要有两个字段将他们区分开。
因为TCP是全双工的,任何一方技能发送也能接收,所以必须要有两个字段将他们区分开。
2. TCP报头的6个标志位
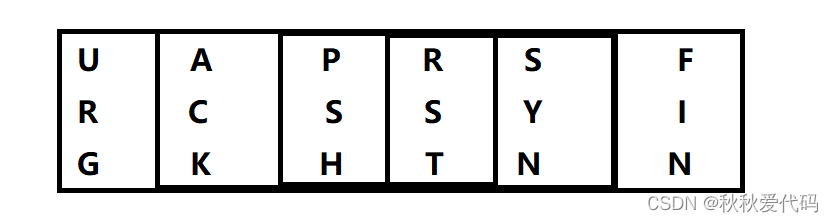 SYN 连接请求标志位
SYN 连接请求标志位
报文当中的SYN被设置为1,表明该报文是一个连接建立的请求报文。
只有在连接建立阶段,SYN才被设置,正常通信时SYN不会被设置。
ACK 报文当中的ACK被设置为1,表明该报文可以对收到的报文进行确认。
一般除了第一个请求报文没有设置ACK以外,其余报文基本都会设置ACK,因为发送出去的数据本身就对对方发送过来的数据具有一定的确认能力,因此双方在进行数据通信时,可以顺便对对方上一次发送的数据进行响应。
FIN 连接断开请求标志位
报文当中的FIN被设置为1,表明该报文是一个连接断开的请求报文。
只有在断开连接阶段,FIN才被设置,正常通信时FIN不会被设置。
URG 紧急标志位,配合16位紧急指针使用
双方在进行网络通信的时候,由于TCP是保证数据按序到达的,即便发送端将要发送的数据分成了若干个TCP报文进行发送,最终到达接收端时这些数据也都是有序的,因为TCP可以通过序号来对这些TCP报文进行顺序重排,最终就能保证数据到达对端接收缓冲区中时是有序的。
TCP按序到达本身也是我们的目的,此时对端上层在从接收缓冲区读取数据时也必须是按顺序读取的。但是有时候发送端可能发送了一些“紧急数据”,这些数据需要让对方上层提取进行读取,此时应该怎么办呢?
此时就需要用到URG标志位,以及TCP报头当中的16位紧急指针。
当URG标志位被设置为1时,需要通过TCP报头当中的16位紧急指针来找到紧急数据,否则一般情况下不需要关注TCP报头当中的16位紧急指针。
16位紧急指针代表的就是紧急数据在报文中的偏移量。
因为紧急指针只有一个,它只能标识数据段中的一个位置,因此紧急数据只能发送一个字节
PSH 督促对方尽快将你的接收缓冲区当中的数据交付给上层。
我们一般认为:
当使用read/recv从缓冲区当中读取数据时,如果缓冲区当中有数据read/recv函数就能够读到数据进行返回,而如果缓冲区当中没有数据,那么此时read/recv函数就会阻塞住,直到当缓冲区当中有数据时才会读取到数据进行返回。
实际这种说法是不太准确的,其实接收缓冲区和发送缓冲区都有一个水位线的概念。
比如我们假设TCP接收缓冲区的水位线是100字节,那么只有当接收缓冲区当中有100字节时才让read/recv函数读取这100字节的数据进行返回。
如果接收缓冲区当中有一点数据就让read/recv函数读取返回了,此时read/recv就会频繁的进行读取和返回,进而影响读取数据的效率(在内核态和用户态之间切换也是有成本的)。
因此不是说接收缓冲区当中只要有数据,调用read/recv函数时就能读取到数据进行返回,而是当缓冲区当中的数据量达到一定量时才能进行读取。
当报文当中的PSH被设置为1时,实际就是在告知对方操作系统,尽快将接收缓冲区当中的数据交付给上层,尽管接收缓冲区当中的数据还没到达所指定的水位线。这也就是为什么我们使用read/recv函数读取数据时,期望读取的字节数和实际读取的字节数是不一定吻合的。
RST 要求重新连接的标志位
在通信双方在连接未建立好的情况下,一方向另一方发数据,此时另一方发送的响应报文当中的RST标志位就会被置1,表示要求对方重新建立连接。
在双方建立好连接进行正常通信时,如果通信中途发现之前建立好的连接出现了异常也会要求重新建立连接。
3. 3次握手和4次挥手
![]() (1)什么是链接
(1)什么是链接

因为有大量client将来可能会连接server,所以server端一定有大量的连接,OS将这些连接管理起来,先对这些连接的共性和差异进行描述刻画,再将他们通过一定的结构组织起来。
所谓的连接,本质是内核中的一种数据结构类型,建立连接成功的时候,内存中会创建对应的连接对象,在对对象进行某种数据结构的组织。
==》维护连接实惠消耗CPU和内存资源的!!!
(2)如何理解3次握手
 为什么要三次握手?不可以是一次,两次吗?
为什么要三次握手?不可以是一次,两次吗?
![]() 1.奇数次连接可以保证server端 嫁接同等程度的成本给client端,(避免大量的SYN洪水造成server端不能正常工作);
1.奇数次连接可以保证server端 嫁接同等程度的成本给client端,(避免大量的SYN洪水造成server端不能正常工作);
2.可以很好的验证全双工。
分析如图:

建立连接一定能成功吗?
![]() 如图,第三次的ACK是可能会丢失的,所以三次握手不一定保证成功,这就会涉及到之前提到的 RST和PSH 标志位了。
如图,第三次的ACK是可能会丢失的,所以三次握手不一定保证成功,这就会涉及到之前提到的 RST和PSH 标志位了。
(3)如何理解4次挥手
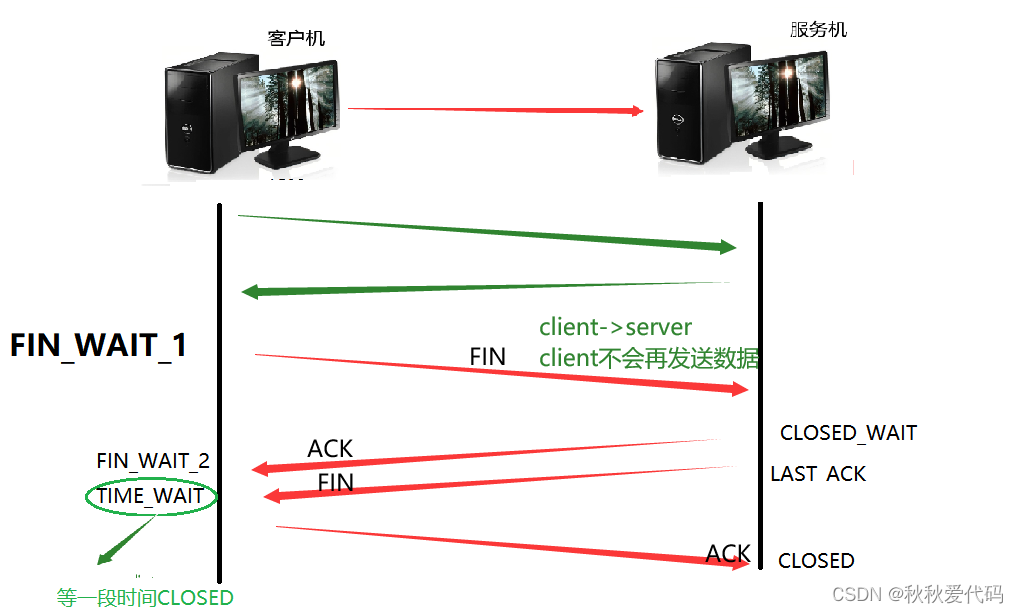
TIME_WAIT状态下,虽然4次挥手已经完成,但是主动断开连接的一方要维持一段时间(2MSL 最大报文生存时间,保证数据在网络中消散)的TIME_WAIT,在该状态下,连接实际已经断开但是地址信息,ip,port依旧是被占用的,此时就可能出现bind失败的情况。
![]() 如果我们发现服务器具有大量的CLOSE_WAIT状态的连接,原因是什么呢?
如果我们发现服务器具有大量的CLOSE_WAIT状态的连接,原因是什么呢?
![]() 应用层的服务端写的有bug,忘记关闭对应连接的sockfd。必须主动将不需要的文件描述符关闭
应用层的服务端写的有bug,忘记关闭对应连接的sockfd。必须主动将不需要的文件描述符关闭