继续,书接上回,这次我通过jsrpc,也学会了不少逆向的知识,感觉对于一般的网站应该都能应付了。当然我说的是简单的网站,遇到那些混淆的,还有那种猿人学里面的题目,还是免谈了。那种需要的水平太高,我学习爬虫的目的也不是找什么工作,只是为了找数据,能够满足我找数据的需要就好。
现在我的初步问题已经解决了,原以为可以使用jsrpc一路搜集数据。可是还是遇到了新的问题。
接下来我想搜集这个网站的志愿服务项目的数据。发现这个网站的请求类型也比较复杂,要抓到某一个项目的数据,需要多次点击,定位到那个项目,而且进入项目的新页面,好像jsrpc获得的参数也是没什么用的了。
不知道为什么。可以先看一下。
这时,我知道这个query应该是也带bean参数。
那么再次截获它的i值,就可以使用rpc,获得bean参数吧,想着时这样的。

这个query,地址是:/webapi/listProjectsFortisWeb/query
那么我们就找这个请求时的i

i值有了,可以直接请求了吧。但是结果令人失望

得到的结果一直是固定的那么几个东西。即使换了i,换了参数,也会得到同样的结果。我也不太明白为什么。可能是网站需要经过几次鼠标点击,在点击的过程中,请求变了,我使用python请求,并没有抓到他那个真实的请求。
过程太复杂,我想我也研究不出来,比不了那些搞网站的。所以眼看又进入了困境。
这时候,想到了selenim。虽然一直以来都觉得selenium慢的要死。但是没办法啊,我会的,能够用的都用的差不多了,不会的也学了,学的也快吐了。不想再继续搞下去了,想着selenium慢就慢吧,好歹也是个办法。
browsermobproxy的使用
说干就干, 但是还有一个问题,就是我怎么能让senenium返回给我一个json,也就是一个动态网站返回给我的东西,我怎么截取这个json。selenium一旦渲染出来,就是一个网页元素了。怎么抓取到服务器发给我的json呢。
这时候看到知乎上一个帖子介绍了browsermobproxy。感觉可以用,就试了一下。
确实可以。简单来说,这个库就是相当于一个python版的fiddler,只不过fiddler是集成在一个软件里面,python调用不方便。但是这个库直接安装到python里面就可以了。简单
直接pip install就可以。
然后我也放弃了使用rpc方法,直接使用python模拟鼠标点击。

简单粗暴。就是慢点。
直接上代码,
import json
import os
import requests
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from browsermobproxy import Server
from selenium.webdriver.chrome.options import Options
import timeserver = Server(r'E:\code\codeForArticle2023\sdzyfw2\sdzyfw2.0\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat')
server.start()
proxy = server.create_proxy()
print(proxy.proxy)
proxy.new_har("my_baidu", options={"captureHeaders": True, "captureContent":True})chrome_options = Options()
chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))
chrome_options.add_argument('--ignore-certificate-errors')
chrome_options.add_experimental_option("excludeSwitches", ["ignore-certificate-errors"])driver = webdriver.Chrome(executable_path=r'venv/Scripts/chromedriver-win64/chromedriver.exe', options=chrome_options)
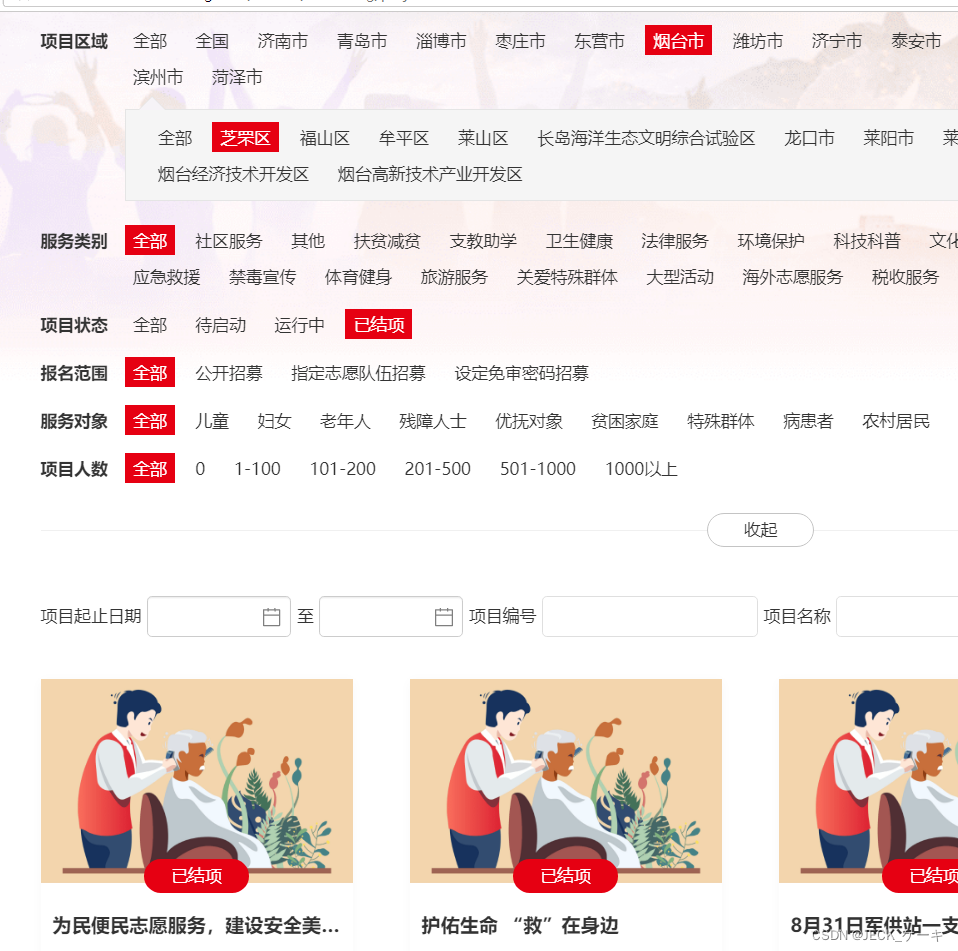
driver.get("http://sd.chinavolunteer.mca.gov.cn/subsite/shandong/project")ele = WebDriverWait(driver, 10, 0.2).until(EC.visibility_of_element_located((By.XPATH, u'//div//a[text()="烟台市"]')), u'没有发现内容')
item = driver.find_element_by_xpath("//div//a[text()='烟台市']")
item.click()ele = WebDriverWait(driver, 10, 0.2).until(EC.visibility_of_element_located((By.XPATH, u'//div//a[text()="芝罘区"]')), u'没有发现内容')
item2 = driver.find_element_by_xpath("//a[text()='芝罘区']")
item2.click()ele = WebDriverWait(driver, 10, 0.2).until(EC.visibility_of_element_located((By.XPATH, u'//div//a[text()="已结项"]')), u'没有发现内容')
item3 = driver.find_element_by_xpath("//a[text()='已结项']")
item3.click()try:WebDriverWait(driver, 10).until(EC.presence_of_element_located(By.CSS_SELECTOR, "div.panel-card"))except Exception as e:doNthing = e# ele = WebDriverWait(driver, 10, 0.2).until(EC.visibility_of_element_located((By.XPATH, u'//div//a[text()="已结项"]')), u'没有发现内容')
panels = driver.find_elements_by_css_selector(".panel-card")
p1 = panels[0]link = p1.find_element_by_css_selector('h2')
link.click()win_hans = driver.window_handles
driver.switch_to.window(win_hans[-1])shijian = driver.find_element_by_xpath("//span[text()='时长公示']")
shijian.click()table = driver.find_element_by_xpath("//table[@class='table-list']")
trs = table.find_elements_by_xpath('//tbody//tr')
len(trs)if len(trs) == 13:page = driver.find_element_by_xpath("//a[text()='下一页']")page.textpage.click()
else:pass# driver.close()result = proxy.harwith open("sdzyfw2/sdzyfw2.0/har_all.json", 'w', encoding='utf-8') as f:f.write(json.dumps(list1, ensure_ascii=False))
# print(str(result))list1 =[]
for rs in result['log']['entries']:if "china" in rs['request']['url']:if "chinavolunteer" in rs['request']['url']:print(rs['request']['url'])# response = rs['response']list1.append(rs)with open("sdzyfw2/sdzyfw2.0/har.json", 'w', encoding='utf-8') as f:f.write(json.dumps(list1, ensure_ascii=False))代码也没怎么整理,大致的意思就是使用selenium呼出浏览器,然后在浏览器里面一步步找到我想要的东西,最后把这些所有的包存放到一个har里面。后期在筛选har,提取我想要的信息。
发现这个也是很无敌的,直接免去了反反爬措施。因为就是浏览器,除非网站对webdriver有检测,不然也没办法。就老老实实的一个一个爬吧。