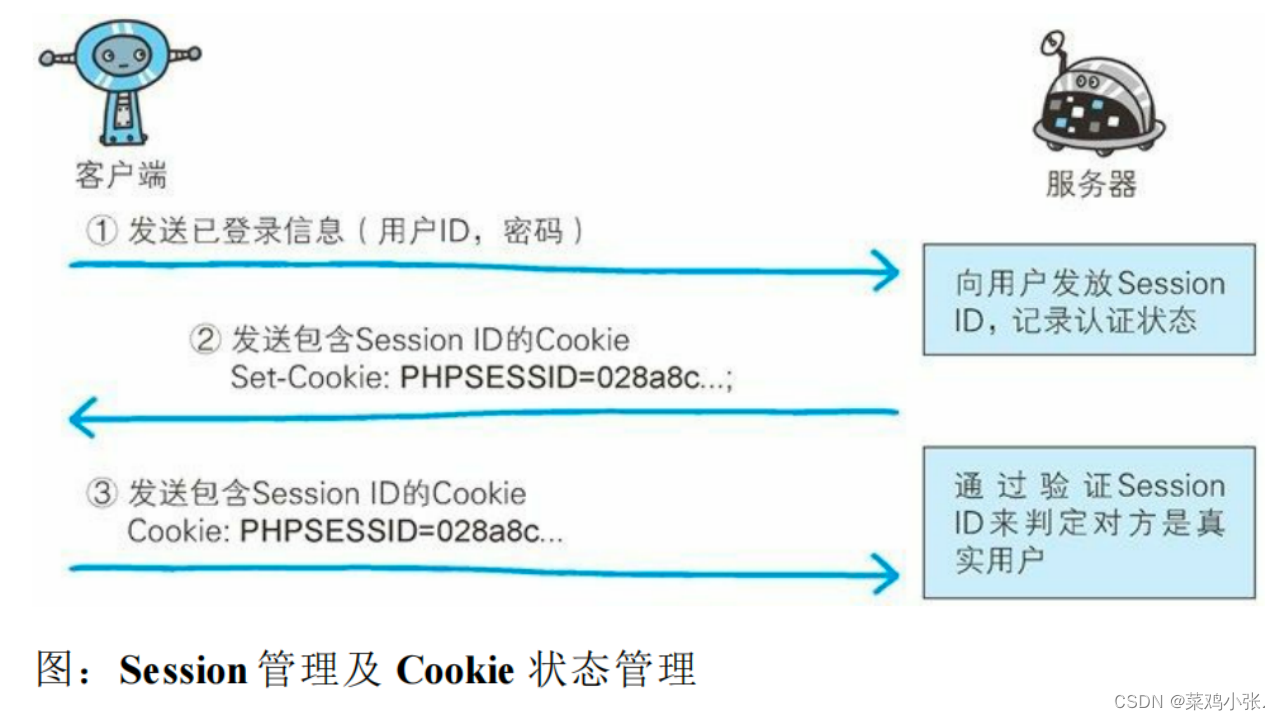
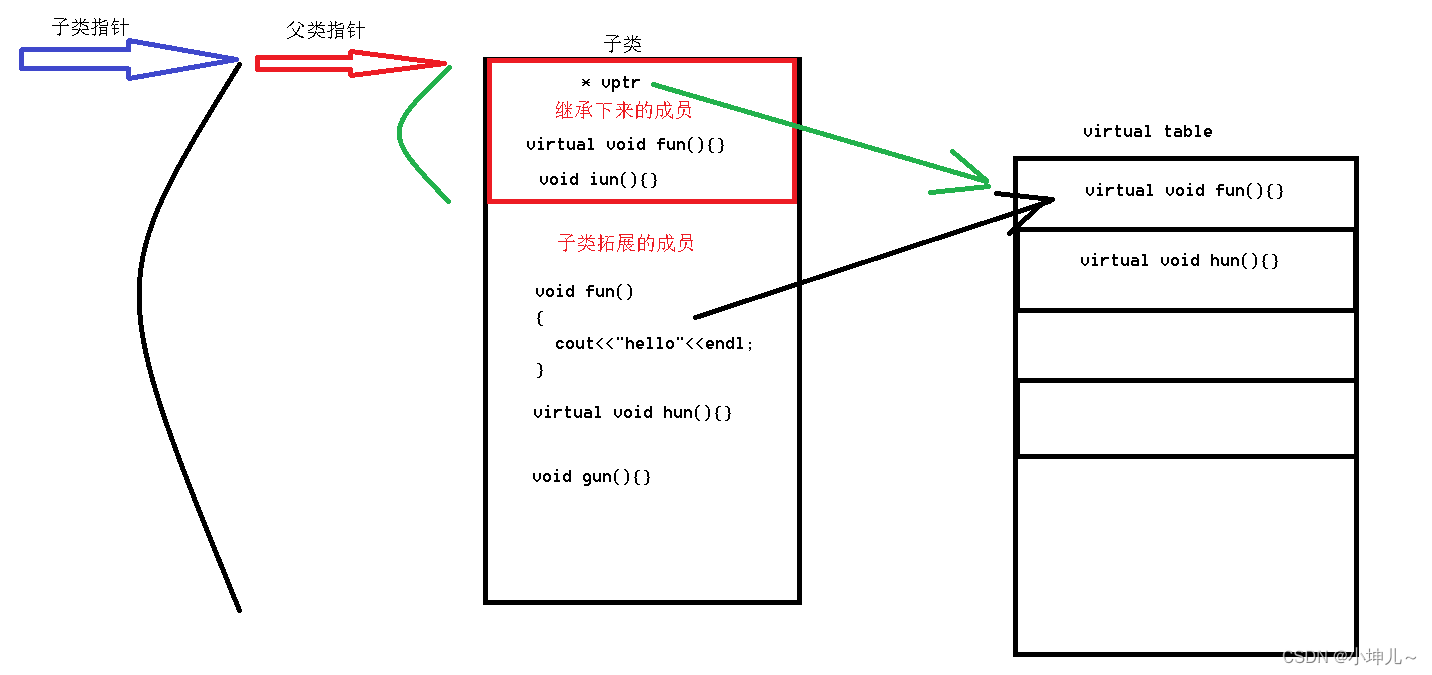
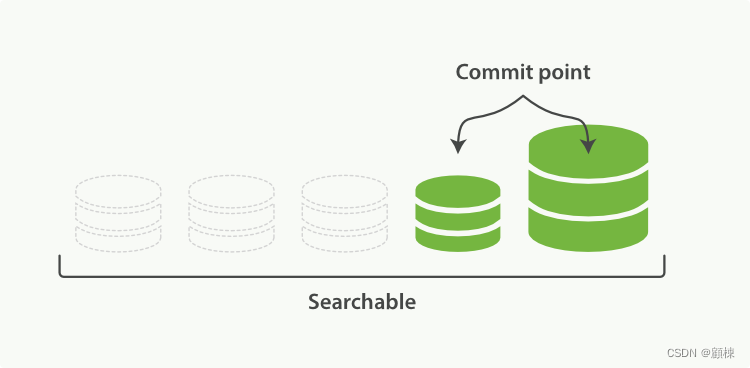
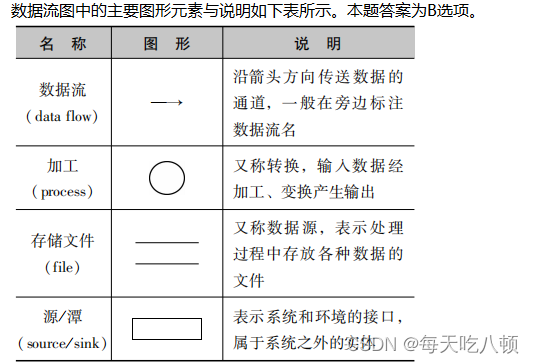
我一直坚持一个观点,即并非所有基于向量的解决方案都应被统称为向量数据库,尽管它们的能力在某些方面可以与之匹敌。从我的观点来看,例如 pgvector 或 Elasticsearch,它们都是非常出色且成熟的产品,在特定场景下,确实可以很好地满足用户需求。

在数据量很小的情况下,使用 Elasticsearch,结合标量检索,已经足以满足业务场景。或者,如果你的原始数据完全存储在关系型数据库,然后基于 pgvector 操作去进行几十万甚至 100 万数据的搜索,这样也是完全可行的。但是一旦数据量变大,你会发现很多业务场景会受到传统数据库设计的限制,无法很好地扩展。
实际上,在讨论向量数据库提供哪些能力时,我认为有几个关键点无法回避,包括算法、算力和调度。作为一个向量数据库,这几个方面都需要经过特殊设计。

我一直提到的一个例子是,如果你只想进行近邻检索,你完全可以写个 ANN,也许只需要不到 10 行代码就能实现你所需的近邻检索功能。但是大家选择不这样做的原因,在很大程度上考虑了性能和成本因素。从这个角度看,一旦性能、成本和可扩展性对你至关重要,许多传统的数据库可能无法满足需求了。