使用Langchain+GPT+向量数据库chromadb 来创建文档对话机器人
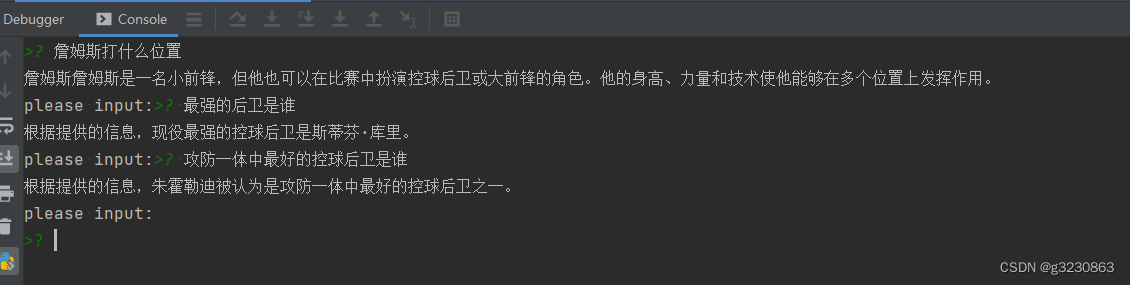
一.效果图如下:
二.安装包
pip install langchainpip install chromadbpip install unstructuredpip install jieba
三.代码如下
#!/usr/bin/python
# -*- coding: UTF-8 -*-import os # 导入os模块,用于操作系统相关的操作import chromadb
import jieba as jb # 导入结巴分词库
from langchain.chains import ConversationalRetrievalChain # 导入用于创建对话检索链的类
from langchain.chat_models import ChatOpenAI # 导入用于创建ChatOpenAI对象的类
from langchain.document_loaders import DirectoryLoader # 导入用于加载文件的类
from langchain.embeddings import OpenAIEmbeddings # 导入用于创建词向量嵌入的类
from langchain.text_splitter import TokenTextSplitter # 导入用于分割文档的类
from langchain.vectorstores import Chroma # 导入用于创建向量数据库的类import os
os.environ["OPENAI_API_KEY"] = 'xxxxxx'# 初始化函数,用于处理输入的文档
def init():files = ['2023NBA.txt'] # 需要处理的文件列表cur_dir = '/'.join(os.path.abspath(__file__).split('/')[:-1])for file in files: # 遍历每个文件data_path = os.path.join(cur_dir, f'data/{file}')with open(data_path, 'r', encoding='utf-8') as f: # 以读模式打开文件data = f.read() # 读取文件内容cut_data = " ".join([w for w in list(jb.cut(data))]) # 对读取的文件内容进行分词处理cut_file =os.path.join(cur_dir, f"data/cut/cut_{file}")with open(cut_file, 'w',encoding='utf-8') as f: # 以写模式打开文件f.write(cut_data) # 将处理后的内容写入文件# 新建一个函数用于加载文档
def load_documents(directory):# 创建DirectoryLoader对象,用于加载指定文件夹内的所有.txt文件loader = DirectoryLoader(directory, glob='**/*.txt')docs = loader.load() # 加载文件return docs # 返回加载的文档# 新建一个函数用于分割文档
def split_documents(docs):# 创建TokenTextSplitter对象,用于分割文档text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)docs_texts = text_splitter.split_documents(docs) # 分割加载的文本return docs_texts # 返回分割后的文本# 新建一个函数用于创建词嵌入
def create_embeddings(api_key):# 创建OpenAIEmbeddings对象,用于获取OpenAI的词向量embeddings = OpenAIEmbeddings(openai_api_key=api_key)return embeddings # 返回创建的词嵌入# 新建一个函数用于创建向量数据库
def create_chroma(docs_texts, embeddings, persist_directory):new_client = chromadb.EphemeralClient()vectordb = Chroma.from_documents(docs_texts, embeddings, client=new_client, collection_name="openai_collection")return vectordb # 返回创建的向量数据库# load函数,调用上面定义的具有各个职责的函数 pip install unstructured
def load():docs = load_documents('data/cut') # 调用load_documents函数加载文档docs_texts = split_documents(docs) # 调用split_documents函数分割文档api_key = os.environ.get('OPENAI_API_KEY') # 从环境变量中获取OpenAI的API密钥embeddings = create_embeddings(api_key) # 调用create_embeddings函数创建词嵌入# 调用create_chroma函数创建向量数据库vectordb = create_chroma(docs_texts, embeddings, 'data/cut/')# 创建ChatOpenAI对象,用于进行聊天对话openai_ojb = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")# 从模型和向量检索器创建ConversationalRetrievalChain对象chain = ConversationalRetrievalChain.from_llm(openai_ojb, vectordb.as_retriever())return chain # 返回该对象init()
# 调用load函数,获取ConversationalRetrievalChain对象
# pip install chromadb
# pip install unstructured
# pip install jieba
chain = load()# 定义一个函数,根据输入的问题获取答案
def get_ans(question):chat_history = [] # 初始化聊天历史为空列表result = chain({ # 调用chain对象获取聊天结果'chat_history': chat_history, # 传入聊天历史'question': question, # 传入问题})return result['answer'] # 返回获取的答案if __name__ == '__main__': # 如果此脚本作为主程序运行s = input('please input:') # 获取用户输入while s != 'exit': # 如果用户输入的不是'exit'ans = get_ans(s) # 调用get_ans函数获取答案print(ans) # 打印答案s = input('please input:') # 获取用户输入
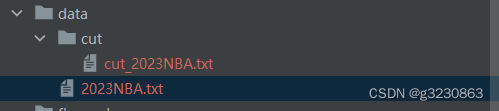
文件存放地址

参考:
https://python.langchain.com/docs/use_cases/chatbots
https://python.langchain.com/docs/integrations/vectorstores/chroma
https://blog.csdn.net/v_JULY_v/article/details/131552592?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522169450205816800226590967%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=169450205816800226590967&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-131552592-null-null.142v93chatsearchT3_2&utm_term=langchain&spm=1018.2226.3001.4449


![[npm]package.json文件](https://img-blog.csdnimg.cn/ba0ff41b041446bd9abcd40b81ea59d4.png)