1、讲一下你最熟悉的模块是怎么测试的?
2、fiddler如何抓https请求?
步骤:
设置浏览器http代理
安装证书
导入证书,端口号8888
手机端获取fiddler的地址,配置无线局域网代理,安装手机证书。
3、jmeter如何参数化
(1)用户定义的变量
添加一个线程组----添加一个配置元件—用户定义的变量。
填写好变量名如注册、登录、充值,然后在他们各自的请求中进行参数化引用��ip{phone}。
点击运行,查看结果树
(2)函数助手获取参数值
打开函数助手对话框,找到__RandomString,10个用户注册的话,假设前三位固定,后八位随机。
设置字符串长度,取值范围,参数名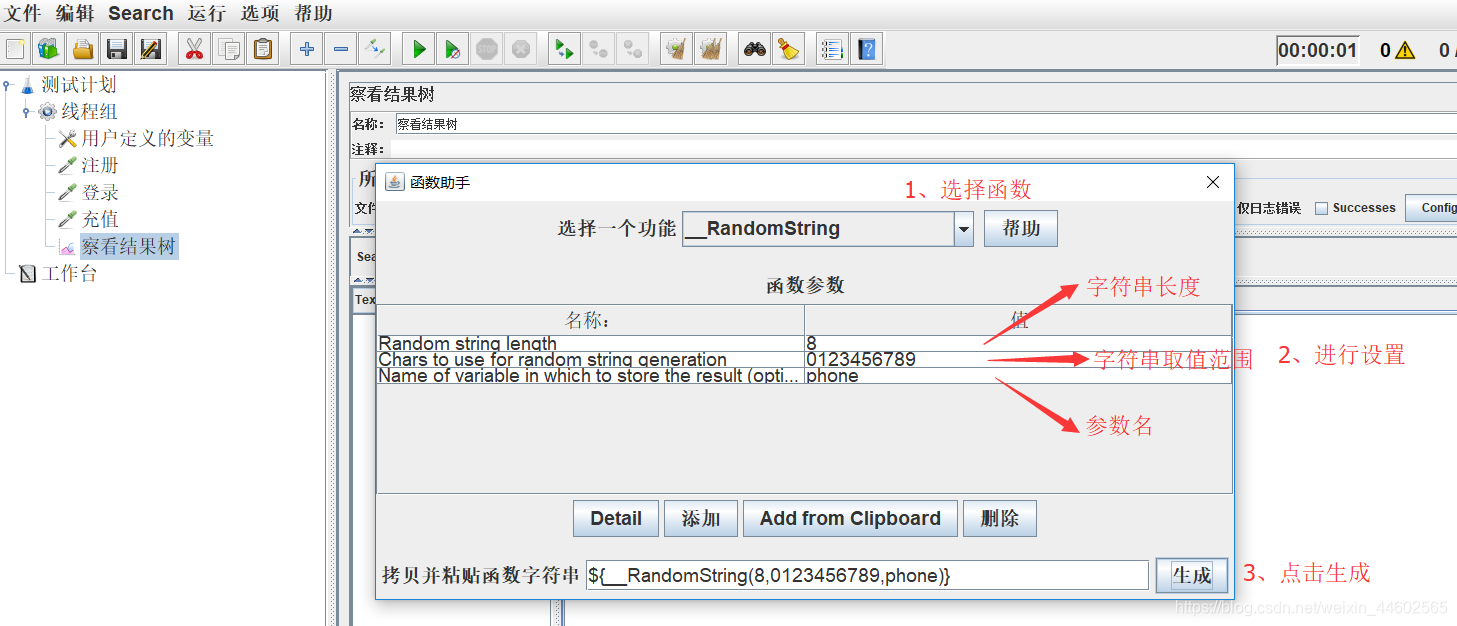
拷贝生成的字符串进行参数引用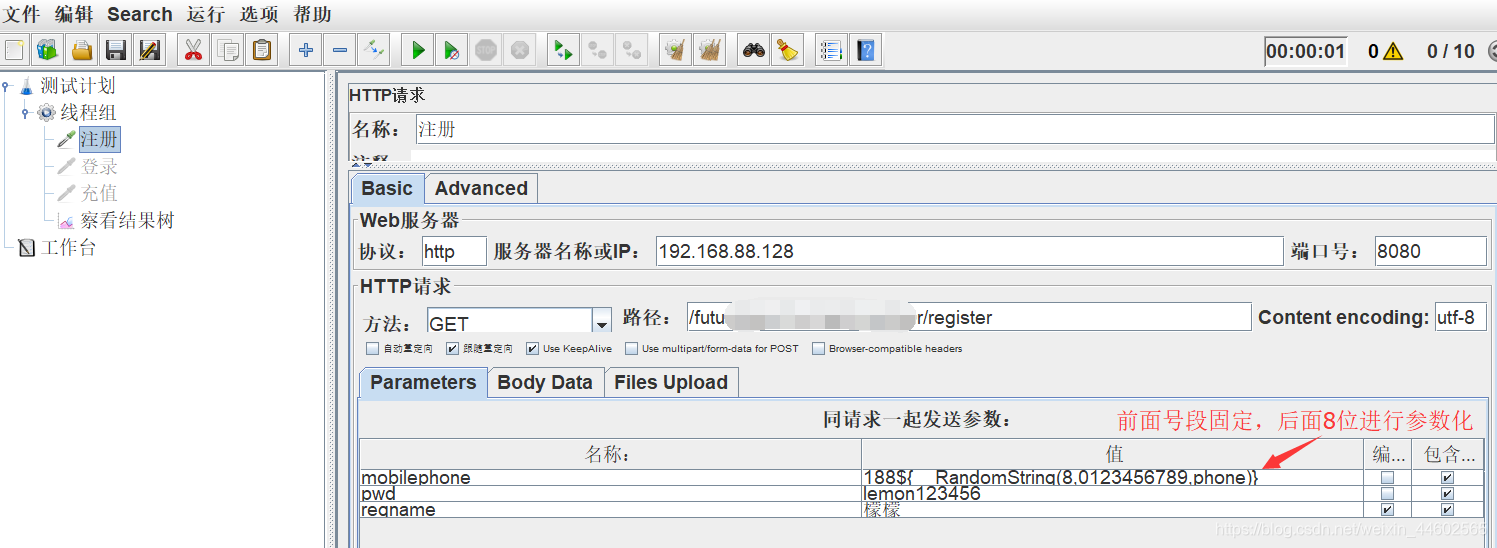
设置线程数为10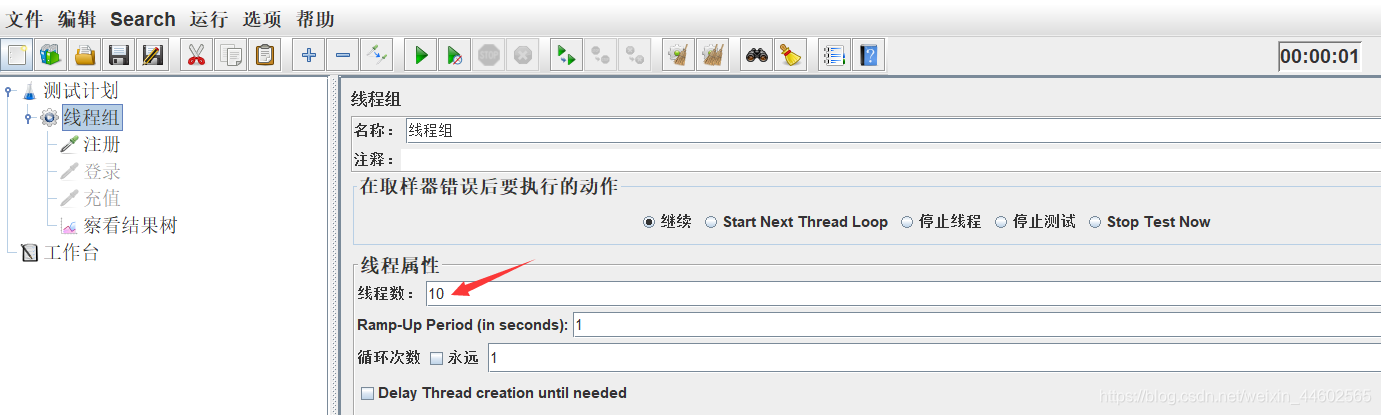
(3)CSV Data Set Config获取参数值
将用户的手机号名字提前存到txt里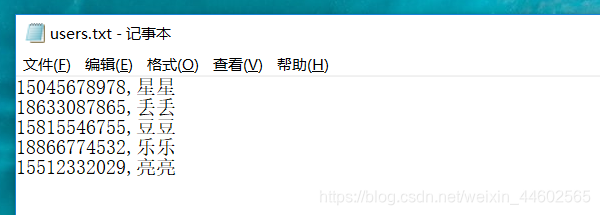
线程组右键添加–>配置元件–>CSV Data Set Config
直接参数化引用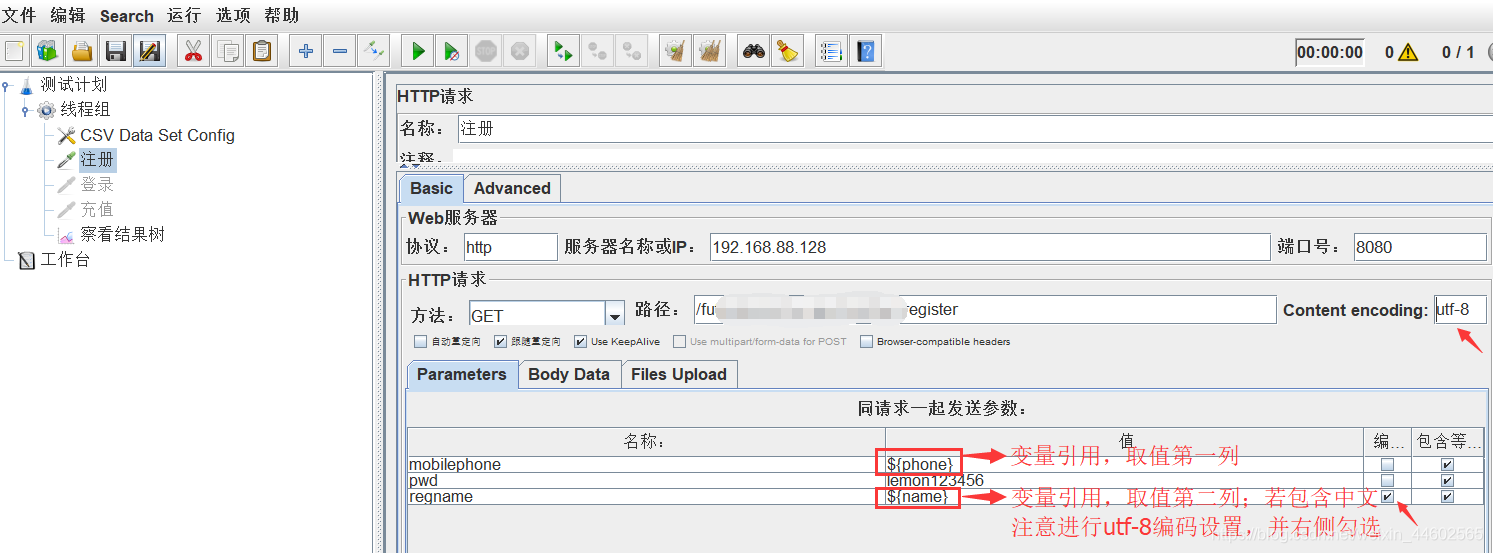
通过函数助手进行参数化引用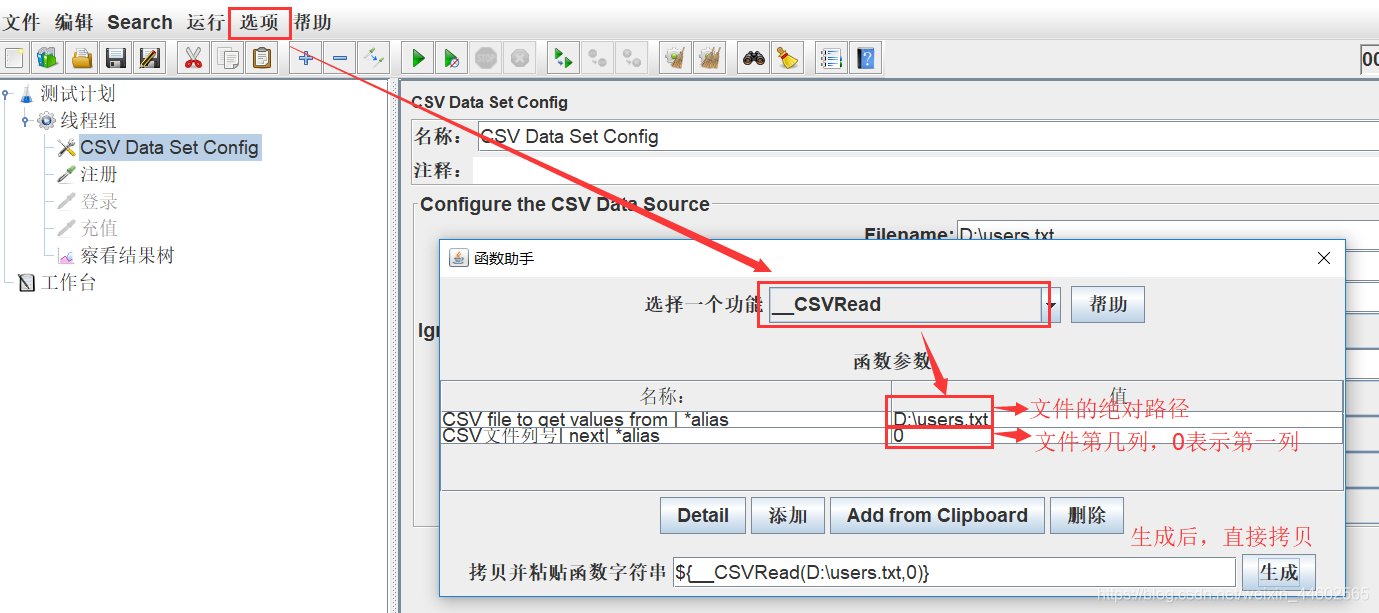

4、jmeter如何关联测试?
5、
开发觉得是BUG,你觉得不是?
一般这种问题会有两种情况,一种是体验性的bug,需求上确实没有提出,去找产品进行确认,是遗留还是本次迭代改掉,二是代码优化上面的问题,比如获取短信验证码,每次都需要30秒以上,这时候我认为是我们的程序代码存在问题。如果开发不承认是一个bug。那么我会去找相似的竞品体验时间,如果大部分竞品是1-2秒,那么我们的代码确实是有问题,影响用户
6、、 如何区分前后端BUG?
通过请求和响应来判断。前端数据发送到了后端,后端收到了请求,没有返回数据,就是后端除了问题。前端在用户输入数据的时候,没有携带数据就是前端的问题。或者说后端给了数据前端没有显示,也是前端的问题。
7、自动化回归测试怎么实现的?
好的面试官,自动化的话在这几个项目中还是有涉及到的,尤其是关于冒烟测试的脚本都是我自己开发的。在项目中呢,我就利用了python+selenium,利用了pageobject这种的对象模型,进行了自动化脚本测试的开发。这样冒烟跑通了的话,我就进行深度测试。一般来讲我的设计的方法就是先把当时冒烟测试设计的用例,利用自动化脚本实现。脚本框架结构就是现在比较流行的po模型,pageobgect模型,把一些公共的基础类,抽象成一个基类,其他的一些特殊的,属性啊,操作对象啊,我就把他作为子类。子类主要是调用主类的方法,测试数据我是把他做分离了。一般就是放到单独的目录文件结构里,在执行的时候去掉它。整体来讲,我用的是unitest方法,在我们的test环节把所有的用例都含进去。最终还调了个第三方的测试报告,testeoundner html这样一个东西把接口这些输出来。测试用例的话用excel进行一个管理,加载了一个openexcel这样一个函数模块去读取本地信息。然后我通过循环的方式逐个判断用例执行当时我是这么做的。
8、碰到的最大的困难是什么?
我们这个项目测试可能只有我一个人,然后每天都要进行一个冒烟测试,那么这样以来每天对我造成一个小时去做这个有点不划算,当时我就想看能不能把一些冒烟测试去做一个自动化,在实施过程中,我用的是python+selenium 的方式发现有些元素定位不是很方便,比方说xpath定位,就经常会遇到问题,后来就想了很多方法,怎么解决某一个元素定位的问题,这时候我发现这个元素是个多属类型的,属性差不多但是,有很多个,每次生成不同的数据导致xpath路径不一样。这时候我就利用的查找元素组的方式解决的
9、fiddler的中断方式(断点)
在请求开始时中断 bpu、在响应到达是中断 bpfter、在特定http状态码时中断 bps、在特定请求method是中断 bpv/bpm
10、该项目模块你是怎么测试的?
功能上讲功能点测试和业务流程测试,选一个功能点描述设计用例的思路。
兼容性、性能、可靠性



![[Linux入门]---搭建Linux环境](https://img-blog.csdnimg.cn/f939d4c14a184fc0b1a615cb1fe119f4.png)