想象一下,键入“戏剧性的介绍音乐”并听到一首飙升的交响乐,或者编写“令人毛骨悚然的脚步声”并获得高质量的音效。这是稳定音频的承诺,一个文本到音频的人工智能模型周三宣布由能合成立体声的稳定人工智能44.1千赫来自文字描述的音乐或声音。不久,类似的技术可能会挑战音乐家的工作。
如果你还记得的话,Stability AI是帮助投资创建稳定扩散,2022年8月发布的潜在扩散图像合成模型。该公司不满足于制作图像,还通过后台支持将业务扩展到了音频领域哈蒙奈,一个推出音乐生成器的人工智能实验室舞蹈扩散九月。
现在Stability和Harmonai想用稳定音频打入商业ai音频制作。由…判断生产样品,这似乎是一个重大的音频质量升级,从以前的人工智能音频发生器,我们已经看到了。
在其宣传页面上,Stability提供了人工智能模型的例子,并提供了“史诗预告片音乐,强烈的部落打击乐器和铜管乐器”和“lofi hip hop beat melody chill hop 85 BPM”等提示。它还提供了使用稳定音频生成的声音效果样本,如航空公司飞行员通过对讲机讲话和人们在繁忙的餐馆中交谈。
为了训练它的模型,稳定性与股票音乐提供商合作AudioSparx并授权了一个数据集“由超过800,000个音频文件组成,包含音乐、声音效果和单乐器词干,以及相应的文本元数据。”在将19,500小时的音频输入模型后,Stable Audio知道如何模仿它在命令下听到的某些声音,因为这些声音在其神经网络中与它们的文本描述相关联。
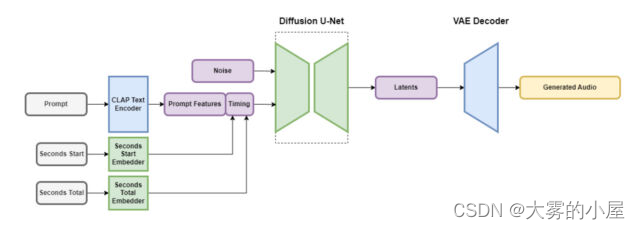
稳定音频包含几个部分,它们协同工作以快速创建自定音频。一部分以保留重要特征的方式缩小音频文件,同时去除不必要的噪音。这使得系统既能更快地进行教学,又能更快地创建新的音频。另一部分使用文本(音乐和声音的元数据描述)来帮助指导生成哪种音频。
为了加快速度,稳定音频架构对高度简化的压缩音频表示进行操作,以减少推理时间(机器学习模型在获得输入后生成输出所需的时间)。根据Stability AI的说法,Stable Audio可以以44.1 kHz的采样率渲染95秒的16位立体声音频(通常称为“CD质量因为它符合CD格式的技术规格)Nvidia A100 GPU。A100是为人工智能使用而设计的强大的数据中心GPU,它比典型的桌面游戏GPU更有能力。
虽然生成的音频在位深度和采样速率方面可能符合CD规范,但值得注意的是,稳定音频产生的音乐的实际感知质量可能会有很大差异,尤其是因为音频是从数据集中的压缩表示中生成的。
如上所述,稳定的音频并不是第一个基于潜在扩散技术的音乐发生器。去年12月,我们报道了重复融合一个业余爱好者对稳定扩散的音频版本感兴趣,尽管其产生的几代产品在质量上远远达不到稳定音频的样本。今年1月,谷歌发布了MusicLM,这是一个24 kHz音频的人工智能音乐生成器,Meta推出了一套开源音频工具(包括一个文本到音乐生成器),名为音频工艺八月。现在,随着44.1千赫立体声音频,稳定的扩散正在增加赌注。
稳定性说,稳定的音频将可在一个免费层和12美元每月专业计划。通过免费选项,用户每月可以生成多达20首曲目,每首曲目最长20秒。Pro计划扩展了这些限制,允许每月生成500首曲目,曲目长度可达90秒。未来的稳定版本预计将包括基于稳定音频架构的开源模型,以及为那些对开发音频生成模型感兴趣的人提供的培训代码。
就目前情况而言,考虑到音频保真度,我们可能处于生产质量的人工智能生成的稳定音频音乐的边缘。音乐人被AI模特取代会开心吗?不太可能,如果历史告诉我们艾在视觉艺术领域的抗议。目前,人类可以轻松超越人工智能可以产生的任何东西,但这种情况可能不会持续太久。无论如何,人工智能生成的音频可能会成为专业人员音频制作工具箱中的另一个工具。