YOLOv5:修改backbone为ConvNeXt
- 前言
- 前提条件
- 相关介绍
- ConvNeXt
- YOLOv5修改backbone为ConvNeXt
- 修改common.py
- 修改yolo.py
- 修改yolov5.yaml配置
- 参考

前言
- 记录在YOLOv5修改backbone操作,方便自己查阅。
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。它是一个在COCO数据集上预训练的物体检测架构和模型系列,代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
ConvNeXt
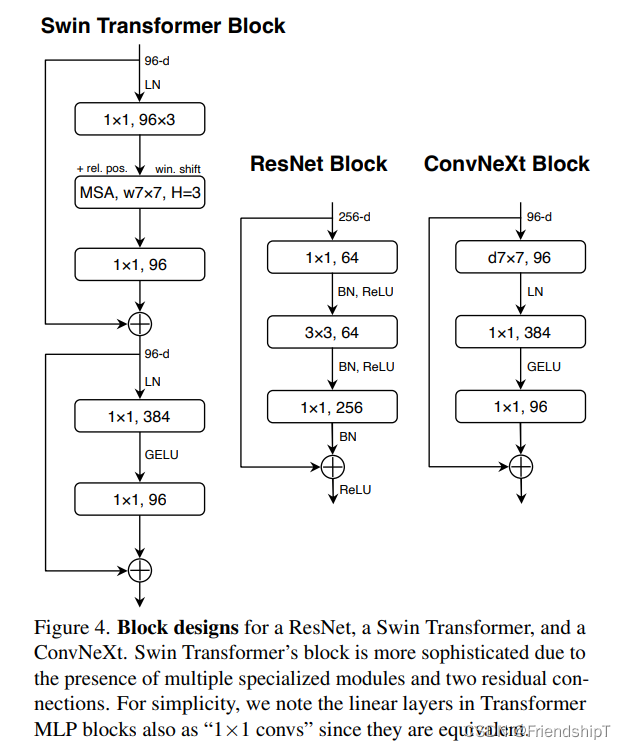
- ConvNeXt是一种由Facebook AI Research和UC Berkeley共同提出的卷积神经网络模型。它是一种纯卷积神经网络,由标准卷积神经网络模块构成,具有精度高、效率高、可扩展性强和设计非常简单的特点。ConvNeXt在2022年的CVPR上发表了一篇论文,题为“面向2020年代的卷积神经网络”。ConvNeXt已在ImageNet-1K和ImageNet-22K数据集上进行了训练,并在多个任务上取得了优异的表现。ConvNeXt的训练代码和预训练模型均已在GitHub上公开。
- ConvNeXt是基于ResNet50进行改进的,其与Swin Transformer一样,具有4个Stage;不同的是ConvNeXt将各Stage中Block的数量比例从3:4:6:3改为了与Swin Transformer一样的1:1:3:1。 此外,在进行特征图降采样方面,ConvNeXt采用了与Swin Transformer一致的步长为4,尺寸为4×4的卷积核。
- ConvNeXt的优点包括:
- ConvNeXt是一种纯卷积神经网络,由标准卷积神经网络模块构成,具有精度高、效率高、可扩展性强和设计非常简单的特点。
- ConvNeXt在ImageNet-1K和ImageNet-22K数据集上进行了训练,并在多个任务上取得了优异的表现。
- ConvNeXt采用了Transformer网络的一些先进思想对现有的经典ResNet50/200网络做一些调整改进,将Transformer网络的最新的部分思想和技术引入到CNN网络现有的模块中从而结合这两种网络的优势,提高CNN网络的性能表现.
- ConvNeXt的缺点包括:
- ConvNeXt并没有在整体的网络框架和搭建思路上做重大的创新,它仅仅是依照Transformer网络的一些先进思想对现有的经典ResNet50/200网络做一些调整改进.
- ConvNeXt相对于其他CNN模型而言,在某些情况下需要更多计算资源.
- 论文地址:https://arxiv.org/abs/2201.03545
- 官方源代码地址:https://github.com/facebookresearch/ConvNeXt.git
- 有兴趣可查阅论文和官方源代码地址。
YOLOv5修改backbone为ConvNeXt
修改common.py
将以下代码,添加进common.py。
############## ConvNext ##############
import torch.nn.functional as F
class LayerNorm_s(nn.Module):def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):super().__init__()self.weight = nn.Parameter(torch.ones(normalized_shape))self.bias = nn.Parameter(torch.zeros(normalized_shape))self.eps = epsself.data_format = data_formatif self.data_format not in ["channels_last", "channels_first"]:raise NotImplementedErrorself.normalized_shape = (normalized_shape,)def forward(self, x):if self.data_format == "channels_last":return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)elif self.data_format == "channels_first":u = x.mean(1, keepdim=True)s = (x - u).pow(2).mean(1, keepdim=True)x = (x - u) / torch.sqrt(s + self.eps)x = self.weight[:, None, None] * x + self.bias[:, None, None]return xclass ConvNextBlock(nn.Module):def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6):super().__init__()self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise convself.norm = LayerNorm_s(dim, eps=1e-6)self.pwconv1 = nn.Linear(dim, 4 * dim)self.act = nn.GELU()self.pwconv2 = nn.Linear(4 * dim, dim)self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),requires_grad=True) if layer_scale_init_value > 0 else Noneself.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()def forward(self, x):input = xx = self.dwconv(x)x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)x = self.norm(x)x = self.pwconv1(x)x = self.act(x)x = self.pwconv2(x)if self.gamma is not None:x = self.gamma * xx = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)x = input + self.drop_path(x)return xclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path_f(x, self.drop_prob, self.training)def drop_path_f(x, drop_prob: float = 0., training: bool = False):if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass CNeB(nn.Module):# CSP ConvNextBlock with 3 convolutions by iscyy/yoloairdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1)self.m = nn.Sequential(*(ConvNextBlock(c_) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
############## ConvNext ##############
修改yolo.py
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, CNeB]:

修改yolov5.yaml配置
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
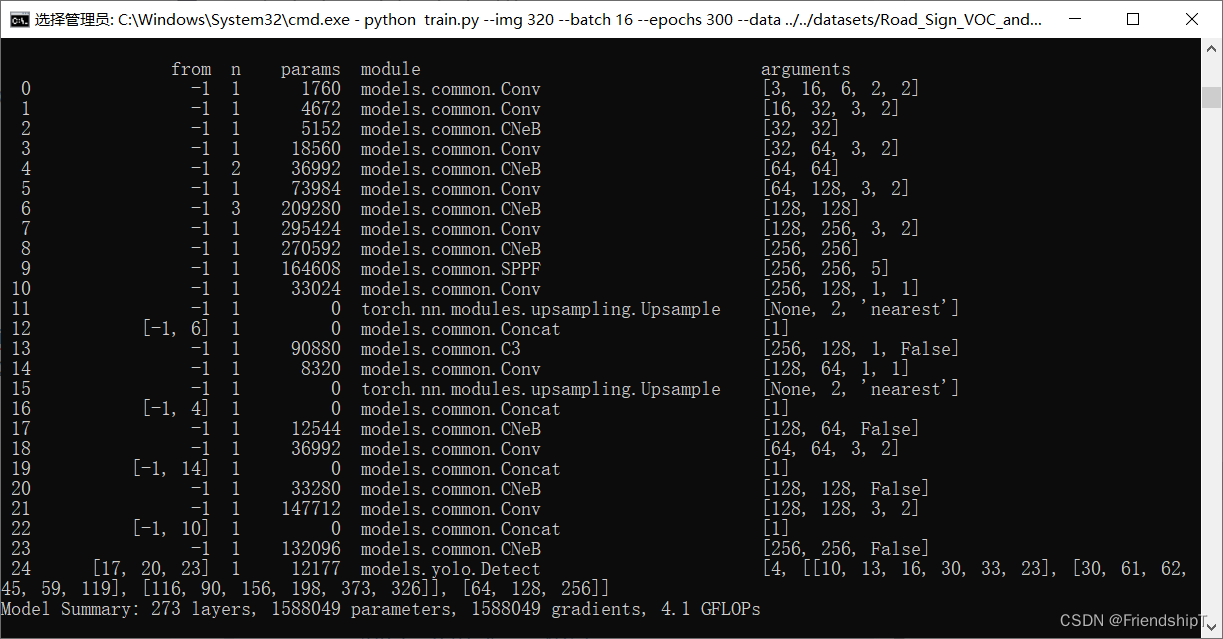
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, CNeB, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, CNeB, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, CNeB, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, CNeB, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, CNeB, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, CNeB, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, CNeB, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
参考
[1] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie. A ConvNet for the 2020s. 2022
[2] https://github.com/facebookresearch/ConvNeXt.git
[3] https://github.com/ultralytics/yolov5.git
[4] https://zhuanlan.zhihu.com/p/594051612
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏、自然语言处理
专栏或我的个人主页查看- 基于DETR的人脸伪装检测
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
- YOLOv5:TensorRT加速YOLOv5模型推理
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- 玩转Jetson Nano(五):TensorRT加速YOLOv5目标检测
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- Python将COCO格式实例分割数据集转换为YOLO格式实例分割数据集
- YOLOv5:使用7.0版本训练自己的实例分割模型(车辆、行人、路标、车道线等实例分割)
- 使用Kaggle GPU资源免费体验Stable Diffusion开源项目