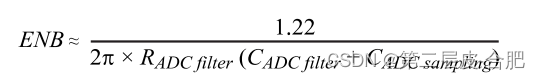今天给大家分享的内容是 Alluxio Operator的一体化部署方案。我会将内容分成 4 个部分来给大家讲解。

首先,介绍 Kubernetes 容器化部署和当前所面临的挑战。
然后,引入operator的概念,介绍当前业界关于Kubernetes 容器化部署问题的主流解决方案。
接着,讲解如何针对应用服务去实现对应的operator。
最后用Alluxio作为实际案例展示operator是如何实现的。
一、Kubernetes 容器化部署所面临的挑战
目前 Kubernetes 已经是业界比较主流的容器化部署方案,主要因为它对现在的容器化支持非常好,但是同时它也存在一些问题。
我们详细看一下Kubernetes容器化部署的过程,以Presto 为例,部署Presto、将Presto上云,需要做哪些事情?

第一步:梳理组件上云之后需要部署哪些 Kubernetes 资源。我们把应用打包成容器镜像,传到云仓库里面。
第二步:设计部署组件所需要的 Kubernetes 资源。如上图就展示了Presto在 Kubernetes 上的部署架构。因为Presto 组件包含了 coordinator 和 worker 两个不同的角色,所以我们针对这两个不同角色的配置需要有对应的ConfigMap资源,而且对coordinator和 worker 分别都需要有 Deployment 支撑部署。此外,为了打通 worker 与 coordinator的网络通讯,我们还需要一个 Service 资源。有了这样一个部署架构图之后,我们还要去思考到底要按什么样的顺序提交资源。比如对Presto 来说,我们需要提交Service、Deployment,还有 ConfigMap,这些资源都是通过 yaml 文件描述的,它们之间有先后顺序,有一定的依赖关系。比如在这个例子里,我们要先提交ConfigMap,再基于 ConfigMap创建Deployment,有了 Deployment 之后,我们再去部署Service。至此,我们发现需要有先后顺序做部署组件,这样就带来了一些问题:
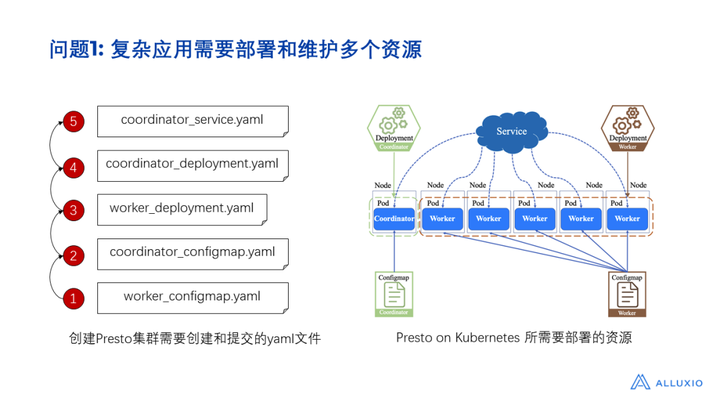
首先它带来的第一个问题就是所涉及到的Kubernetes 资源可能有多个,维护起来很不方便。尤其是对于很多大数据存储和计算领域里面的中间件,可能涉及到非常多的依赖,甚至包括一些上游下游的支撑组件。
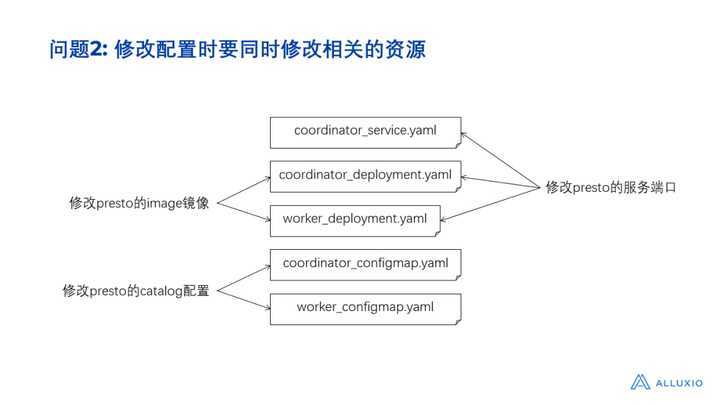
在Kubernetes 上要跑起来,需要多个 yaml 文件。比如以 Presto 为例,它需要的yaml文件有 5 个,我们如果要去实现Presto上云,就要维护多个yaml文件,这就导致了第二个问题,当我们需要修改某一个配置的时候,其实我们不仅要修改某一个 yaml 文件,可能还要修改所涉及到的跟它相关联的yaml文件。假设我们要修改容器的镜像版本,我们应该只需要修改某一个文件的镜像版本即可,但事实上,由于整个架构里面涉及到多个yaml文件、多个 Kubernetes 资源,所以这就导致了至少修改两个文件,修改起来非常复杂。又假设我们要修改服务的端口,从8080改成8081,会导致维护的复杂度变高,要改多个文件。诸如此类的修改操作,就导致增加了运维复杂度。

第三个问题是一个组件其实是由多个资源共同支撑而实现,但是这些资源的状态又是相互独立的。我们无法从更抽象更高维度的层级去监控所有资源的信息。比如刚刚提到的这些 Kubernetes 资源,共同组成了一个集群。但我们无法自动收集集群的使用情况,因为不同资源之间相互独立,而它们各自的日志只局限于自己本身。假设我们想根据集群的情况进行自动扩缩容,这个时候需要手动根据集群的情况去做扩缩容。我们只能知道某一个资源在某个时刻发生了变更,但无法知道集群到底什么时候发生了变更,要获取到这些信息,需要在更抽象的层级下才能实现。再比如,我们无法在集群的层面做自动备份容灾,如果突然遇到了一个需求,要下线一批机器,需要对机器上的数据进行迁移,那么这个时候只能手动做这些事情,通过手动调整Kubernetes的配置来实现。一方面需要很大的人力维护成本,另一方面即使能够通过手动实现,也很难跟踪到集群在何时做了哪些变更,只能看Kubernetes的内置日志,因此,我们也无法很好地做到弹性扩缩容。
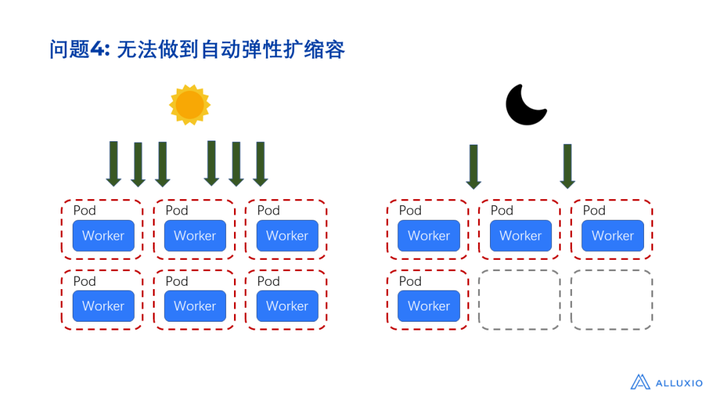
诸如 Presto 这样的计算引擎,白天可能用的人较多,请求量很大,这时候需要的资源就比较多,可以适当地给它扩充一些资源,但是到了晚上,或者是一个业务比较闲置的情况下,其实大部分的资源就可以回收起来,去做一些别的事情。比如留给 spark 或者 Flink 做ETL ,节省资源减少消耗,也相当于是在省钱。
二、关于Kubernetes 容器化部署问题的主流解决方案

我们看到了诸多Kubernetes 容器化部署所遇到的挑战,相应地,业界为了解决这些问题,提出了Operator 的概念。我们先来回顾一下,Kubernetes的资源包括哪些东西?我们要把一个应用部署到Kubernetes集群里,经常会用到的资源包括:PV、PVC、StatefulSet、CronJob、DaemonSet、 ConfigMap、Secret等。

这些资源在 Kubernetes 中属于内置资源,也许我们会有疑问,Kubernetes为什么能够监听到我们提交的这些资源?

上图展示了三个资源文件,分别是Service、Deployment和ConfigMap,其中 Deployment引用了ConfigMap中的属性内容,而Service 则给 Deployment 提供了一个网络访问的支持。Service、Deployment和ConfigMap这三种资源类型都是Kubernetes内置的。

当用户通过 kubectl创建一个 Deployment 资源时, kubectl内部会通过Kubernetes API Service 将请求提交到Kubernetes 集群。此时,Kubernetes内置的 Deployment Controller监听到了用户提交创建Deployment资源的请求事件,并负责处理请求。所谓Controller,可以理解为一个一直挂在集群中运行的守护进程。具体来说,用户提交的请求实际上会插入到一个被Deployment Controller监听的队列里,当队列中有新的请求进来时,Deployment Controller就会负责处理。当Deployment Controller从队列中获取到请求事件之后,它会进一步解析资源中的属性,然后对比集群中的资源和用户提交的 Deployment 资源,判断状态、属性是否一致,当出现不一致的时候, Deployment Controller 就会执行一些措施来改变目前的状态,让它能够变成用户所期望的状态。
比如,假设用户提交了一个Deployment资源,Deployment Controller 发现当前集群里不存在这样的一个资源,那么它就会创建新的Deployment,按照声明里的副本数创建相应数量的POD,并且按照所指定的镜像版本从镜像仓库里拉取镜像。当用户更新了 Deployment 时,在队列里相应地也会出现一个update事件。
Deployment Controller会对比现有 Department 的状态,如果它发现镜像的版本发生了变更,就会把原来的容器删掉,重新拉取新的镜像,用新的镜像创建新的容器。

上述就是内置 Kubernetes 资源Controller的原理,Kubernetes里的每一种资源都有一种对应的Controller,比如Deployment对应有 Deployment Controller,StatefulSet对应有 StatefulSet Controller。
一般来说,部署一个服务应用会涉及到很多不同的 Kubernetes 内置资源,正如刚才介绍的部署Presto的例子,需要将Kubernetes提供的这些内置资源组合起来,借助这种组合的方式才能实现部署集群的目的。此时我们不妨可以想一想,是否可以有一个自定义的定制资源来替代那些资源的组合呢?比如假设要部署Presto,如果存在一个叫做Presto的资源,同时让 Kubernetes 具备一个Presto Controller来监控Presto资源,并且自动创建ConfigMap、Deployment和Service,这样就省去手动创建、校验等步骤。此外,当我们修改某一个配置时,也不需要同时修改相关的资源。
Kubernetes 为我们提供了customer resource 定制资源。customer resource允许我们创建一个自定义的资源,并且可以定义资源里面包含哪些属性(比如 image 属性)。单纯定义customer resource仍然是不够的,因为当我们将定义好的customer resource commit到Kubernetes之后,此时Kubernetes并不知道该如何去处理,它只能校验customer resource的定义是否合法。它并不知道如何根据customer resource的属性去创建deployment ConfigMap等内置资源。因此,我们仍然需要去实现这样一个自动化程序(即定制资源的controller)。在此基础上,Operator的概念就是一个定制资源加上相对应定制资源的controller。

刚才我们以 Deployment 为例解释了 Kubernetes 的controller,介绍了它是如何和用户提交的 deployment 资源产生作用进而完成 Kubernetes Deployment 部署的。
同样地,如果我们要定义一个名为Presto的 customer resource,首先需要提交一个CRD来定义这个名为Presto的customer resource包含哪些属性,CRD也就是 custom resource 的definition,它用于告诉 Kubernetes customer resource里有一个名为Presto的资源类型,同时定义了这个Presto资源类型里面有哪些属性。提交了CRD之后, Kubernetes便可以识别Presto这种customer resource。此时如果用户提交了一个Presto customer resource到Kubernetes,我们还需要一个类似于deployment controller进程的自定义controller,以同样的方式发现并处理customer resource。
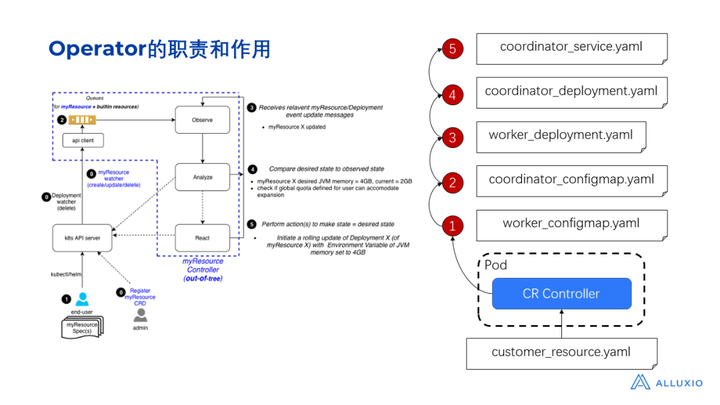
自定义的 controller 会获取到资源的描述,当它发现有人提交了一个名为Presto 的资源,它需要按照一定的顺序创建对应的这些 kubernetes 资源:
1、根据Presto资源中定义的属性,先去创建一个 ConfigMap 来描述JVM配置;
2、创建一个 deployment,包含Presto具体的镜像版本;
3、创建一个service,连通Presto coordinator 和Presto worker。
上述的3个步骤需要在 controller 进程里实现。因此,自定义的controller 其实跟内置的Kubernetes controller 原理一样。只不过自定义的 controller 需要我们自己去实现自己的业务逻辑。当我们创建了一个 Presto 资源后,自定义的controller仍然要监控资源的状态,如果资源的状态被更新了(比如Presto的镜像被更新了),那么它也需要根据更新之后的状态和当前状态进行对比,之后controller 要去做的事情就是自动更新它所创建的相关资源,而我们则无须关心要更新哪些内置的deployment和service。至此,我们就理解了实际上Operator通过一套解决方案自动化地减少了我们手工维护资源的步骤。
对于 Operator 来说,它的职责是帮我们减少人工的维护成本。以刚才的 Presto部署为例,如果我们实现了一个 Presto controller,这个controller实际上是一个进程,我们可以把它放在 Kubernetes 集群上的一个pod里运行 。当它发现有一个Presto的customer resource提交到Kubernetes集群时,它就应该要按顺序地创建对应的内置资源。原来这个创建的步骤是由人工创建的,现在变成由Presto controller负责创建。它会先创建 config map,再创建deployment,再创建service。

我们可以看一下 Operator 的能力分级。首先,假设我们抛开Operator,回到最原始的 Kubernetes 部署方式,则所有的这些资源都需要我们自己去创建和部署,并且按顺序手工提交。所以如果有一个进程能够帮助我们按照顺序创建这些资源,省去人工创建的步骤,那么这样就达到了Level 1。相当于所有步骤都已经被编排好,不再需要人工维护。
在此基础上,当我们修改了customer resource中的某些属性,Operator也应该负责更新相关的资源。比如如果镜像的版本发生了变更,此时理所当然地Operator也能帮我们同时去修改那些相关的资源,这样一来,我们也不需要维护里面这些资源之间的关系了。如果能做到这一点,就达到了Level 2。
更进一步地,Operator作为整个应用组件之上更抽象的进程,其实它还可以帮我们做一些应用集群之外的事情(比如存储的备份、容灾、自动迁移等)。如果具备这样的能力,我们就可以说Operator达到了Level 3。
再有,我们还可以在此之上收集一些关于应用组件或者集群的宏观信息,比如什么时候发生了扩缩容、什么时候做了配置变更等,再比如如果它进行了滚动升级,那我们可以收集到有关CPU和内存的使用情况,知道什么时候 CPU 的使用率高、内存资源使用得多,什么时候使用得少。这些信息在后期可以被进一步用来做优化,比如可以对资源进行调优,可以对整个集群的指标进行收集,甚至实现水位告警,发送一条短信或者是打电话或者用邮件来通知用户,此时的Operator达到了Level 4。
最后,假设在集群部署的应用组件能够在Operator基础上做到自动扩缩容,我们就可以说它达到了Level 5。比如,基于前面Level 4所收集的指标进行分析后,发现应用在白天的请求较多,而晚上较少,则Operator可以自动根据请求的数目去做扩缩容,自动地去修改pod的副本数。在这样的情况下,Operator实现了参数的自动调优。
上述的这5个Level的分级标准实际上来自于Operator SDK 的官网。
接下来我们就以Alluxio为例阐述如何实现Alluxio Operator。我们首先要考虑的是,将Alluxio部署到 Kubernetes 需要哪些类型的资源做支撑。
三、如何针对应用服务实现对应的Operator
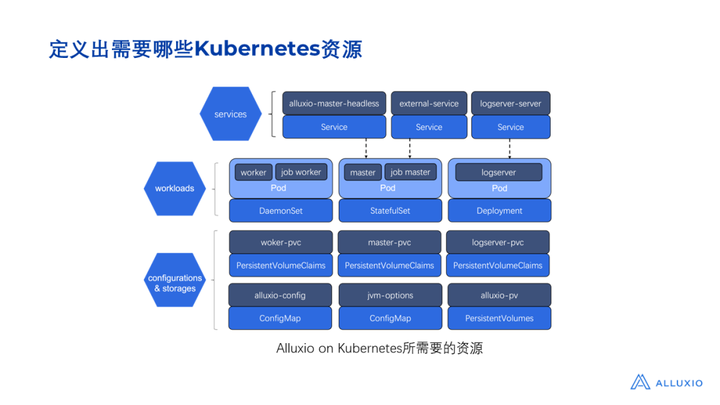
一个Alluxio集群所需要的资源很多,其中还包括存储和网络相关的资源。我们第一步先设计出如图所示的架构图。如图所示, 部署Alluxio所需的资源可以分成 3 层:
1) 第一层是配置和存储相关的资源。我们需要一些 config map 专门配置 Alluxio的基本配置信息,比如jvm配置、pv存储配置。另外,由于Alluxio集群需要涉及到存储,所以还需要 PVC 资源。
2) 第二层是workload。目前业界大部分的大数据组件都采用了主从架构的设计,Alluxio也一样,它存在master和worker两种角色,针对master和worker的部署,我们分别使用DaemonSet和StatefulSet,而针对logserver(用于日志的收集)的部署,则使用 deployment。
3) 第三层是service。为了让所有节点之间可以网络互通,还要部署service。
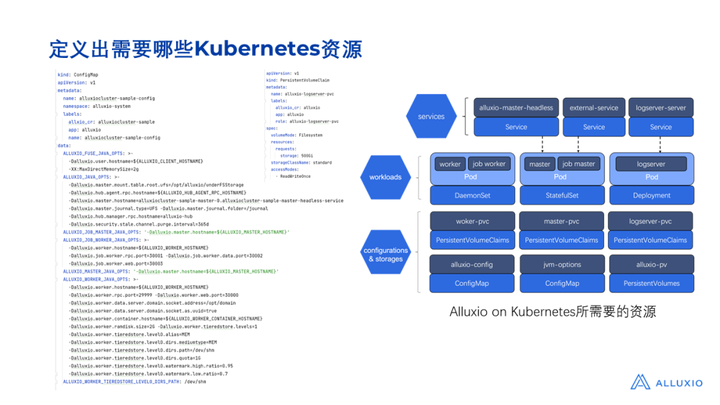


第二步是梳理出具体要创建哪些资源,以及每一种资源包含哪些属性。如图所示给出了所有部署Alluxio所需资源的YAML文件。
无论我们是否采用 Operator 的部署方案,都需要梳理出要创建哪些资源(对应如图所示的YAML文件)。Operator的作用是在此基础上帮助我们实现自动化部署,免除了手工按顺序提交这些 YAML文件的操作。为了实现自己的Operator,要先定义customer resource,将涉及到的资源属性抽象出来,如图所示,在Alluxio的customer resource里把一些比较关键的属性抽象出来,比如master和worker的配置信息。


由于不同资源之间存在着先后依赖关系,所以我们需要按照一定顺序逐一创建这些资源。首先要部署的是ConfigMap和存储相关的资源,第二步才去部署workerload,第三步部署services。因为显然我们需要先创建出deployment,才可能把 service 部署起来。即使我们采用手工部署的方式,也要遵循这样的顺序,只不过我们现在先把这个顺序梳理出来,以便在实现 Operator 的时候,通过程序来自动按照这个顺序创建资源。
实现 Operator 的逻辑其实就是通过 Operator 调用 kubernetes API 提供的接口,按照顺序部署和更新资源。Operator SDK是当前比较流行的一个实现Operator的框架(https://sdk.operatorframework.io),它主体通过golang 实现,框架内也提供了一些实用的例子。另一方面,目前在社区上也有相应的Operator 仓库(https://operatorhub.io),里面有相当丰富的各个组件的Operator实现。Operator 这一概念被提出之后,业界也陆陆续续地针对主流大数据组件实现了一些社区版的Operator,提供了一些相对方便的容器化部署解决方案。
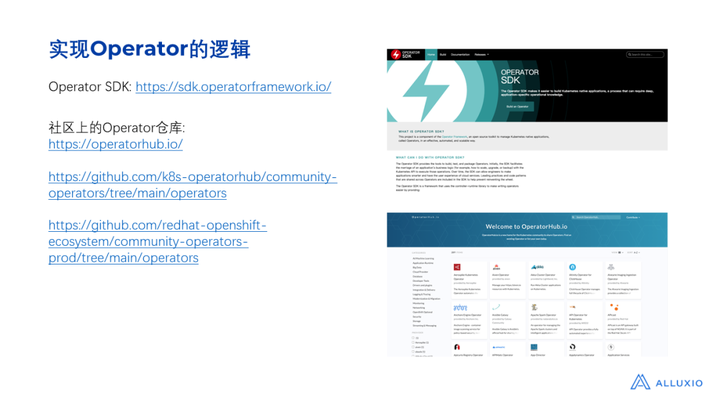
四、Alluxio Operator如何更好地实现Alluxio的一体化部署

我们最后再来回顾一下Alluxio Operator所创建的资源有哪些。Operator帮我们创建的资源可以分成三个级别:
1) 配置信息相关的资源:包括 JVM 配置和 PV 存储,以及worker、master 和 logserver 的 PVC。
2) Workload资源: Alluxio Worker、Alluxio Master 和 Alluxio LogServer 的节点分别使用了 DaemonSet、 SatefulSet 和 Deployment 进行部署。
3) Service资源: Alluxio Master和 Alluxio LogServer所需要的service。

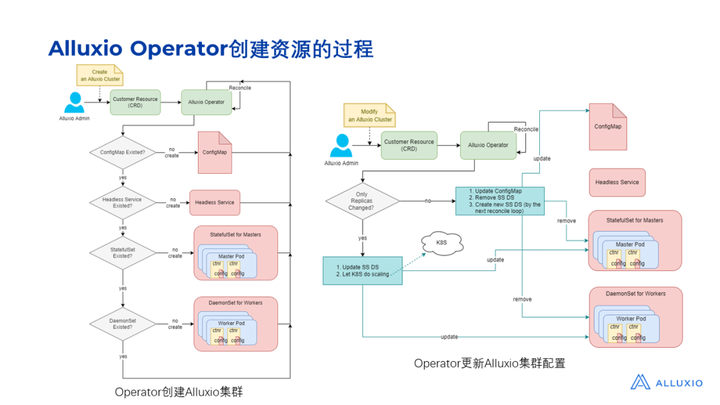
截图中展示了Alluxio Operator创建和更新Alluxio集群的过程,Operator运行在一个POD中,当用户提交了一个他自己的customer resource之后,集群里面就多了一个名为 Alluxio Cluster 的资源。


片刻之后,Operator 帮我们创建了所需的资源,如图所示我们能看到有很多POD被自动创建出来,包括master和worker相关的POD,同时config map和service也被创建出来了。未来,其实还可以再做一些事情:
1) 利用 Operator 做数据自动备份和负载均衡;
2) 收集集群内CPU和内存的使用情况,实现节点的动态扩缩容,根据 CPU 内存的使用情况做弹性伸缩;
3) 实现 UFS 的数据预缓存、预加载;
4) 为Alluxio集群提供一个可视化的操作仪表板,对 UFS 进行状态跟踪。
这些功能可以在未来为我们大幅减少Alluxio集群的维护成本。
问答环节
Q1:当前大数据平台一般是采用HDFS作为底层分布式存储,如果想整体迁移到 Kubernetes,是否有类似HDFS Operator的方案?
目前主流的 HDFS 部署方式依然还是通过YARN 来部署,由于这种方式已经做得比较成熟了,所以如果想整体迁移到Kubernetes,现阶段业界关于 HDFS Operator 这样的一些解决方案还是比较少见,可能这种模式仍然需要一段探索的时间。
Q2:Alluxio作为一个分布式缓存组件,介于计算应用与底层存储之间,实现了数据缓存的加速。如果将Alluxio、计算和存储组件部署在同一个K8S 集群上,在架构层面上有什么建议呢?
如果都是放在Kubernetes,其实它们之间是相对比较独立的。Alluxio其中一个非常重要的应用场景,就是在存算分离的基础上来做实现性能提升,因此往往Alluxio会跟计算集群部署在同一侧。目前 Kubernetes 的部署方式,更有利于Alluxio和计算应用端进行结合。
想要了解更多关于Alluxio的干货文章、热门活动、专家分享,可点击进入【Alluxio智库】: