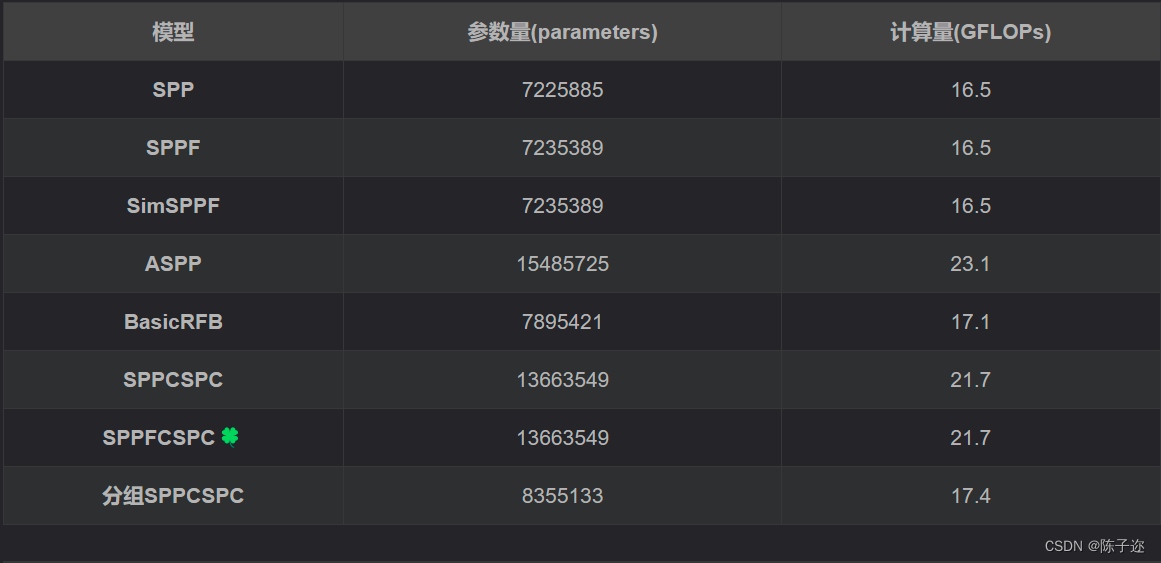
⼀、 MQ 简介
MQ : MessageQueue ,消息队列。是在互联⽹中使⽤⾮常⼴泛的⼀系列服务中间件。 这个词可以分两个部分来看,⼀是Message :消息。消息是在不同进程之间传递的数据。这些进程可以部署在同⼀台机器上,也可以分布在不同机器上。⼆是Queue :队列。队列原意是指⼀种具有 FIFO( 先进先出 ) 特性的数据结构,是⽤来缓存数据的。对于消息中间件产品来说,能不能保证FIFO 特性,尚值得考量。但是,所有消息队列都是需要具备存储消息,让消息排队的能⼒。
⼴义上来说,只要能够实现消息跨进程传输以及队列数据缓存,就可以称之为消息队列。例如我们常⽤的 QQ 、微信、阿⾥旺旺等就都具备了这样的功能。只不过他们对接的使⽤对象是⼈,⽽我们这⾥讨论的MQ 产品需要对接的使⽤对象是应⽤程序。
MQ 的作⽤主要有以下三个⽅⾯:
异步
例⼦:快递员发快递,直接到客户家效率会很低。引⼊菜⻦驿站后,快递员只需要把快递放到菜⻦驿站,就可以继续发其他快递去了。客户再按⾃⼰的时间安排去菜⻦驿站取快递。
作⽤:异步能提⾼系统的响应速度、吞吐量。
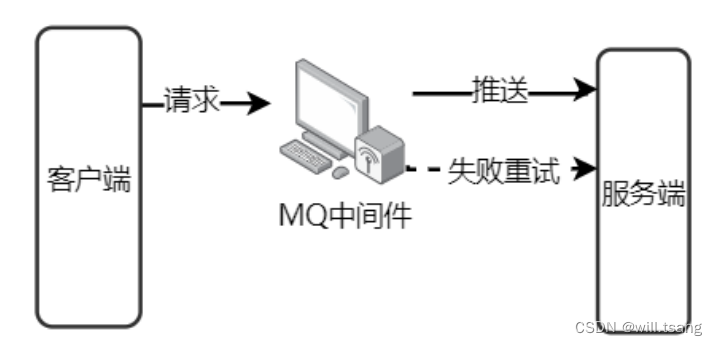
· 解耦
例⼦:《 Thinking in JAVA 》很经典,但是都是英⽂,我们看不懂,所以需要编辑社,将⽂章翻译成其他语⾔,这样就可以完成英语与其他语⾔的交流。
作⽤:
1 、服务之间进⾏解耦,才可以减少服务之间的影响。提⾼系统整体的稳定性以及可扩展性。
2 、另外,解耦后可以实现数据分发。⽣产者发送⼀个消息后,可以由⼀个或者多个消费者进⾏消费,并且消费者的增加或者减少对⽣产者没有影响。
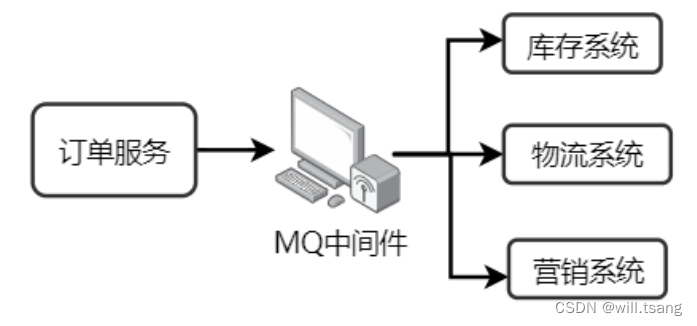
· 削峰
例⼦:⻓江每年都会涨⽔,但是下游出⽔⼝的速度是基本稳定的,所以会涨⽔。引⼊三峡⼤坝后,可以把⽔储存起来,下游慢慢排⽔。
作⽤:以稳定的系统资源应对突发的流量冲击。

⼆、 RocketMQ 产品特点
1 、 RocketMQ 介绍
RocketMQ 是阿⾥巴巴开源的⼀个消息中间件,在阿⾥内部历经了双⼗⼀等很多⾼并发场景的考验,能够处理亿万级别的消息。2016 年开源后捐赠给 Apache ,现在是 Apache 的⼀个顶级项⽬。
早期阿⾥使⽤ ActiveMQ ,但是,当消息开始逐渐增多后, ActiveMQ 的 IO 性能很快达到了瓶颈。于是,阿⾥开始关注Kafka 。但是 Kafka 是针对⽇志收集场景设计的,他的⾼级功能并不是很贴合阿⾥的业务场景。尤其当他的Topic过多时,由于 Partition ⽂件也会过多,这就会加⼤⽂件索引的耗时,会严重影响 IO 性能。于是阿⾥才决定⾃研中间件,最早叫做MetaQ ,后来改名成为 RocketMQ 。最早他所希望解决的最⼤问题就是多 Topic 下的 IO 性能压⼒。但是产品在阿⾥内部的不断改进,RocketMQ 开始体现出⼀些不⼀样的优势。
2 、 RocketMQ 特点
当今互联⽹ MQ 产品众多,其中,影响⼒和使⽤范围最⼤的当数 Apache Kafka 、 RabbitMQ 、 Apache RocketMQ以及Apache Plusar 。这⼏⼤产品虽然都是典型的 MQ 产品,但是由于设计和实现上的⼀些差异,造成他们适合于不同的细分场景。
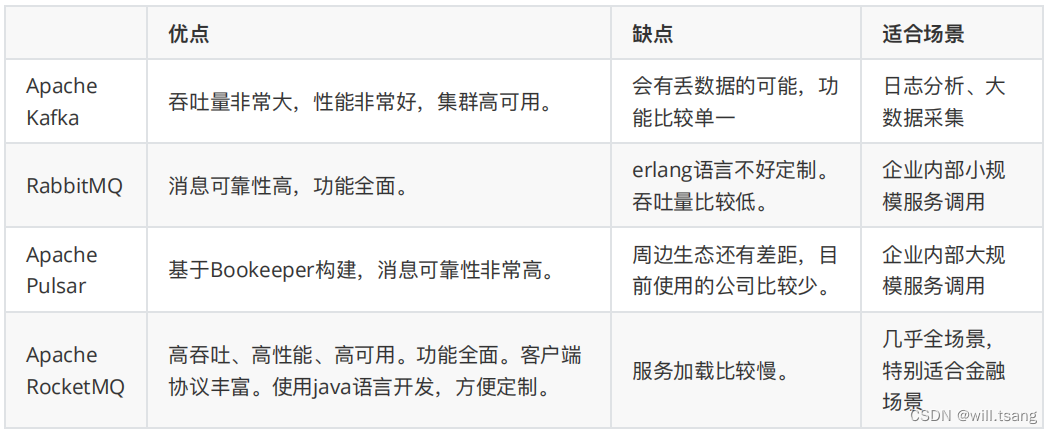
其中 RocketMQ ,孵化⾃阿⾥巴巴。历经阿⾥多年双⼗⼀的严格考验, RocketMQ 可以说是从全世界最严苛的⾼并发场景中摸爬滚打出来的过硬产品,也是少数⼏个在⾦融场景⽐较适⽤的MQ 产品。从横向对⽐来看,RocketMQ与 Kafka 和 RabbitMQ 相⽐。 RocketMQ 的消息吞吐量虽然和 Kafka 相⽐还是稍有差距,但是却⽐RabbitMQ⾼很多。在阿⾥内部, RocketMQ 集群每天处理的请求数超过 5 万亿次,⽀持的核⼼应⽤超过 3000 个。⽽RocketMQ 最⼤的优势就是他天⽣就为⾦融互联⽹⽽⽣。他的消息可靠性相⽐ Kafka 也有了很⼤的提升,⽽消息吞吐量相⽐RabbitMQ 也有很⼤的提升。另外, RocketMQ 的⾼级功能也越来越全⾯,⼴播消费、延迟队列、死信队列等等⾼级功能⼀应俱全,甚⾄某些业务功能⽐如事务消息,已经呈现出领先潮流的趋势。
三、 RocketMQ 快速实战
1 、快速搭建 RocketMQ 服务
RocketMQ 的官⽹地址: http://rocketmq.apache.org 。在下载⻚⾯可以获取 RocketMQ 的源码包以及运⾏包。下载⻚⾯地址: https://rocketmq.apache.org/download 。
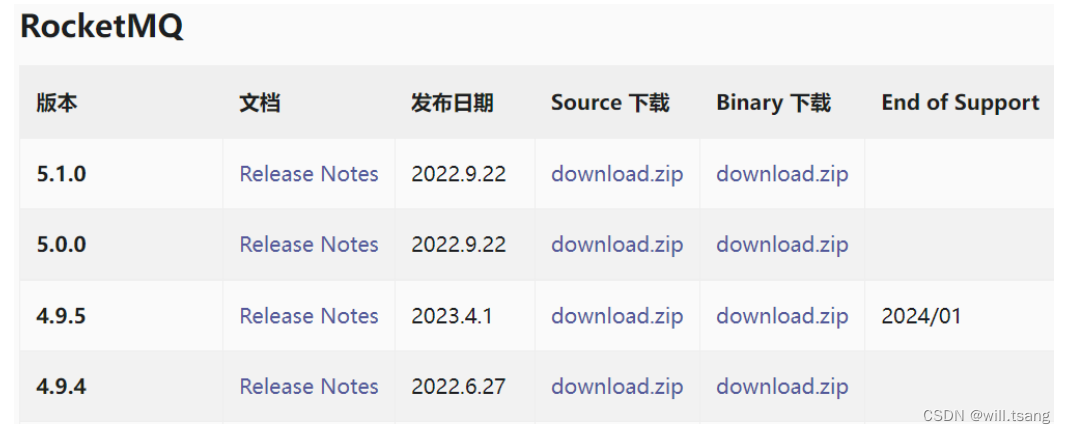
当前最新的版本是 5.x ,这是⼀个着眼于云原⽣的新版本,给 RocketMQ 带来了⾮常多很亮眼的新特性。但是⽬前来看,企业中⽤得还⽐较少。因此,我们这⾥采⽤的还是更为稳定的4.9.5 版本。

运⾏只需要下载 Binary 运⾏版本就可以了。 当然,源码包也建议下载下来,后续会进⾏解读。运⾏包下载下来后,就可以直接解压,上传到服务器上。我们这⾥会上传到/app/rocketmq ⽬录。解压后⼏个重要的⽬录如下 :
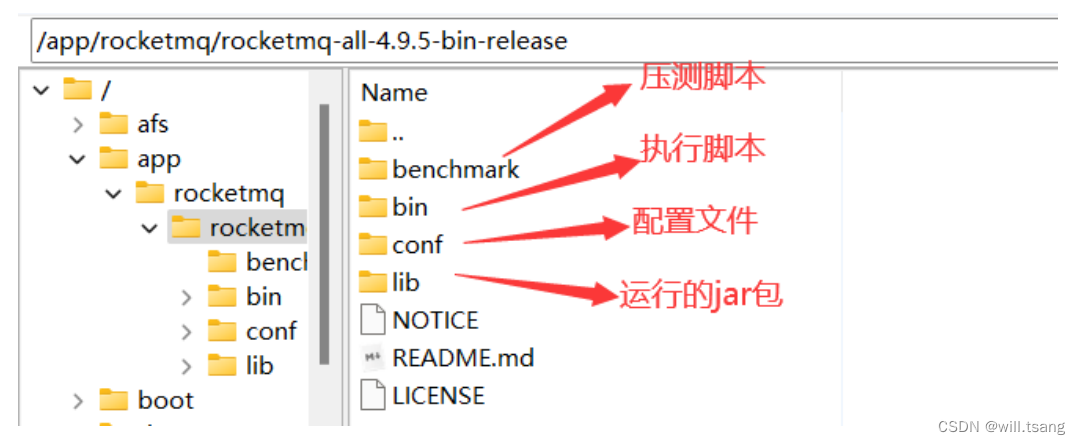
接下来, RocketMQ 建议的运⾏环境需要⾄少 12G 的内存,这是⽣产环境⽐较理想的资源配置。但是,学习阶段,如果你的服务器没有这么⼤的内存空间,那么就需要做⼀下调整。进⼊bin ⽬录,对其中的 runserver.sh 和runbroker.sh两个脚本进⾏⼀下修改。
使⽤ vi runserver.sh 指令,编辑这个脚本,找到下⾯的⼀⾏配置,调整 Java 进程的内存⼤⼩。

接下来,同样调整 runbroker.sh 中的内存⼤⼩。

调整完成后,就可以启动 RocketMQ 服务了。 RocketMQ 服务基于 Java 开发,所以需要提前安装 JDK 。 JDK 建议采⽤1.8 版本即可。

RocketMQ 的后端服务分为 nameserver 和 broker 两个服务,关于他们的作⽤,后⾯会给你分享。接下来我们先将这两个服务启动起来。
第⼀步:启动 nameserver 服务。

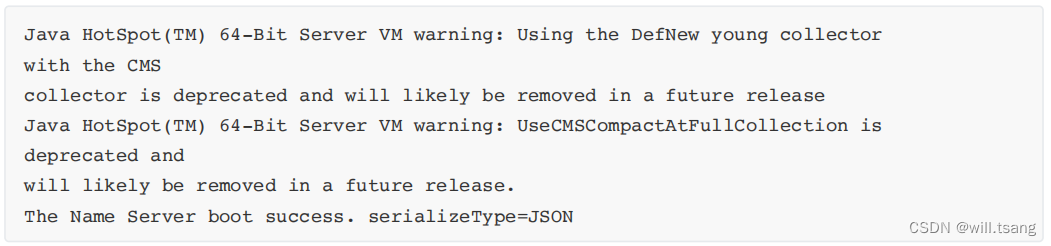
指令执⾏后,会⽣成⼀个 nohup.out 的⽇志⽂件。在这个⽇志⽂件⾥如果看到下⾯这⼀条关键⽇志,就表示nameserver服务启动成功了。
接下来,可以通过 jsp 指令进⾏验证。使⽤ jps 指令后,可以看到有⼀个 NamesrvStartup 的进程运⾏,也表示nameserver服务启动完成。
第⼆步:启动 broker 服务。
启动 broker 服务之前,要做⼀个⼩⼩的配置。进⼊ RocketMQ 安装⽬录下的 conf ⽬录,修改 broker.conf ⽂件,在⽂件最后⾯加⼊⼀个配置:


然后也可以⽤之前的⽅式启动 broker 服务。启动 broker 服务的指令是 mqbroker

启动完成后,同样检查 nohup.out ⽇志⽂件,有如下⼀条关键⽇志,就表示 broker 服务启动正常了。

同样使⽤ jps 指令可以检查服务的启动状态。使⽤ jsp 指令后,可以看到⼀个名为 BrokerStartup 的进程,则表示broker服务启动完成。
2 、快速实现消息收发
RocketMQ 后端服务启动完成后,就可以启动客户端的消息⽣产者和消息消费者进⾏消息转发了。接下来,我们会先通过RocketMQ 提供的命令⾏⼯具快速体验⼀下 RocketMQ 消息收发的功能。然后,再动⼿搭建⼀个 Maven 项⽬,在项⽬中使⽤RocketMQ 进⾏消息收发。
1 、命令⾏快速实现消息收发
第⼀步 :需要配置⼀个环境变量 NAMESRV_ADDR ,只想我们之前启动的 nameserver 服务。
通过 vi ~/.bash_profile 添加以下配置。然后使⽤ source ~/.bash_profile 让配置⽣效。

第⼆步 :通过指令启动 RocketMQ 的消息⽣产者发送消息。

这个指令会默认往 RocketMQ 中发送 1000 条消息。在命令⾏窗⼝可以看到发送消息的⽇志:

这部分⽇志中,并没有打印出发送了什么消息。上⾯ SendResult 开头部分是消息发送到 Broker 后的结果。最后两⾏⽇志表示消息⽣产者发完消息后,服务正常关闭了。
第三步 :可以启动消息消费者接收之前发送的消息

消费者启动完成后,可以看到消费到的消息

每⼀条这样的⽇志信息就表示消费者接收到了⼀条消息。
这个 Consumer 消费者的指令并不会主动结束,他会继续挂起,等待消费新的消息。我们可以使⽤ CTRL+C 停⽌该进程。

2 、搭建 Maven 客户端项⽬
之前的步骤实际上是在服务器上快速验证 RocketMQ 的服务状态,接下来我们动⼿搭建⼀个 RocketMQ 的客户端应⽤,在实际应⽤中集成使⽤RocketMQ 。
第⼀步 :创建⼀个标准的 maven 项⽬,在 pom.xml 中引⼊以下核⼼依赖

第⼆步: 就可以直接创建⼀个简单的消息⽣产者

运⾏其中的 main ⽅法,就会往 RocketMQ 中发送两条消息。在这个实现过程中,需要注意⼀下的是对于⽣产者,需要指定对应的nameserver 服务的地址,这个地址需要指向你⾃⼰的服务器。
第三步 :创建⼀个消息消费者接收 RocketMQ 中的消息。

运⾏其中的 main ⽅法后,就可以启动⼀个 RocketMQ 消费者,接收之前发到 RocketMQ 上的消息,并将消息内容打印出来。在这个实现过程中,需要重点关注的有两点。⼀是对于消费者,同样需要指定nameserver 的地址。⼆是消费者需要在RocketMQ 中订阅具体的 Topic ,只有发送到这个 Topic 上的消息才会被这个消费者接收到。
这样,通过⼏个简单的步骤,我们就完成了 RocketMQ 的应⽤集成。从这个过程中可以看到, RocketMQ 的使⽤是⽐较简单的。但是这并不意味着这⼏个简单的步骤就⾜够搭建⼀个⽣产级别的RocketMQ 服务。接下来,我们会⼀步步把我们这个简单的RocketMQ 服务往⼀个⽣产级别的服务集群推进。
3 、搭建 RocketMQ 可视化管理服务
在之前的简单实验中, RocketMQ 都是以后台服务的⽅式在运⾏,我们并不很清楚 RocketMQ 是如何运⾏的。RocketMQ的社区就提供了⼀个图形化的管理控制台 Dashboard ,可以⽤可视化的⽅式直接观测并管理 RocketMQ的运⾏过程。
Dashboard 服务并不在 RocketMQ 的运⾏包中,需要到 RocketMQ 的官⽹下载⻚⾯单独下载。
这⾥只提供了源码,并没有提供直接运⾏的 jar 包。将源码下载下来后,需要解压并进⼊对应的⽬录,使⽤maven进⾏编译。 ( 需要提前安装 maven 客户端 )

编译完成后,在源码的 target ⽬录下会⽣成可运⾏的 jar 包 rocketmq-dashboard-1.0.1-SNAPSHOT.jar 。接下来可以将这个jar 包上传到服务器上。我们上传到 /app/rocketmq/rocketmq-dashboard ⽬录下
接下来我们需要在 jar 包所在的⽬录下创建⼀个 application.yml 配置⽂件,在配置⽂件中做如下配置:

主要是要指定 nameserver 的地址。
接下来就可以通过 java 指令执⾏这个 jar 包,启动管理控制台服务。

应⽤启动完成后,会在服务器上搭建起⼀个 web 服务,我们就可以通过访问 http://192.168.232.128:8080 查看到管理⻚⾯。

这个管理控制台的功能⾮常全⾯。驾驶舱⻚⾯展示 RocketMQ 近期的运⾏情况。运维⻚⾯主要是管理nameserver服务。集群⻚⾯主要管理 RocketMQ 的 broker 服务。很多信息都⼀⽬了然。在之后的过程中,我们也会逐渐了解DashBoard 管理⻚⾯中更多的细节。
4 、升级分布式集群
之前我们⽤⼀台 Linux 服务器,快速搭建起了⼀整套 RocketMQ 的服务。但是很明显,这样搭建的服务是⽆法放到⽣产环境上去⽤的。⼀旦nameserver 服务或者 broker 服务出现了问题,整个 RocketMQ 就⽆法正常⼯作。⽽且更严重的是,如果服务器出现了问题,⽐如磁盘坏了,那么存储在磁盘上的数据就会丢失。这时RocketMQ 暂存到磁盘上的消息也会跟着丢失,这个问题就⾮常严重了。因此,我们需要搭建⼀个分布式的RocketMQ 服务集群,来防⽌单点故障问题。
RocketMQ 的分布式集群基于主从架构搭建。在多个服务器组成的集群中,指定⼀部分节点作为 Master 节点,负责响应客户端的请求。指令另⼀部分节点作为Slave 节点,负责备份 Master 节点上的数据,这样,当 Master 节点出现故障时,在Slave 节点上可以保留有数据备份,⾄少保证数据不会丢失。
整个集群⽅案如下图所示:
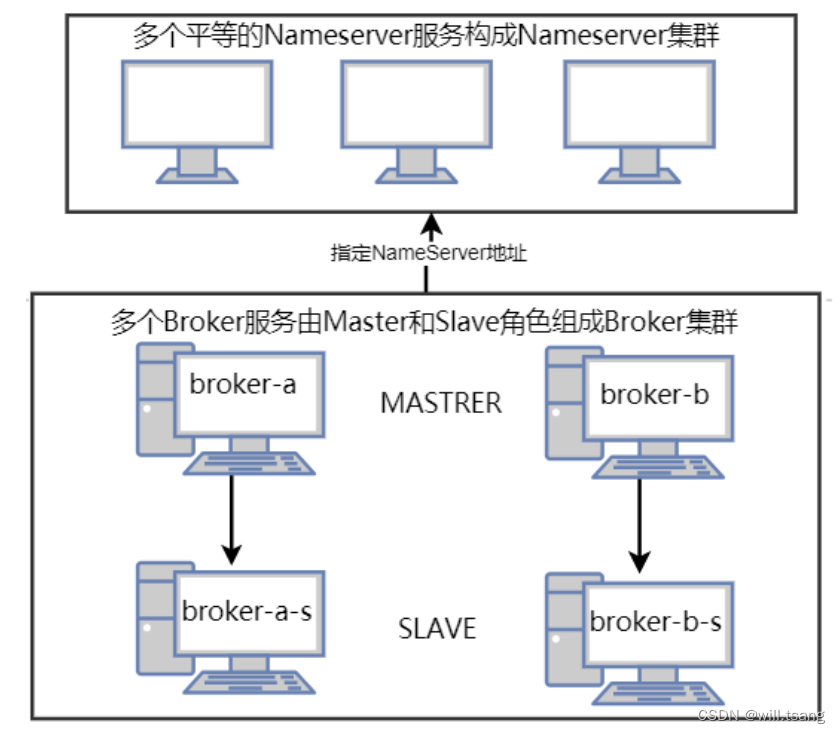
接下来我们准备三台相同的 Linux 服务器,搭建⼀下 RocketMQ 的分布式集群。为了更清晰的描述这三台服务器上的操作,我们给每个服务器指定⼀个机器名。

为了便于观察,我们这次搭建⼀个 2 主 2 从的 RocketMQ 集群,并将主节点和节点都分别部署在不同的服务器上。预备的集群规划情况如下:

第⼀步 :部署 nameServer 服务。
nameServer 服务不需要做特别的配置,按照之前的步骤,在三台服务器上都分别部署 nameServer 服务即可。
第⼆步 :对 Broker 服务进⾏集群配置。
这⾥需要修改 RocketMQ 的配置⽂件,对 broker 服务做⼀些集群相关的参数部署。这些配置⽂件并不需要我们⼿动进⾏创建,在RocketMQ 运⾏包的 conf ⽬录下,提供了多种集群的部署配置⽂件模板。
· 2m-noslave: 2 主⽆从的集群参考配置。这种集群存在单点故障。
· 2m-2s-async 和 2m-2s-sync: 2 主 2 从的集群参考配置。其中 async 和 sync 表示主节点与从节点之间是同步同步还是异步同步。关于这两个概念,会在后续章节详细介绍
· dledger: 具备主从切换功能的⾼可⽤集群。集群中的节点会基于 Raft 协议随机选举出⼀个 Leader ,其作⽤类似于Master 节点。其他的节点都是 follower ,其作⽤类似于 Slave 节点。
我们这次采⽤ 2m-2s-async 的⽅式搭建集群,需要在 worker2 和 worker3 上修改这个⽂件夹下的配置⽂件。
1> 配置第⼀组 broker-a 服务
在 worker2 机器上配置 broker-a 的 MASTER 服务,需要修改 conf/2m-2s-async/broker-a.properties 。示例配置如下:

这⾥对⼏个需要重点关注的属性,做下简单介绍:
· brokerClusterName: 集群名。 RocketMQ 会将同⼀个局域⽹下所有 brokerClusterName 相同的服务⾃动组成⼀个集群,这个集群可以作为⼀个整体对外提供服务
· brokerName: Broker 服务名。同⼀个 RocketMQ 集群当中, brokerName 相同的多个服务会有⼀套相同的数据副本。同⼀个RocketMQ 集群中,是可以将消息分散存储到多个不同的 brokerName 服务上的。
· brokerId: RocketMQ 中对每个服务的唯⼀标识。 RocketMQ 对 brokerId 定义了⼀套简单的规则, master 节点需要固定配置为0 ,负责响应客户端的请求。 slave 节点配置成其他任意数字,负责备份 master 上的消息。
· brokerRole: 服务的⻆⾊。这个属性有三个可选项: ASYNC_MASTER , SYNC_MASTER 和 SLAVE 。其中,ASYNC_MASTER和 SYNC_MASTER 表示当前节点是 master 节点,⽬前暂时不⽤关⼼他们的区别。 SLAVE 则表示从节点。
· namesrvAddr: nameserver 服务的地址。 nameserver 服务默认占⽤ 9876 端⼝。多个 nameserver 地址⽤;隔开。
接下来在 worekr3 上配置 broker-a 的 SLAVE 服务。需要修改 conf/2m-2s-async/broker-a-s.properties 。示例配置如下:

其中关键是 brokerClusterName 和 brokerName 两个参数需要与 worker2 上对应的 broker-a.properties 配置匹配。brokerId 配置 0 以为的数字。然后 brokerRole 配置为 SLAVE 。
这样,第⼀组 broker 服务就配置好了。
2> 配置第⼆组 borker-b 服务
与第⼀组 broker-a 服务的配置⽅式类似,在 worker3 上配置 broker-b 的 MASTER 服务。需要修改 conf/2m-2s-async/broker-b.properties⽂件,配置示例如下:


在 worker2 上配置 broker-b 的 SLAVE 服务。需要修改 conf/2m-2s-async/broker-b-s.properties ⽂件,配置示例如下:

这样就完成了 2 主 2 从集群的配置。配置过程汇总有⼏个需要注意的配置项:
· store 开头的⼀系列配置:表示 RocketMQ 的存盘⽂件地址。在同⼀个机器上需要部署多个 Broker 服务时,不同服务的存储⽬录不能相同。
· listenPort :表示 Broker 对外提供服务的端⼝。这个端⼝默认是 10911 。在同⼀个机器上部署多个 Broker 服务时,不同服务占⽤的端⼝也不能相同。
· 如果你使⽤的是多⽹卡的服务器,⽐如阿⾥云上的云服务器,那么就需要在配置⽂件中增加配置⼀个brokerIP1属性,指向所在机器的外⽹⽹卡地址。
第三步 :启动 Broker 服务
集群配置完成后,需要启动 Broker 服务。与之前启动 broker 服务稍有不同,启动时需要增加 -c 参数,指向我们修改的配置⽂件。
在 worker2 上启动 broker-a 的 master 服务和 broker-b 的 slave 服务:

在 worker3 上启动 broker-b 的 master 服务和 broker-a 的 slave 服务:

第四步 :检查集群服务状态
对于服务的启动状态,我们依然可以⽤之前介绍的 jps 指令以及 nohup.out ⽇志⽂件进⾏跟踪。不过,在RocketMQ的 bin ⽬录下,也提供了 mqadmin 指令,可以通过命令⾏的⽅式管理 RocketMQ 集群。
例如下⾯的指令可以查看集群 broker 集群状态。通过这个指令可以及时了解集群的运⾏状态。
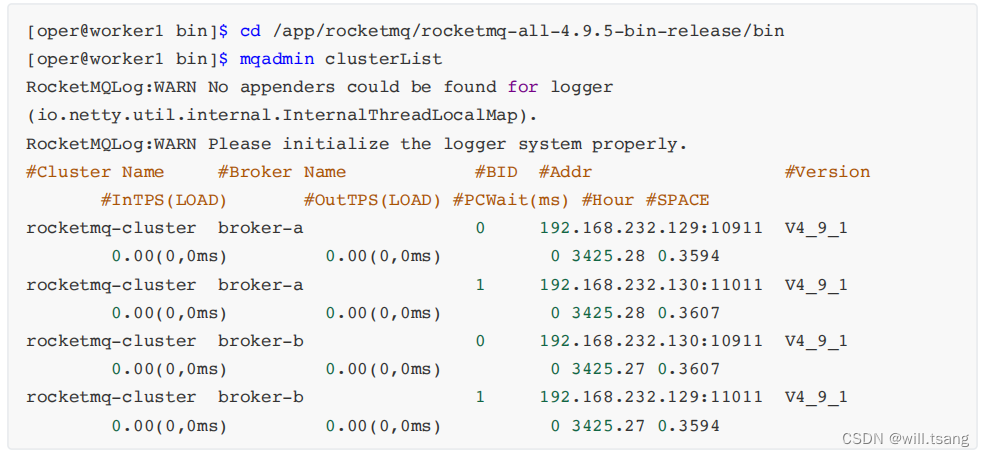
mqadmin 指令还提供了⾮常丰富的管理功能。你可以尝试直接使⽤ mqadmin 指令,就会列出 mqadmin ⽀持的所有管理指令。如果对某⼀个指令不会使⽤,还可以使⽤mqadmin help 指令查看帮助。
另外,之前搭建的 dashboard 也是集群服务状态的很好的⼯具。只需要在之前搭建 Dashboard 时创建的配置⽂件中增加指定nameserver 地址即可。

启动完成后,在集群菜单⻚就可以看到集群的运⾏情况
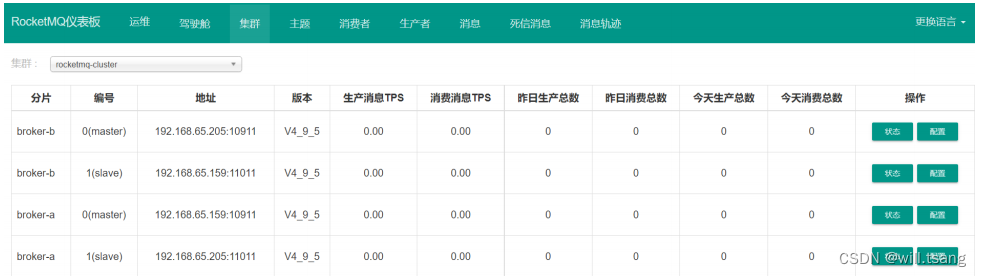
在 RocketMQ 的这种主从架构的集群下,客户端发送的消息会分散保存到 broker-a 和 broker-b 两个服务上,然后每个服务都配有slave 服务,可以备份对应 master 服务上的消息,这样就可以防⽌单点故障造成的消息丢失问题。
5 、升级⾼可⽤集群
主从架构的 RocketMQ 集群,由于给每个 broker 服务配置了⼀个或多个 slave 备份服务,可以保证当 broker 服务出现问题时,broker 上的消息不会丢失。但是,这种主从架构的集群却也有⼀个不⾜的地⽅,那就是不具备服务⾼可⽤。
这⾥所说的服务⾼可⽤,并不是并不是指整个 RocketMQ 集群就不能对外提供服务了,⽽是指集群中的消息就不完整了。实际上,当RocketMQ 集群中的 broker 宕机后,整个集群会⾃动进⾏ broker 状态感知。后续客户端的各种请求,依然可以转发到其他正常的broker 上。只不过,原本保存在当前 broker 上的消息,就⽆法正常读取了,需要等到当前broker 服务重启后,才能重新被消息消费者读取。
当⼀个 broker 上的服务宕机后,我们可以从对应的 slave 服务上找到 broker 上所有的消息。但是很可惜,主从架构中各个服务的⻆⾊都是固定了的,slave 服务虽然拥有全部的数据,但是它没办法升级成为 master 服务去响应客户端的请求,依然只是傻傻等待master 服务重启后,继续做它的数据备份⼯作。
这时,我们⾃然就希望这个 slave 服务可以升级成为 master 服务,继续响应客户端的各种请求,这样整个集群的消息服务就不会有任何中断。⽽RocketMQ 提供的 Dledger 集群,就是具备⻆⾊⾃动转换功能的⾼可⽤集群。
整个集群结构如下图所示:
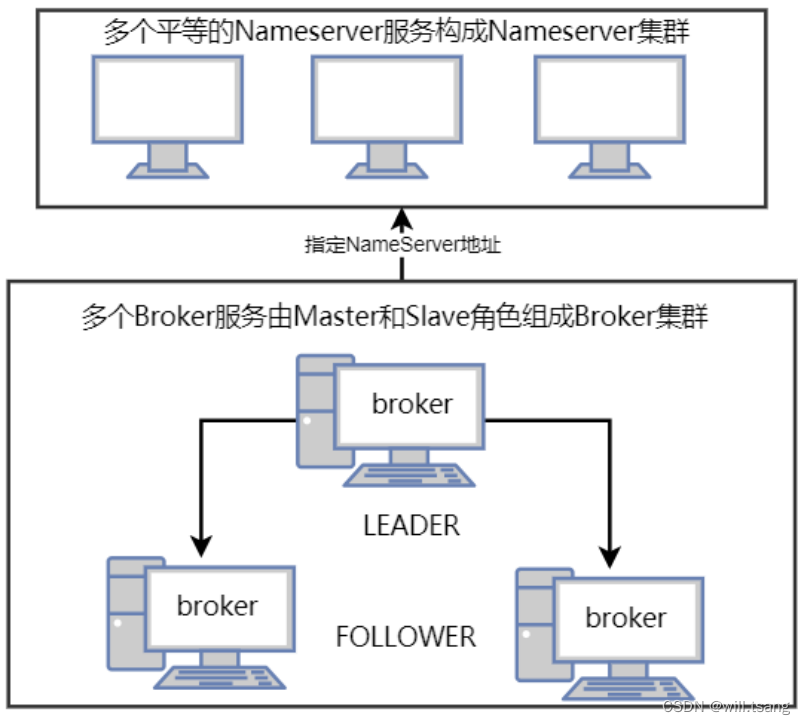
在 Dledger 集群中,就不再单独指定各个 broker 的服务,⽽是由这些 broker 服务⾃⾏进⾏选举,产⽣⼀个 Leader⻆⾊的服务,响应客户端的各种请求。⽽其他的broker 服务,就作为 Follower ⻆⾊,负责对 Leader 上的数据进⾏备份。当然,Follower 所要负责的事情,⽐主从架构中的 SLAVE ⻆⾊会要复杂⼀点,因为这种节点选举是在后端不断进⾏的,他们需要随时做好升级成Leader 的准备。
Dledger 集群的选举是通过 Raft 协议进⾏的, Raft 协议是⼀种多数同意机制。也就是每次选举需要有集群中超过半数的节点确认,才能形成整个集群的共同决定。同时,这也意味着在Dledger 集群中,只要有超过半数的节点能够正常⼯作,那么整个集群就能正常⼯作。因此,在部署Dledger 集群时,通常都是部署奇数台服务,这样可以让集群的容错性达到最⼤。
接下来,我们就⽤之前准备的 3 台服务器,搭建⼀个 3 个节点的 Dledger 集群。在这个集群中,只需要有 2 台Broker服务正常运⾏,这个集群就能正常⼯作。
第⼀步 :部署 nameserver
这⼀步和之前部署主从集群没有区别,不需要做过多的配置,直接在三台服务器上启动 nameserver 服务即可。
实际上,如果你是从上⼀个主从架构开始搭建起来的话,那么 nameserver 集群都不需要重新启动, nameserver会⾃动感知到broker 的变化。
第⼆步 :对 Broker 服务进⾏集群配置。
对于 Dledger 集群的配置, RocketMQ 依然贴⼼的给出了完整的示例,不需要强⾏记忆。
在 conf/dledger ⽬录下, RocketMQ 默认给出了三个配置⽂件,这三个配置⽂件可以在单机情况下直接部署成⼀个具有三个broker 服务的 Dledger 集群,我们只需要按照这个配置进⾏修改即可。

接下来我们可以在三台机器的 conf/dledger ⽬录下,都创建⼀个 broker.conf ⽂件,对每个 broker 服务进⾏配置。
worker1 的 broker.conf 配置示例
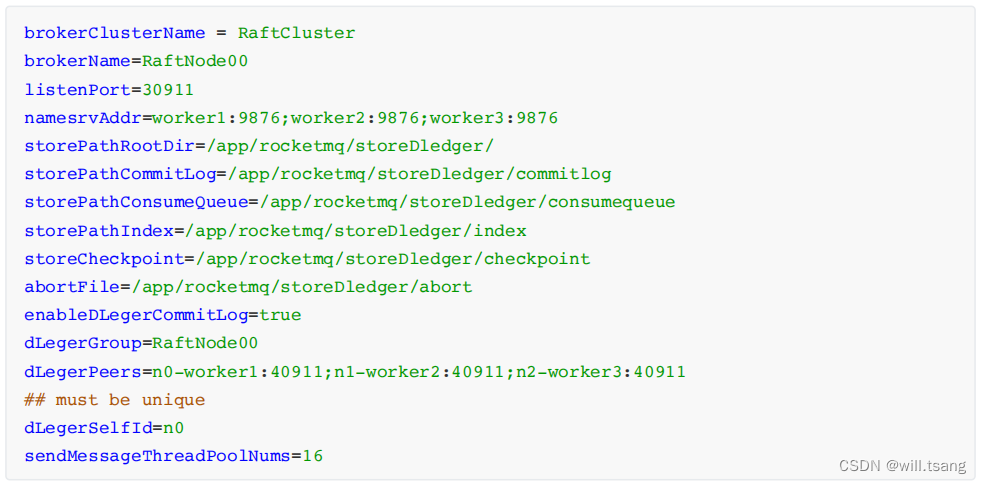
worker2 的 broker.conf 配置示例:

worker3 的 broker.conf 配置示例:

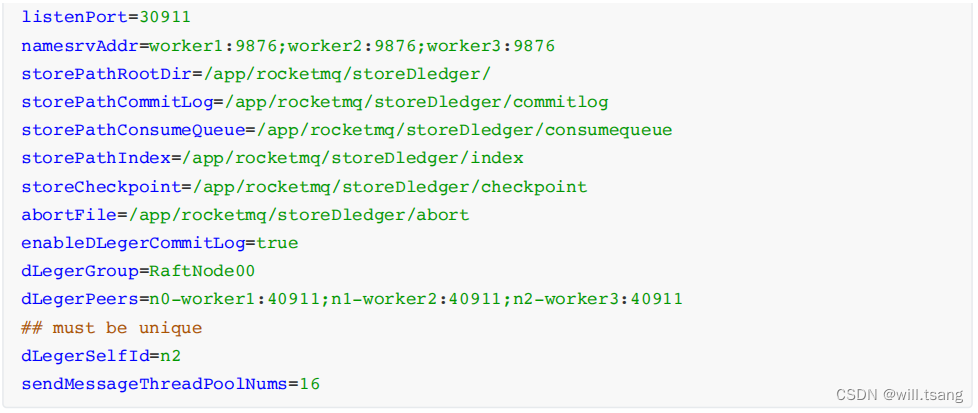
这⾥对⼏个需要重点关注的配置项,做下介绍:
· enableDLegerCommitLog: 是否启动 Dledger 。 true 表示启动
· namesrvAddr: 指定 nameserver 地址
· dLedgerGroup: Dledger Raft Group 的名字,建议跟 brokerName 保持⼀致。
· dLedgerPeers: Dledger Group 内各个服务节点的地址及端⼝信息。同⼀个 Group 内的各个节点配置必须要保持⼀致。
· dLedgerSelfId: Dledger 节点 ID ,必须属于 dLedgerPeers 中的⼀个。同⼀个 Group 内的各个节点必须不能重复。
· sendMessageThreadPoolNums : dLedger 内部发送消息的线程数,建议配置成 cpu 核⼼数。
· store 开头的⼀系列配置: 这些是配置 dLedger 集群的消息存盘⽬录。如果你是从主从架构升级成为 dLedger架构,那么这个地址可以指向之前搭建住主从架构的地址。dLedger 集群会兼容主从架构集群的消息格式,只不过主从架构的消息⽆法享受dLedger 集群的两阶段同步功能。
第三步 :启动 broker 服务
和启动主从架构的 broker 服务⼀样,我们只需要在启动 broker 服务时,指定配置⽂件即可。在三台服务器上分别执⾏以下指令,启动broker 服务。

第四步 :检查集群服务状态
我们可以在 Dashboard 控制台的集群菜单⻚看到 Dledger 集群的运⾏状况。
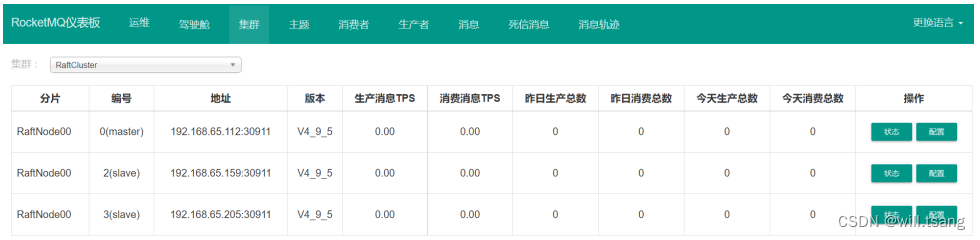
从整个配置过程中可以看到,我们并没有指定每个节点的⻆⾊,⽽ Dledger 集群就⾃动将 192.168.232.129 也就是worker2 上的 broker 服务选举成了 master 。
接下来如果你有兴趣,可以⾃⼰尝试下停⽌ woker2 上的 broker 服务,再重新观察集群的运⾏状况。 RocketMQ会在发现worker2 服务宕机后,很快的选举产⽣新的 master 节点。但具体选举出 worker1 还是 worker3 作为master,则是随机的。
但是,如果你尝试继续停⽌ worker1 或 worker3 上的 broker 服务,那么集群中宕机的 broker 服务就超过了半数,也就是两台。这时这个Dledger 集群就选举不出 master 节点,也就⽆法正常⼯作了。
关于 Dledger 集群的⼀些补充
Dledger 集群机制是 RocketMQ ⾃ 4.5 版本开始⽀持的⼀个重要特性。他其实是由 OpenMessage 组织带⼊RocketMQ的⼀个系列框架。他是⼀个为⾼可⽤、⾼性能、⾼可靠的分布式存储系统提供基础⽀持的组件。他做的事情主要有两个,⼀是在集群中选举产⽣master 节点。 RocketMQ 集群需要⽤这个 master 节点响应客户端的各种请求。⼆是在各种复杂的分布式场景下,保证CommitLog ⽇志⽂件在集群中的强⼀致性。
以下是 ChatGPT 对于 Dledger 的功能描述

其背后的核⼼就是 Raft 协议。这是⼀种强⼤的分布式选举算法,其核⼼是只要集群中超过半数的节点作出的共同决议,就认为是集群最终的共同决议。
Raft 协议通过投票机制保持数据⼀致性。详细的细节,我们这⾥不做过多讨论,只是给你介绍⼀下 Raft 协议⼀个很强⼤的地⽅,就是他解决了分布式集群中的脑裂问题。
关于脑裂问题,这是在集群选举过程中⼀个出现概率不⾼,但是让很多⼈头疼的问题。在分布式集群内,有可能会由于⽹络波动或者其他⼀些不稳定因素,造成集群内节点之间短时间通信不畅通。这时就容易在集群内形成多个包含多个节点的⼩集合。这些集合就会独⽴进⾏选举,各⾃产⽣新的Master 节点。当⽹络恢复畅通后,集群中就有了多个Master 节点。当集群中出现多个 Master 节点后,其他节点就不知道要听从谁的指令了,从⽽造成集群整体⼯作瘫痪。也就是俗话说的“ ⼀⼭不容⼆⻁ ” 。脑裂问题在以 Zookeeper 为代表的早前⼀代分布式⼀致性产品中,是⼀个⾮常头疼的问题。⽽Raft 协议对于脑裂问题,会采⽤随机休眠的机制,彻底解决脑裂问题。 RocketMQ 是 Raft
协议的⼀个重要的成功示例。 Kafka 也在之后基于 Raft 协议,⾃⾏实现了 Kraft 集群机制。
同样,附上 ChatGPT 对于脑裂问题的介绍,供你参考:

注: Dledger 集群由于会接管 RocketMQ 原⽣的⽂件写⼊,所以, Dledger 集群的⽂件写⼊速度⽐ RocketMQ 的原⽣写⼊⽅式是要慢⼀点的。这会对RocketMQ 的性能产⽣⼀些影响。所以,当前版本的 Dledger 集群在企业中⽤得并不是太多。5.0 版本对 Dledger 集群抽出了⼀种 Dledger Controller 模式,也就是只⽤ Dledger 集群的选举功能,⽽不⽤他的Commit ⽂件写⼊功能,这样性能可以得到⼀定的提升。
四、总结 RocketMQ 的运⾏架构
通过之前的⼀系列实验,相信你对 RocketMQ 的运⾏机制有了⼀个⼤概的了解。接下来我们结合⼀下之前实验的过程,来理解⼀下RocketMQ 的运⾏架构。
下图是 RocketMQ 运⾏时的整体架构:
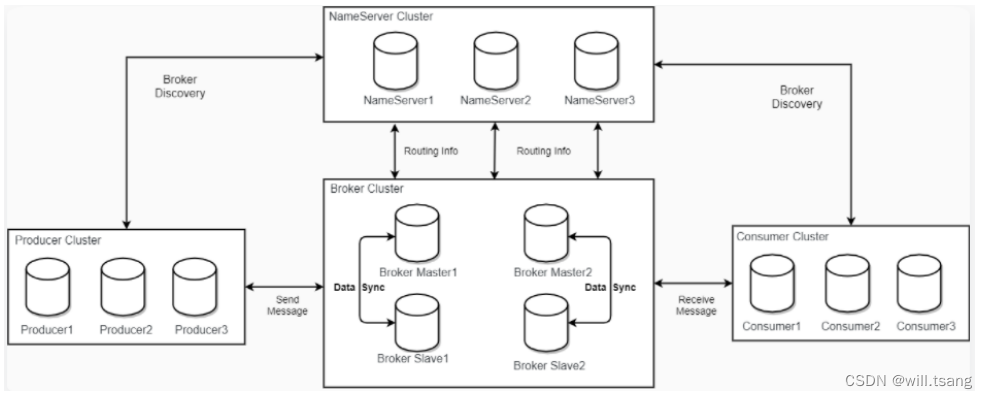
接下来,我们就完整梳理⼀下 RocketMQ 中各个组件的作⽤:
1 、 nameServer 命名服务
在我们之前的实验过程中,你会发现, nameServer 不依赖于任何其他的服务,⾃⼰独⽴就能启动。并且,不管是broker 还是客户端,都需要明确指定 nameServer 的服务地址。以⼀台电脑为例, nameServer 可以理解为是整个RocketMQ 的 CPU ,整个 RocketMQ 集群都要在 CPU 的协调下才能正常⼯作。
2 、 broker 核⼼服务
从之前的实验过程中你会发现, broker 是 RocketMQ 中最为娇贵的⼀个组件。 RockeMQ 提供了各种各样的重要设计来保护broker 的安全。同时 broker 也是 RocketMQ 中配置最为繁琐的部分。同样以电脑为例, broker 就是整个RocketMQ中的硬盘、显卡这⼀类的核⼼硬件。 RocketMQ 最核⼼的消息存储、传递、查询等功能都要由 broker 提供。
3 、 client 客户端
Client 包括消息⽣产者和消息消费者。同样以电脑为例, Client 可以认为是 RocketMQ 中的键盘、⿏标、显示器这类的输⼊输出设备。⿏标、键盘输⼊的数据需要传输到硬盘、显卡等硬件才能进⾏处理。但是键盘、⿏标是不能直接将数据输⼊到硬盘、显卡的,这就需要CPU 进⾏协调。通过 CPU ,⿏标、键盘就可以将输⼊的数据最终传输到核⼼的硬件设备中。经过硬件设备处理完成后,再通过CPU 协调,显示器这样的输出设备就能最终从核⼼硬件设备中获取到输出的数据。
五、理解 RocketMQ 的消息模型
⾸先:我们先来尝试往 RocketMQ 中发送⼀批消息。
在上⼀章节提到, RocketMQ 提供了⼀个测试脚本 tools.sh ,⽤于快速测试 RocketMQ 的客户端。
在服务器上配置了⼀个 NAMESRV_ADDR 环境变量后,就可以直接使⽤ RocketMQ 提供的 tools.sh 脚本,调⽤RocketMQ提供的 Producer 示例。

这⾥调⽤的 Producer 示例实际上是在 RocketMQ 安装⽬录下的 lib/rocketmq-example-4.9.5.jar 中包含的⼀个测试类。tools.sh 脚本则是提供 Producer类的运⾏环境。
Producer这个测试类,会往RocketMQ 中发送⼀千条测试消息。发送消息后,我们可以在控制台看到很多如下的⽇志信息。

这是 RocketMQ 的 Broker 服务端给消息⽣产者的响应。这个响应信息代表的是 Broker 服务端已经正常接收并保存了消息⽣产者发送的消息。这⾥⾯提到了很多topic 、 messageQueue 等概念,这些是什么意思呢?我们不妨先去RocketMQ的 DashBoard 控制台看⼀下 RocketMQ 的 Broker 是如何保存这些消息的。
访问 DashBoard 上的 “ 主题 ” 菜单,可以看到多了⼀个名为 TopicTest 的主题。
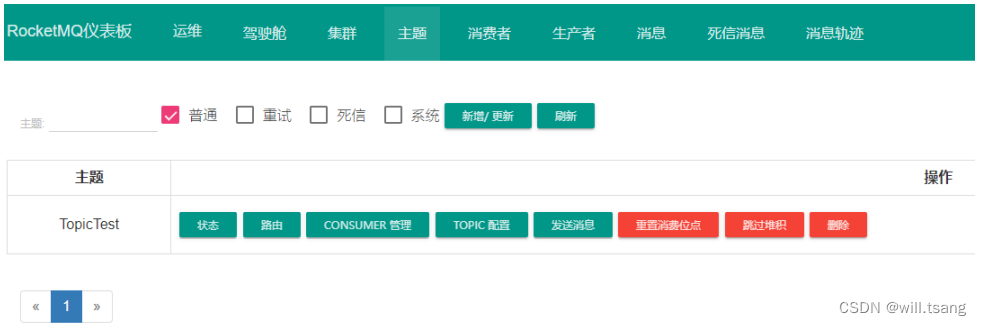
这个 TopicTest 就是我们之前运⾏的 Producer 创建的主题。点击 “ 状态 ” 按钮,可以看到 TopicTest 上的消息分布。

从这⾥可以看到, TopicTest 这个话题下,分配了⼋个 MessageQueue 。这⾥的 MessageQueue 就是⼀个典型的具有FIFO (先进先出)特性的消息集合。这⼋个 MessageQueue 均匀的分布在了集群中的两个 Broker 服务上。每个MesasgeQueue 都记录了⼀个最⼩位点和最⼤位点。这⾥的位点代表每个 MessageQueue 上存储的消息的索引,也称为offset( 偏移量 ) 。每⼀条新记录的消息,都按照当前最⼤位点往后分配⼀个新的位点。这个位点就记录了这⼀条消息的存储位置。
从 Dashboard 就能看到,每⼀个 MessageQueue ,当前都记录了 125 条消息。也就是说,我们之前使⽤Producer示例往 RocketMQ 中发送的⼀千条消息,就被均匀的分配到了这⼋个 MessageQueue 上。
这是,再回头来看之前⽇志中打印的 SendResult 的信息。⽇志中的 MessageQueue 就代表这⼀条消息存在哪个队列上了。⽽queueOffset 就表示这条消息记录在 MessageQueue 的哪个位置。

然后:我们尝试启动⼀个消费者来消费消息
我们同样可以使⽤ tools.sh 来启动⼀个消费者示例。

这个 Consumer 同样是 RocketMQ 下的 lib/rocketmq-example-4.9.5.jar 中提供的消费者示例。 Consumer 启动完成后,我们可以在控制台看到很多类似这样的⽇志:

这⾥⾯也打印出了⼀些我们刚刚熟悉的 brokerName , queueId , queueOffset 这些属性。其中 queueOffset 属性就表示这⼀条消息在MessageQueue 上的存储位点。通过记录每⼀个消息的 Offset 偏移量, RocketMQ 就可以快速的定位到这⼀条消息具体的存储位置,继⽽正确读取到消息的内容。
接下来,我们还是可以到 DashBoard 上印证⼀下消息消费的情况。
在 DashBoard 的 “ 主题 ” ⻚⾯,选择对应主题后的 “CONSUMER 管理 ” 功能,就能看到消费者的消费情况。
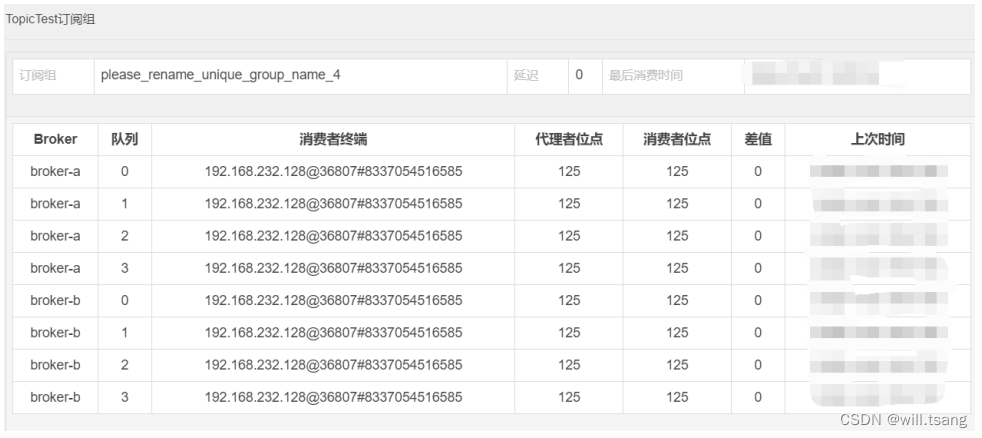
从这⾥可以看到,刚才的 Comsumer 示例启动了⼀个叫做 please_rename_unique_group_name_4 的消费者组。然后这个消费者从⼋个队列中都消费了数据。后⾯的代理者位点记录的是当前MessageQueue 上记录的最⼤消息偏移量。⽽消费者位点记录的是当前消费者组在MessageQueue 上消费的最⼤消息偏移量。其中的差值就表示当前消费者组没有处理完的消息。
并且,从这⾥还可以看出, RocketMQ 记录消费者的消费进度时,都是以 “ 订阅组 ” 为单位的。我们也可以使⽤上⼀章节的示例,⾃⼰另外定义⼀个新的消费者组来消费TopicTest 上的消息。这时, RocketMQ 就会单独记录新消费者组的消费进度。⽽新的消费者组,也能消费到TopicTest 下的所有消息。
接下来:我们就可以梳理出 RocketMQ 的消息记录⽅式
对之前的实验过程进⾏梳理,我们就能抽象出 RocketMQ 的消息模型。如下图所示:
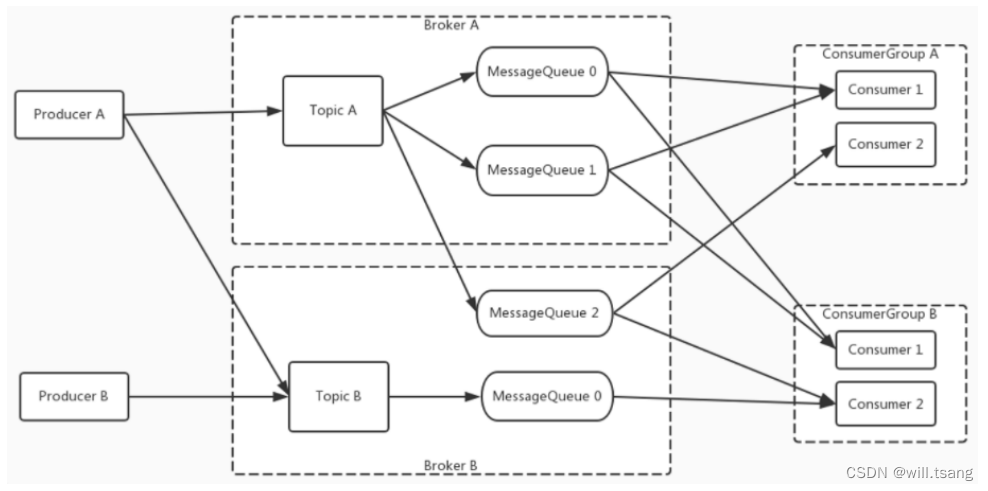
⽣产者和消费者都可以指定⼀个 Topic 发送消息或者拉取消息。⽽ Topic 是⼀个逻辑概念。 Topic 中的消息会分布在后⾯多个MessageQueue 当中。这些 MessageQueue 会分布到⼀个或者多个 broker 中。
在 RocketMQ 的这个消息模型当中,最为核⼼的就是 Topic 。对于客户端, Topic 代表了⼀类有相同业务规则的消息。对于Broker , Topic 则代表了系统中⼀系列存储消息的资源。所以, RocketMQ 对于 Topic 是需要做严格管理的。如果任由客户端随意创建Topic ,那么服务端的资源管理压⼒就会⾮常⼤。默认情况下, Topic 都需要由管理员在RocketMQ 的服务端⼿动进⾏创建,然后才能给客户端使⽤的。⽽我们之前在 broker.conf 中⼿动添加的autoCreateTopic=true,就是表示可以由客户端⾃⾏创建 Topic 。这种配置⽅式显然只适⽤于测试环境,在⽣产环境不建议打开这个配置项。如果需要创建 Topic ,可以交由运维⼈员提前创建 Topic 。
⽽对于业务来说,最为重要的就是消息 Message 了。⽣产者发送到某⼀个 Topic 下的消息,最终会保存在 Topic 下的某⼀个MessageQueue 中。⽽消费者来消费消息时, RocketMQ 会在 Broker 端给每个消费者组记录⼀个消息的消费位点Offset 。通过 Offset 控制每个消费者组的消息处理进度。这样,每⼀条消息,在⼀个消费者组当中只被处理⼀次。

六、章节总结
这⼀章节,主要是快速熟悉 RocketMQ 产品,并通过操作,理解总结 RocketMQ 的运⾏架构以及消息模型。这些抽象的模型和架构,实际上就体现了MQ 产品最为核⼼的设计思想。如果可以的话,最好对⽐之间介绍过的RabbitMQ和 Kafka ,将这⼏个产品进⾏横向对⽐,这样就更能理解设计的精髓。
当然,这只是⼀个基础的消息模型。在⾯对具体业务时, RocketMQ 在这个消息模型的基础上,进⾏了⼤量的业务封装。下⼀章节就会着重了解RocketMQ 针对各种业务场景设计的消息功能。