目录
- Celery介绍
- Celery安装
- Celery使用
- 项目文件和配置
- 启动Celery
- 编写任务
- 调用异步任务
- 查看任务执行状态及结果
- 设置定时和周期性任务
- 配置文件添加任务
- Django Admin添加周期性任务
- 启动任务调度器beat
- Flower监控任务执行状态
- Celery高级用法与注意事项
- 给任务设置最大重试次数
- 不同任务交由不同Queue处理
- 忽略不想要的结果
- 避免启动同步子任务
- Django的模型对象不应该作为参数传递
- 使用on_commit函数处理事务
Celery介绍
Django Web项目中我们经常需要执行耗时的任务比如发送邮件、调用第三方接口、批量处理文件等等,将这些任务异步化放在后台运行可以有效缩短请求响应时间。另外服务器上经常会有定时任务的需求,比如清除缓存、备份数据库等工作。Celery是一个高效的异步任务队列/基于分布式消息传递的作业队列,可以轻松帮我们在Django项目中设置执行异步和周期性任务。
Celery是一个高效的基于分布式消息传递的作业队列。它主要通过消息(messages)传递任务,通常使用一个叫Broker(中间人)来协调client(任务的发出者)和worker(任务的处理者)。 clients发出消息到队列中,broker将队列中的信息派发给 Celery worker来处理。Celery本身不提供消息服务,它支持的消息服务(Broker)有RabbitMQ和Redis。一般推荐Redis,因为其在Django项目中还是首选的缓存后台。
Celery安装
除了安装Celery。因为要使用Redis做消息队列的broker,所以还需要安装Redis。另外如果要设置定时或周期性任务,还需要安装django-celery-beat。
# pip安装必选
Django==3.2
celery==5.0.5
redis==3.5.3# 可选,windows下运行celery 4以后版本,还需额外安装eventlet库
eventlet # 推荐安装, 需要设置定时或周期任务时安装,推荐安装
django-celery-beat==2.2.0# 视情况需要,需要存储任务结果时安装,视情况需要
django-celery-results==2.0.1# 视情况需要,需要监控celery运行任务状态时安装
folower==0.9.7
Celery使用
项目文件和配置
在正式使用celery和django-celery-beat之前,你需要做基础的配置。假如你的Django项目文件夹布局如下所示,你首先需要在myproject/myproject目录下新增celery.py并修改__init__.py。
- myproject/- manage.py- project/- __init__.py # 修改这个文件- celery.py # 新增这个文件- asgi.py- settings.py- urls.py- wsgi.py
新建celery.py,添加如下代码:
import os
from celery import Celery# 设置环境变量
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'myproject.settings')# 实例化
app = Celery('myproject')# namespace='CELERY'作用是允许你在Django配置文件中对Celery进行配置
# 但所有Celery配置项必须以CELERY开头,防止冲突
app.config_from_object('django.conf:settings', namespace='CELERY')# 自动从Django的已注册app中发现任务
app.autodiscover_tasks()# 一个测试任务
@app.task(bind=True)
def debug_task(self):print(f'Request: {self.request!r}')
修改__init__.py,如下所示:
from .celery import app as celery_app
__all__ = ('celery_app',)
接下来修改Django项目的settings.py,添加Celery有关配置选项,如下所示:
# 最重要的配置,设置消息broker,格式为:db://user:password@host:port/dbname
# 如果redis安装在本机,使用localhost
# 如果docker部署的redis,使用redis://redis:6379
CELERY_BROKER_URL = "redis://127.0.0.1:6379/0"# celery时区设置,建议与Django settings中TIME_ZONE同样时区,防止时差
# Django设置时区需同时设置USE_TZ=True和TIME_ZONE = 'Asia/Shanghai'
CELERY_TIMEZONE = TIME_ZONE
其它Celery常用配置选项包括:
# 为django_celery_results存储Celery任务执行结果设置后台
# 格式为:db+scheme://user:password@host:port/dbname
# 支持数据库django-db和缓存django-cache存储任务状态及结果
CELERY_RESULT_BACKEND = "django-db"
# celery内容等消息的格式设置,默认json
CELERY_ACCEPT_CONTENT = ['application/json', ]
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'# 为任务设置超时时间,单位秒。超时即中止,执行下个任务。
CELERY_TASK_TIME_LIMIT = 5# 为存储结果设置过期日期,默认1天过期。如果beat开启,Celery每天会自动清除。
# 设为0,存储结果永不过期
CELERY_RESULT_EXPIRES = xx# 任务限流
CELERY_TASK_ANNOTATIONS = {'tasks.add': {'rate_limit': '10/s'}}# Worker并发数量,一般默认CPU核数,可以不设置
CELERY_WORKER_CONCURRENCY = 2# 每个worker执行了多少任务就会死掉,默认是无限的
CELERY_WORKER_MAX_TASKS_PER_CHILD = 200
完整配置选项见:
- https://docs.celeryproject.org/en/stable/userguide/configuration.html#std-setting-result_expires
注意:
- 在Django中正式编写和执行自己的异步任务前,一定要先测试redis和celery是否安装好并配置成功。
- 一个无限期阻塞的任务会使得工作单元无法再做其他事情,建议给任务设置超时时间。
启动Celery
首先要确定Reid服务已正常启动。
启动redis服务后,你要先进入项目所在文件夹运行python manage.py runserver命令启动Django服务器(无需创建任何app),然后再打开一个终端terminal窗口输入celery命令,启动worker。
# Linux下测试,启动Celery
Celery -A myproject worker -l info# Windows下测试,启动Celery
Celery -A myproject worker -l info -P eventlet# 如果Windows下Celery不工作,输入如下命令
Celery -A myproject worker -l info --pool=solo
如果你能看到[tasks]下所列异步任务清单如debug_task,以及最后一句celery@xxxx ready, 说明你的redis和celery都配置好了,可以开始正式工作了。
-------------- celery@DESKTOP-H3IHAKQ v4.4.2 (cliffs)
--- ***** -----
-- ******* ---- Windows-10-10.0.18362-SP0 2020-04-24 22:02:38- *** --- * ---
- ** ---------- [config]
- ** ---------- .> app: myproject:0x456d1f0
- ** ---------- .> transport: redis://127.0.0.1:6379/0
- ** ---------- .> results: redis://localhost:6379/0
- *** --- * --- .> concurrency: 4 (eventlet)-- ******* ---- .> task events: OFF (enable -E to monitor tasks in this worker)--- ***** ------------------- [queues].> celery exchange=celery(direct) key=celery[tasks]. myproject.celery.debug_task[2020-04-24 22:02:38,484: INFO/MainProcess] Connected to redis://127.0.0.1:6379/0
[2020-04-24 22:02:38,500: INFO/MainProcess] mingle: searching for neighbors
[2020-04-24 22:02:39,544: INFO/MainProcess] mingle: all alone
[2020-04-24 22:02:39,572: INFO/MainProcess] pidbox: Connected to redis://127.0.0.1:6379/0.
[2020-04-24 22:02:39,578: WARNING/MainProcess] c:\users\missenka\pycharmprojects\django-static-html-generator\venv\lib\site-packages\celery\fixups\django.py:203: UserWarning: Using sett
ings.DEBUG leads to a memoryleak, never use this setting in production environments!leak, never use this setting in production environments!''')
[2020-04-24 22:02:39,579: INFO/MainProcess] celery@DESKTOP-H3IHAKQ ready.
编写任务
Celery配置完成后,我们就可以编写任务了。Django项目中所有需要Celery执行的异步或周期性任务都放在tasks.py文件里,该文件可以位于project目录下,也可以位于各个app的目录下。专属于某个Celery实例化项目的task可以使用@app.task装饰器定义,各个app目录下可以复用的task建议使用@shared_task定义。
两个示例如下所示:
# myproject/tasks.py
# 专属于myproject项目的任务
app = Celery('myproject')
@ app.task
def test():pass# app/tasks.py, 可以复用的task
from celery import shared_task
import time@shared_task
def add(x, y):time.sleep(2)return x + y
上面我们定义一个名为add的任务,它接收两个参数,并返回计算结果。为了模拟耗时任务,我们中途让其sleep 2秒。现在已经定义了一个耗时任务,后面再看如何调用。
注意:
- 使用celery定义任务时,避免在一个任务中调用另一个异步任务,容易造成阻塞。
- 当我们使用
@app.task装饰器定义我们的异步任务时,那么这个任务依赖于根据项目名myproject生成的Celery实例。然而我们在进行Django开发时为了保证每个app的可重用性,我们经常会在每个app文件夹下编写异步任务,这些任务并不依赖于具体的Django项目名。使用@shared_task装饰器能让我们避免对某个项目名对应Celery实例的依赖,使app的可移植性更强。
调用异步任务
Celery提供了2种以异步方式调用任务的方法,delay和apply_async方法,如下所示:
# 方法一:delay方法
task_name.delay(args1, args2, kwargs=value_1, kwargs2=value_2)# 方法二: apply_async方法,与delay类似,但支持更多参数
task.apply_async(args=[arg1, arg2], kwargs={key:value, key:value})
我们接下来看一个具体的例子。我们编写了一个Django视图函数,使用delay方法调用add任务。
# app/views.py
from .tasks import adddef test_celery(request):# 使用delay调用异步任务add.delay(3, 5)return HttpResponse("Celery works")# app/urls.py
urlpatterns = [re_path(r'^test/$', views.test_celery, name="test_celery")
]
当你通过浏览器访问/test/链接时,你根本感受不到2s的延迟,页面可以秒开,同时你会发现终端的输出如下所示,显示任务执行成功。
我们现在再次使用apply_async方法调用add任务,不过还要打印初任务的id (task.id)和状态status。Celery会为每个加入到队列的任务分配一个独一无二的uuid, 你可以通过task.status获取状态和task.result获取结果。注意:apply_async传递参数的方式与delay方法不同。
# app/views.py
from .tasks import adddef test_celery(request):result = add.apply_async(args=[3, 5])return HttpResponse(result.task_id + ' : ' + result.status)
Django返回响应结果如下所示。这是在预期之内的,因为Django返回响应时任务还未执行完毕。
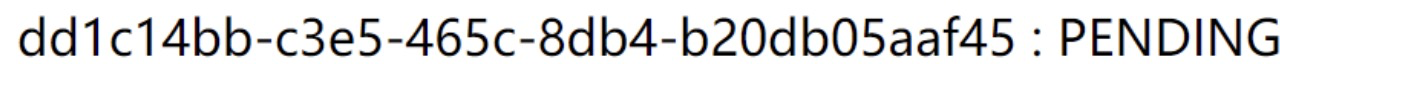
那么问题来了,这个异步任务执行了,返回了个计算结果(8),那么我们系统性地了解任务状态并获取这个执行结果呢? 答案是django-celery-results。
查看任务执行状态及结果
通过pip安装django-celery-results后,需要将其加入到INSTALLED_APPS并使用migrate命令迁移创建数据表。以下几项配置选项是与这个库相关的。
# 支持数据库django-db和缓存django-cache存储任务状态及结果
# 建议选django-db
CELERY_RESULT_BACKEND = "django-db"
# celery内容等消息的格式设置,默认json
CELERY_ACCEPT_CONTENT = ['application/json', ]
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
安装配置完成后,进入Django admin后台,你就可以详细看到每个任务的id、名称及状态。
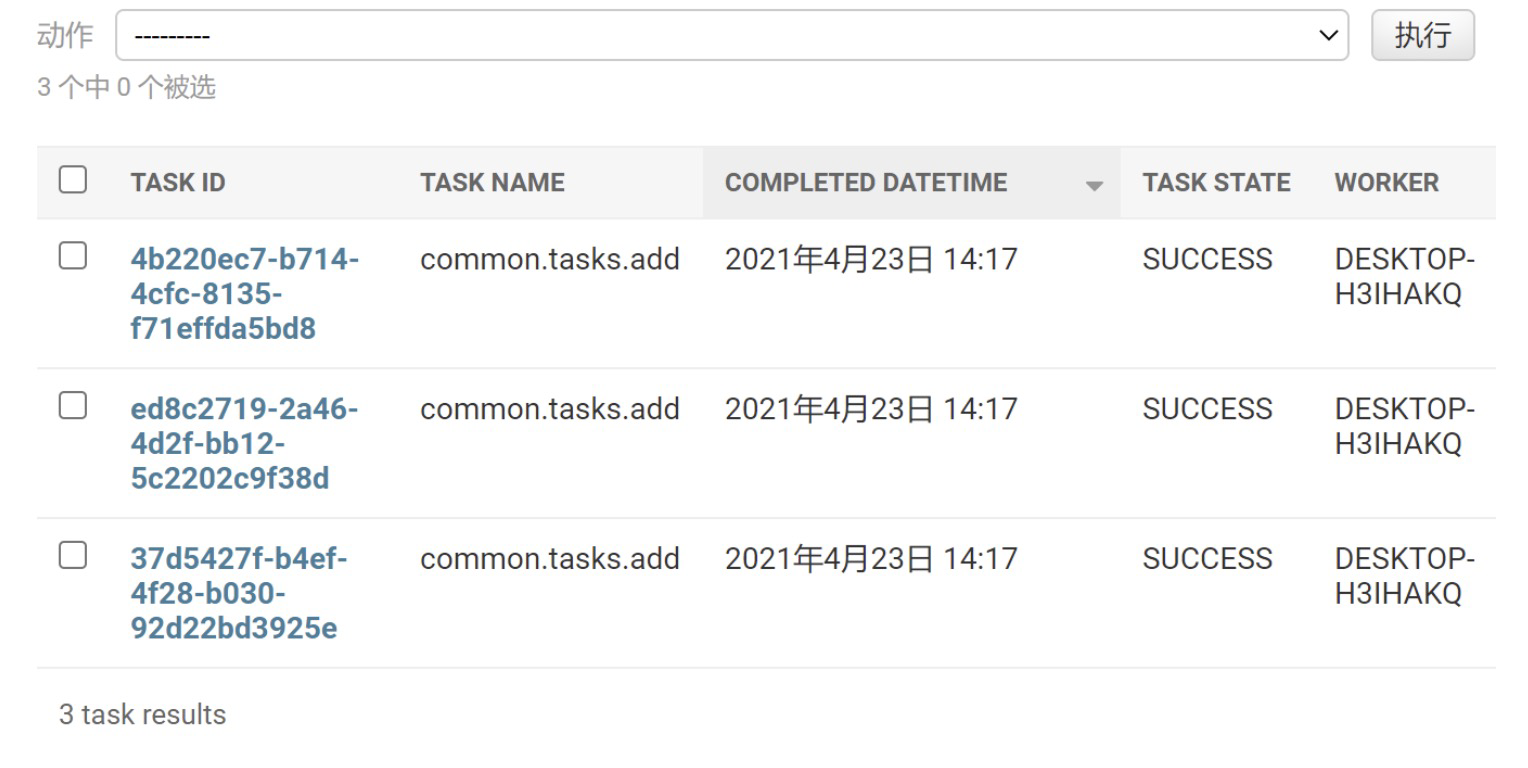
点击单个任务id,你可以看到有关这个任务的更多信息,比如传递的参数和返回结果,如下所示:

除了在Django admin后台中查看任务状态和结果,你还可以在视图中通过AsyncResult方法获取任务执行状态和结果,它需要接收一个任务的task_id(通常为uuid格式)。
from celery.result import AsyncResult
# 调用异步任务
async_task = add.apply_async(args=[3, 5])
# 获取任务状态和结果
AsyncResult(async_task.task_id).status
AsyncResult(async_task.task_id).result
设置定时和周期性任务
借助于装django-celery-beat后, 你可以将任一Celery任务设置为定时任务或周期性任务。使用它你只需要通过pip安装它,并加入INSTALLED_APPS里去。
django-celery-beat提供了两种添加定时或周期性任务的方式,一是直接在settings.py中添加,二是通过Django admin后台添加。
配置文件添加任务
同一任务可以设置成不同的调用周期,给它们不同的任务名就好了。
from datetime import timedelta
CELERY_BEAT_SCHEDULE = {"add-every-30s": {"task": "app.tasks.add",'schedule': 30.0, # 每30秒执行1次'args': (3, 8) # 传递参数-},"add-every-day": {"task": "app.tasks.add",'schedule': timedelta(hours=1), # 每小时执行1次'args': (3, 8) # 传递参数-},
}
Django Admin添加周期性任务
先在settings.py中将任务调度器设为DatabaseScheduler
CELERY_BEAT_SCHEDULER = 'django_celery_beat.schedulers:DatabaseScheduler'
然后进入Periodic Task表添加和修改周期性任务即可。

如果你希望在特定的时间(某月某周或某天)执行一个任务,你可以通过crontab设置定时任务,如下例所示:
CELERY_BEAT_SCHEDULE = {# 每周一早上7点半执行'add-every-monday-morning': {'task': 'app.tasks.add','schedule': crontab(hour=7, minute=30, day_of_week=1),'args': (7, 8),},
}
更多Crontab定义案例如下所示:
| 例子 | 含义 |
|---|---|
crontab() | 每分 |
crontab(minute=0, hour=0) | 每天午夜 |
crontab(minute=0, hour='*/3') | 能被3整除的小时数,3,6,9点等等 |
crontab(minute=0,``hour='0,3,6,9,12,15,18,21') | 与前面相同,指定小时 |
crontab(minute='*/15') | 每15分钟 |
crontab(day_of_week='sunday') | 星期日每分钟 |
crontab(minute='*',``hour='*', day_of_week='sun') | 同上 |
crontab(minute='*/10',``hour='3,17,22', day_of_week='thu,fri') | 每10分钟运行一次, 但仅限于周四或周五的 3-4 am, 5-6 pm, 和10-11 pm. |
crontab(minute=0, hour='*/2,*/3') | 可以被2或3整除的小时数,除了 1am, 5am, 7am, 11am, 1pm, 5pm, 7pm, 11pm |
crontab(minute=0, hour='*/5') | 可以被5整除的小时 |
crontab(minute=0, hour='*/3,8-17') | 8am-5pm之间可以被3整除的小时 |
crontab(0, 0, day_of_month='2') | 每个月的第2天 |
crontab(0, 0,``day_of_month='2-30/2') | 每月的偶数日 |
crontab(0, 0,``day_of_month='1-7,15-21') | 每月的第一和第三周 |
crontab(0, 0, day_of_month='11',``month_of_year='5') | 每年的5月11日 |
crontab(0, 0,``month_of_year='*/3') | 每个季度首个月份每天 |
Crontab也可以通过Django Admin添加,然后与任务进行绑定。
如果你变换了时区timezone,比如从’UTC’变成了’Asia/Shanghai’,需重置周期性任务,这非常重要。
# 调整timezone后重置任务
$ python manage.py shell
>>> from django_celery_beat.models import PeriodicTask
>>> PeriodicTask.objects.update(last_run_at=None)
前面我们只是添加了定时或周期性任务,我们还需要启动任务调度器beat分发定时和周期任务给Celery的worker。
启动任务调度器beat
多开几个终端,一个用来启动任务调度器beat,另一个启动celery worker,你的任务就可以在后台执行啦。
# 开启任务调度器
Celery -A myproject beat# Linux下开启Celery worker
Celery -A myproject worker -l info# windows下开启Celery worker
Celery -A myproject worker -l info -P eventlet# windows下如果报Pid错误
Celery -A myproject worker -l info --pool=solo
Flower监控任务执行状态
除了django_celery_results, 你可以使用flower监控后台任务执行状态。它提供了一个可视化的界面,在测试环境中非常有用。
pip install flower
安装好后,你有如下两种方式启动服务器。启动服务器后,打开http://localhost:5555即可查看监控情况。
# 从terminal终端启动, proj为项目名
$ flower -A proj --port=5555
# 从celery启动
$ celery flower -A proj --address=127.0.0.1 --port=5555
Celery高级用法与注意事项
给任务设置最大重试次数
定义任务时可以通过max_retries设置最大重试次数,并调用self.retry方法调用。因为要调用self这个参数,定义任务时必须设置bind=True。
@shared_task(bind=True, max_retries=3)
def send_batch_notifications(self):try:something_raising()raise Exception('Can\'t send email.')except Exception as exc:self.retry(exc=exc, countdown=5)send_mail(subject='Batch email notifications',message='Test email',from_email='no-reply@example.com',recipient_list=['john@example.com'])
不同任务交由不同Queue处理
不同的任务所需要的资源和时间不一样的。为了防止一些非常占用资源或耗时的任务阻塞任务队列导致一些简单任务也无法执行,可以将不同任务交由不同的Queue处理。下例定义了两个Queue队列,default执行普通任务,heavy_tasks执行重型任务。
CELERY_TASK_DEFAULT_QUEUE = 'default'
CELERY_TASK_DEFAULT_ROUTING_KEY = 'default'
CELERY_QUEUES = (Queue('default', Exchange('default'), routing_key='default'),Queue('heavy_tasks', Exchange('heavy_tasks'), routing_key='heavy_tasks'),
)
CELERY_TASK_ROUTES = {'myapp.tasks.heave_tasks': 'heavy_tasks'
}
忽略不想要的结果
如果你不在意任务的返回结果,可以设置 ignore_result 选项,因为存储结果耗费时间和资源。你还可以可以通过 task_ignore_result 设置全局忽略任务结果。
@app.task(ignore_result=True)
def my_task():something()
避免启动同步子任务
让一个任务等待另外一个任务的返回结果是很低效的,并且如果工作单元池被耗尽的话这将会导致死锁。
# 坏例子
@app.task
def update_page_info(url):page = fetch_page.delay(url).get()info = parse_page.delay(url, page).get()store_page_info.delay(url, info)@app.task
def fetch_page(url):return myhttplib.get(url)@app.task
def parse_page(url, page):return myparser.parse_document(page)@app.task
def store_page_info(url, info):return PageInfo.objects.create(url, info)
# 好例子
def update_page_info(url):# fetch_page -> parse_page -> store_pagechain = fetch_page.s(url) | parse_page.s() | store_page_info.s(url)chain()@app.task()
def fetch_page(url):return myhttplib.get(url)@app.task()
def parse_page(page):return myparser.parse_document(page)@app.task(ignore_result=True)
def store_page_info(info, url):PageInfo.objects.create(url=url, info=info)
在好例子里,我们将不同的任务签名链接起来创建一个任务链,三个子任务按顺序执行。
Django的模型对象不应该作为参数传递
Django 的模型对象不应该作为参数传递给任务。几乎总是在任务运行时从数据库获取对象是最好的,因为老的数据会导致竞态条件。假象有这样一个场景,你有一篇文章,以及自动展开文章中缩写的任务:
class Article(models.Model):title = models.CharField()body = models.TextField()@app.task
def expand_abbreviations(article):article.body.replace('Old text', 'New text')article.save()
首先,作者创建一篇文章并保存,这时作者点击一个按钮初始化一个缩写展开任务:
>>> article = Article.objects.get(id=102)
>>> expand_abbreviations.delay(article)
现在,队列非常忙,所以任务在2分钟内都不会运行。与此同时,另一个作者修改了这篇文章,当这个任务最终运行,因为老版本的文章作为参数传递给了这个任务,所以这篇文章会回滚到老的版本。修复这个竞态条件很简单,只要参数传递文章的 id 即可,此时可以在任务中重新获取这篇文章:
@app.task
def expand_abbreviations(article_id):article = Article.objects.get(id=article_id)article.body.replace('MyCorp', 'My Corporation')article.save()
使用on_commit函数处理事务
我们再看另外一个celery中处理事务的例子。这是在数据库中创建一个文章对象的 Django 视图,此时传递主键给任务。它使用 commit_on_success 装饰器,当视图返回时该事务会被提交,当视图抛出异常时会进行回滚。
from django.db import transaction@transaction.commit_on_success
def create_article(request):article = Article.objects.create()expand_abbreviations.delay(article.pk)
如果在事务提交之前任务已经开始执行会产生一个竞态条件;数据库对象还不存在。解决方案是使用 on_commit 回调函数来在所有事务提交成功后启动任务。
from django.db.transaction import on_commitdef create_article(request):article = Article.objects.create()on_commit(lambda: expand_abbreviations.delay(article.pk))
参考:
https://pythondjango.cn/django/advanced/12-sync-periodic-tasks-with-celery/