Elasticsearch,一个强大的开源搜索和分析引擎,已经在全球范围内被广泛应用于各种场景,包括网站搜索、日志分析、实时应用等。由于其强大的功能和灵活性,Elasticsearch 已经成为大数据处理的重要工具。然而,对于许多初次接触 Elasticsearch 的人来说,如何正确安装和配置 Elasticsearch 可能会有些困惑。因此,本文将详细介绍如何在不同的操作系统上安装 Elasticsearch,帮助你快速搭建起 Elasticsearch 的开发或测试环境。
文章目录
- 1、Elasticsearch安装步骤
- 1.1、下载
- 1.2、解压
- 1.3、启动
- 1.4、验证
- 1.5、注意
- 2、Postman交互
- 1.1、检查 Elasticsearch 服务状态
- 1.2、创建一个新的索引
- 1.3、获取指定索引的信息
- 1.4、添加文档
- 1.5、查询指定索引中的所有文档
- 2.6、其他
1、Elasticsearch安装步骤
1.1、下载
官网下载地址:https://www.elastic.co/cn/downloads/elasticsearch
选择对应配置与版本下载:
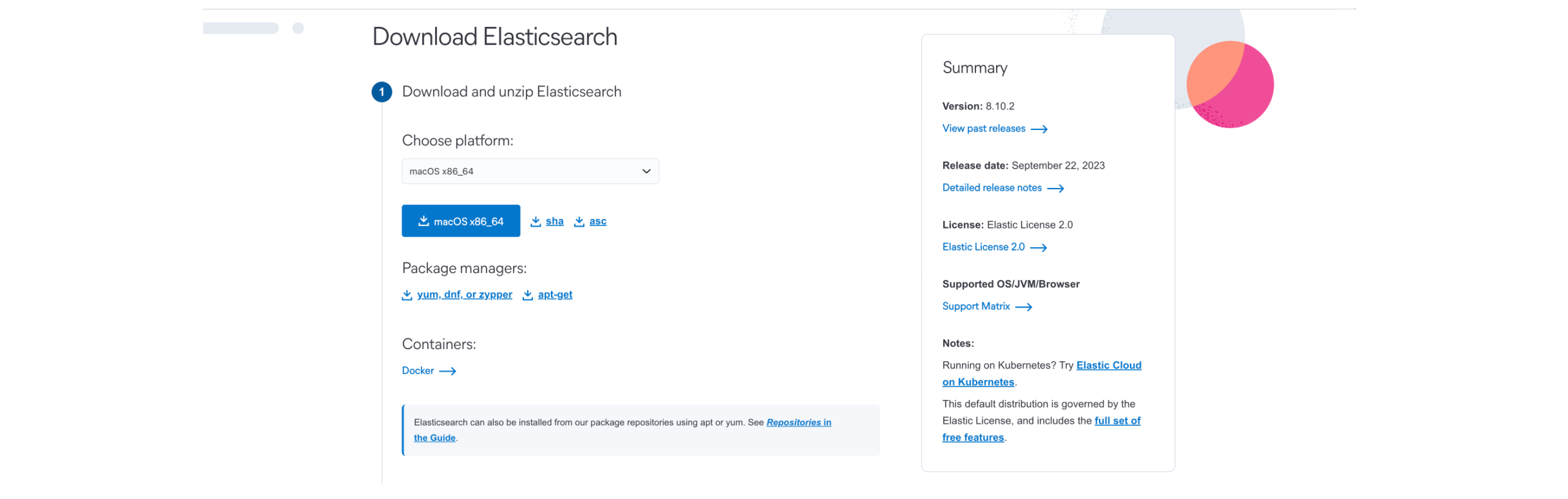
1.2、解压
下载压缩包后解压
1.3、启动
其实不存在什么安装不安装,解压完之后 ES 就能直接用了,我们打开文件包,再打开 bin/ 目录,然后打开这个叫 elasticsearch 的文件,即可启动 ElasticSearch::

打开之后等一等:
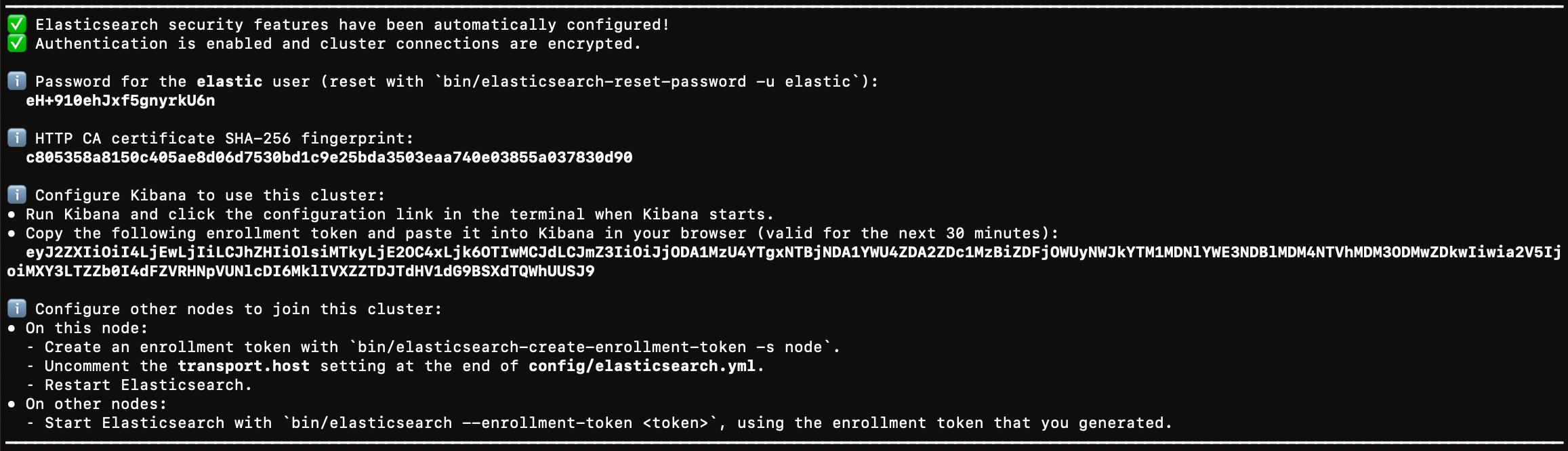
1.4、验证
Elasticsearch 默认使用端口为 9200,我们打开浏览器,输入域名:
http://localhost:9200/
可以看到:

至此,恭喜你,ElasticSearch 安装成功了。
1.5、注意
如果报错:
received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/[0:0:0:0:0:0:0:1]:9200
原因是 Elasticsearch 开启了安全认证,虽然 started 成功,但访问 http://localhost:9200/ 失败。
解决方案:
找到 config/ 目录下面的 elasticsearch.yml 配置文件,把安全认证开关从原先的 true 都改成 false,实现免密登录访问即可,修改这两处都为 false 后:

2、Postman交互
Elasticsearch 可以与 Postman 交互。Elasticsearch 提供了 RESTful API,可以通过 HTTP 请求进行交互,而 Postman 是一个非常流行的 API 测试工具,可以用来发送 HTTP 请求,因此可以用来与 Elasticsearch 进行交互。
1.1、检查 Elasticsearch 服务状态
方法:GET
URL:http://localhost:9200/
这个 API 用于检查 Elasticsearch 服务的状态,它没有入参。
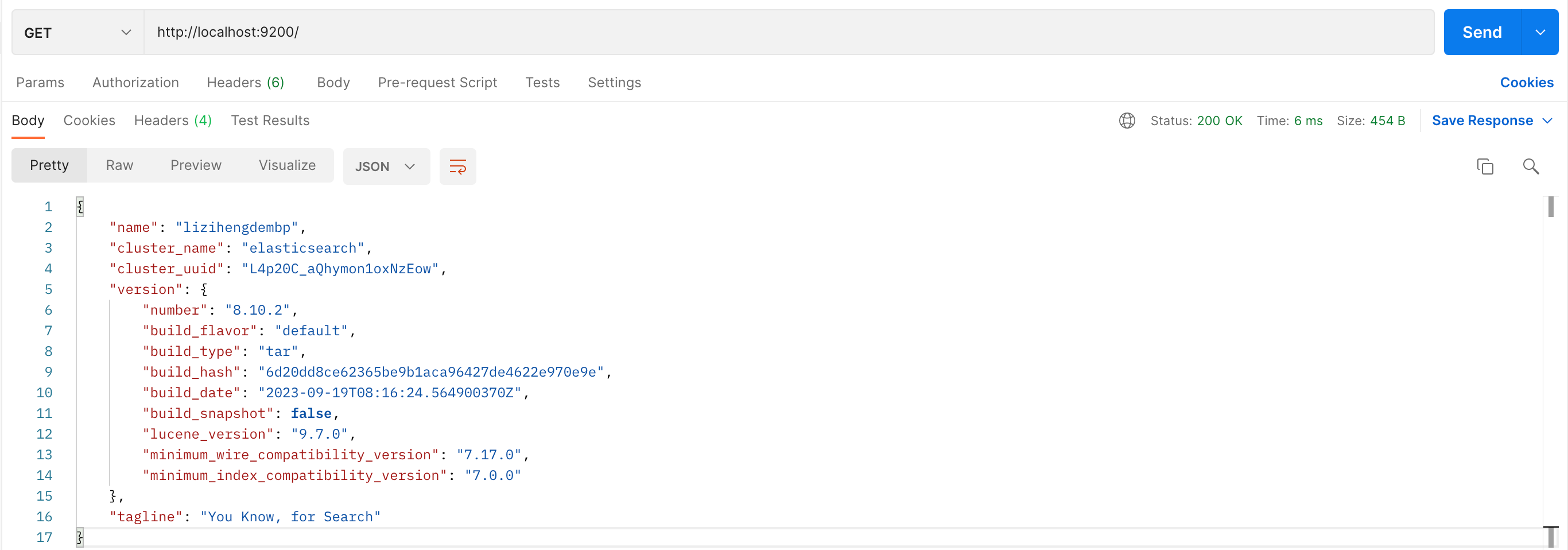
出参 JSON 对象包含了以下信息:
name:节点名称;cluster_name:集群名称;cluster_uuid:集群的唯一标识符;version:包含了关于 Elasticsearch 版本的一些信息,如版本号、构建类型、构建日期等;tagline:Elasticsearch 的标语
通过这个 API,你可以快速检查 Elasticsearch 服务是否正常运行,以及获取服务的一些基本信息。
1.2、创建一个新的索引
方法:PUT
URL:http://localhost:9200/my_index
这个 API 用于创建一个名为 my_index 的新索引

当你发送这个 PUT 请求后,如果索引创建成功,Elasticsearch 会返回一个 JSON 对象,包含了一些关于操作的信息。
这个 JSON 对象包含了以下信息:
acknowledged:如果为 true,表示索引创建请求已经被成功接收。shards_acknowledged:如果为 true,表示索引创建操作已经在所有分片上成功完成。index:创建的索引名称。
1.3、获取指定索引的信息
方法:GET
URL:`http://localhost:9200/my_index`
这个 API 用于获取名为 my_index 的索引的信息。
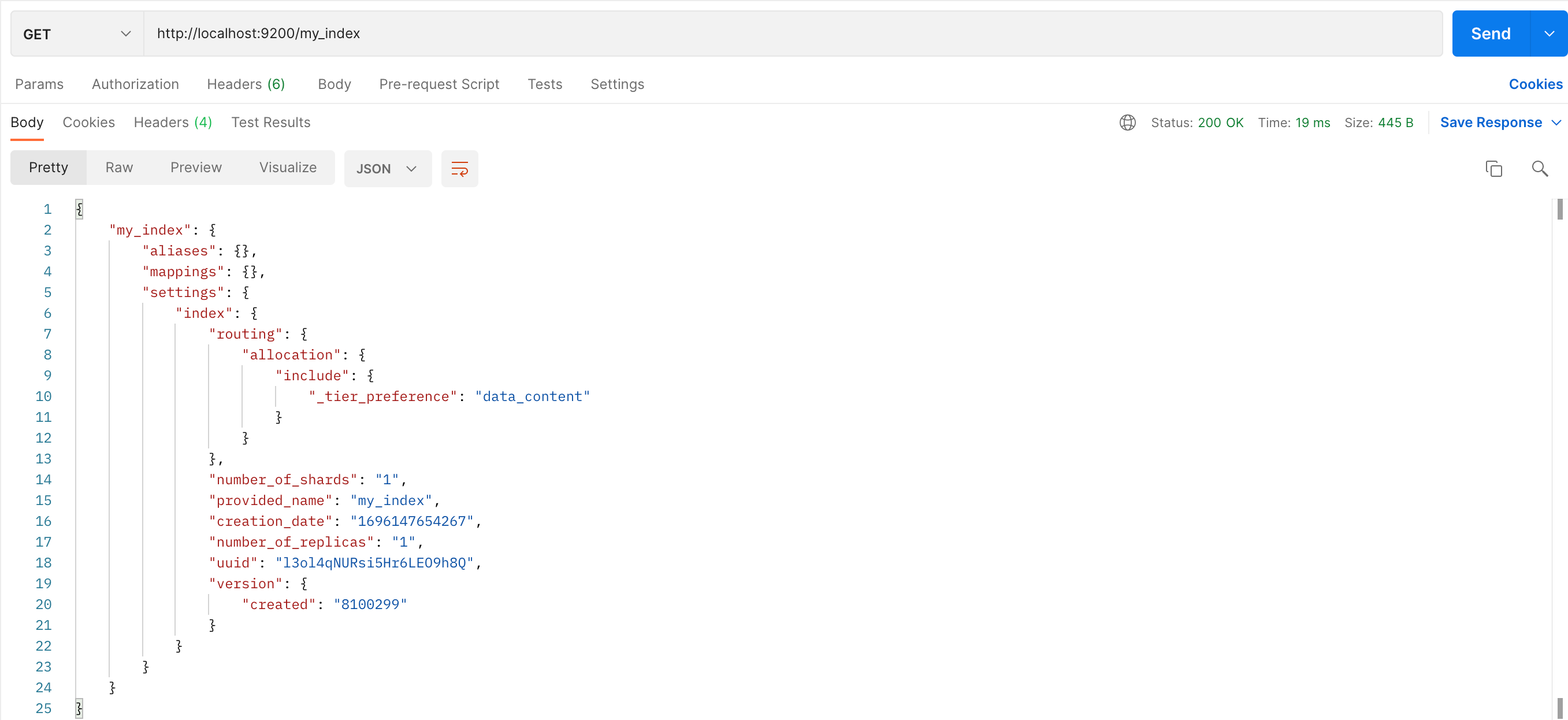
当你发送这个 GET 请求后,如果索引存在,Elasticsearch 会返回一个 JSON 对象,包含了索引的一些信息。
这个 JSON 对象包含了以下信息:
- my_index:索引的名称。
aliases:索引的别名;mappings:索引的映射信息,包括字段名称、字段类型等;settings:索引的设置信息,包括创建日期、分片数量、副本数量、UUID、版本等。
通过这个 API,你可以获取 Elasticsearch 索引的详细信息。
1.4、添加文档
方法:POST
URL:`http://localhost:9200/my_index/_doc`
这个 API 用于在 my_index 索引中添加一个新的文档。
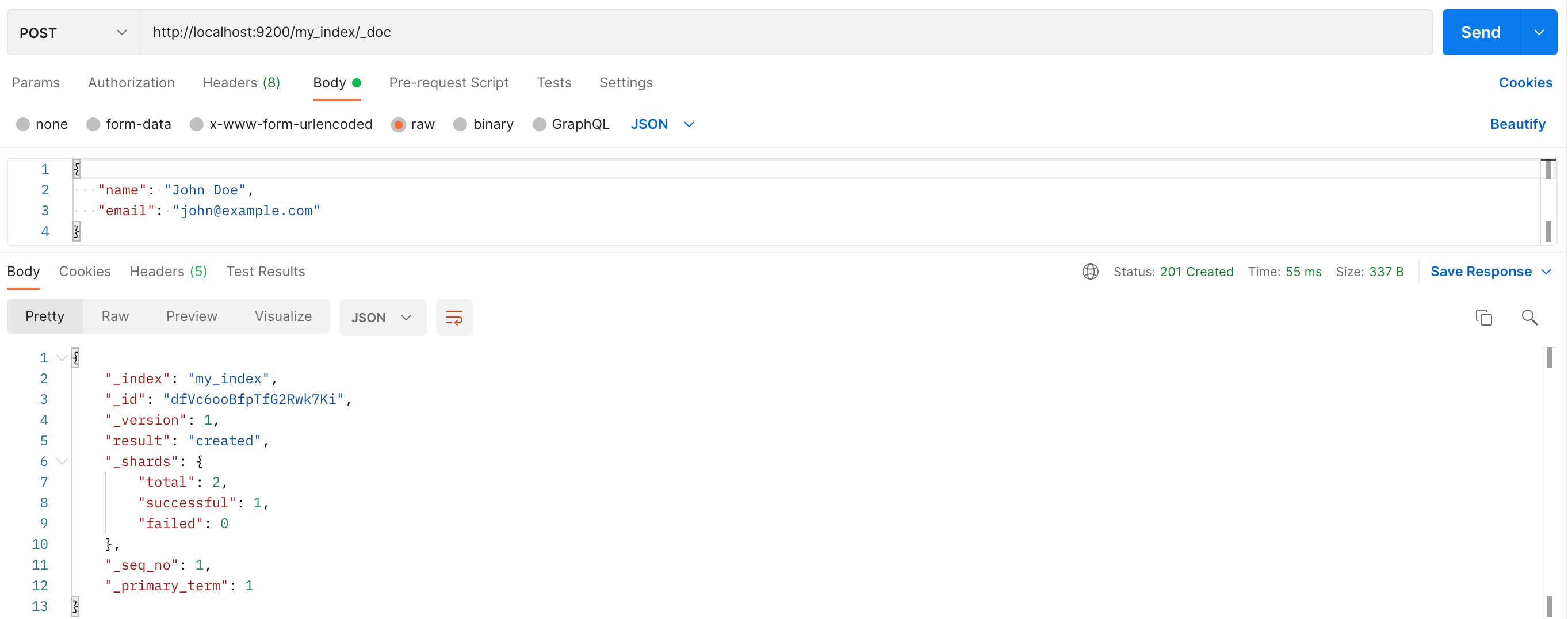
在这个例子中,我们添加了一个新的文档,包含两个字段:name 和 email。
当你发送这个 POST 请求后,如果添加成功,Elasticsearch 会返回一个 JSON 对象,包含了一些关于操作的信息。
这个 JSON 对象包含了以下信息:
_index:文档所在的索引名称。_type:文档的类型(如果有的话)。_id:新添加的文档的 ID。_version:文档的版本号,新添加的文档的版本号为 1。result:操作的结果,这里是 “created”,表示文档已被创建。_shards:操作涉及的分片数量,包括总数、成功数和失败数。_seq_no:操作的序列号。_primary_term:操作的主要术语。
通过这个 API,你可以在 Elasticsearch 索引中添加新的文档。
1.5、查询指定索引中的所有文档
方法:GET
URL:http://localhost:9200/my_index/_search
这个 API 用于查询 my_index 索引中的所有文档
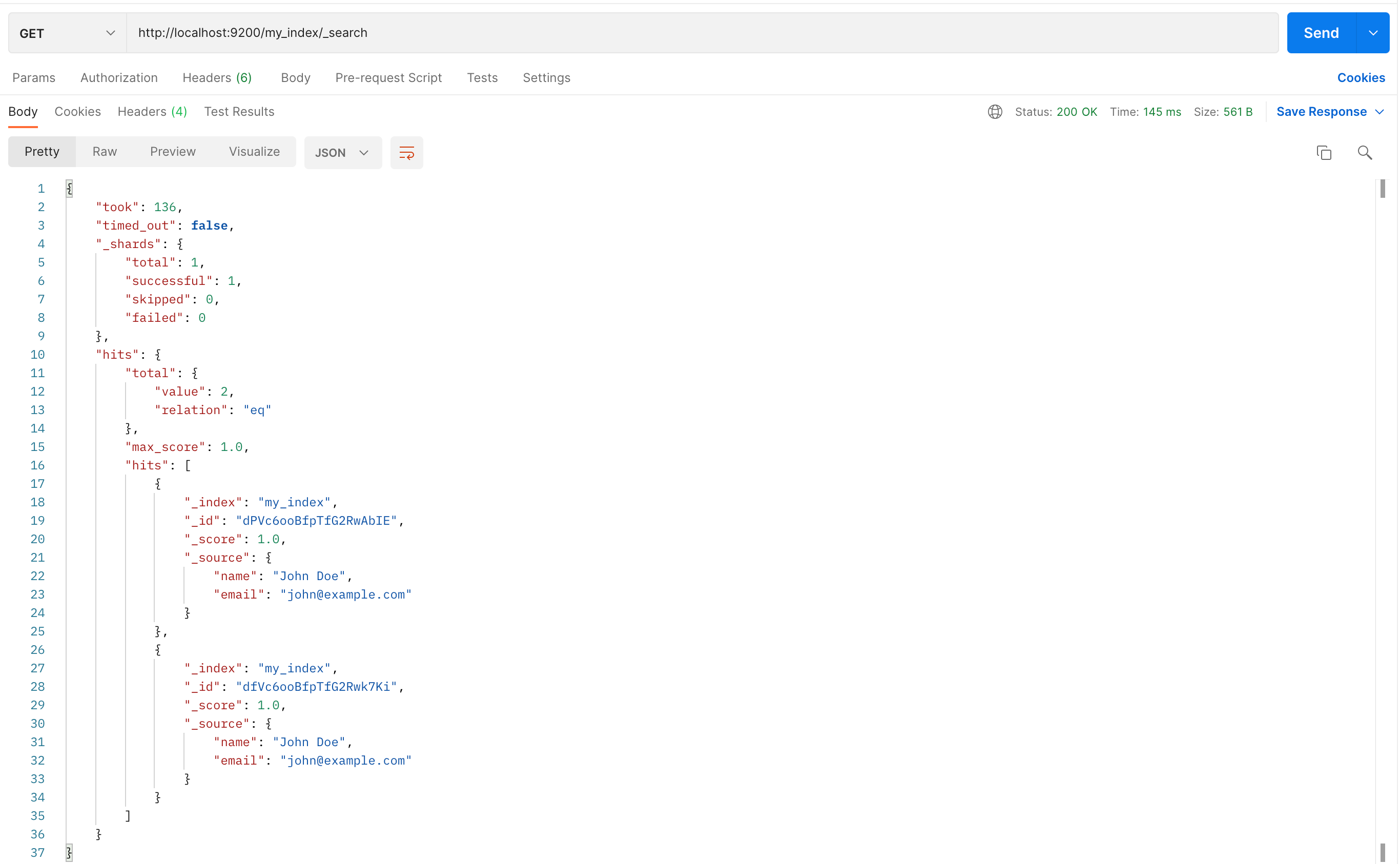
当你发送这个 GET 请求后,Elasticsearch 会返回一个 JSON 对象,包含了查询结果。
这个 JSON 对象包含了以下信息:
took:查询操作花费的时间(毫秒)。timed_out:如果为 true,表示查询操作超时。_shards:查询操作涉及的分片数量,包括总数、成功数、跳过数和失败数。hits:查询结果。total:匹配的文档总数。max_score:匹配文档的最大得分。hits:一个数组,包含了匹配的文档。每个文档包括索引名称、文档类型、文档 ID、得分和源文档内容。
通过这个 API,你可以查询 Elasticsearch 索引中的所有文档。
2.6、其他
-
获取文档
方法:GET
URL:
http://localhost:9200/my_index/_doc/1 -
更新文档
方法:POST
URL:
http://localhost:9200/my_index/_update/1Body(选择 raw 和 JSON 格式):
{"doc": {"name": "Jane Doe"} } -
删除文档
方法:DELETE
URL:
http://localhost:9200/my_index/_doc/1 -
查询所有文档
方法:GET
URL:
http://localhost:9200/my_index/_search -
复杂查询
方法:GET
URL:
http://localhost:9200/my_index/_searchBody(选择 raw 和 JSON 格式):
{"query": {"match": {"name": "John Doe"}} } -
删除索引
方法:DELETE
URL:
http://localhost:9200/my_index -
批量添加文档
方法:POST
URL:
http://localhost:9200/my_index/_bulkBody(选择 raw 和 JSON 格式):
{ "index" : { "_id" : "1" } } { "name" : "John Doe", "email" : "john@example.com" } { "index" : { "_id" : "2" } } { "name" : "Jane Doe", "email" : "jane@example.com" } -
获取多个文档
方法:GET
URL:
http://localhost:9200/my_index/_mgetBody(选择 raw 和 JSON 格式):
{"ids" : ["1", "2"] } -
统计文档数量
方法:GET
URL:
http://localhost:9200/my_index/_count -
范围查询
方法:GET
URL:http://localhost:9200/my_index/_search
Body(选择 raw 和 JSON 格式):
{"query": {"range" : {"age" : {"gte" : 10,"lte" : 20}}}
}
- 排序查询
方法:GET
URL:http://localhost:9200/my_index/_search
Body(选择 raw 和 JSON 格式):
{"query" : {"match_all" : {}},"sort" : [{ "age" : "desc" }]
}
- 聚合查询
方法:GET
URL:http://localhost:9200/my_index/_search
Body(选择 raw 和 JSON 格式):
{"aggs" : {"avg_age" : { "avg" : { "field" : "age" } }}
}
- 高亮查询
方法:GET
URL:http://localhost:9200/my_index/_search
Body(选择 raw 和 JSON 格式):
{"query" : {"match" : { "name" : "John Doe" }},"highlight" : {"fields" : {"name" : {}}}
}
- 删除所有文档
方法:POST
URL:http://localhost:9200/my_index/_delete_by_query
Body(选择 raw 和 JSON 格式):
{"query": {"match_all": {}}
}
- 创建别名
方法:POST
URL:http://localhost:9200/_aliases
Body(选择 raw 和 JSON 格式):
{"actions" : [{ "add" : { "index" : "my_index", "alias" : "my_alias" } }]
}
-
获取集群健康状态
方法:GET
URL:
http://localhost:9200/_cluster/health