前言
视频编辑和修复确实是随着电子产品的普及变得越来越重要的技能。有许多视频编辑工具可以帮助人们轻松完成这些任务如:Adobe Premiere Pro,Final Cut Pro X,Davinci Resolve,HitFilm Express,它们都提供一些视频修复功能,但并不适合没有太多专业技术的用户。
至于视频目标移除、水印移除、掩码补全和视频外扩等高级功能,通常需要使用更专业的图像处理工具,如Adobe After Effects或Adobe Photoshop,这些工具需要一定的学习曲线。
ProPainter是由南洋理工大学的S-Lab团队开发的一款视频智能修复算法,ProPainter完成:视频目标移除、视频水印移除、视频掩码补全、视频外扩等多个实用功能!
一、算法解析
1.项目地址
项目主页:https://shangchenzhou.com/projects/ProPainter/
论文链接:https://arxiv.org/abs/2309.03897
代码链接:https://github.com/sczhou/ProPainter
官方的项目效果:
视频目标移除/视频水印移除/视频掩码补全
如果项目git或者模型下载不下来,可以使用csdn上传好的资源:https://download.csdn.net/download/matt45m/88385370
2.视频修复
视频修复是一项任务,旨在通过填补缺失区域或移除不需要的内容,来修复视频中的损坏或缺失部分。这个领域可以分为两个主要方向:对象移除和对象补全。
- 对象移除(Object Removal):这是视频修复的一个重要方面,通常用于删除视频中的不需要的对象,如水印、不想显示的元素或干扰物体。传统方法可以使用纹理合成技术,而深度学习方法可以通过学习如何填充缺失区域来实现对象移除。
- 对象补全(Object Inpainting):对象补全是填补视频中缺失区域的过程,通常用于修复受损的视频帧或恢复损坏的部分。这对于修复老电影、修复损坏的监控录像或处理不完整的视频流非常有用。
在视频修复中,有两种主要的算法方法:传统方法和深度学习方法。传统方法依赖于纹理合成技术,它们通过从周围的视频帧中复制纹理信息来填补缺失区域。另一方面是深度学习方法,深度学习方法已经在视频修复中取得了显著的进展。生成对抗网络(GANs)、变分自编码器(VAEs)和Transformer等神经网络架构已被广泛应用于视频修复任务。这些方法可以自动学习从输入视频中生成高质量修复结果的映射关系,使修复过程更加智能化。
3.算法简介
流传播和时空Transformer是视频修复任务中的两个主要机制。尽管它们在视频修复中非常有用,但仍然存在一些限制,这些限制对它们的性能产生了影响。传统的基于传播的方法通常在图像或特征域中执行,这可能导致由于不准确的光流而引起的空间不对齐问题。此外,内存和计算资源的限制可能会限制特征传播和视频Transformer的时间范围,从而阻止了对远程帧的对应信息的探索。
为了应对这些限制,ProPainter算法应运而生。该算法包括增强的流传播和高效的Transformer组件,以提高视频修复性能。ProPainter算法包括三个部件:
循环流完成(Cyclic Flow Completion):首先,ProPainter采用高效的循环流完成网络来修复损坏的光流场。这有助于处理光流信息的不准确性,确保在视频修复中有准确的流场信息可用。
双域传播(Bimodal Propagation):接下来,在图像和特征域中执行传播,并且这两个域是联合训练的。这一方法允许算法探索来自全局和局部时间框架的对应关系,从而提供更可靠和有效的传播。这种联合域的传播有助于更好地理解和修复视频中的内容。
掩模引导稀疏变压器(Mask-Guided Sparse Transformer):最后,ProPainter引入了掩模引导稀疏变压器块,以优化特征传播。这些块使用时空注意力来优化传播的特征,并采用仅考虑令牌子集的稀疏策略。这样做旨在提高算法的效率,减少内存消耗,同时保持高性能水平。
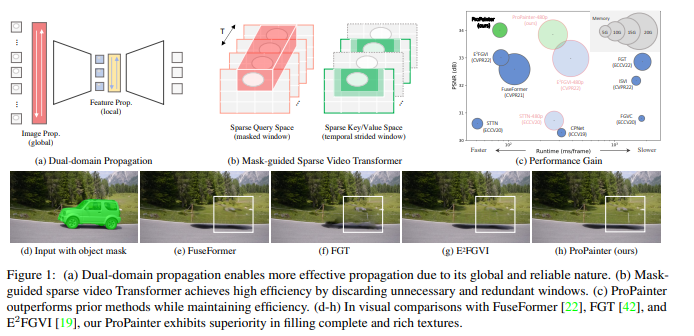
从论文中可以知道,这些图形描述了ProPainter算法的关键优点和性能,以下是对每张图的简要解释:
- (a) 图展示了双域传播的优点,因为它具有全局性和可靠性,能够实现更有效的信息传播。这表明ProPainter算法在利用图像和特征域的联合传播方面具有优势。
- (b) 图展示了掩码引导稀疏视频转换器如何通过丢弃不必要和冗余的窗口来提高算法的处理效率。这意味着ProPainter算法在资源利用方面更加高效。
- © 图展示了ProPainter算法在PSNR指标上的高性能,同时还显示了较短的运行时间。这表明ProPainter能够在保持高质量修复的同时,加速修复过程。
- (d-h) 图展示了ProPainter算法与其他方法(FuseFormer、FGT和E2FGVI)进行视觉比较的结果。这些比较显示,ProPainter在填充完整和丰富纹理方面表现出优势,证明了其在视频修复任务中的出色性能。
4.算法处理流程
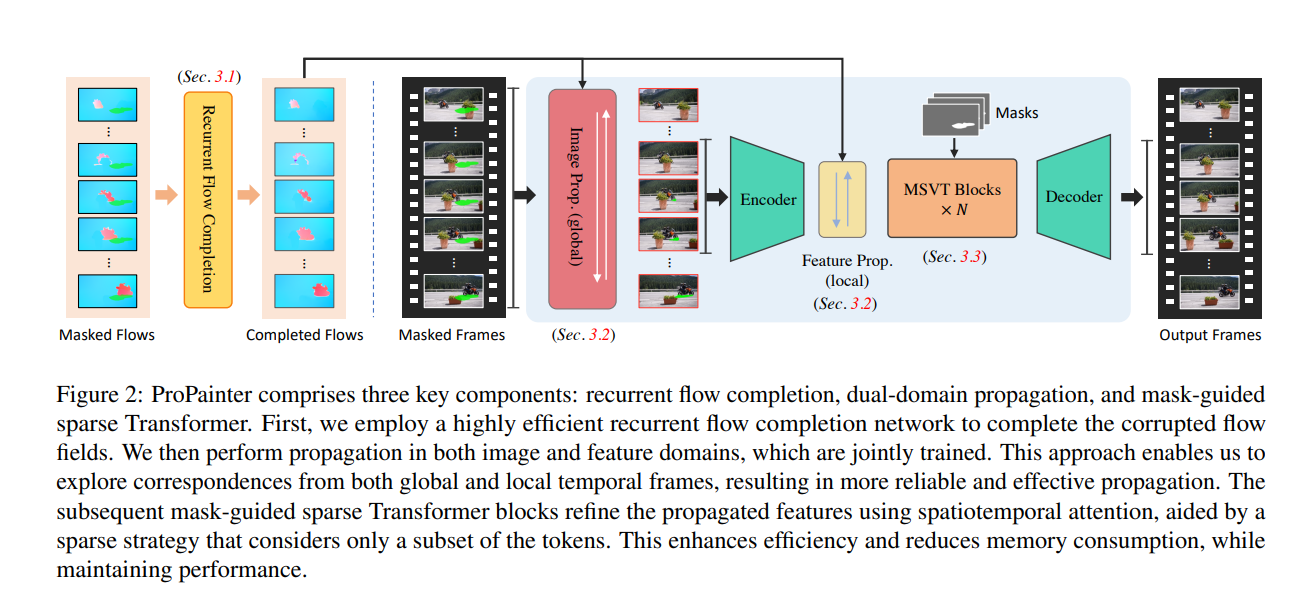
从论文中,可以看到ProPainter算法的工作流程:
- 循环流补全网络:ProPainter首先使用高效的循环流补全网络来修复损坏的光流场。这有助于确保在视频修复中有准确的流场信息可用,以更好地理解视频帧之间的运动。
- 图像和特征域传播:接下来,ProPainter在图像和特征域中进行传播,这两个域是联合训练的。这一方法允许算法从全局和局部时间帧中探索对应关系,以实现更可靠和有效的信息传播。
- Encoder编码器和局部Feature Prop:通过将经过图像传播操作的输出图像送入Encoder编码器,ProPainter获取局部的Feature Prop。这有助于进一步处理和优化传播的特征。
- 掩码引导的稀疏Transformer块:最后,ProPainter使用掩码引导的稀疏Transformer块对传播的特征进行精细调整。这些块使用时空注意力来进行优化,并采用仅考虑特定子集的稀疏策略。这有助于提高算法的效率,减少内存消耗,同时保持高性能水平。
二、项目部署
1. 部署环境
我这里测试部署的系统win 10, cuda 11.8,cudnn 8.5,GPU是RTX 3060, 8G显存,使用conda创建虚拟环境。
官方给的环境配置:
CUDA >= 9.2
PyTorch >= 1.7.1
Torchvision >= 0.8.2
创建并激活一个虚拟环境:
conda create -n ProPainter python==3.8activate ProPainter
下载项目:
git clone https://github.com/sczhou/ProPainter.git
为了避免Pytorch与GPU不兼容的问题,这里单独安装torch:
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install -r requirements.txt
模型下载:
https://github.com/sczhou/ProPainter/releases/tag/v0.1.0
下载之后,放到项目里面:
2 . 目标移除
从官方给的测试,可以看到官方把视频拆分成一帧帧图像,加上要移除目标的mask图,格式如下:

单图如下:


这一步可以借助 Segment-and-Track Anything这个算法完成,关于Segment-and-Track Anything的使用与环境部署可以看我之前的博客,Segment-and-Track Anything转出的的图像是不是黑白mask图像,可以用以下代码进行转换:
然后把mask变成黑和白两种
import os
import numpy as np
import cv2
from glob import glob
from tqdm import tqdmroot_dir = 'xxx/xxxx/data/'
name = 'tao'msk_folder = f'{root_dir}/{name}/{name}_masks'
img_folder = f'{root_dir}/{name}/{name}'
frg_mask_folder = f'{root_dir}/{name}/{name}_masks_0'
bkg_mask_folder = f'{root_dir}/{name}/{name}_masks_1'
os.makedirs(frg_mask_folder, exist_ok=True)
os.makedirs(bkg_mask_folder, exist_ok=True)files = glob(msk_folder + '/*.png')
num = len(files)for i in tqdm(range(num)):file_n = os.path.basename(files[i])mask = cv2.imread(os.path.join(msk_folder, file_n), 0)mask[mask > 0] = 1cv2.imwrite(os.path.join(frg_mask_folder, file_n), mask * 255)bg_mask = mask.copy()bg_mask[bg_mask == 0] = 127bg_mask[bg_mask == 255] = 0bg_mask[bg_mask == 127] = 255cv2.imwrite(os.path.join(bkg_mask_folder, file_n), bg_mask)
然后执行测试代码:
python inference_propainter.py --video inputs/object_removal/bmx-trees --mask inputs/object_removal/bmx-trees_mask
如果图像太大了,内存爆炸,则要指定压缩大小:
python inference_propainter.py --video inputs/object_removal/bmx-trees --mask inputs/object_removal/bmx-trees_mask --height 240 --width 432
3.视频祛水印
分割出水印的位置的mask图像,这步可以使用 Segment Anything这个项目完成:


然后执行:
python inference_propainter.py --video inputs/video_completion/running_car.mp4 --mask inputs/video_completion/mask_square.png --height 240 --width 432
测试效果:
视频目标移动与祛水印