阿丹:
国庆快乐呀大家!
在项目开始前一个好的设计、一个健康的表关系,不仅会让开发变的有趣舒服,也会在后期的维护和升级迭代中让系统不断的成长。那么今天就认识和解读一下阿里的准则!!
建表规约
表达是与否概念的字段
原文:
阿丹:
如果使用这个准则,可以避免以下情况的问题:
- 命名混淆:通过使用明确的命名规则,可以确保代码中的字段名清晰易懂,减少阅读和理解代码的困难。
- 类型不匹配:由于强制规定了字段类型为unsigned tinyint,可以确保字段值在数据库中正确存储和传输,避免了因类型不匹配而引起的错误。
- 范围不确定:通过使用tinyint类型并明确是与否的取值范围,可以确保字段值的合理取值范围,避免超出数据类型的范围而引发的错误。
- 逻辑错误:采用is_xxx的命名方式,与数据库中常用的布尔类型字段命名规范保持一致,有助于避免在查询、筛选等操作中出现的逻辑错误。
- 代码可维护性:统一的命名规则使得代码更易于维护,其他开发人员在阅读或接手项目时可以快速理解并遵循该规则,降低了代码维护的难度。
综上所述,通过遵循该准则,可以避免由于命名混淆、类型不匹配、范围不确定、逻辑错误以及代码可维护性差引起的问题。
表名、字段名
原文:
阿丹:
遵循这个准则,可以避免以下情况的问题:
- 大小写问题:在Windows系统中,MySQL不区分大小写,但在Linux系统中默认是区分大小写的。因此,遵循这个准则可以避免在跨平台使用时出现大小写引起的混乱或错误。
- 数字开头问题:禁止表名和字段名以数字开头,可以避免在查询和引用时出现不必要的困扰和错误。
- 双下划线命名问题:禁止两个下划线之间只出现数字,可以避免与数据库保留字或特殊字符引起的冲突,让名称更具可读性和可理解性。
- 命名规范一致性:通过正例示例,可以了解到符合规范的表名、字段名命名方式,从而保持代码风格的一致性,降低代码维护的难度。
遵循这个准则可以帮助避免在数据库表名和字段名命名时出现不规范、不可读、易混淆等问题,提高代码的可维护性和可读性。
表名不使用复数名词
原文
阿丹:
如果遵循这个准则,可以避免以下情况的问题:
- 名词复数问题:在表名中不使用复数名词,可以避免混淆表中的实体与实体的数量。例如,如果你有一个"users"表,它应该只包含"user"实体,而不是"users"实体,保持单数形式能够清晰地区分实体和实体的数量。
- 数据一致性问题:在数据存储和处理过程中,如果表名使用复数名词,可能会导致数据处理的一致性问题。例如,在查询或过滤数据时,可能会因为忽略了复数形式而导致数据的不一致。
- 代码可读性问题:表名和DO类名使用单数形式,可以使代码更加易读和理解。在代码中引用表或类的名称时,单数形式可以更清晰地表达其含义,减少阅读和理解代码的难度。
遵循这个准则可以帮助避免在表名和DO类名中使用复数名词,提高代码的可读性和数据的一致性,使代码更加规范和易于维护。
禁用保留字
原文
【强制】禁用保留字,如 desc、range、match、delayed 等,请参考 MySQL 官方保留字。
阿丹:
遵循这个准则,你可以避免以下情况的问题:
- 数据库表或字段命名问题:MySQL有官方定义的保留字,如"desc"、"range"、"match"等。如果你在创建表或定义字段时使用了这些保留字,可能会导致语法错误或运行时问题。因此,遵循这个准则可以避免此类问题。
- 查询语句错误:在编写查询语句时,如果使用了MySQL的保留字作为表名或字段名,可能会导致查询失败或返回错误结果。遵循这个准则可以避免此类问题。
- 代码可读性和可维护性:使用保留字作为表名或字段名可能会对代码的可读性和可维护性造成负面影响,因为其他开发人员可能不熟悉或理解错误的命名。遵循这个准则可以提高代码的可读性和可维护性。
主键索引名为 pk_字段名
原文:
阿丹:
如果遵循这个准则,可以避免以下情况的问题:
- 索引命名混淆:通过使用特定的前缀(如 "pk_","uk_","idx_")来区分主键索引、唯一索引和普通索引,可以使代码更具可读性,并减少对索引的误解和误用。
- 维护和扩展困难:在代码中明确指定不同类型的索引名称,有助于降低后期维护和扩展的难度。当需要添加新的索引或修改现有的索引时,可以通过查看索引名称的前缀来快速识别其类型,从而更容易进行维护。
- 命名规范一致性:遵循这种命名规范可以使你的代码与阿里巴巴Java开发手册保持一致,从而提高代码的可读性和可维护性。同时,也可以减少在团队合作或代码审查过程中的争议和沟通成本。
- 便于工具的使用:一些开发工具(如IDE或数据库管理工具)可以自动识别或解析特定的命名规则,从而方便开发者进行索引的创建、查询和维护。遵循这种命名规范可以使你的代码更好地与这些工具集成,提高开发效率。
遵循这个准则可以帮助你避免在索引命名时出现混淆、误用等问题,并提高代码的可读性、可维护性和可扩展性。
小数类型为 decimal
原文
阿丹
- 精度损失问题:
float和double类型在存储时存在精度损失的问题。特别是在进行浮点数比较时,可能会得到不准确的结果。使用decimal类型可以避免这种精度损失,因为它采用了十进制表示法,能够更准确地存储和比较小数。 - 数据存储问题:如果需要存储的数据范围超过了
decimal的范围,按照这个准则的建议,可以将数据拆分成整数和小数部分,然后分别存储。这样可以避免数据存储问题,确保数据的完整性和准确性。 - 代码可维护性和可读性:使用
decimal类型可以使代码更具可维护性和可读性。因为其他开发人员可以更容易地理解你的代码,并清楚地知道你正在使用的数据类型。
如果存储的字符串长度几乎相等,使用 char 定长字符串类型
原文
阿丹
可以避免以下情况的问题:
- 内存浪费:在MySQL中,如果存储的字符串长度几乎相等,使用
char定长字符串类型可以避免内存浪费。因为char类型是定长的,它不会像变长字符串类型那样在内存中分配额外的空间。 - 性能问题:使用
char定长字符串类型可以提高性能。由于char类型是定长的,所以在执行字符串拼接或频繁修改字符串等操作时,它不会像变长字符串类型那样需要重新分配和复制内存,因此性能更高。 - 减少垃圾回收的压力:由于
char定长字符串类型不会像变长字符串类型那样产生内存重新分配和复制,因此可以减少垃圾回收的压力,降低系统的开销。 - 避免可能的溢出问题:对于某些特定场景,如字符串拼接等操作,使用
char[]可能比String更安全,因为它不会因为创建新的字符串实例而引发可能的溢出问题。
varchar 是可变长字符串,不预先分配存储空间
原文:
阿丹:
这段阿里巴巴的Java MySQL开发准则强调了如何有效地使用数据库中的字符串字段。下面是我对这段准则的理解,以及使用这个准则可以避免的情况:
- 使用
VARCHAR而不是固定长度的字符串类型 (CHAR) 可以避免预先分配存储空间的问题。VARCHAR是可变长度的字符串,只会存储实际的数据,不会像CHAR那样预先分配空间。这可以节省存储空间,特别是在处理长度不定的字符串时。 - 这段准则建议将
VARCHAR的最大长度设置为5000。这是因为在大多数情况下,如果字符串的长度超过这个值,那么将其定义为TEXT类型可能更为合适。TEXT类型适用于存储大量的文本数据,可以很好地处理大量文字内容。 - 如果一个字段的长度超过了5000,准则建议将这个字段独立出来,放到另一张表中,并使用主键来对应。这可以避免这个大字段影响其他字段的索引效率。在数据库中,索引是提高查询速度的关键,如果一个字段非常大,可能会影响到其他字段的索引效率。通过将大字段独立出来,可以避免这种情况。
- 这个准则还可以避免在处理大量文本数据时出现的性能问题。如果一个字段的长度非常大,可能会影响到查询速度和数据库的性能。通过将大字段独立出来,可以减少对数据库性能的影响。
表必备三字段
原文
阿丹:
这条准则的建议是,每一个数据库表都应该有以下三个字段:
id:这是一个唯一标识符,通常被用作主键。在这个字段中,你应该存储的是每个记录的唯一标识。在阿里巴巴的准则中,推荐使用bigint unsigned类型,这意味着这个数字可以被视为非常大的无符号整数。在单表情况下,这个字段通常被设置为自增,即每当你添加一条新的记录时,这个字段的值会自动增加。gmt_create:这是一个日期时间字段,用于记录每条记录的创建时间。它的类型是datetime,可以精确到秒。在这个字段中,你可以存储创建记录时的日期和时间。gmt_modified:这是另一个日期时间字段,用于记录每条记录最后一次被修改的时间。它的类型也是datetime。在这个字段中,你可以存储对记录进行最后一次修改时的日期和时间。
如果你遵循这个准则,你可以避免以下情况的问题:
- 每个表都有唯一的主键,可以避免数据重复的问题。特别是在处理大量数据时,主键可以确保数据的唯一性和准确性。
gmt_create和gmt_modified这两个时间戳字段可以帮助你跟踪记录的创建和修改历史,可以避免在处理数据时出现时间上的混乱。- 使用这些标准字段可以让你更容易地实现数据库操作的可追溯性和可管理性。例如,你可以很容易地找出最近被修改的记录,或者找到某个特定时间点创建的记录等。
- 这些字段的定义和使用也有助于提高查询性能,因为数据库可以更有效地使用这些字段进行索引。
总的来说,这个准则有助于在设计数据库表结构时更加规范和统一,以便于进行更高效的数据管理和查询操作,避免了可能的数据问题。
业务名称_表的作用
原文
阿丹:
这段阿里巴巴的Java MySQL开发准则建议你在命名表时,采用“业务名称_表的作用”的形式,以增加可读性和可理解性。这种命名方式可以帮助开发者更好地理解表在业务逻辑中的位置和作用,有利于维护和扩展代码。
以正例中的例子来说明:
alipay_task:这个表可能涉及到支付宝的相关任务信息,通过这样的命名,我们可以直观地知道这个表的内容与支付宝相关,并且是用来存储任务信息的。force_project:这个表可能涉及到强制项目相关的信息,如此命名可以帮助我们理解这个表主要存储的是关于强制项目的数据。trade_config:这个表可能存储的是交易配置的相关信息,通过这个命名,我们可以清楚地知道这个表的主要作用是存储交易配置。
如果你遵循这个准则,你可以避免以下情况的问题:
- 减少歧义:明确的表名可以避免开发和维护过程中对表的理解产生歧义。如果表名与其代表的数据内容不一致,可能会导致数据管理混乱或理解错误。
- 提高代码可读性:清晰的表名可以让其他开发者更容易理解代码,减少阅读和理解代码的难度。
- 易于维护和扩展:明确的表名使得在项目后期扩展和维护时更加方便。例如,如果需要添加新的表,使用相似的命名方式可以让其他开发者更快地理解新表的作用。
- 避免数据冗余:如果表的命名能明确其作用,可以避免因冗余数据造成的存储空间浪费和查询效率降低。
- 便于数据库管理:对于大型项目或复杂的数据库结构,命名的统一性和规范性可以使数据库管理更为高效。
总的来说,这个准则可以提高代码的可读性和可维护性,避免因表命名不当引发的一系列问题。
字段允许适当冗余
原文:
阿丹:
这段阿里巴巴的Java MySQL开发准则是在推荐一种适当的冗余策略来提高查询性能,但同时也强调了数据一致性的重要性。这里的冗余字段应该遵循以下两个原则:
- 不是频繁修改的字段:如果一个字段经常被修改(例如,用户名、描述等),那么冗余这个字段可能会导致数据不一致。因为每次修改都需要更新所有相关的冗余字段,这可能导致数据不一致或者数据不一致的问题更严重。
- 不是超长varchar字段,更不能是text字段:varchar字段长度过长或者使用text字段,可能会导致存储冗余数据过多,从而影响到数据库的性能。同时,过长的字段也可能会占用更多的内存和磁盘空间,导致资源的浪费。
举个正例,比如商品类目名称这个字段,如果使用频率高,字段长度短(即,类目名称基本一成不变),那么可以在相关联的表中冗余存储这个类目名称,以避免每次需要用到它时都要进行一次关联查询。
如果你遵循了这条准则,你可以避免以下情况的问题:
- 提高查询性能:通过适当的冗余策略,可以提高查询性能,特别是对于一些复杂的关联查询,冗余可以减少关联查询的复杂度,提高查询效率。
- 减少资源消耗:通过冗余策略,可以减少关联查询的使用,从而减少数据库的资源消耗,提高数据库的性能和稳定性。
- 避免数据不一致:遵循准则中的两个原则,可以避免因为频繁修改和冗余字段过长而引起的数据不一致问题。
- 提高数据安全性:冗余策略可以提高数据的可用性和可靠性,减少因为查询失败或者数据丢失而带来的风险。
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表
原文
阿丹:
这段阿里巴巴的Java MySQL开发准则是在推荐一种数据库设计的策略,即当单表行数超过500万行或者单表容量超过2GB时,推荐进行分库分表。
首先,我们需要理解什么是分库分表。分库分表是一种数据库设计策略,它用于解决单个数据库无法处理大量数据的问题。通过将一个大的表拆分成多个小的表,并分布在不同的数据库(分库)或者不同的表(分表)中,可以提高查询性能和数据管理。
那么,这段准则在说什么呢?这段准则的意思是,如果一个表的容量或者行数还没有达到这个级别,那么就没有必要过早地进行分库分表。过早地进行分库分表可能会带来一些额外的复杂性,例如,需要处理跨表查询,数据一致性问题,以及可能的分布式事务等问题。而这些问题的处理往往会带来额外的开发难度和性能损耗。
所以,如果预计三年后的数据量根本达不到这个级别,那么在创建表时就不应该过早地考虑分库分表。
通过遵循这个准则,你可以避免以下情况:
- 过早地引入复杂性:如果没有必要进行分库分表,那么你可以避免引入这种架构带来的复杂性。例如,你可以避免处理跨表查询,数据一致性问题等。
- 避免浪费资源:如果没有必要进行分库分表,那么你可以避免在这种场景下投入大量资源来设计和实现分库分表的方案。这些资源可能会被更好地用于其他方面,例如业务功能的开发等。
- 避免性能下降:虽然分库分表可以提高查询性能,但是如果过早地引入这种架构,可能会导致性能下降。例如,跨表查询可能会导致性能下降,数据一致性问题可能会导致数据更新操作性能下降等。
总的来说,这个准则可以帮助你在数据库设计时避免过早地引入复杂性,浪费资源,以及性能下降等问题。
合适的字符存储长度
原文:
阿丹:
这段阿里巴巴的Java MySQL开发准则主要强调了合适字符存储长度的选择对于数据库性能的重要影响。
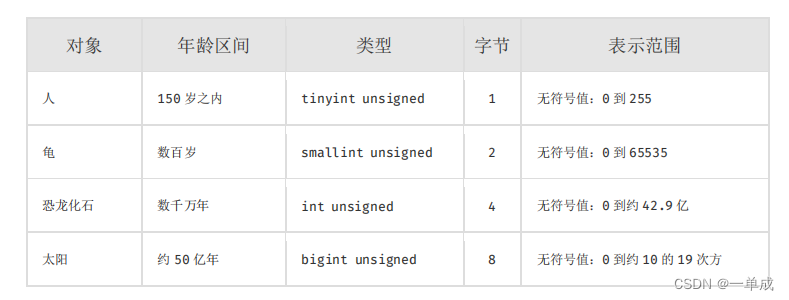
对于字符存储长度来说,不同的数据类型有不同的存储长度。例如,tinyint是1字节,smallint是2字节,int是4字节,bigint是8字节。这些长度不仅决定了存储空间的大小,也影响了索引的存储以及查询的速度。
当我们在设计数据库表的时候,要尽可能地选择合适的字符存储长度。如果选择的长度过大,可能会造成存储空间的浪费,而如果选择的长度过小,可能会存储不了足够的数据,或者造成数据溢出。
选择正确的字符存储长度,可以帮助我们避免以下情况:
- 节约数据库表空间:选择正确的字符存储长度,可以有效地利用存储空间,避免空间的浪费。
- 提高检索速度:如果字符存储长度合适,那么在执行查询操作时,数据库可以更快地定位到所需的数据,从而提高检索速度。
- 减少索引存储:索引是用于快速查找数据的,如果字符存储长度合适,那么索引的大小也会相应地减小,从而减少存储空间的使用。
- 避免数据溢出:如果字符存储长度过小,可能会导致数据溢出,即数据会被写入到无法正常读取的内存区域,从而造成数据丢失。
此外,这段准则还给出了一些具体的例子,说明了如何选择合适的字符存储长度。例如,对于人的年龄,选择tinyint unsigned就足够了,因为人的年龄一般不会超过255岁;而对于龟的年龄,选择smallint unsigned更合适,因为龟的寿命一般在数百岁以内,其值的范围在0到65535之间;对于恐龙化石和太阳的年龄,则分别选择了int unsigned和bigint unsigned,因为它们的年龄范围更大。
通过遵循这个准则,你可以在设计数据库表时选择合适的字符存储长度,从而避免上述问题。



![[BJDCTF2020]Mark loves cat](https://img-blog.csdnimg.cn/f4b47489add44a5f8ee18e4e027976e5.png)