作者:vivo 互联网大数据团队 - Wang Zhiwen
本文介绍了vivo在大数据元数据服务横向扩展道路上的探索历程,由实际面临的问题出发,对当前主流的横向扩展方案进行了调研及对比测试,通过多方面对比数据择优选择TiDB方案。其次分享了整个扩展方案流程、实施遇到的问题及解决方案,对于在大数据元数据性能上面临同样困境的开发者本篇文章具有非常高的参考借鉴价值。
一、背景
大数据元数据服务Hive Metastore Service(以下简称HMS),存储着数据仓库中所依赖的所有元数据并提供相应的查询服务,使得计算引擎(Hive、Spark、Presto)能在海量数据中准确访问到需要访问的具体数据,其在离线数仓的稳定构建上扮演着举足轻重的角色。vivo离线数仓的Hadoop集群基于CDH 5.14.4版本构建,HMS的版本选择跟随CDH大版本,当前使用版本为1.1.0-cdh5.14.4。
vivo在HMS底层存储架构未升级前使用的是MySQL存储引擎,但随着vivo业务发展,数据爆炸式增长,存储的元数据也相应的增长到亿级别(PARTITION_PARAMS:8.1亿、PARTITION_KEY_VALS:3.5亿、PARTITIONS:1.4亿),在如此大量的数据基数下,我们团队经常面临机器资源的性能瓶颈,往往用户多并发的去查询某些大分区表(50w+分区),机器资源的使用率就会被打满,从而导致元数据查询超时,严重时甚至整个HMS集群不可用,此时恢复手段只能暂时停服所有HMS节点,直到MySQL机器负载降下来后在逐步恢复服务。为此,针对当前MySQL方案存在的严重性能瓶颈,HMS急需一套完善的横向扩展方案来解决当前燃眉之急。
二、横向扩展技术方案选型
为解决HMS的性能问题,我们团队对HMS横向扩展方案做了大量的调研工作,总体下来业内在HMS的横向扩展思路上主要分为对MySQL进行拆库扩展或用高性能的分布式引擎替代MySQL。在第一种思路上做的比较成熟的方案有Hotels.com公司开源的Waggle Dance,实现了一个跨集群的Hive Metastore代理网关,他允许用户同时访问多个集群的数据,这些集群可以部署在不同的平台上,特别是云平台。第二种思路当前主流的做法是用分布式存储引擎TiDB替换传统的MySQL引擎,在Hive社区中有不少公司对hive 2.x接入TiDB做了大量的测试并应用到生产中(详情点击)。
2.1 Waggle Dance
Waggle-dance向用户提供统一的入口,将来自Metastore客户端的请求路由到底层对应的Metastore服务,同时向用户隐藏了底层的Metastore分布,从而在逻辑层面整合了多个Metastore的Hive库表信息。Waggle-dance实现了Metastore的Thrift API,客户端无需改动,对用户来说,Waggle-dance就是一个Metastore。其整体架构如下:
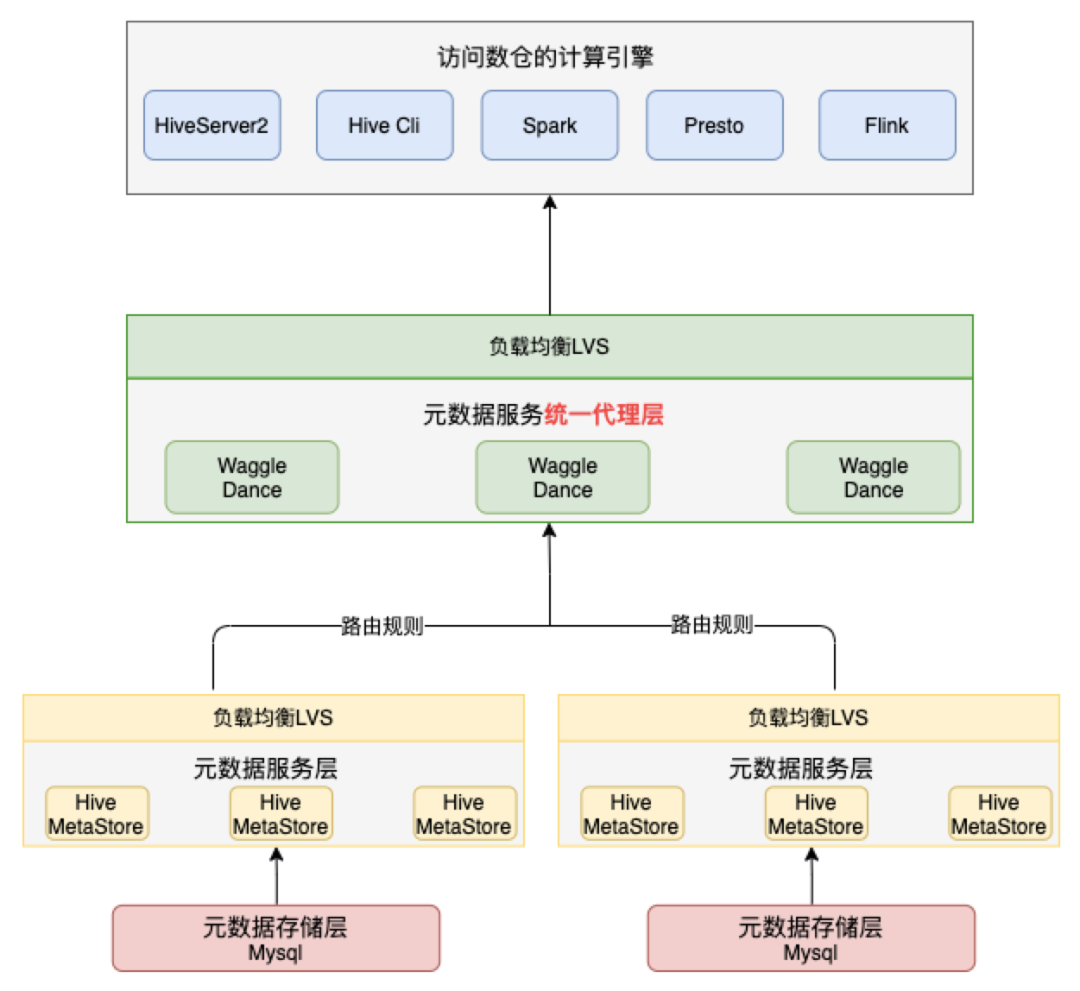
Waggle Dance架构
从Waggle-dance的架构中最突出的特性是其采用了多个不同的MySQL实例分担了原单MySQL实例的压力,除此之外其还有如下优势:
-
用户侧可以沿用Metastore客户端的用法,配置多台Waggle-dance的连接,在当前Waggle-dance连接服务不可用的时候切换到其他的Waggle-dance服务上。
-
Waggle-dance只需几秒即可启动,加上其无状态服务的特性,使得Waggle-dance具备高效的动态伸缩性,可以在业务高峰期快速上线新的服务节点分散压力,在低峰期下线部分服务节点释放资源。
-
Waggle-dance作为一个网关服务,除了路由功能外,还支持后续的定制化开发和差异化部署,平台可根据需要添加诸如鉴权、防火墙过滤等功能。
2.2 TiDB
TiDB 是 PingCAP 公司自主设计、研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP) 的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。在TiDB 4.x版本中,其性能及稳定性较与之前版本得到了很大的提升并满足HMS的元数据查询性能需求。故我们对TiDB也做了相应的调研及测试。结合HMS及大数据生态,采用TiDB作为元数据存储整体的部署架构如下:
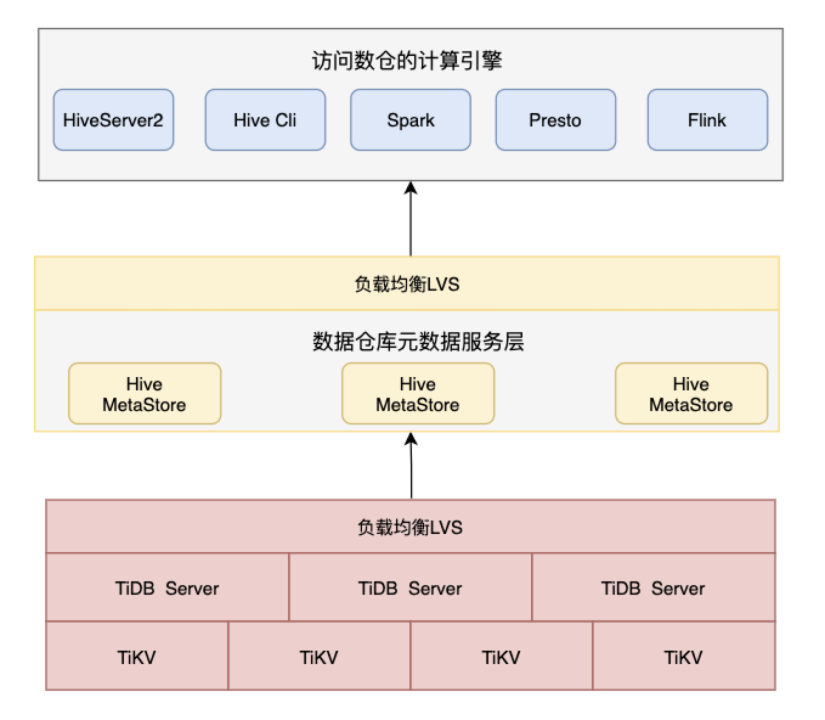
HMS on TiDB架构
由于TiDB本身具有水平扩展能力,扩展后能均分查询压力,该特性就是我们解决HMS查询性能瓶颈的大杀器。除此外该架构还有如下优势:
-
用户无需任何改动;HMS侧面没有任何改动,只是其依赖的底层存储发生变化。
-
不破坏数据的完整性,无需将数据拆分多个实例来分担压力,对HMS来说其就是一个完整、独立的数据库。
-
除引入TiDB作为存储引擎外,不需要额外的其他服务支撑整个架构的运行。
2.3 TiDB和Waggle Dance对比
前面内容对Waggle-dance方案和TiDB方案做了简单的介绍及优势总结,以下列举了这两个方案在多个维度的对比:

通过上述多个维度的对比,TiDB方案在性能表现、水平扩展、运维复杂度及机器成本上都优于waggle-dance方案,故我们线上选择了前者进行上线应用。
三、TiDB上线方案
选择TiDB引擎替代原MySQL存储引擎,由于TiDB与MySQL之间不能做双主架构,在切换过程中HMS服务须完全停服后并重新启动切换至TiDB,为保障切换过程顺利及后面若有重大问题发生能及时回滚,在切换前做了如下数据同步架构以保障切换前MySQL与TiDB数据一致以及切换后仍有MySQL兜底。
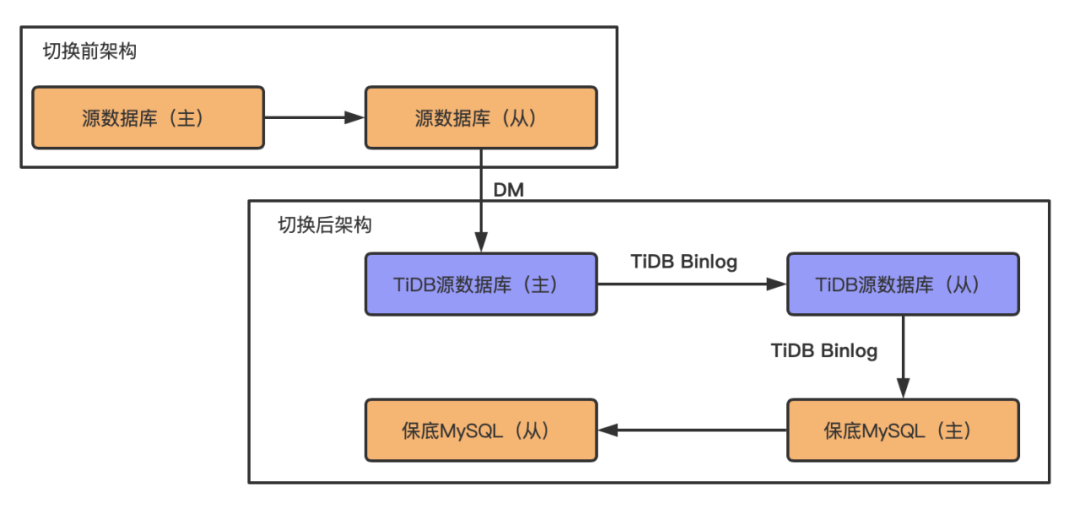
TiDB&MySQL上线前后数据同步架构
在上述架构中,切换前唯一可写入的数据源只有源数据库主库,其他所有TiDB、MySQL节点都为只读状态,当且仅当所有HMS节点停服后,MySQL源数据库从库及TiDB源数据库主库的数据同步最大时间戳与源数据库主库一致时,TiDB源数据库主库才开放可写入权限,并在修改HMS底层存储连接串后逐一拉起HMS服务。
在上述架构完成后,即可开始具体的切换流程,切换整体流程如下:
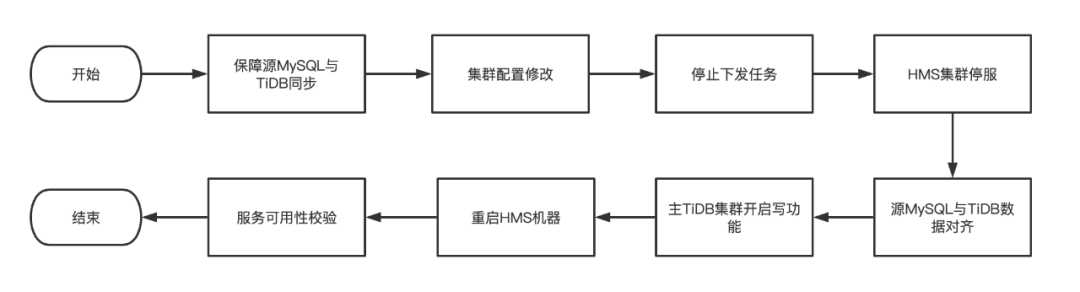
HMS切换底层存储流程
其中在保障源MySQL与TiDB数据正常同步前,需要对TiDB做以下配置:
-
tidb_skip_isolation_level_check需要配置为1 ,否则启动HMS存在MetaException异常。
-
tidb_txn_mode需配置为pessimistic ,提升事务一致性强度。
-
事务大小限制设置为3G,可根据自己业务实际情况进行调整。
-
连接限制设置为最大3000 ,可根据自己业务实际情况进行调整。
此外在开启sentry服务状态下,需确认sentry元数据中NOTIFICATION_ID的值是否落后于HMS元数据库中NOTIFICATION_SEQUENCE表中的NEXT_EVENT_ID值,若落后需将后者替换为前者的值,否则可能会发生建表或创建分区超时异常。
以下为TiDB方案在在不同维度上的表现:
-
在对HQL的兼容性上TiDB方案完全兼容线上所有引擎对元数据的查询,不存在语法兼容问题,对HQL语法兼容度达100%
-
在性能表现上查询类接口平均耗时优于MySQL,性能整体提升15%;建表耗时降低了80%,且支持更高的并发,TiDB性能表现不差于MySQL
-
在机器资源使用情况上整体磁盘使用率在10%以下;在没有热点数据访问的情况下,CPU平均使用率在12%;CPU.WAIT.IO平均值在0.025%以下;集群不存在资源使用瓶颈。
-
在可扩展性上TiDB支持一键水平扩缩容,且内部实现查询均衡算法,在数据达到均衡的情况下各节点可平摊查询压力。
-
在容灾性上TiDB Binlog技术可稳定支撑TiDB与MySQL及TiDB之间的数据同步,实现完整的数据备份及可回退选择。
-
在服务高可用性上TiDB可选择LVS或HaProxy等服务实现负载均衡及故障转移。
以下为上线后HMS主要API接口调用耗时情况统计:
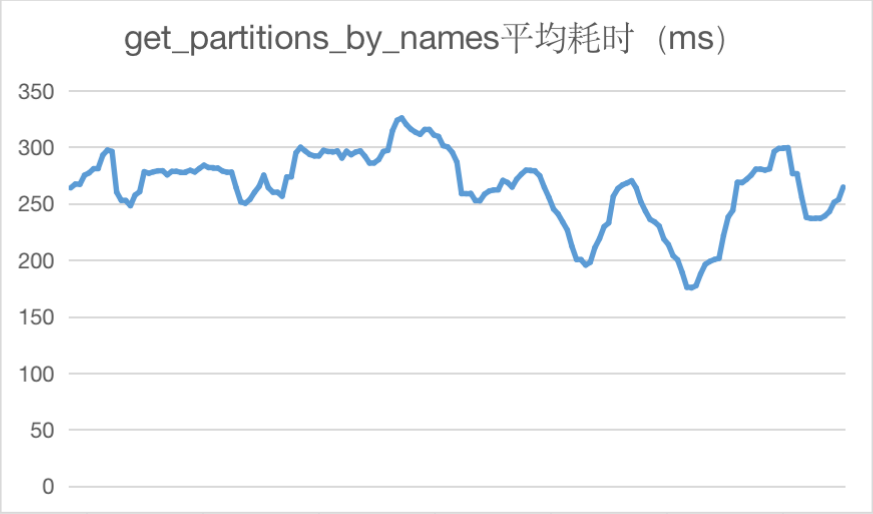
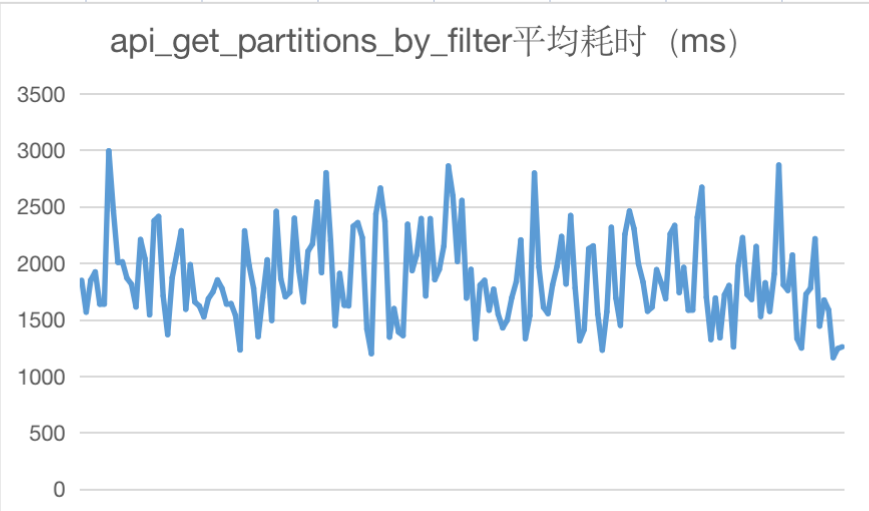
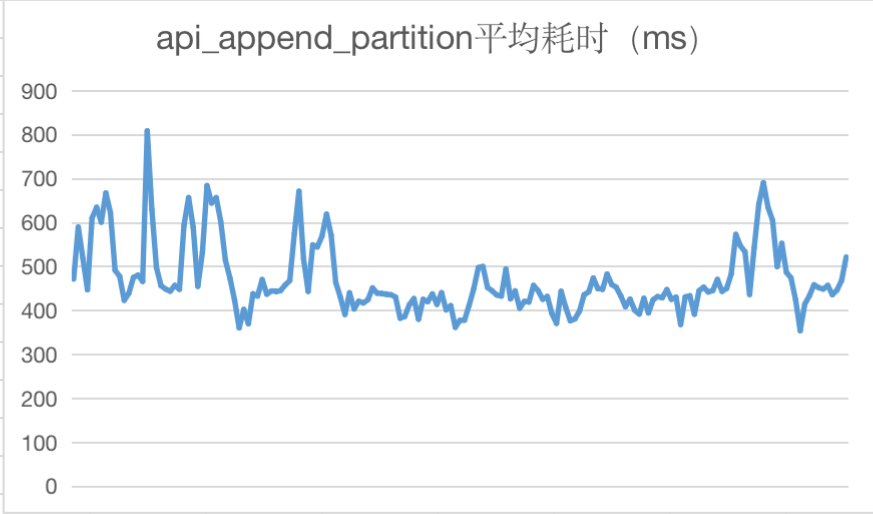
四、问题及解决方案
4.1 在模拟TiDB回滚至MySQL过程中出现主键冲突问题
在TiDB数据增长3倍后,切换回MySQL出现主键重复异常,具体日志内容如下:

主键冲突异常日志
产生该问题的主要原因为每个 TiDB 节点在分配主键ID时,都申请一段 ID 作为缓存,用完之后再去取下一段,而不是每次分配都向存储节点申请。这意味着,TiDB的AUTO_INCREMENT自增值在单节点上能保证单调递增,但在多个节点下则可能会存在剧烈跳跃。因此,在多节点下,TiDB的AUTO_INCREMENT自增值从全局来看,并非绝对单调递增的,也即并非绝对有序的,从而导致Metastore库里的SEQUENCE_TABLE表记录的值不是对应表的最大值。
造成主键冲突的主要原因是SEQUENCE_TABLE表记录的值不为元数据中实际的最大值,若存在该情况在切换回MySQL后就有可能生成已存在的主键导致初见冲突异常,此时只需将SEQUENCE_TABLE里的记录值设置当前实际表中的最大值即可。
4.2 PARTITION_KEY_VALS的索引取舍
在使用MySQL引擎中,我们收集了部分慢查询日志,该类查询主要是查询分区表的分区,类似如下SQL:
#以下查询为查询三级分区表模板,且每级分区都有过来条件SELECT PARTITIONS.PART_ID
FROM PARTITIONSINNER JOIN TBLSON PARTITIONS.TBL_ID = TBLS.TBL_IDAND TBLS.TBL_NAME = '${TABLE_NAME}'INNER JOIN DBSON TBLS.DB_ID = DBS.DB_IDAND DBS.NAME = '${DB_NAME}'INNER JOIN PARTITION_KEY_VALS FILTER0ON FILTER0.PART_ID = PARTITIONS.PART_IDAND FILTER0.INTEGER_IDX = ${INDEX1}INNER JOIN PARTITION_KEY_VALS FILTER1ON FILTER1.PART_ID = PARTITIONS.PART_IDAND FILTER1.INTEGER_IDX = ${INDEX2}INNER JOIN PARTITION_KEY_VALS FILTER2ON FILTER2.PART_ID = PARTITIONS.PART_IDAND FILTER2.INTEGER_IDX = ${INDEX3}
WHERE FILTER0.PART_KEY_VAL = '${PART_KEY}'AND CASE WHEN FILTER1.PART_KEY_VAL <> '__HIVE_DEFAULT_PARTITION__' THEN CAST(FILTER1.PART_KEY_VAL AS decimal(21, 0))ELSE NULLEND = 10AND FILTER2.PART_KEY_VAL = '068';在测试中通过控制并发重放该类型的SQL,随着并发的增加,各个API的平均耗时也会增长,且重放的SQL查询耗时随着并发的增加查询平均耗时达到100s以上,虽然TiDB及HMS在压测期间没有出现任何异常,但显然这种查询效率会让用户很难接受。DBA分析该查询没有选择合适的索引导致查询走了全表扫描,建议对PARTITION_KEY_VALS的PARTITION_KEY_VAL字段添加了额外的索引以加速查询,最终该类型的查询得到了极大的优化,即使加大并发到100的情况下平均耗时在500ms内,对此我们曾尝试对PARTITION_KEY_VALS添加上述索引操作。
但在线上实际的查询中,那些没有产生慢查询的分区查询操作其实都是按天分区的进行一级分区查询的,其SQL类似如下:
SELECT "PARTITIONS"."PART_ID"
FROM "PARTITIONS"INNER JOIN "TBLS"ON "PARTITIONS"."TBL_ID" = "TBLS"."TBL_ID"AND "TBLS"."TBL_NAME" = 'tb1'INNER JOIN "DBS"ON "TBLS"."DB_ID" = "DBS"."DB_ID"AND "DBS"."NAME" = 'db1'INNER JOIN "PARTITION_KEY_VALS" "FILTER0"ON "FILTER0"."PART_ID" = "PARTITIONS"."PART_ID"AND "FILTER0"."INTEGER_IDX" = 0INNER JOIN "PARTITION_KEY_VALS" "FILTER1"ON "FILTER1"."PART_ID" = "PARTITIONS"."PART_ID"AND "FILTER1"."INTEGER_IDX" = 1
WHERE "FILTER0"."PART_KEY_VAL" = '2021-12-28'AND CASE WHEN "FILTER1"."PART_KEY_VAL" <> '__HIVE_DEFAULT_PARTITION__' THEN CAST("FILTER1"."PART_KEY_VAL" AS decimal(21, 0))ELSE NULLEND = 10;由于对PARTITION_KEY_VALS的PARTITION_KEY_VAL字段添加了索引做查询优化,会导致该类查询生成的执行计划中同样会使用idx_PART_KEY_VAL索引进行数据扫描,该执行计划如下:
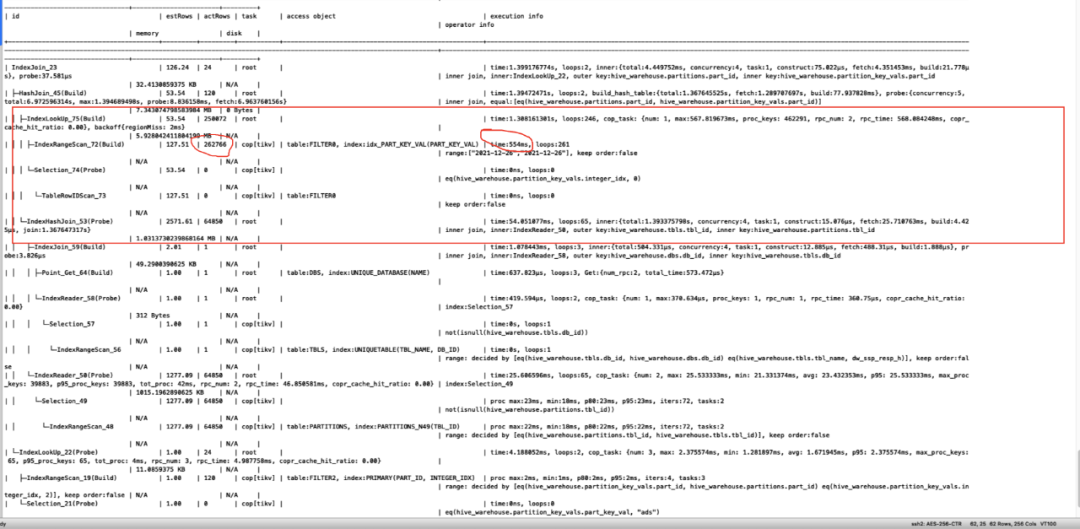
走idx_PART_KEY_VAL索引执行计划
添加的idx_PART_KEY_VAL索引在该字段的具有相同值的数据较少时,使用该索引能检索较少的数据提升查询效率。在hive中的表一级分区基本是按天进行分区的,据统计每天天分区的增量为26w左右,如果使用idx_PART_KEY_VAL索引,按这个数值计算,查询条件为day>=2021-12-21 and day<2021-12-26的查询需要检索将近160w条数据,这显然不是一个很好的执行计划。
若执行计划不走idx_PART_KEY_VAL索引,TiDB可通过dbs、tbls检索出所有关联partition数据,在根据part_id和过滤条件扫描PARTITION_KEY_VALS数据并返回。此类执行计划扫描的数据量和需要查询的表的分区总量有关,如果该表只有少数的分区,则查询能够迅速响应,但如果查询的表有上百万的分区,则该类执行计划对于该类查询不是最优解。
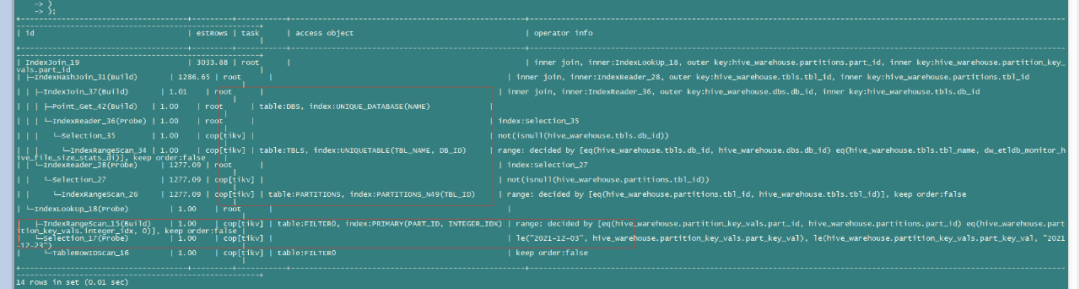
不走idx_PART_KEY_VAL索引执行计划
针对不同执行计划的特性,整理了以下对比点:
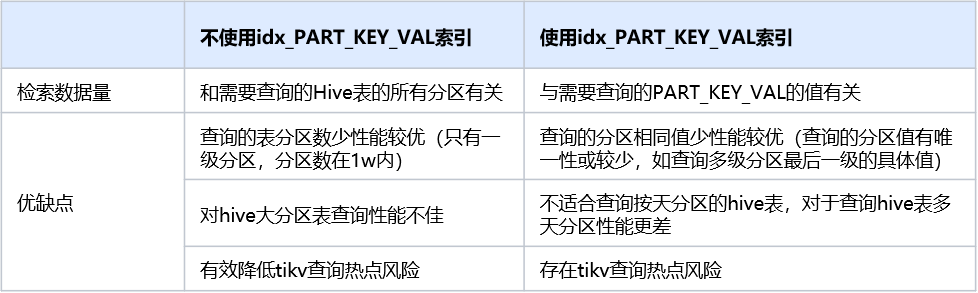
在实际生产中元数据基本都是按天分区为主,每天增长大概有26w左右,且范围查询的使用场景较多,使用idx_PART_KEY_VAL索引查询的执行计划不太适合线上场景,故该索引需不适合添加到线上环境。
4.3 TiDB内存突增导致宕机问题
在刚上线TiDB服务初期,曾数次面临TiDB内存溢出的问题,每次出现的时间都随机不确定,出现的时候内存突增几乎在一瞬间,若期间TiDB的内存抗住了突增量,突增部分内存释放在很长时间都不会得到释放,最终对HMS服务稳定性带来抖动。
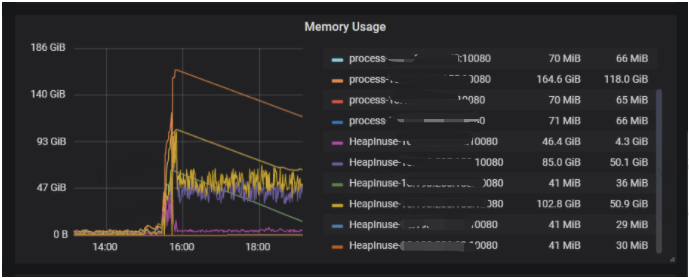
TiDB内存突增情况
通过和TiDB开发、DBA联合分析下,确认TiDB内存飙高的原因为用户在使用Dashboard功能分析慢查询引起;在分析慢查询过程中,TiDB需要加载本地所有的slow-query日志到内存,如果这些日志过大,则会造成TiDB内存突增,此外,如果在分析期间,用户点击了取消按钮,则有可能会造成TiDB的内存泄漏。针对该问题制定如下解决方案:
-
使用大内存机器替换原小内存机器,避免分析慢查询时内存不够
-
调大慢查询阈值为3s,减少日志产生
-
定时mv慢查询日志到备份目录
4.4 locate函数查询不走索引导致TiKV负异常
在HMS中存在部分通过JDO的方式去获取分区的查询,该类查询的过滤条件中用locate函数过滤PART_NAME数据,在TiDB中通过函数作用在字段中是不会触发索引查询的,所以在该类查询会加载对应表的所有数据到TiDB端计算过滤,TiKV则需不断扫描全表并传输数据到TiDB段,从而导致TiKV负载异常。
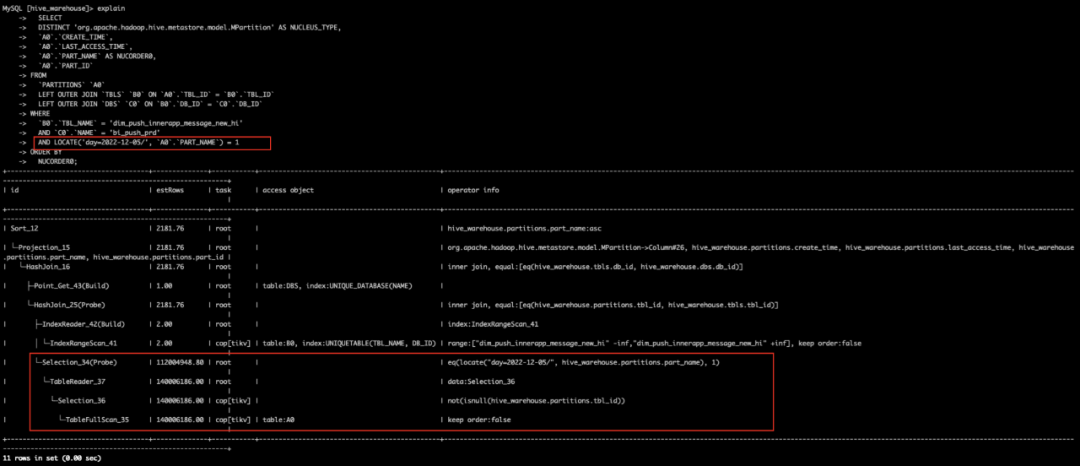
locate函数导致全表扫描
然而上述的查询条件可以通过like方式去实现,通过使用like语法,查询可以成功使用到PARTITIONS表的UNIQUEPARTITION索引过滤,进而在TiKV端进行索引过滤降低负载。
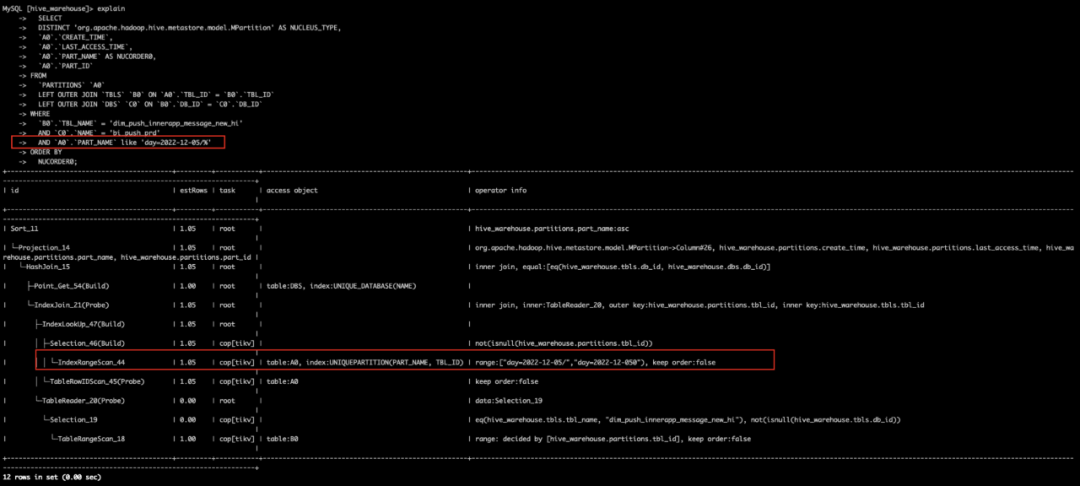
like语法走索引过滤
通过实现将locate函数查询转换为like语法查询,有效降低了TiKV端的负载情况。在HMS端完成变更后,TiKV的CPU使用率降低了将近一倍,由于在KV端进行索引过滤,相应的io使用率有所上升,但网络传输则有明显的下降,由平均1G降低到200M左右。
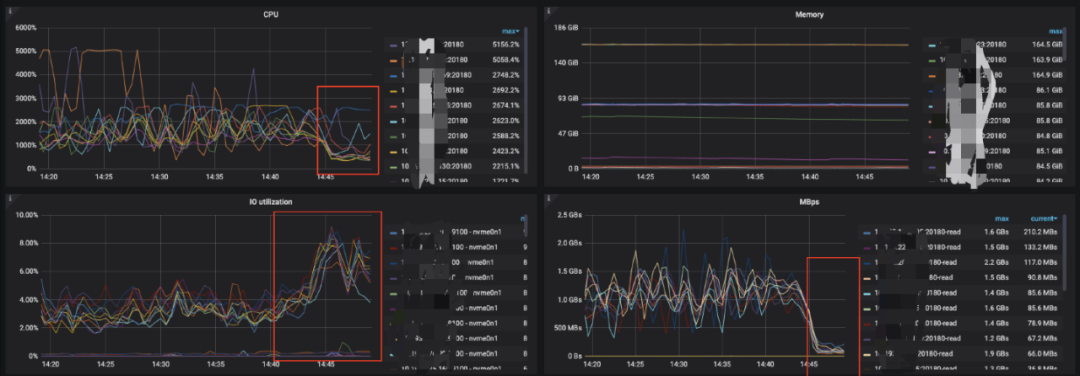
变更前后TiKV的负载情况
除TiKV负载有明显的降低,TiDB的整体性能也得到明显的提升,各项操作耗时呈量级降低。以下整理了TiDB增删改查的天平均耗时情况:
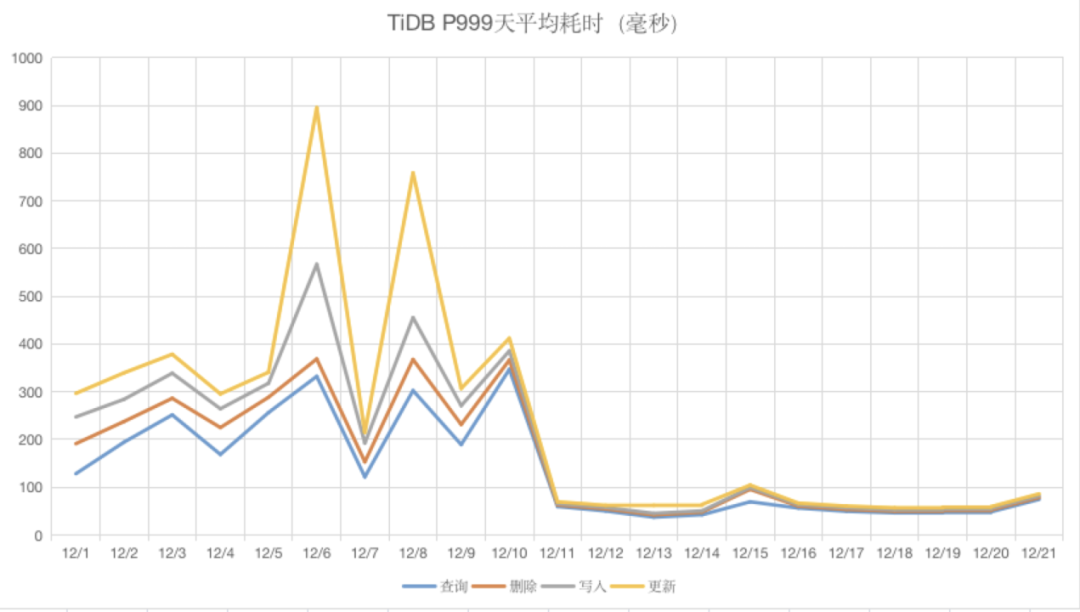
TiDB P999天平均耗时统计
4.5 get_all_functions优化
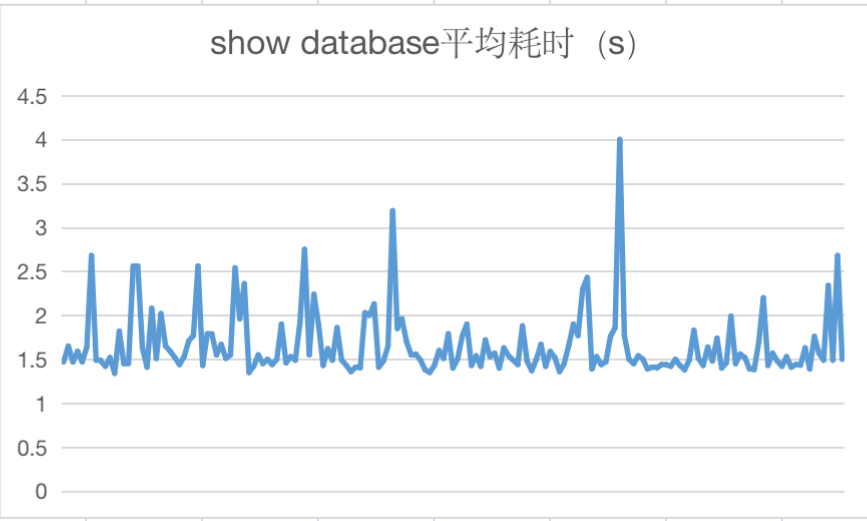
随着hive udf的不断增长,HMS的get_all_functions api平均耗时增长的也越来越久,平均在40-90s,而该api在hive shell中首次执行查询操作时会被调用注册所有的udf,过长的耗时会影响用户对hive引擎的使用体验,例如执行简单的show database需要等待一分钟甚至更久才能返回结果。
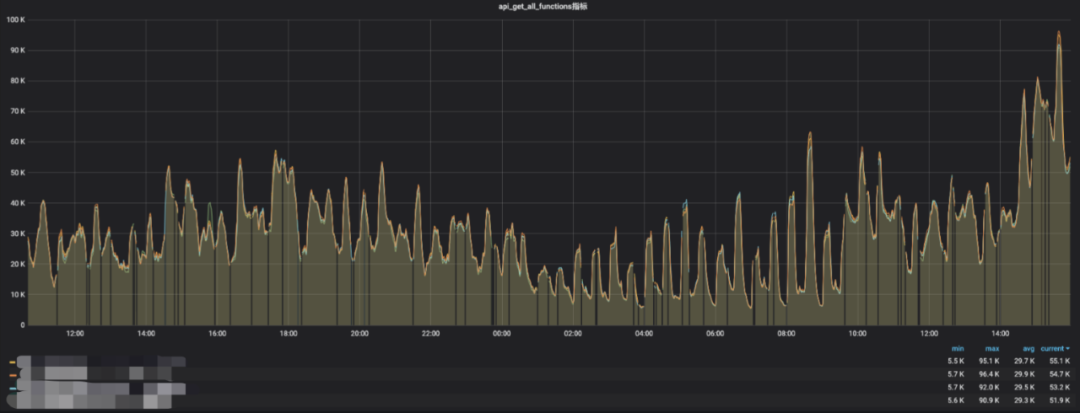
原get_all_functions api平均耗时
导致该api耗时严重的主要原因是HMS通过JDO方式获取所有的Function,在获取所有的udf时后台会遍历每条func去关联DBS、FUNC_RU两个表,获取性能极低。而使用directSQL的方式去获取所有udf数据,响应耗时都在1秒以内完成,性能提升相当明显。以下为directSQL的SQL实现逻辑:
select FUNCS.FUNC_NAME,DBS.NAME,FUNCS.CLASS_NAME,FUNCS.OWNER_NAME,FUNCS.OWNER_TYPE,FUNCS.CREATE_TIME,FUNCS.FUNC_TYPE,FUNC_RU.RESOURCE_URI,FUNC_RU.RESOURCE_TYPE
from FUNCS
left join FUNC_RU on FUNCS.FUNC_ID = FUNC_RU.FUNC_ID
left join DBS on FUNCS.DB_ID = DBS.DB_ID五、总结
我们从2021年7月份开始对TiDB进行调研,在经历数个月的测试于同年11月末将MySQL引擎切换到TiDB。由于前期测试主要集中在兼容性和性能测试上,忽略了TiDB自身可能潜在的问题,在上线初期经历了数次因慢查询日志将TiDB内存打爆的情况,在这特别感谢我们的DBA团队、平台运营团队及TiDB官方团队帮忙分析、解决问题,得以避免该问题的再次发生;与此同时,由于当前HMS使用的版本较低,加上大数据的组件在不断的升级演进,我们也需要去兼容升级带来的变动,如HDFS升级到3.x后对EC文件读取的支持,SPARK获取分区避免全表扫描改造等;此外由于TiDB的latin字符集支持中文字符的写入,该特性会导致用户误写入错误的中文分区,对于此类型数据无法通过现有API进行删除,还需要在应用层去禁止该类型错误分区写入,避免无用数据累积。
经历了一年多的实际生产环境检验,TiDB内存整体使用在10%以内,TiKV CPU使用平稳,使用峰值均在30核内,暂不存在系统瓶颈;HMS服务的稳定性整体可控,关键API性能指标满足业务的实际需求,为业务的增长提供可靠支持。在未来三年内,我们将保持该架构去支撑整个大数据平台组件的稳定运行,期间我们也将持续关注行业内的变动,吸收更多优秀经验应用到我们的生产环境中来,包括但不限于对性能更好的高版本TiDB尝试,HMS的性能优化案例。