一、写在前面
好久不更新咯,因为没有什么有意思的东西分享的。
今天更新,是因为GPT整合了自家的图像生成工具,名字叫作DALL·E 3。
DALL·E 3是OpenAI推出的一种生成图像的模型,它基于GPT-3架构进行训练,但是它的主要目的是将文本描述转化为图像。以下是DALL·E 3的一些主要功能:
(1)图像生成:DALL·E 3可以根据给定的文本描述生成相应的图像。
(2)多样性:通过不同的文本描述,DALL·E 3可以生成多种风格和内容的图像。
(3)细节捕捉:DALL·E 3能够根据具体和详细的描述生成相应细节的图像。
(4)多图像输出:对于一个描述,DALL·E 3可以生成多个不同风格或角度的图像。

二、开始尝鲜
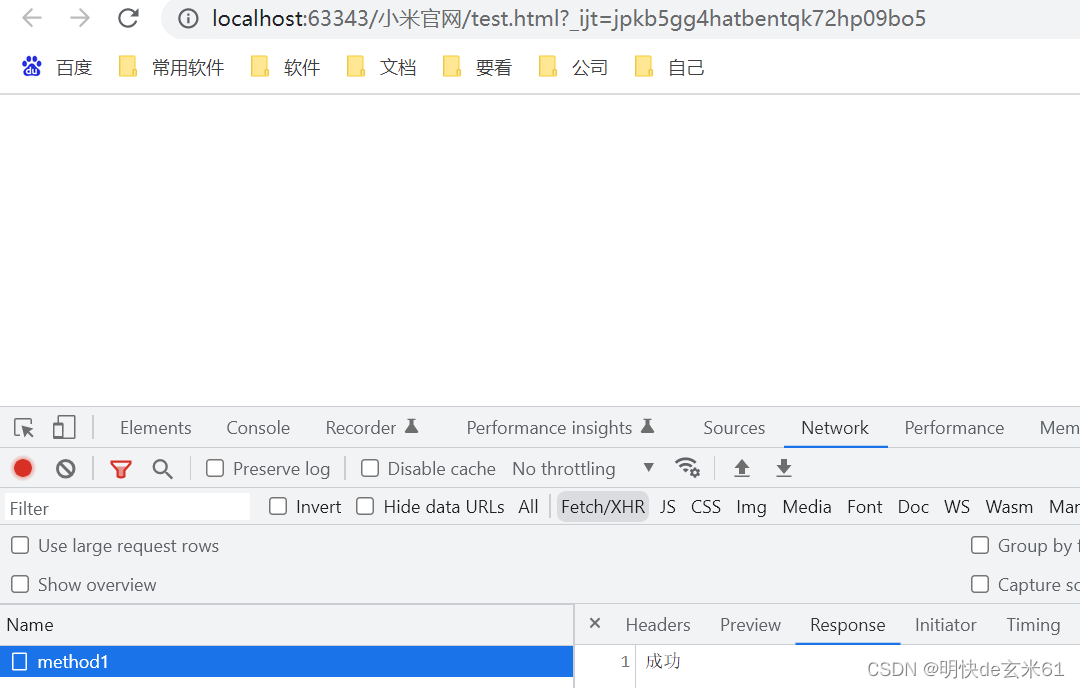
(1)咒语:生成一个猫咪的图片。
GPT回复:

首先,GPT自己提供了四个更详细的咒语,用于生成我们所需要的猫咪。
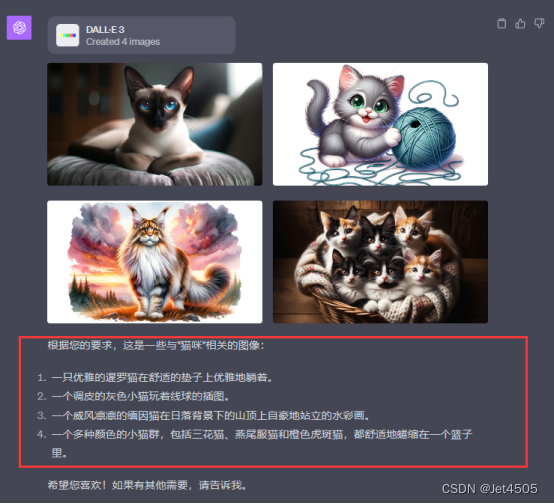
其次,GPT根据自己生成的咒语,生成了四张猫咪的图片。我们可以点击其中一张图片,放大查看,也可以把图片下载备用。

(2)咒语:将图一的猫咪的眼睛换成不同颜色。
GPT回复:

好吧,怪我没说清楚。
(3)咒语:将图一的猫咪的眼睛换成不同颜色,其中左眼是绿色,右眼是充满活力的榛子色。
GPT回复:

这下子OK了。接下来,我想试试换一个姿势。
(4)咒语:将图中猫咪换成炸毛、弓背的攻击姿态,并把背景换成野外。
GPT回复:

嗯,这个弓背跟我想象的不太一样,哈哈哈。
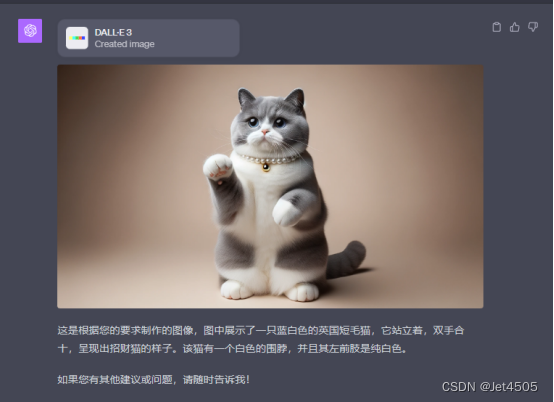
(5)咒语:将图中猫咪换成英国短毛猫,蓝白色,有个白色围脖,左前肢是纯白。站立姿势,双手合十,呈现出招财猫的样子。
三、写在最后
DALL·E 3作为一个先进的文本到图像的生成模型,个人觉得在我们日常工作中会有很大的作用。例如,在教育上,有助于学生更好地理解复杂的概念通过可视化,或者为教育材料创建定制的插图。在科研上,将抽象的科学概念转化为直观的图像,或者直接点,给你的标书画画插图什么的。
当然,绘画界的先驱还的是Midjourney,但是呢,同样是要花钱,我宁愿花一分钱,实现多种功能。
今天只是尝个鲜,后续实战有啥收获,继续分享。