一、定义
网络爬虫,是按照一定规则,自动抓取网页信息。爬虫的本质是模拟浏览器打开网页,从网页中获取我们想要的那部分数据。
二、Python为什么适合爬虫
Python相比与其他编程语言,如java,c#,C++,python抓取网页的接口更简洁;并且有丰富的网络抓取模块。
三、爬虫库beautifulsoup
1、Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。
2、Beautiful Soup抓取数据后得到一个文档对象(beautifulsoup对象),其实也是一个复杂的树形结构文档,因此还需要解析器来解析这段文档。可以使用Python自带的html.parser进行解析,也可以使用lxml进行解析(相对于其他几种来说要强大一些)。
说明:选择使用lxml解析器解析,需要安装lxml模块,但是使用时候无需import lxml
3、模块安装
pip install bs4
pip install lxml
4、模块导入
from bs4 import BeautifulSoup
5、BeautifulSoup方法
BeautifulSoup(markup, features)接受两个参数:第一个参数(markup):文件对象或字符串对象第二个参数(features):解析器,未指定则使用python自带的标准解析器(html.parser),但会产警告6、 Beautiful Soup对象
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: BeautifulSoup 、Tag 、NavigableString 、Comment 。

6.1 BeautifulSoup对象
BeautifulSoup对象对象表示的是一个文档的全部内容。
例如:
from bs4 import BeautifulSoup # 导入BeautifulSoup4库f1 = open(r'D:\Document\Workspace\pywokrspace\test1\urllib_test_runoob_search.html','r',encoding='utf-8')
soup1 = BeautifulSoup(f1,'lxml')#使用lxml解析器解析
print(soup1)
f1.close()
返回的内容为Beautiful Soup对象文档,其实和html页面很类似。
<!DOCTYPE html>
<html>
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<meta content="width=device-width, initial-scale=1.0" name="viewport"/>
<title>Python 教程 的搜索結果</title>
<meta content="noindex, follow, max-image-preview:large" name="robots"/>
<link href="https://static.runoob.com/images/icon/mobile-icon.png" rel="apple-touch-icon"/>
<meta content="菜鸟教程" name="apple-mobile-web-app-title"/>
</head>
<body>
<!-- 头部 -->
<div class="col search row-search-mobile">
<form action="index.php">
<input autocomplete="off" class="placeholder" name="s" placeholder="搜索……"/>
</form>
</div>
</body>
</html>
6.2 Tag对象
1、Tag即HTML或XML中的标签对:Tag对象与XML或HTML原生文档中的tag相同。
2、获取Tag对象
步骤一:从一个beautifulsoup对象中获取指定的Tag对象,可以使用:beautifulsoup对象.标签名,要获取哪个标签的Tag对象,就传入哪个标签的标签名,它返回的是一个标签。注:当存在多个标签名相同时,这种方法返回的Tag对象是所有内容中第一个符合要求的标签。
步骤二:获取tag对象的属性,返回属性内容字典
属性说明:
-
(1)、attrs属性:指的是一个标签的属性,一个标签的属性一般是由键值对组成,属性名=值
(2)、一个标签可能有很多个属性
(3)、获取一个Tag对象的attrs属性,可以使用:Tag对象.attrs
(4)、使用Tag对象的attrs属性可以把标签对的属性以字典形式返回Tag对象无属性时返回的是一个空字典
步骤三:获取到Tag对象属性后,可以继续使用使用字典方法获取标签对中的具体数据
举例说明:
from bs4 import BeautifulSoup # 导入bs4库html = """<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>"""
soup = BeautifulSoup(html, "lxml") # 指定解析器
a_tag = soup.a # 获取a标签
print("a标签的tag对象为:", a_tag)
a_tag_attrs = soup.a.attrs # 获取a标签的属性,也可先获取a标签,再获取a属性,分2步
print("a标签的tag对象的属性为:", a_tag_attrs)
a_tag_attrs_href_dict = a_tag_attrs["href"] # 使用字典的索引
print("通过字典索引获取到的tag对象的属性"+ a_tag_attrs_href_dict)
输出:
a标签的tag对象为: <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
a标签的tag对象的属性为: {'href': 'http://example.com/tillie', 'class': ['sister'], 'id': 'link3'}
通过字典索引获取到的tag对象的属性http://example.com/tillie
6.3、NavigableString对象
1、NavigableString对象:指的是标签对中的数据
2、获取一个Tag对象中的数据(NavigableString对象),可以使用:Tag对象.string
from bs4 import BeautifulSoup # 导入bs4库html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story A</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Tillie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3"><!-- Elsie --></a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml") # 指定解析器,创建beautifulsoup对象
head_string = soup.head.string
p_string = soup.p.string
a_tag = soup.a
a_tag_string = a_tag.string
print("header标签中的数据为:", head_string)
print("p标签中的数据为:", p_string)
print("a标签中的数据为:",a_tag_string)
6.4 Comment对象
Comment 对象是一个特殊类型的NavigableString对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
举例说明:
from bs4 import BeautifulSoup # 导入bs4库html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml") # 指定解析器,创建beautifulsoup对象
print("a标签的tag对象为:", soup.a)
print("a标签内的数据为:", soup.a.string) # a标签内的数据为一个注释
输出:
a标签的tag对象为: <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
a标签内的数据为: Elsie
6.5 补充
获取Tag对象,上面提到:使用beautifulsoup对象.标签名获取标签的Tag对象,当存在多个标签名相同时,它返回的是所有内容中第一个符合要求的标签。
获取某个指定的tag有两种情况:一种是获取指定的第一个标签(这种实际中用得很少),另一种是获取指定的全部标签对
场景一:获取指定的第一个标签
获取指定的第一个标签就是使用前面介绍的"soup对象.标签名"
这种方法总计如下:
1、获取某个标签对可以使用:soup对象.标签名
2、这种方法:只能获得整个文档中第一个符合要求的标签(存在多个一样的标签对时只会返回第一个)
3、如果想要的标签对中镶嵌了其他标签对,那么也会把里面镶嵌的标签对一起返回
4、这种方法在实际运用中发现:不能把标签名定义成变量,就是不能通过变量来批量获得一些标签对,所以这种方法有比较大的局限性
场景二:获取指定的全部标签对
1、要获取一个文档中某个指定的所有标签,就需要使用find_all()方法:BeautifulSoup对象或Tag对象都可以使用find_all()方法来找其下面的子标签
2、其参数可以是很多类型,最常用的是:传入需要获取的标签的标签名
3、find_all()方法返回的是一个由所有符合要求的标签组成的列表
举例如下:
from bs4 import BeautifulSouphtml = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml")tag_body = soup.find_all("p") # 获取所有p标签的tag对象
print("p标签对为:", tag_body)tag_a = soup.find_all("a") # 获取所有a标签的tag对象
print("a标签对为:", tag_a)
输出:
p标签对为: [<p class="title" name="dromouse"><b>The Dormouse's story</b></p>, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>, <p class="story">...</p>]
a标签对为: [<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]4、上面是使用find_all()方法获取所有符合要求的tag对象组成的列表,然后可以遍历出每一个tag对象,最后获得每一个tag对象的name、attrs属性以及string
举例如下:
from bs4 import BeautifulSouphtml = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""soup = BeautifulSoup(html, "lxml")def parse_msg(tagName):tags = soup.find_all(tagName) # find_all()返回的是一个由tag对象组成的列表,因此需要遍历for tag in tags:print("标签的tag对象为为:", tag)print("标签的属性为:", tag.attrs)print("标签的数据为:", tag.string)parse_msg("a")
parse_msg("p")输出:
标签的tag对象为为: <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
标签的属性为: {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
标签的数据为: Elsie
标签的tag对象为为: <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
标签的属性为: {'href': 'http://example.com/lacie', 'class': ['sister'], 'id': 'link2'}
标签的数据为: Lacie
标签的tag对象为为: <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
标签的属性为: {'href': 'http://example.com/tillie', 'class': ['sister'], 'id': 'link3'}
标签的数据为: Tillie标签的tag对象为为: <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
标签的属性为: {'class': ['story']}
标签的数据为: None
标签的tag对象为为: <p class="story">...</p>
标签的属性为: {'class': ['story']}
标签的数据为: ...
也可以看出:这种嵌套在里面的标签对,如果返回的是外层的tag对象,那也只能获得外层tag对象的name和attrs属性
NavigableString对象同理tag对象:
1、获取标签对中的NavigableString对象,可以使用:soup对象.标签名.string的方法来获取(跟前面name或attrs一样,只是说这里的字符串属于另一个对象)。且这种方法只会返回第一个符合要求的标签对中的字符串
2、也可以先试用find_all()的方法先找出全部符合要求的标签对,然后遍历得到每一个标签对内的字符串
另外还有
1、find()方法,find()与find_all() 用法一样,区别是 find_all() 方法的返回结果是值包含一个元素的列表,而 find() 方法直接返回结果(即找到了就不再找,只返第一个匹配的),find_all() 方法没有找到目标是返回空列表, find() 方法找不到目标时,返回 None。
2、get_text()方法:只输出tag中的文本内容
from bs4 import BeautifulSoupmarkup = '<a href="http://example.com/">I linked to <i>example.com</i>点我</a>'
soup = BeautifulSoup(markup, "lxml")
print(soup)
print(soup.get_text())
3、select()方法:可以按标签查找,用的多是按标签逐层查找筛选元素
Beautiful Soup支持大部分的CSS选择器,在 Tag 或 BeautifulSoup 对象的 .select() 方法中传入字符串参数, 即可使用CSS选择器的语法找到tag。可以按标签逐层查找到我们需要的内容,这点特别方便,就是定位,避免了单一的标签无法定位到我们所需要的内容元素。
soup.select("html head title") #标签层级查找
soup.select("td div a") #标签路径 td-->div-->a
soup.select('td > div > a') #note:推荐使用这种记法
选择谷歌浏览器,右键copy --copy selector,可以得到对应的CSS选择器。如下:
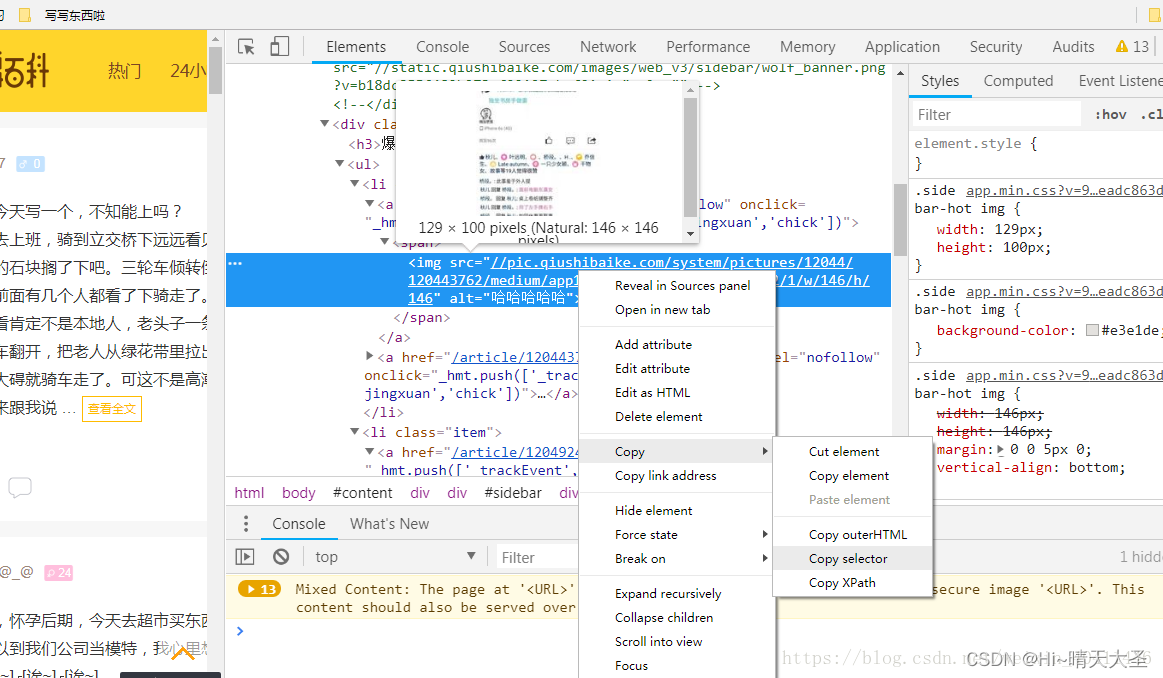
div > a > div > span (我运行的时候发现一个问题,> 前后一定要有空格,不然会报错的)
#coding=utf-8
from bs4 import BeautifulSoup
import requests#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:print(link.get_text())
四、网络请求
在使用Python爬虫时,需要模拟发起网络请求访问html页面(上面案例为了方便查阅,直接赋值了一个页面),主要用到的库有requests库和python内置的urllib库,一般建议使用requests,它是对urllib的再次封装。
requests的优势:Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,一步到位,而urllib.request只能先构造get,post请求,再发起,需要分2步完成。
requests模块的使用方法见文档《Python requests模块》
五、RE模块(标准库)
在html文档中获取到的内容,可能还不够细致,比如,我们取到的是不是我们想要的链接、不是我们需要提取的邮箱数据等等,为了提取细精确的数据,需要使用正则表达式。
RE模块的使用方法见文档《Python 正则表达式》
六、案例实践
#coding=utf-8
from bs4 import BeautifulSoup
import requests#使用requests抓取页面内容,并将响应赋值给page变量
html = requests.get('https://www.qiushibaike.com/text/')#使用content属性获取页面的源页面
#使用BeautifulSoap解析,吧内容传递到BeautifulSoap类
soup = BeautifulSoup(html.content,'lxml')
#我是分隔符,下面就是select()方法咯~
links = soup.select('div > a >div >span')
for link in links:print(link.get_text())


![[补题记录] Atcoder Beginner Contest 297(F)](https://img-blog.csdnimg.cn/b1b85ba027524ec2a40a4e67a743166c.png)