文章目录
- 3. 分布式文件系统HDFS
- 3.1 分布式文件系统HDFS简介
- 3.2 HDFS相关概念
- 3.3 HDFS的体系结构
- 3.4 HDFS的存储原理
- 3.5 HDFS数据读写
- 3.5.1 HDFS的读数据过程
- 3.5.2 HDFS的写数据过程
- 3.6 HDFS编程实战
3. 分布式文件系统HDFS
3.1 分布式文件系统HDFS简介
-
HDFS就是解决海量数据的分布式存储问题
-
为什么会出现分布式文件系统?

-
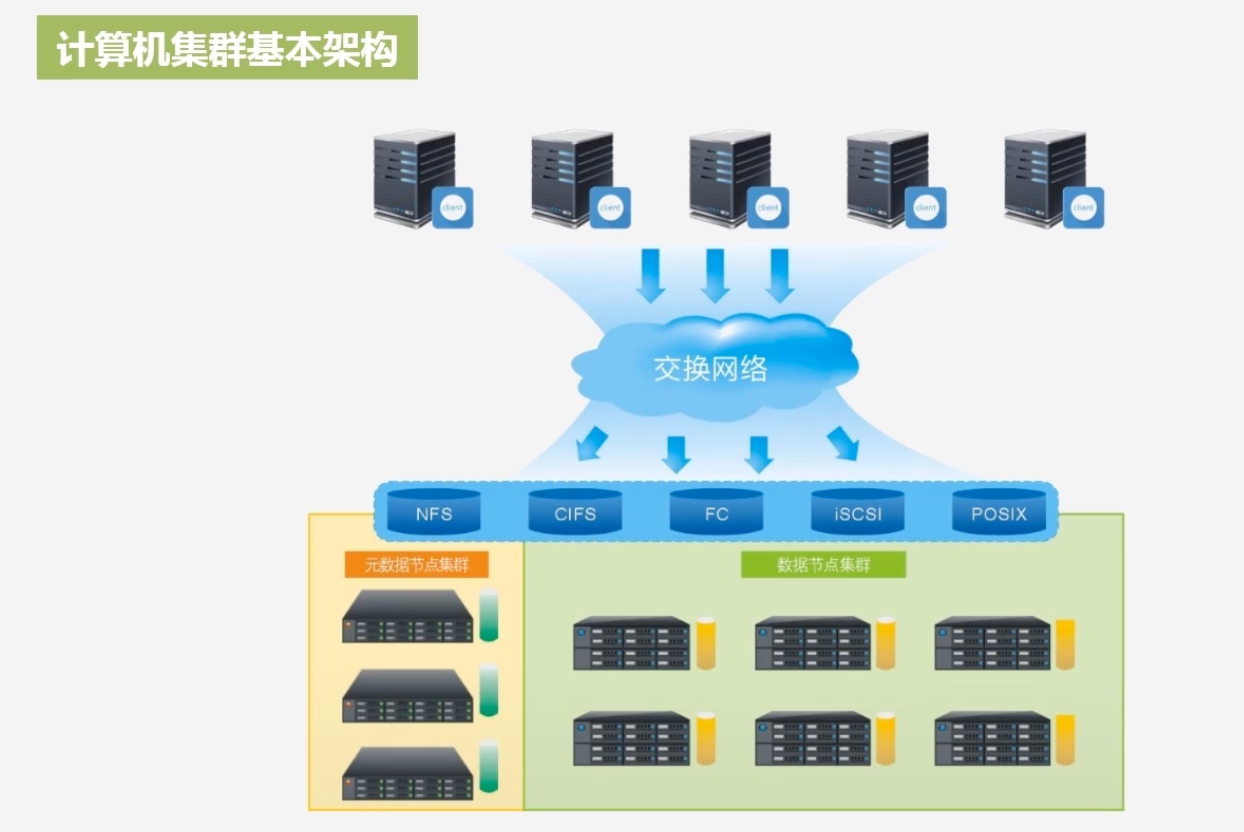
计算机集群基本架构
- 每个机架由若干个节点构成

-
机架的内部之间是通过光纤交换机进行连接,机架与机架通过带宽更高的光纤交换机进行连接
-
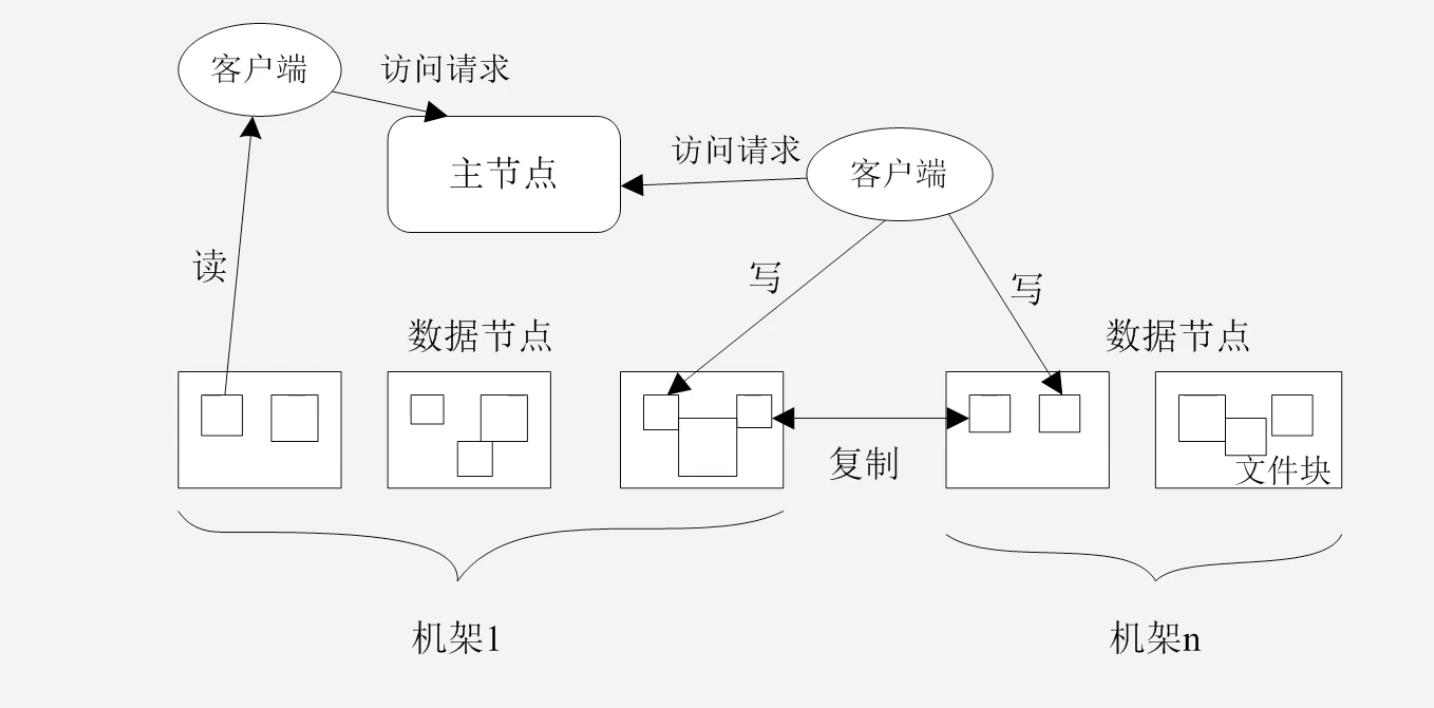
分布式文件系统的存储结构
-
主节点存储相关的元数据服务:目录存储服务,从节点需要完成相关的数据存储任务
-
-
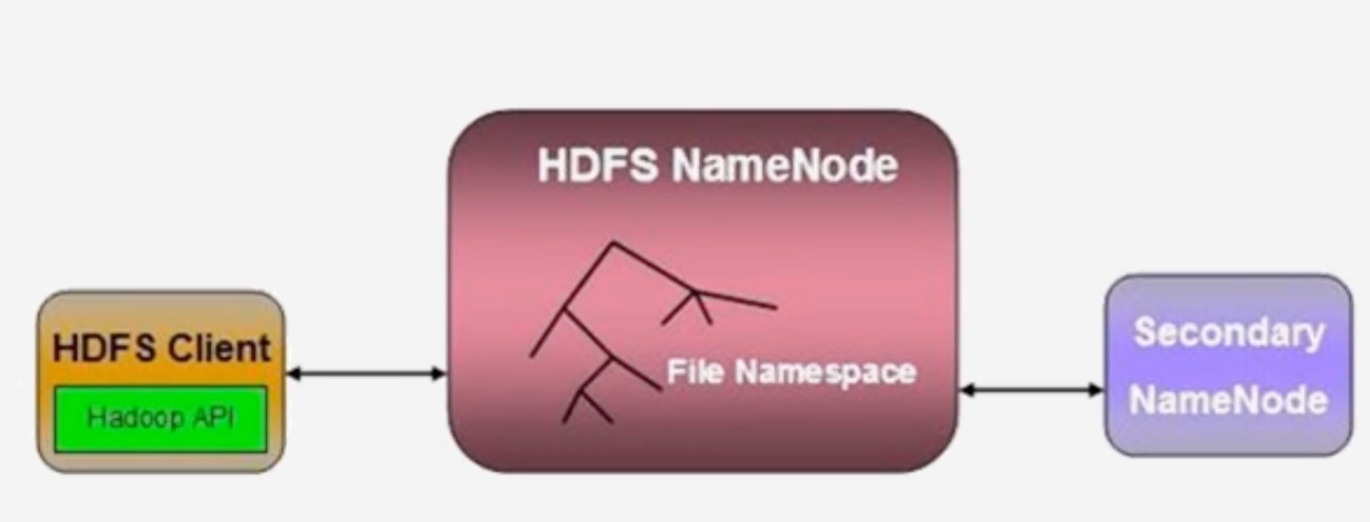
HDFS是非常流行的一个分布式存储系统
-
HDFS实现的目标
- 兼容廉价的硬件设备
- 实现流数据读写
- 支持大数据集
- 支持简单的文件模型
- 强大的跨平台兼容性:基于JAVA语言开发,JAVA语言有着良好的跨平台特性
-
HDFS局限性
- 不适合低延迟数据访问:不能满足实时的处理需求
- 无法高效存储大量小文件:因为HDFS是通过元数据指引到客户端的哪个节点找文件,这些namenode会被保存到内存中去,到内存中检索索引数据结构,如果小文件太多,这个索引结构会过于庞大,在索引结构中搜索的效率会越来越低
- 不支持多用户写入以及任意修改文件
3.2 HDFS相关概念
-
块的概念
- 块的大小比普通文件系统大很多,普通文件系统可能几字节,它可以达到64M或者128M
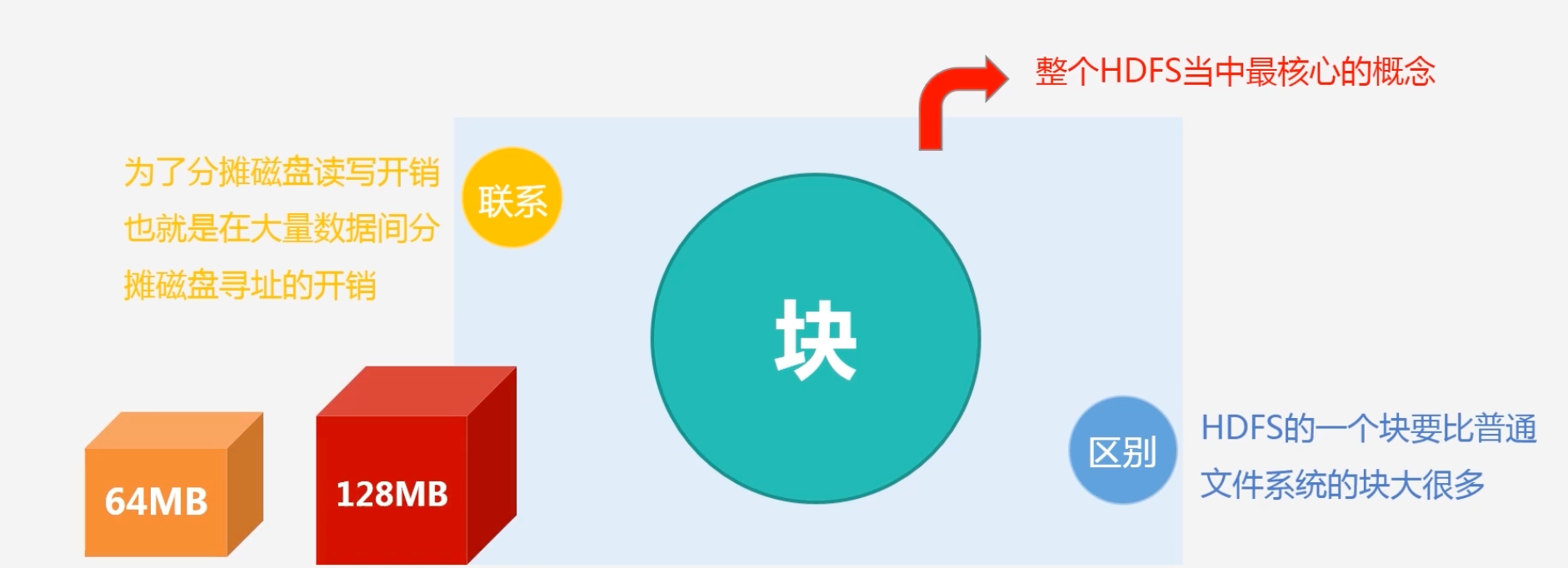
- HDFS采用这种抽象的块的概念设计好处?为什么要这样设计块?
- 为了支持面向大规模的数据存储:对大文件进行切割,可以分别存储在不同的数据节点,可以突破单机存储的上线
- 简化系统设计:通过块设计方便元数据管理,块大小固定,可以很容易知道一个文件需要几个块进行存储
- 适合数据备份:一个块可以冗余的存储到多个不同的节点上
- 同时降低分布式节点的寻址开销:访问HDFS数据需要经过三级寻址:元数据目录–>数据节点–>取数据
- 块是否是设置的越大越好?
- 不是,如果块过大会导致MapReduce就一两个任务时,在执行完全牺牲了MapReduce的并行度,发挥不了分布式并行处理的效果
-
HDFS的两大组件
-
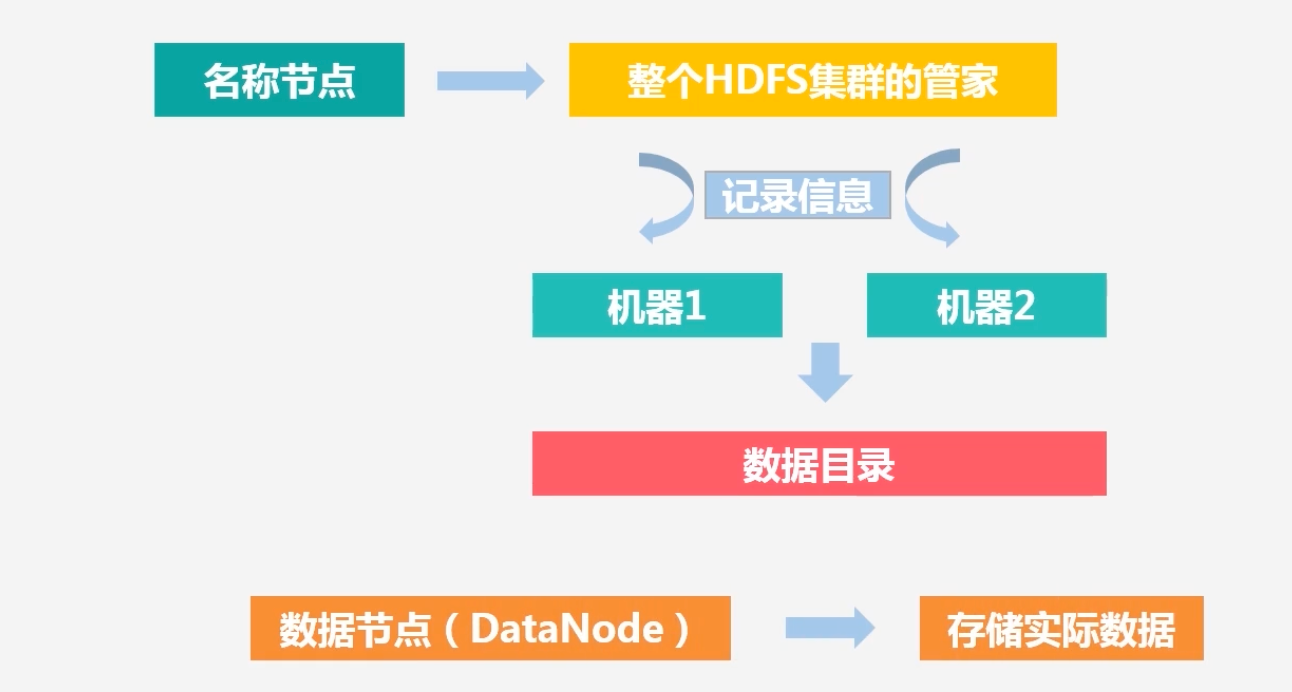
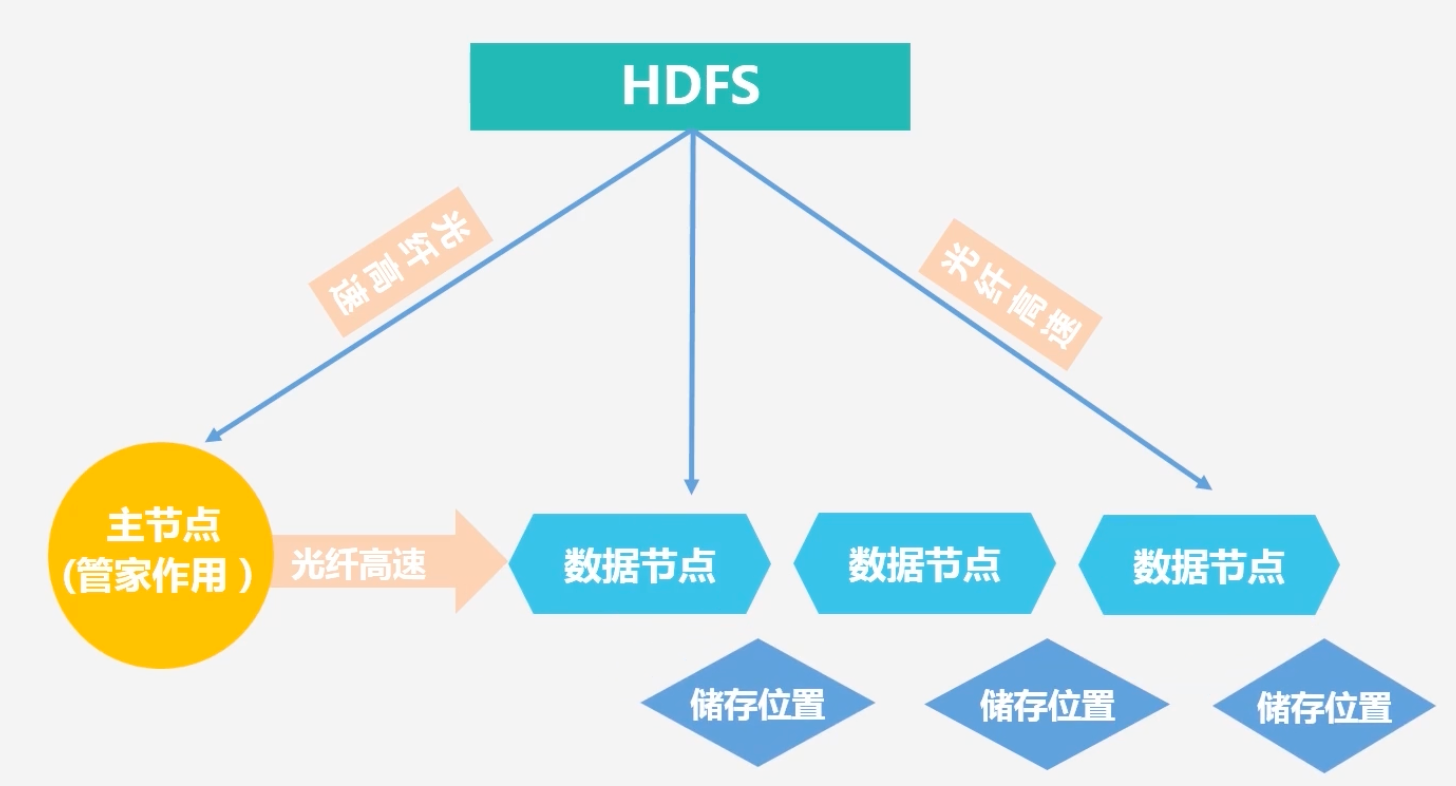
名称节点(NameNode):整个HDFS集群的管家,假如客户端访问一个特别大的文件,通过NameNode可以知道这个大文件的每一个块被放置在哪个机器节点之上
-
数据节点(DateNode):负责存储实际数据,将数据保存到本地的Linux文件系统中去
-
-
元数据的作用?

-
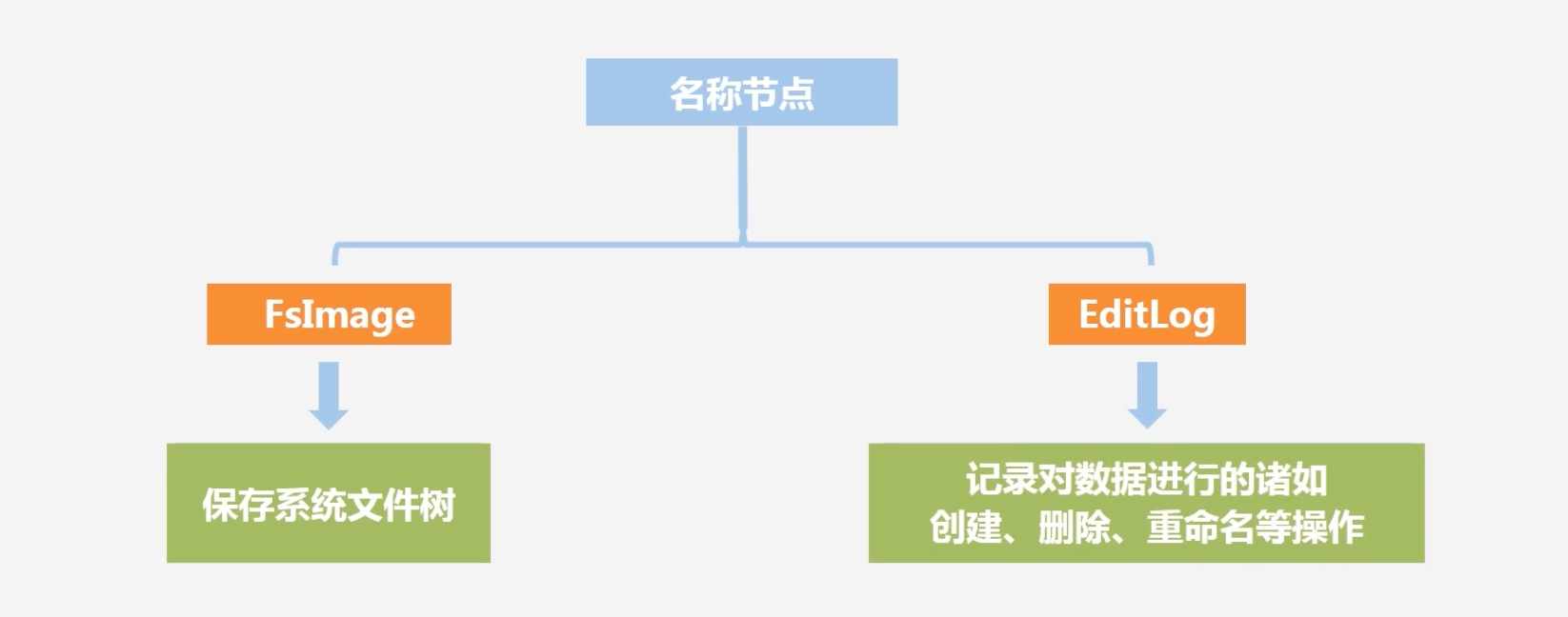
名称节点包含的两大结构:FsImage和EditLog
-
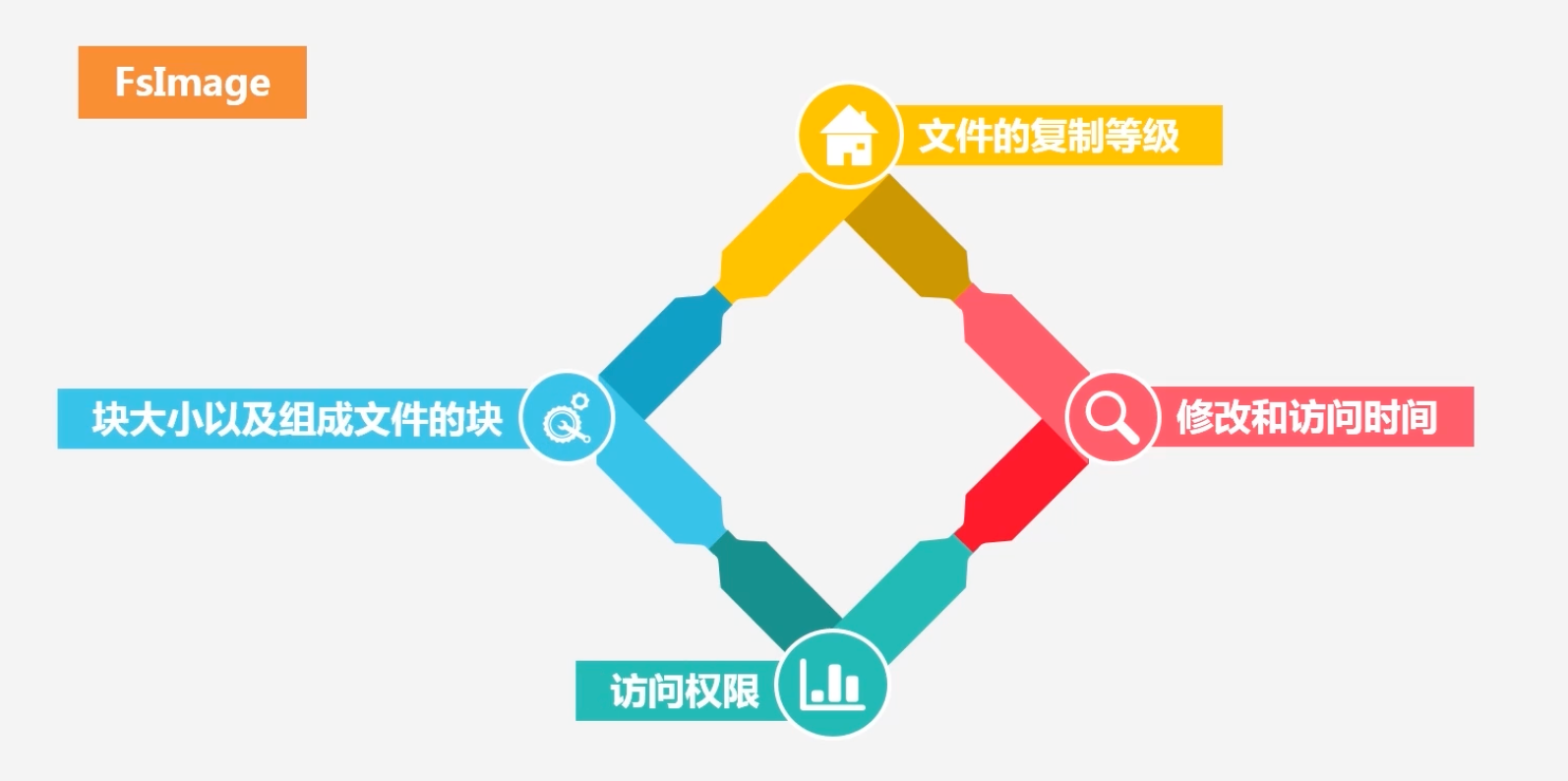
FsImage包含内容
注意FsImage不保存块具体在数据节点的位置,这个在单独的内存区域维护的
数据节点中加入新数据–>向名称节点汇报数据节点中包含哪些块–>名称节点构建清单:包含各个块的位置分布
-
-
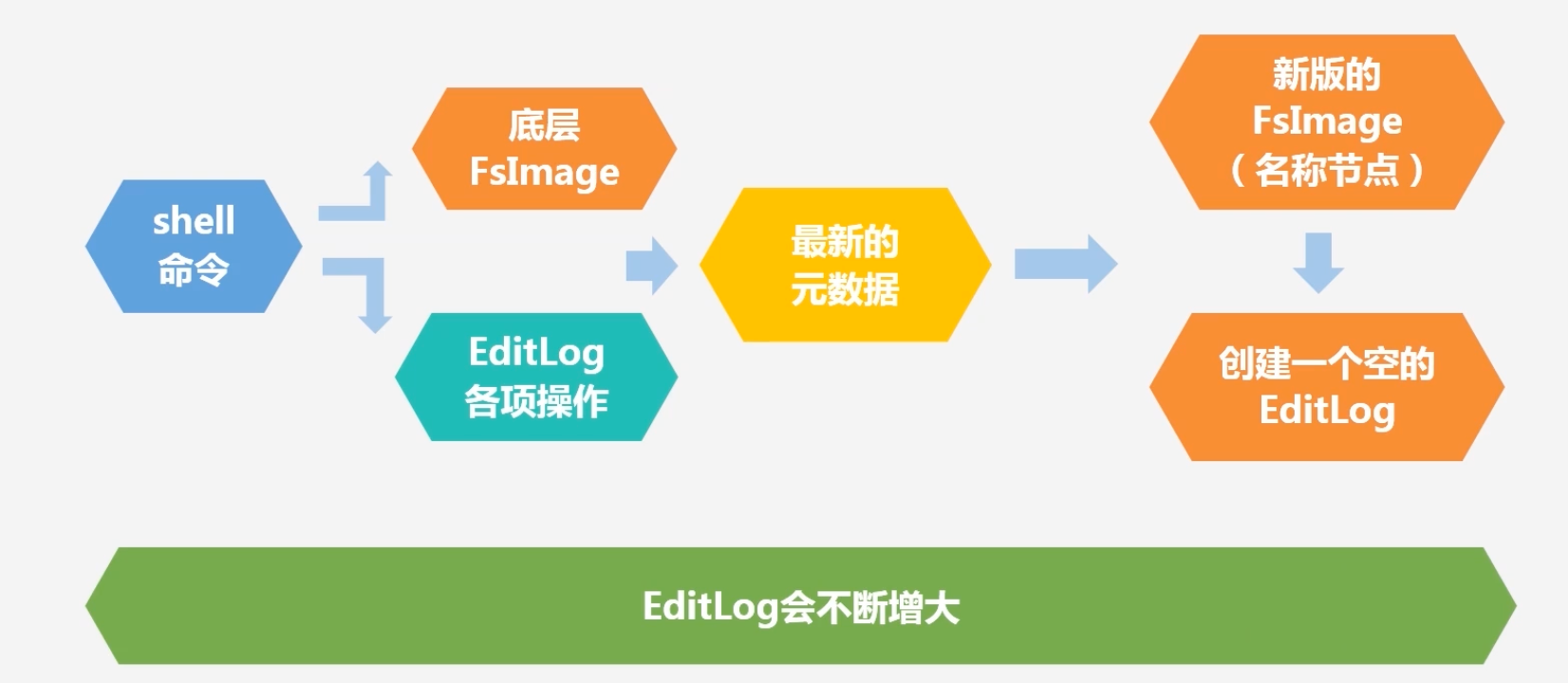
HDFS要如何利用NameNode的数据结构
- shell命令启动NameNode–>将FsImage从后台加载到内存中去,和EditLog中的内容进行合并(对数据结构的修改记录存储在EditLog中)–>得到最新元数据–>将新版FsImage保留,创建空的EditLog
- EditLog永远保存的是更新操作(增量操作),然后再将EditLog合并到FsImage中去
-
但是若是不断的修改操作,会使得EditLog不断增加,影响整体使用的性能?怎么办?
-
引入第二名称节点(SecondNameNode):
- 作为名称节点的冷备份
- 对EditLog的处理
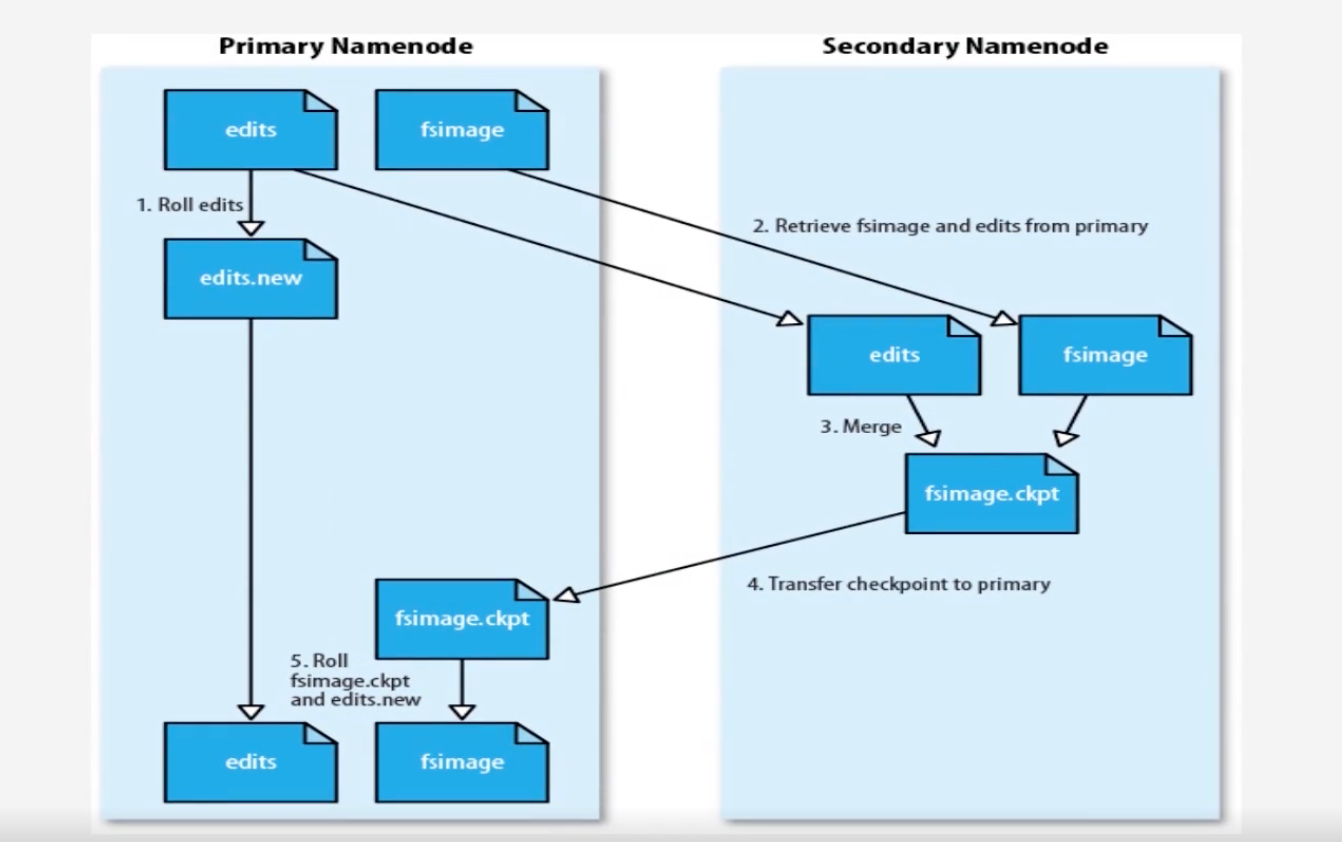
- 在第一名称节点的EditLog较大时,第二名称节点会告诉第一名称节点停止使用EditLog文件,并将EditLog写入自己机器

-
1.此时NameNode会马上停止,此时生成edits.new,将新到达的更新写到edits.new中,将原来旧的editlog内容由secondNameNode取走
-
2.SecondNameNode会通过http的get方式,将NameNode的FsImage和EditLog都下载到本地,然后在SecondNameNode做合并操作,得到新的FsImage,然后发送给NameNode

-
3.NameNode再将Edits.new更改为EditLog:即实现了不断增加的Editlog和FsImage合并,又实现了冷备份效果

-
数据节点:存储数据,数据节点拿到存储数据的文件目录,又将数据保留到各自的linux文件系统中去
3.3 HDFS的体系结构
-
主节点:管家作用;从节点:数据存储作用
-
HDFS的命名空间
-
HDFS的目录访问和普通目录相同,都是通过/进行访问

-
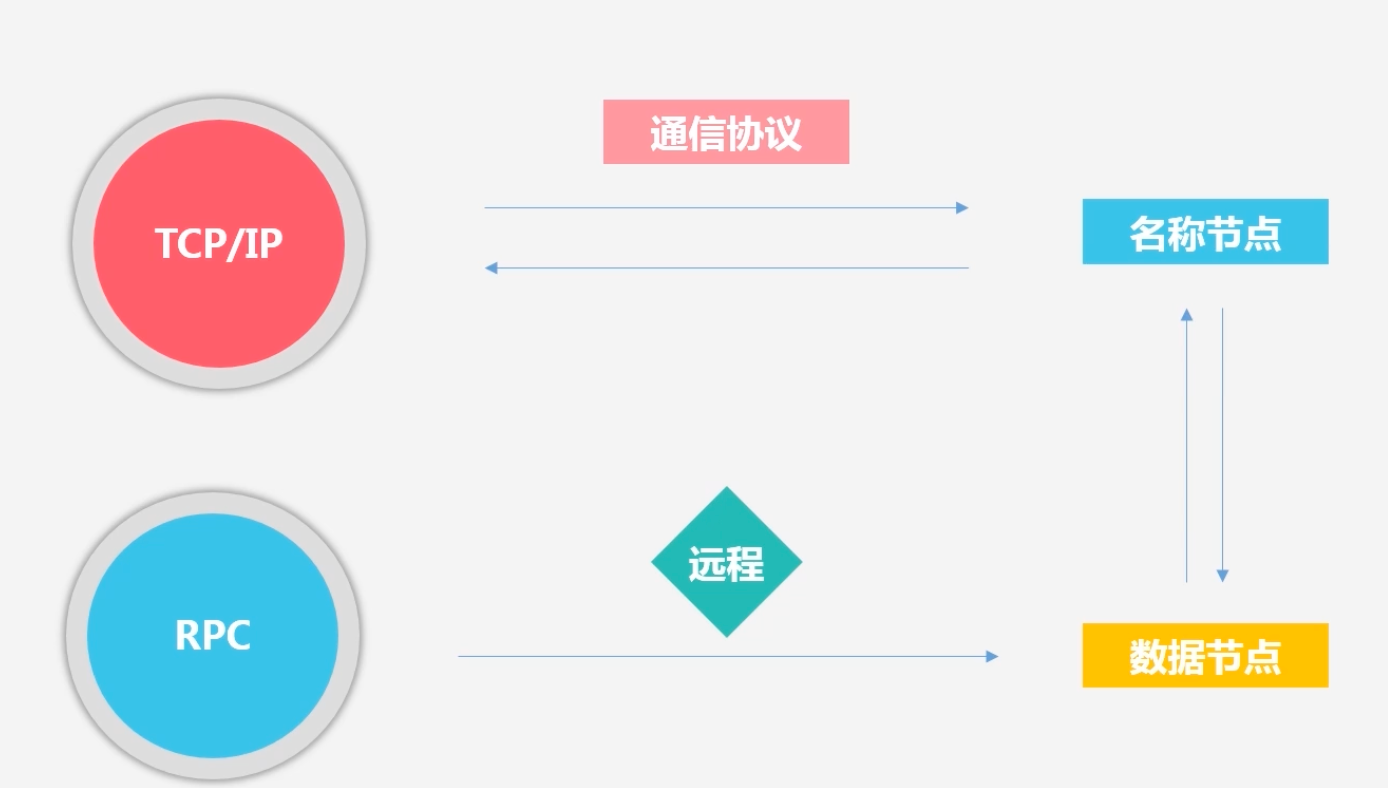
所有的HDFS基于TCP/IP的通信协议,不同组件之间的通信协议有差异:例如客户端向名称节点发起TCP连接,使用客户端协议和名称节点进行交互;客户端和数据节点进行交互是通过远程调用:RPC来进行实现的
-
-
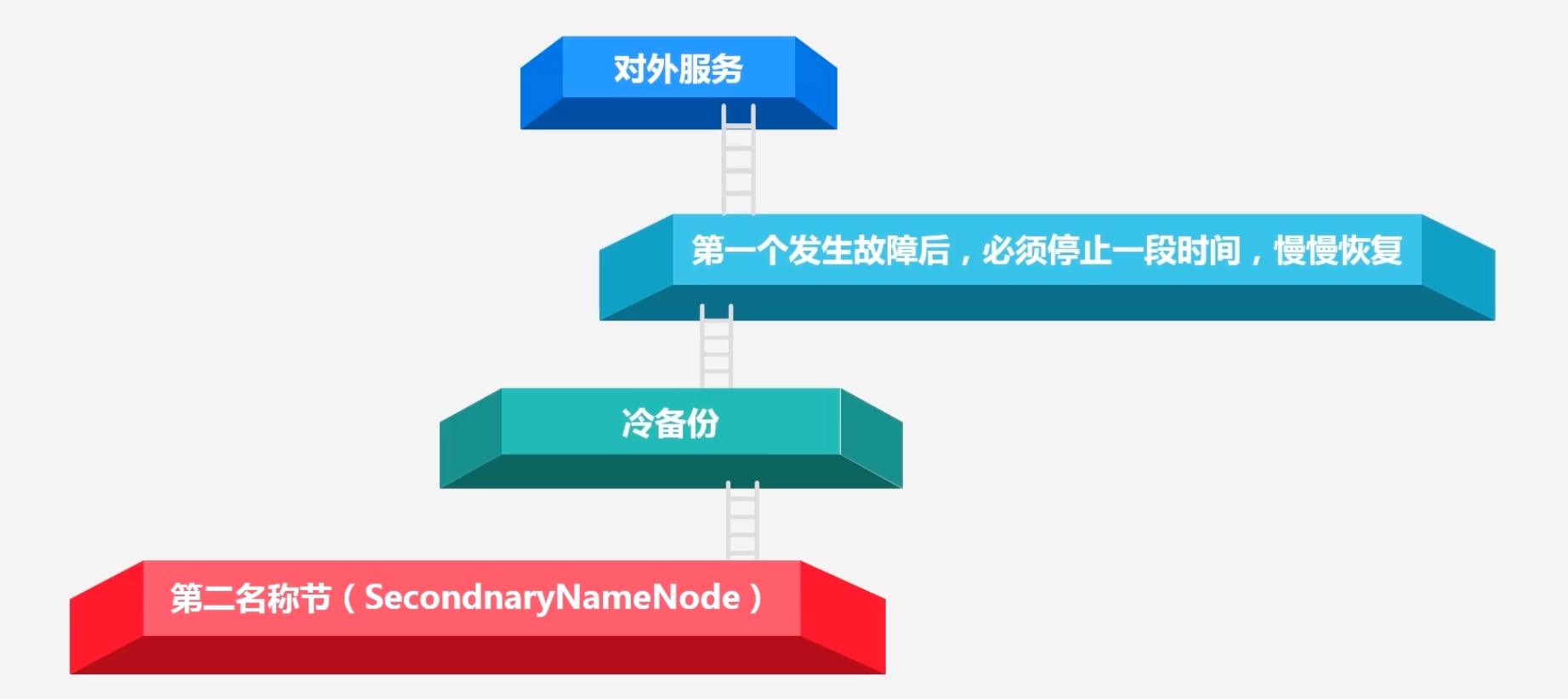
HDFS体系结构的局限性:

注意secondNamenode并不能保证集群的可用性:
因为secondNameNode是冷备份,就是在故障发生时,必须停止一段时间,慢慢恢复,这个恢复的过程会导致整个集群的不可用
-
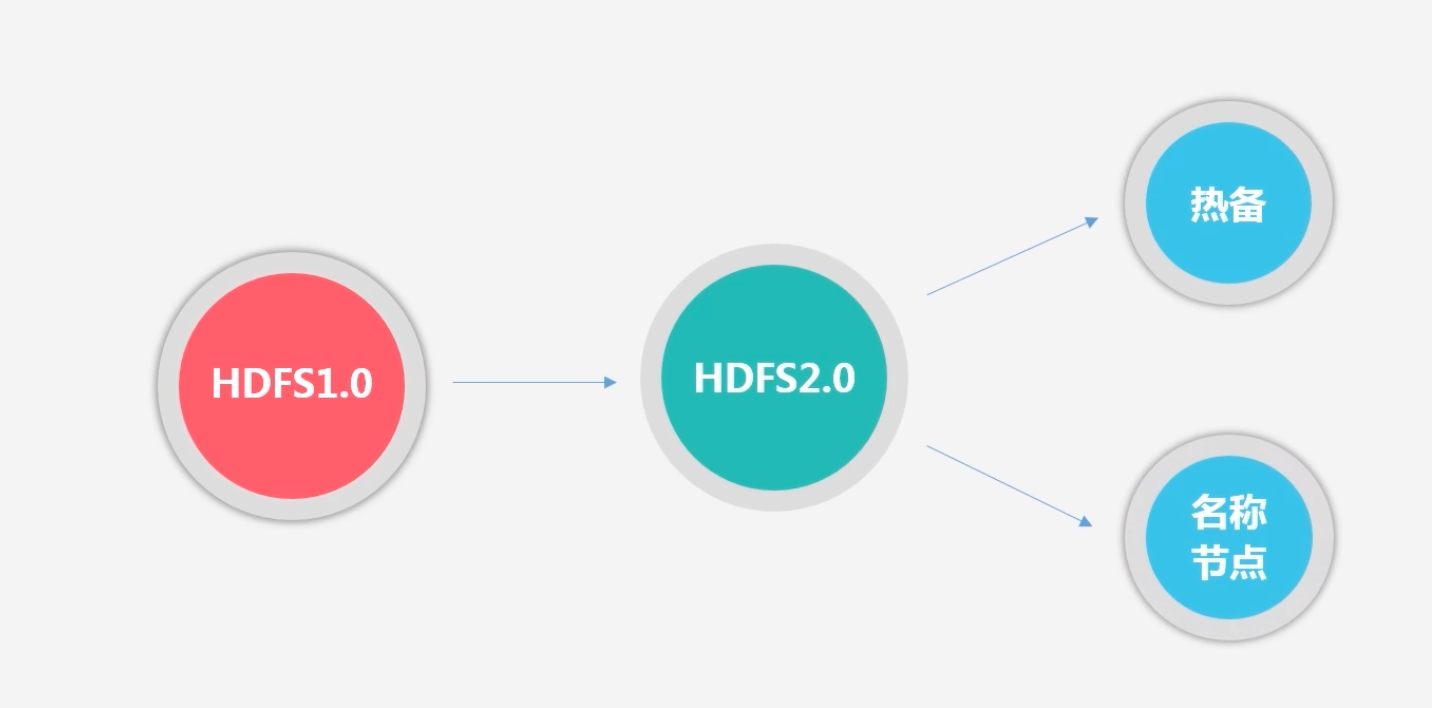
如何解决?HDFS2.0
3.4 HDFS的存储原理
-
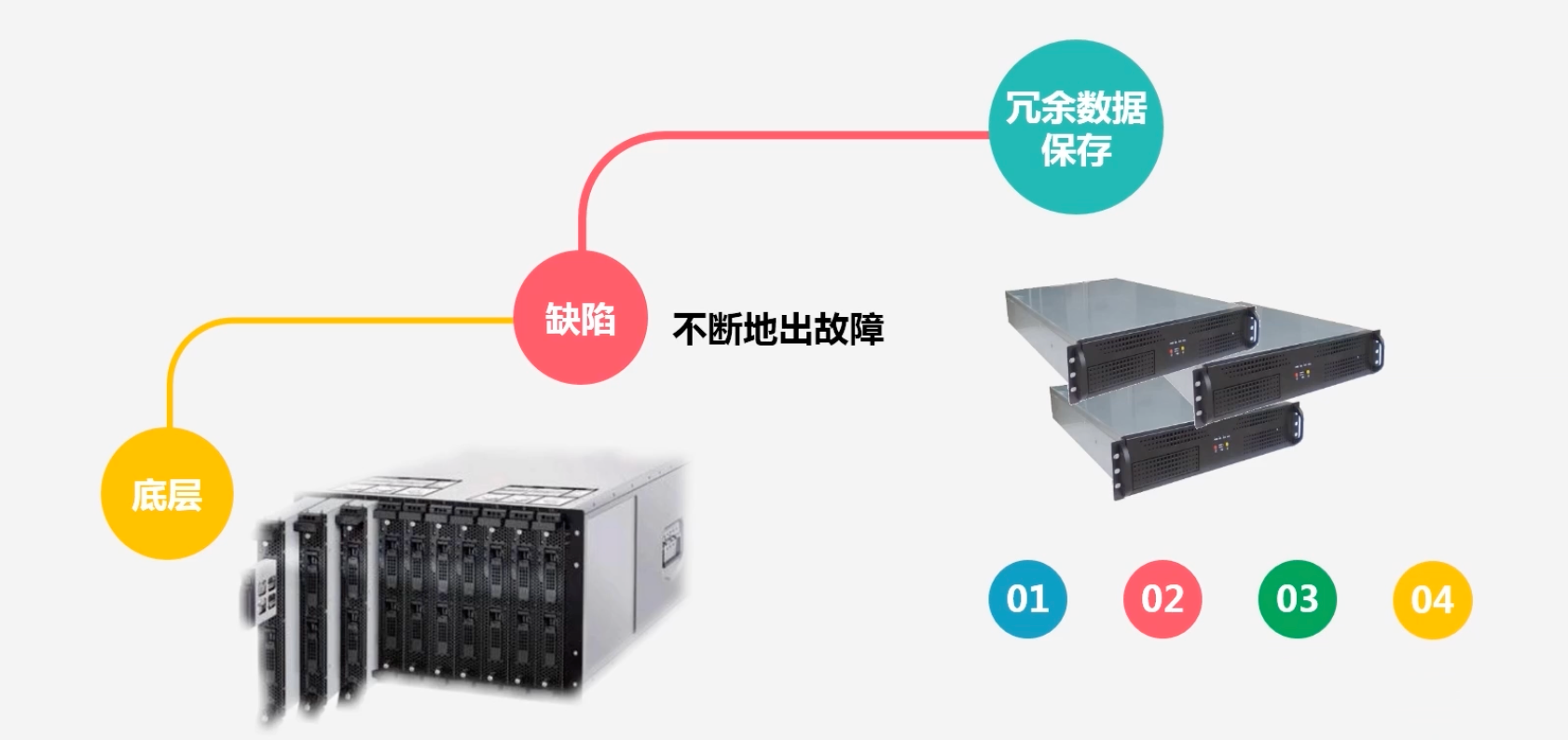
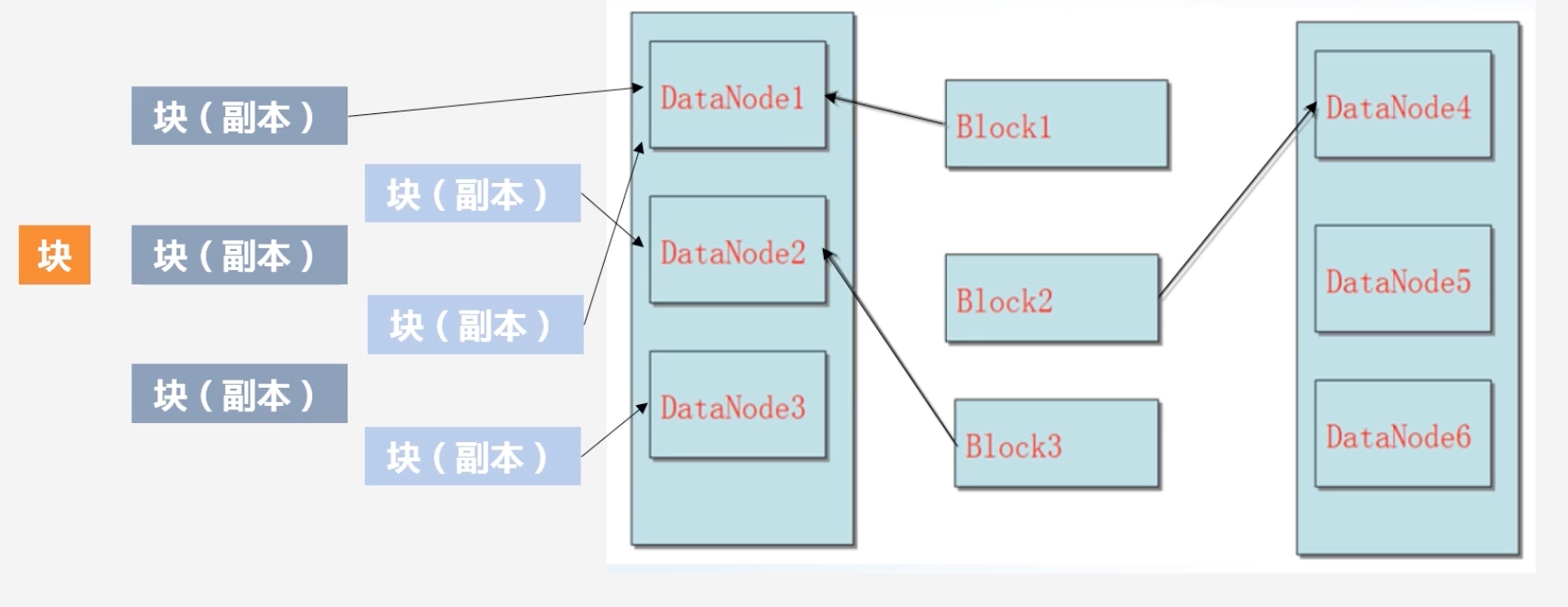
冗余数据保存问题
-
HDFS建立在廉价机器上,其缺点是会不停出故障,因此以块为单位,会将数据进行冗余保存,一般情况下一份数据会被保存为3份
-
有何好处?
-
加快数据传输速度:因为假设3个客户端ABC,需要访问同一个数据块,在冗余数据存储可以使三个客户端并行进行访问

-
很容易检查数据错误:可以通过三个副本之间对照来检查数据是否有误
-
保证数据可靠性:即使有机器down了,仍然能保有其他机器是可用的
-
-
-
数据保存策略问题
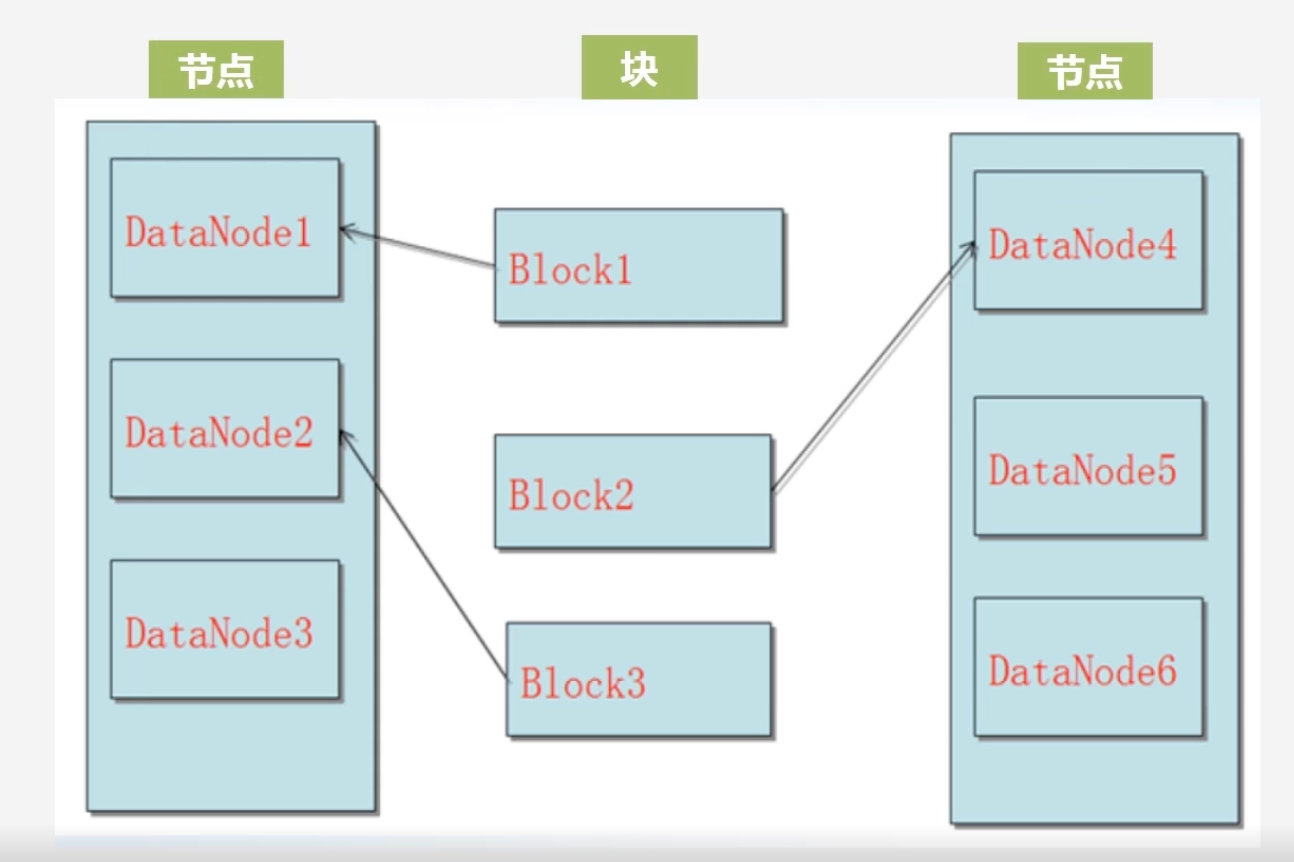
-
假设此时有一个块存入
-
首先创建三个副本,假设块是由数据节点1发起的,这个副本称为第一副本,其则直接将其放在数据节点1上,不需要通过网络复制到其他节点上
-
若是集群外部的某个节点发起了写数据请求,HDFS会随机挑选一个磁盘不太满,cpu不太忙的节点作为第一副本。
-
第二副本会放置在和第一个副本不同的机架上
-
第三副本放置在第一个副本相同机架的其他节点上
-
若还有其他副本,则通过随机算法,放置在任意节点上
-
-
数据读取问题:

-
-
数据恢复的问题
-
名称节点出错?
-
HDFS1.0:会将整个HDFS暂停一段时间,即从secondNameNode中进行冷备份恢复一段时间,再进行对外服务
-
HDFS2.0:不需要暂停,直接热备份

-
-
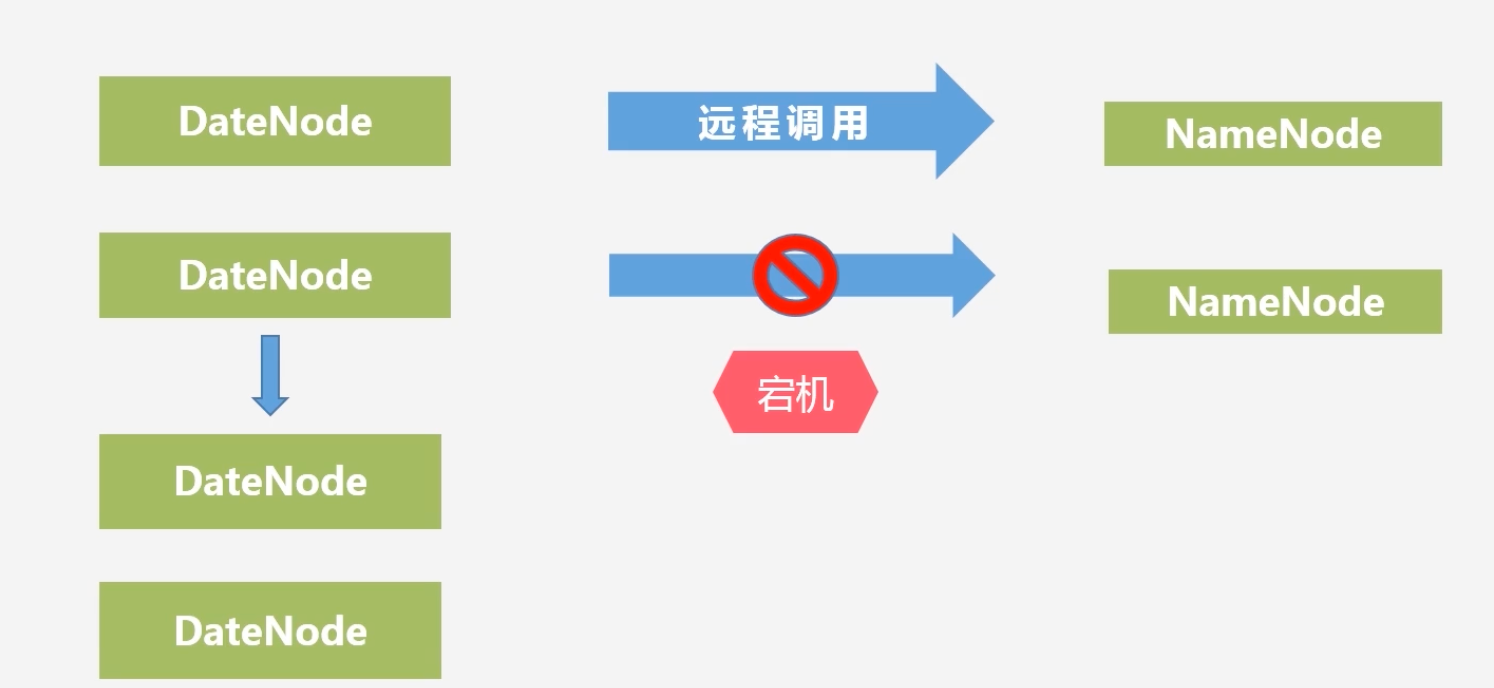
数据节点出错?
-
数据节点会隔一段时间向名称节点发送心跳信息,说明其还活着,若是名称节点收不到该数据节点的心跳信息,说明该数据节点发生故障
-
名称节点会在该数据节点列表上将其标记为宕机,即不可用,把存储在这个节点上的数据重新分发到其他的机器上去
-
当负载不均衡的时候,某个节点的负载过重,也会将这个节点的数据迁移到其他节点
-
-
数据本身出错?
-
客户端读取数据会对它进行校验码校验,如果发现校验码不正确,说明数据出错
-
这个校验码是在客户端写入数据时,为数据块生成校验码,保存在同一个文件目录中去,下次读数据块时,会对读到的数据进行校验码计算,
将计算的校验码和原来得到的校验码进行对比,不一致说明发生错误

-
-
3.5 HDFS数据读写
3.5.1 HDFS的读数据过程
-
HDFS的FileSystem的基类,会有很有子类继承它而实现不同的功能
-
FileSystem基本方法:open read close 。open创建输入流封装了DFSInputStream, 是专门针对 HDFS的实现;create方法创建了FSoutputstream,同样封装了DFSoutputstream
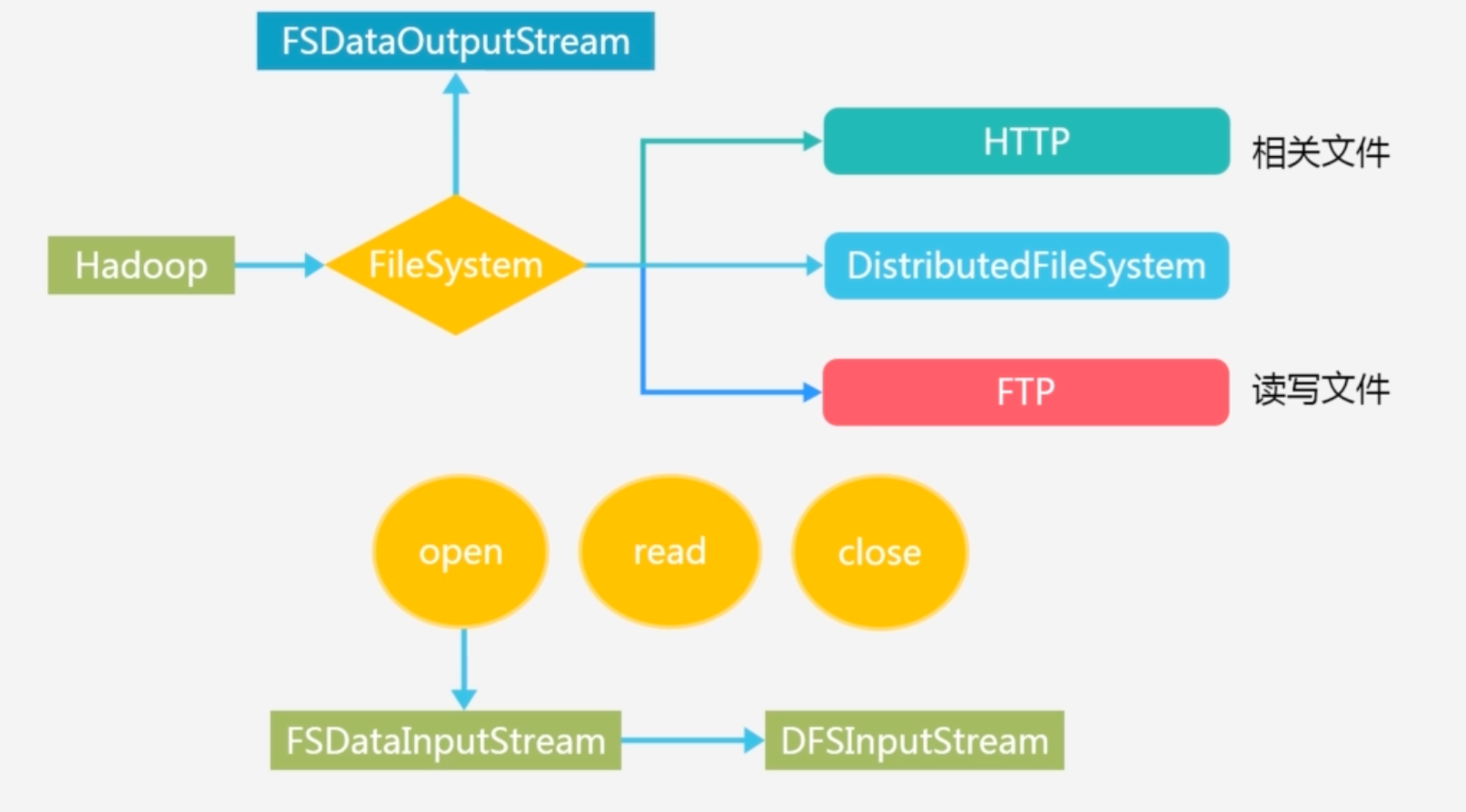
-
FileSystem.get(conf):获得工程目录下的两个配置文件 hdfs-site.xml 和core-site.xml

-
HDFS读数据的整个流程
-
1.打开文件:用FileSystem声明文件对象,生成DistributedFileSystem的实例对象;创建输入流:FSDataInputStream,获取数据块信息,与名称节点通过远程过程调用进行沟通
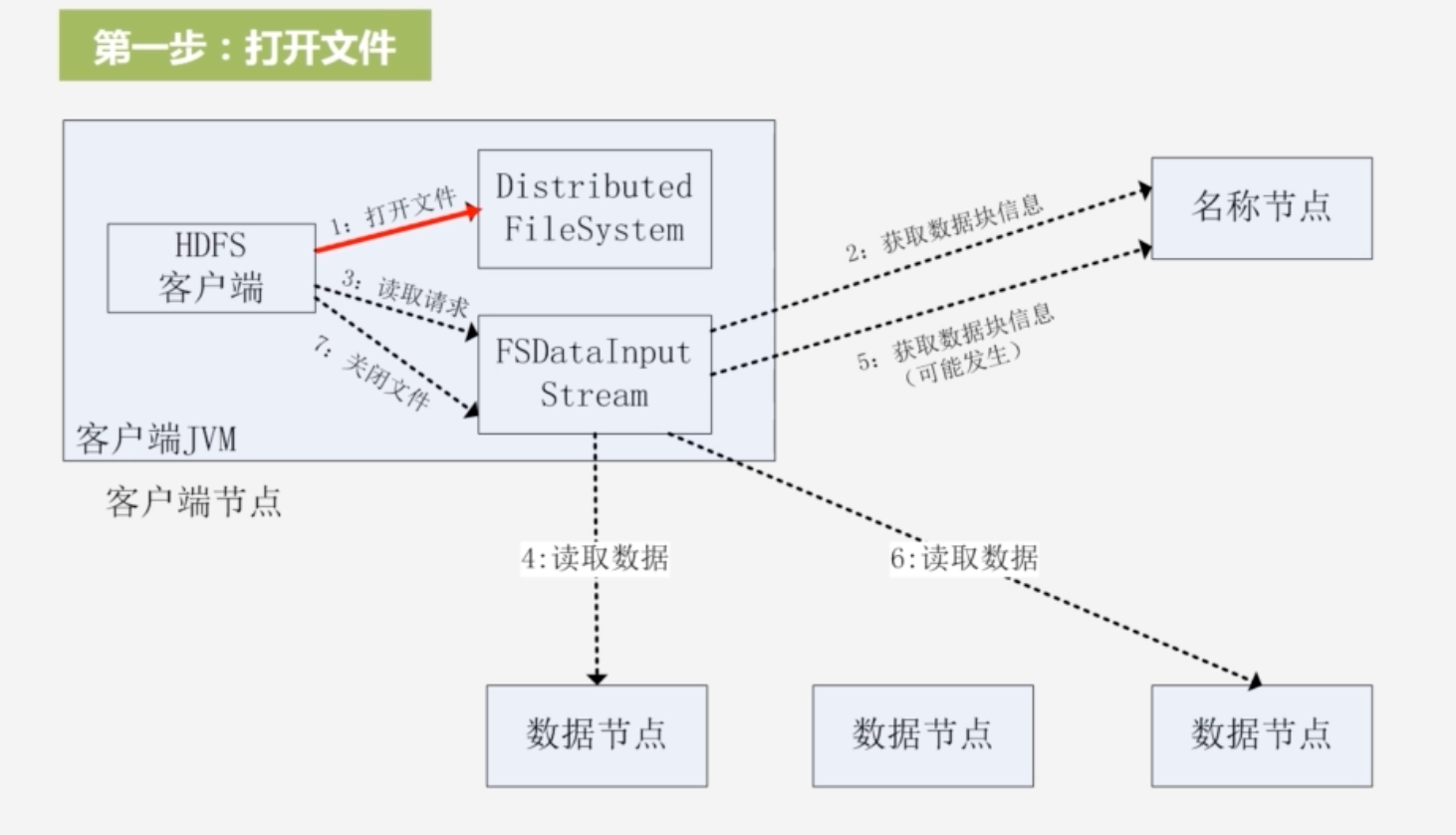
-
2.获取数据块信息:获取读取的数据块被保存在的数据节点位置信息,名称节点会把包含这个文件开始部分(文件可能包含很多块)的数据块位置信息返回
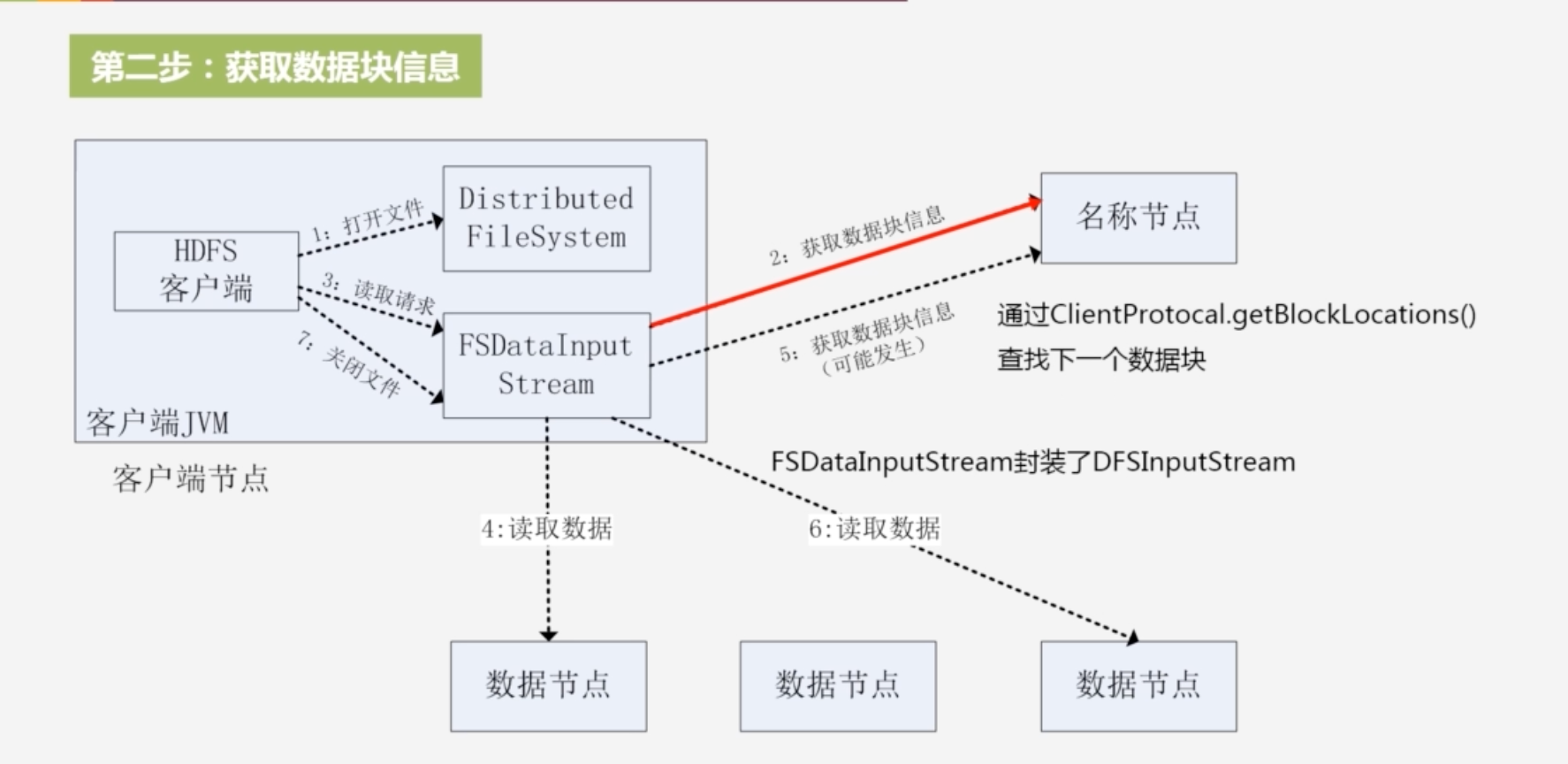
-
3.客户端获得输入流,可以调用read函数读取数据,会根据数据节点距离客户端的远近进行排序,客户端拿到排序后的数据节点位置列表,选择距离客户端最近的数据节点建立连接,读数据
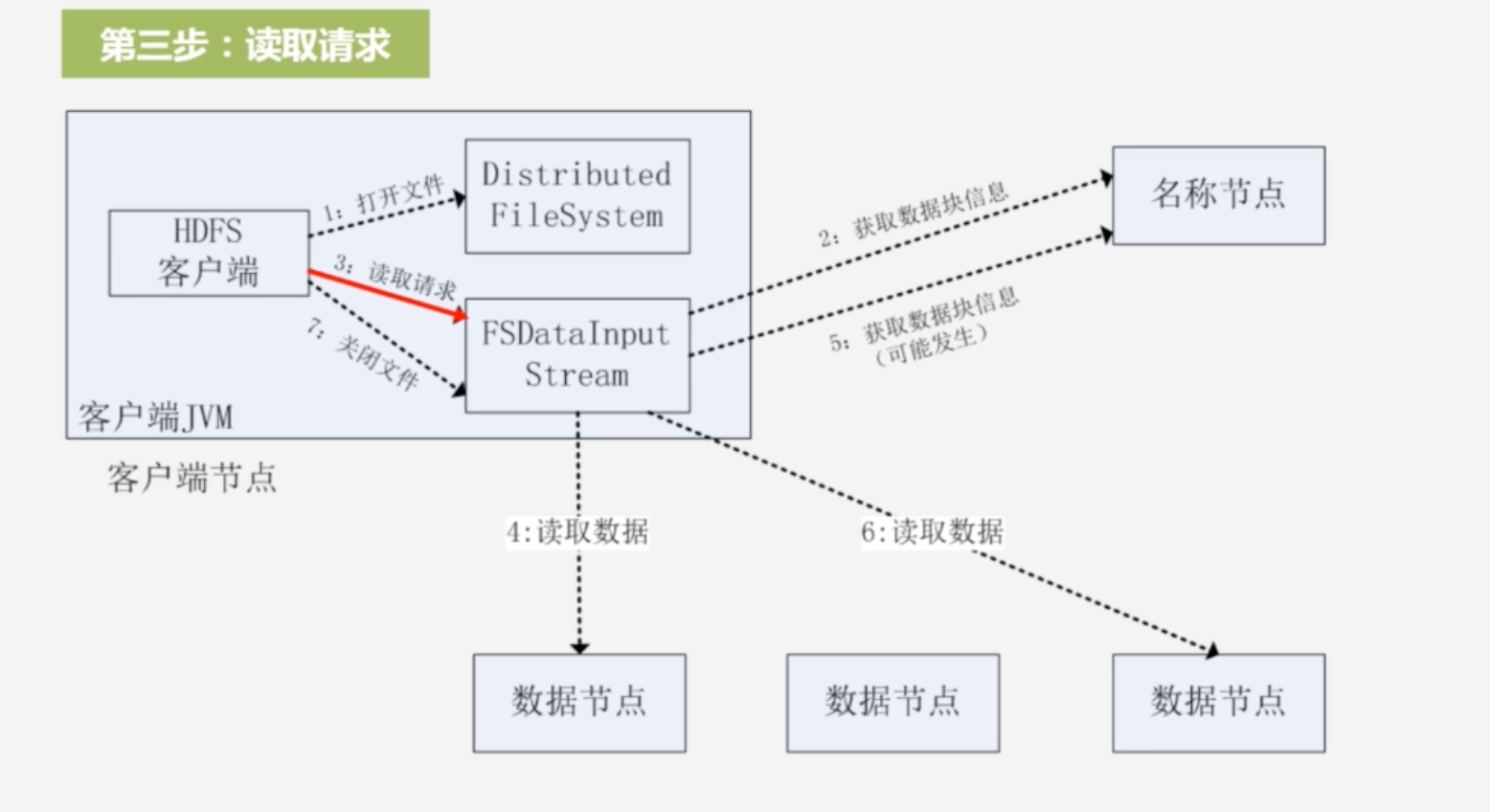
-
- 将数据从数据节点读取到客户端
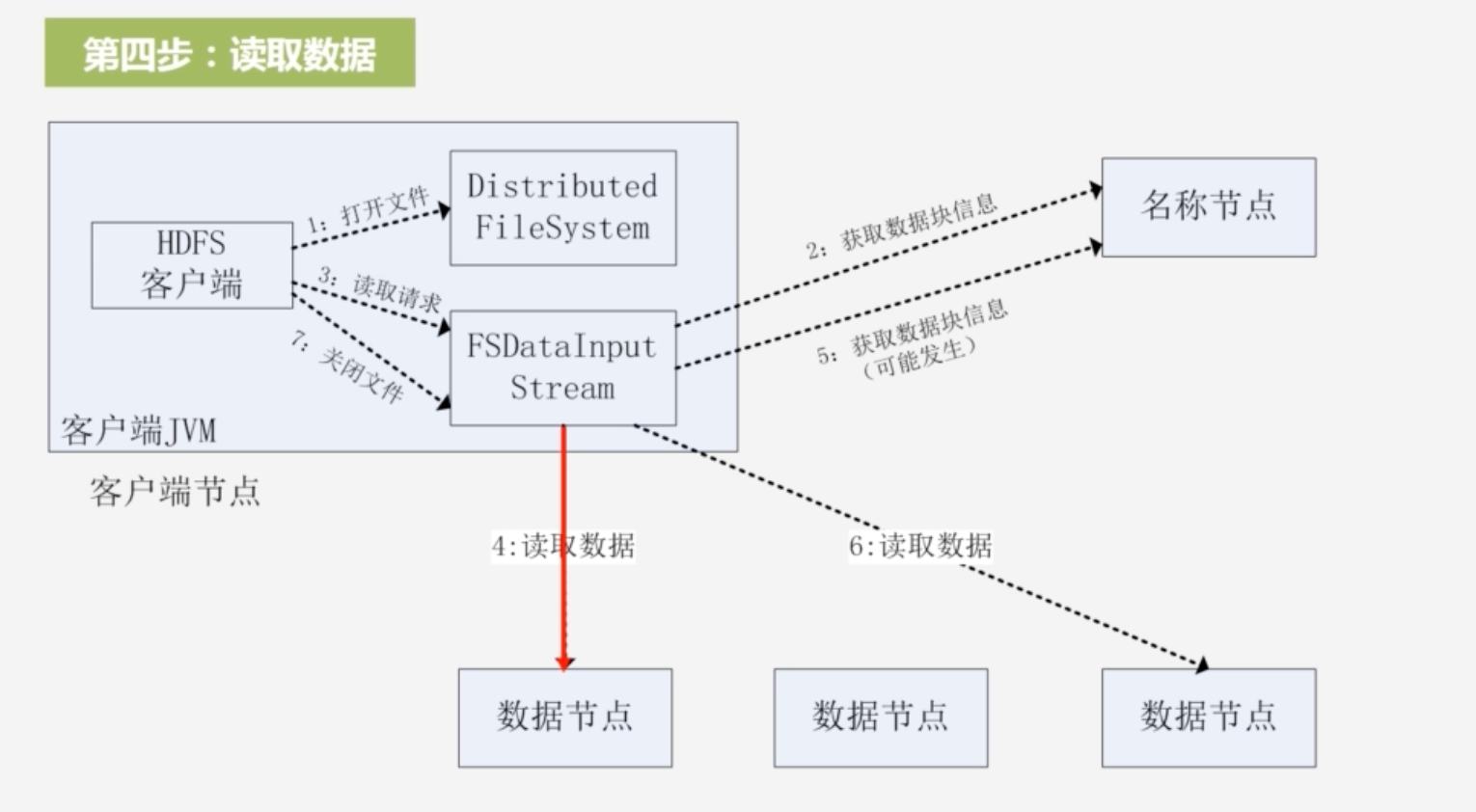
-
5.因为文件可能分为多个块,需要读取这个文件其他块的信息,通过ClientProtocal.getBlockLocations()查找下一数据块的位置
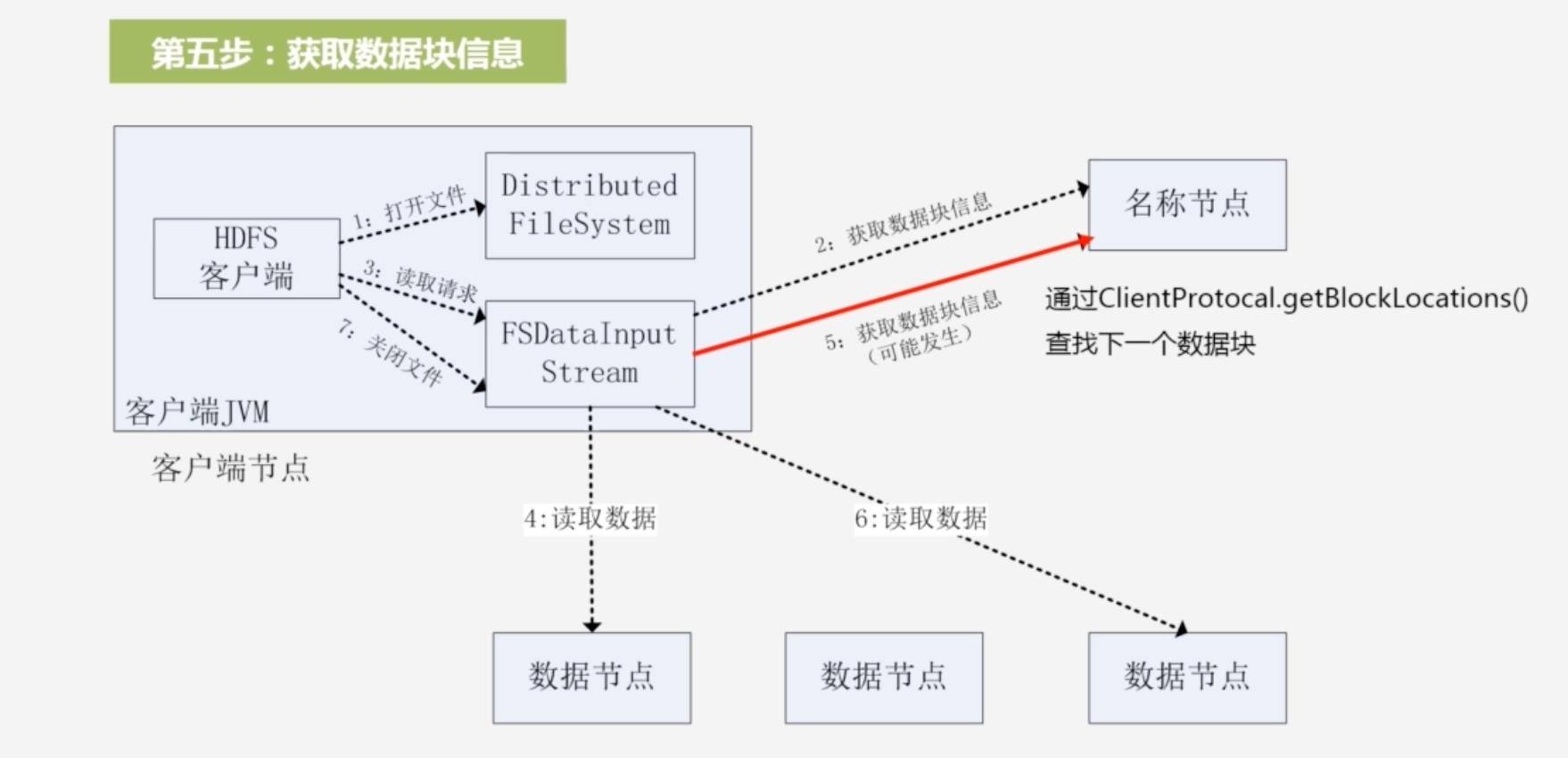
-
6.然后又读取该块节点的数据,又关闭输入流;一直循环直到完成这个文件所有块的读取
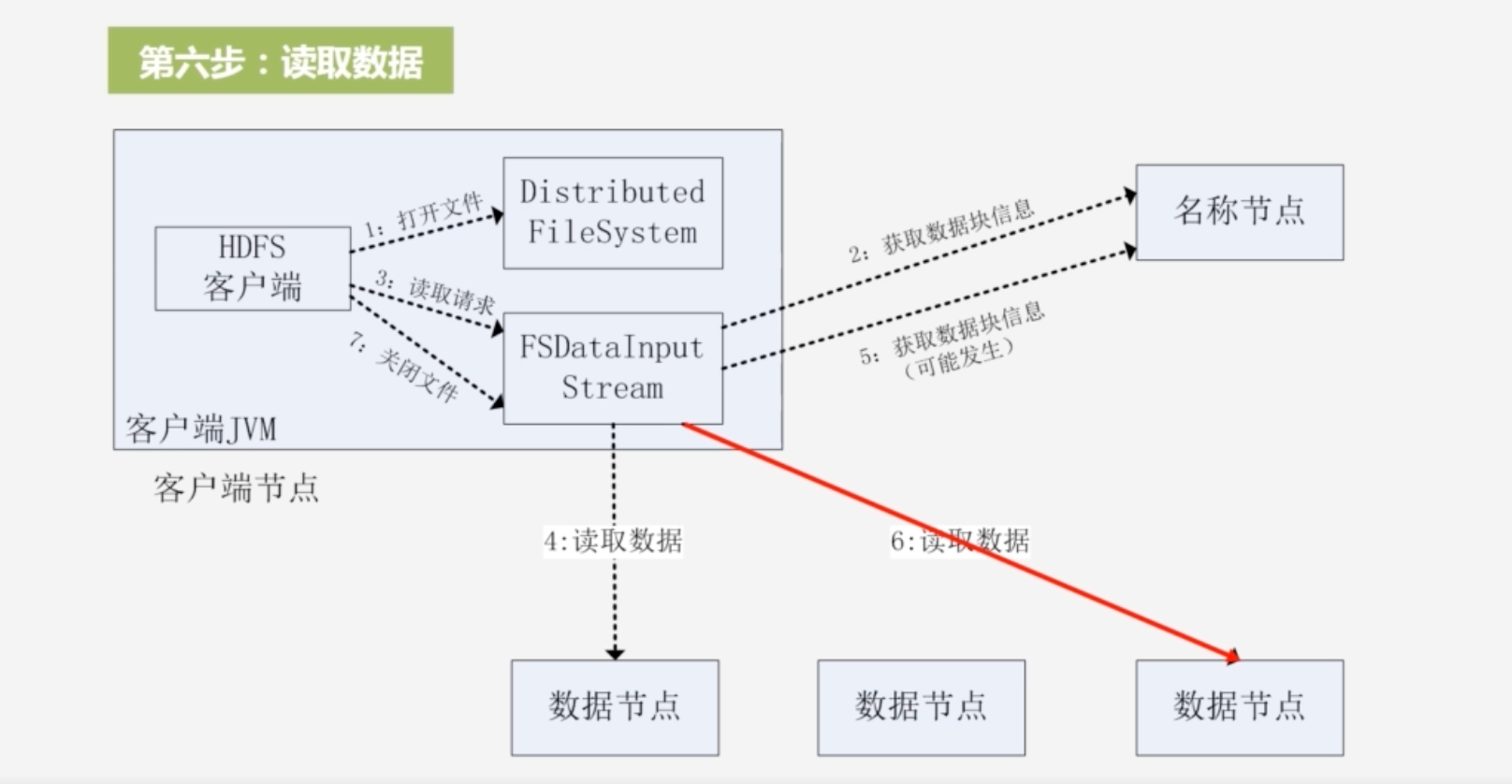
-
7.最后关闭文件
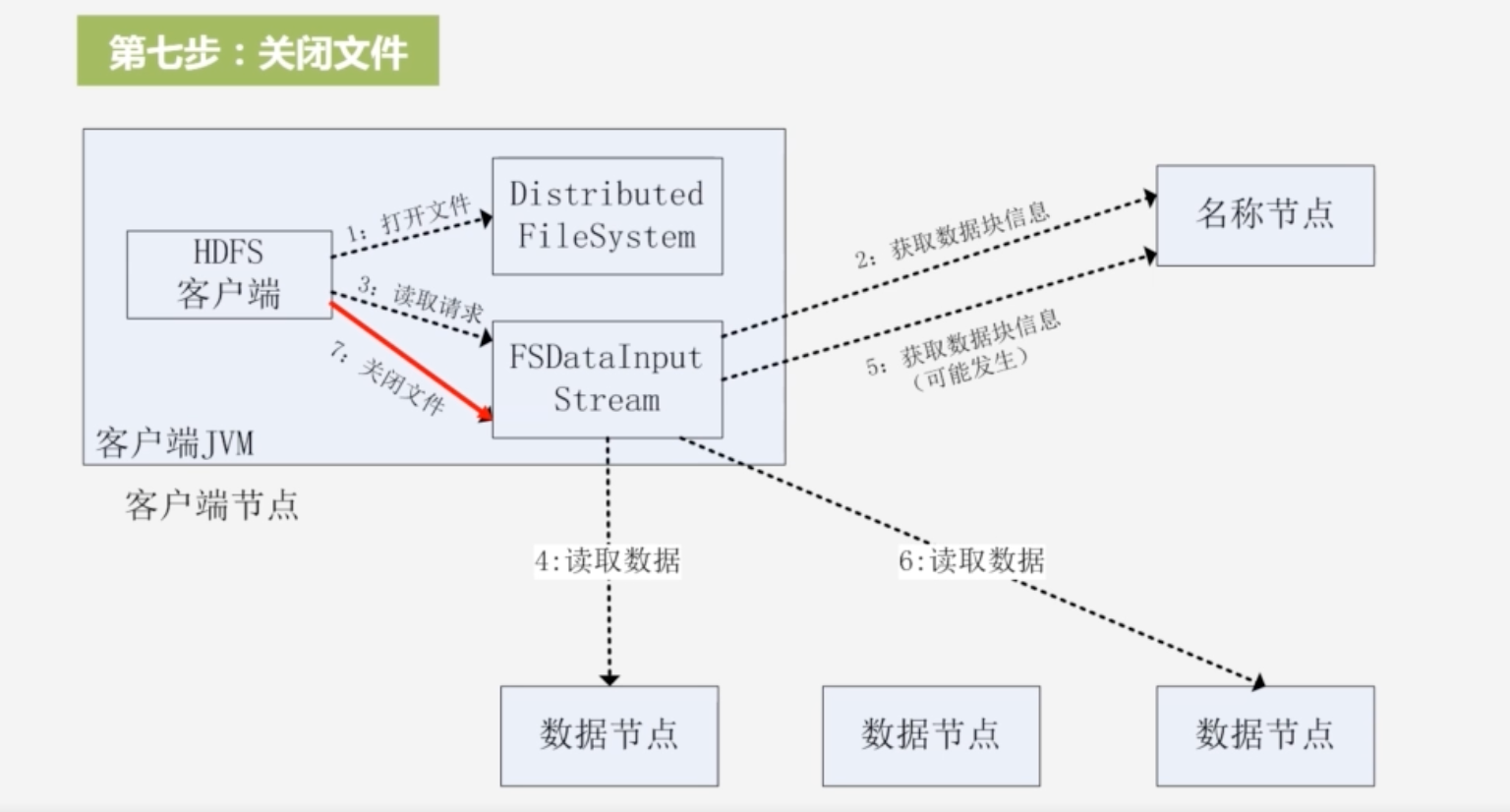
-
3.5.2 HDFS的写数据过程
-
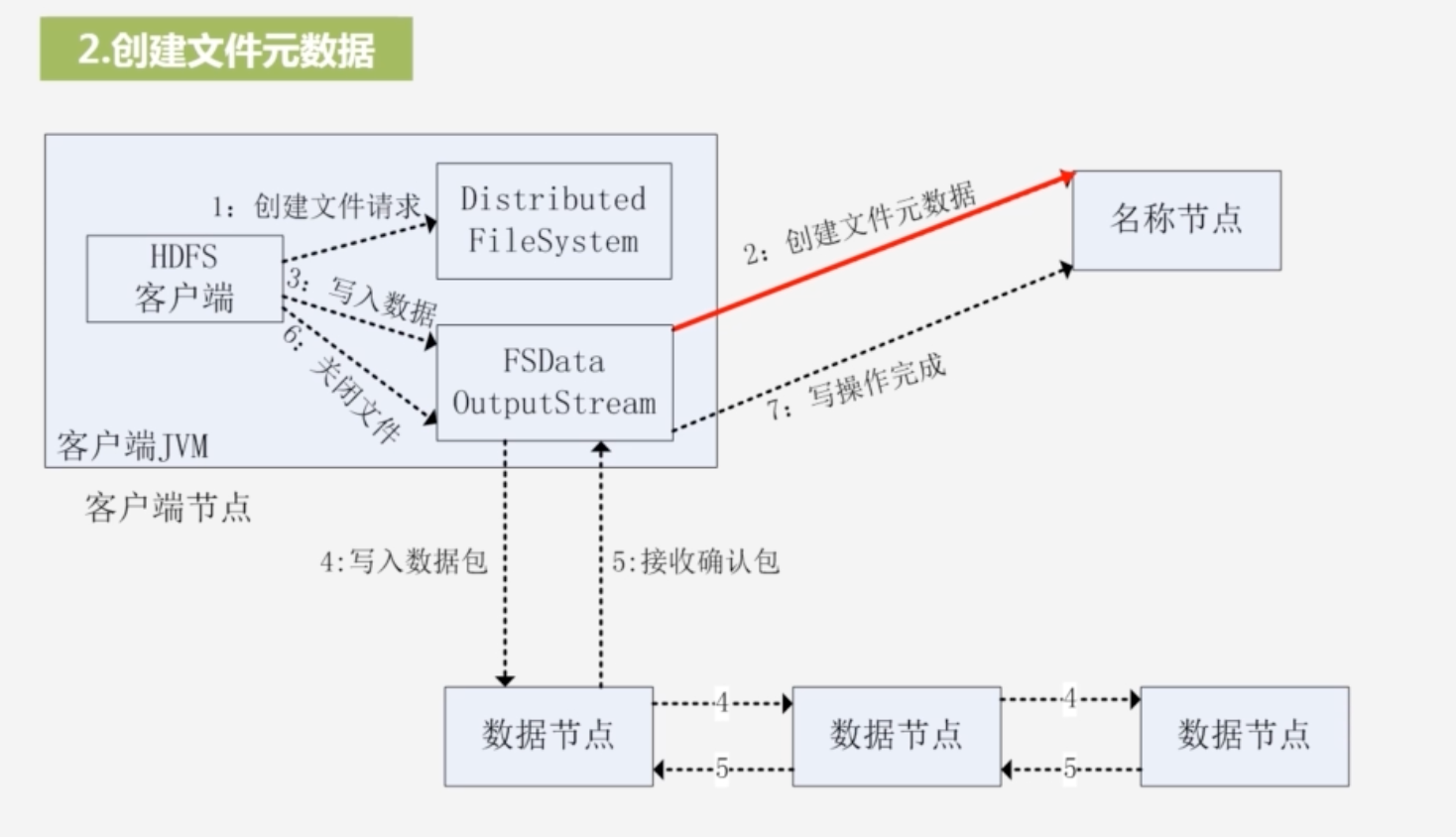
1.创建文件请求,实例化Distributed FileSystem;创建FSDataOutputStream,其内部封装DFSOutputStream,与名称节点打交道
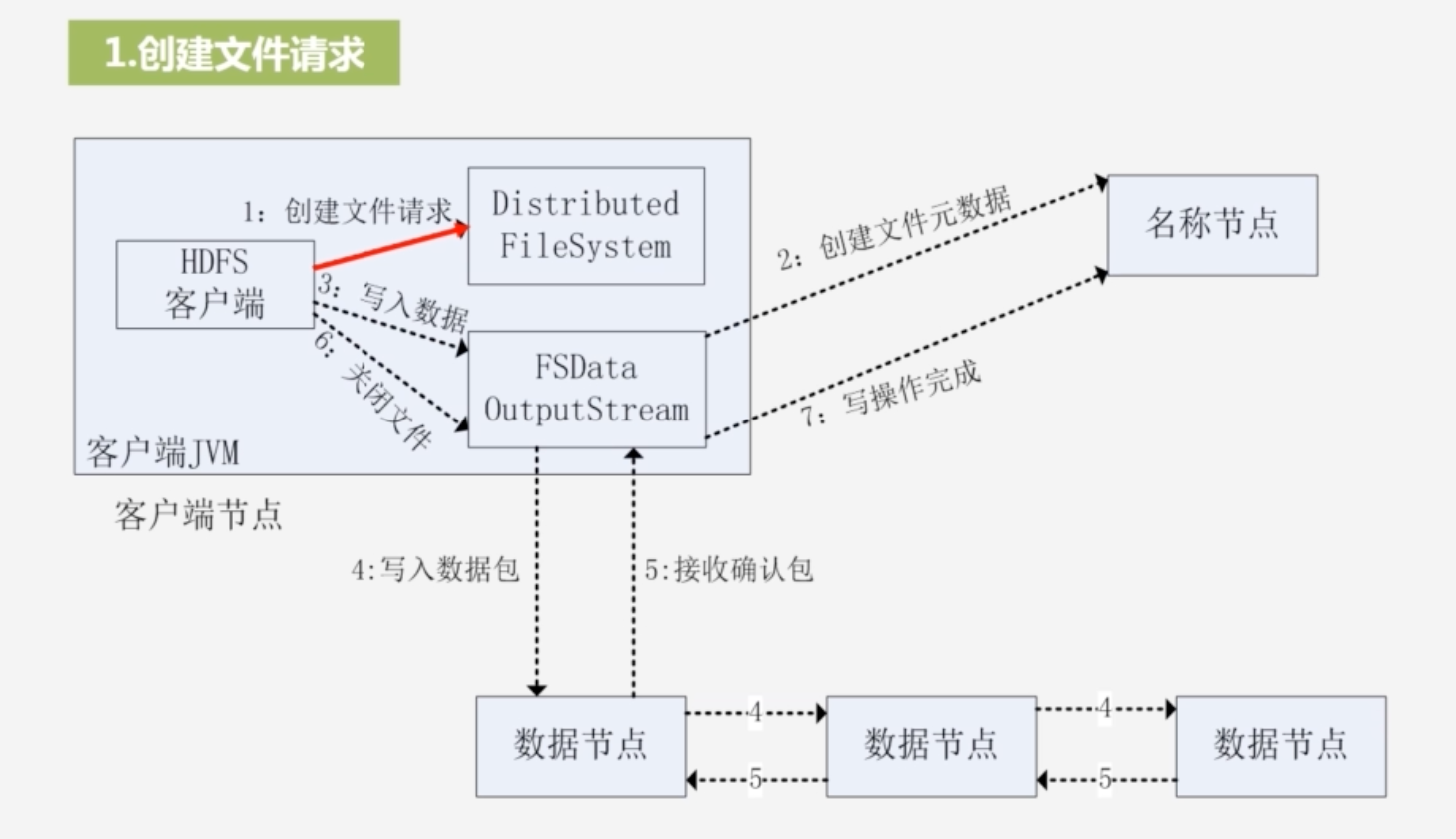
-
-
输出流通过远程过程调用rpc,让名称节点在文件系统命名空间中新建一个文件,名称节点会检查文件是否存在,以及客户端是否有权限创建这个文件,若是通过,则该名称节点会创建这个文件
-
-
3.写入数据
将整个数据分包:并将其放入DFSOutputStream的内部队列中去,DFSOutputStream向名称节点申请保存这个数据包的数据节点

-
-
写入数据包
流水线复制:将数据包复制到第一个节点,再由第一个节点复制到第二个节点,形成流水线复制

-
-
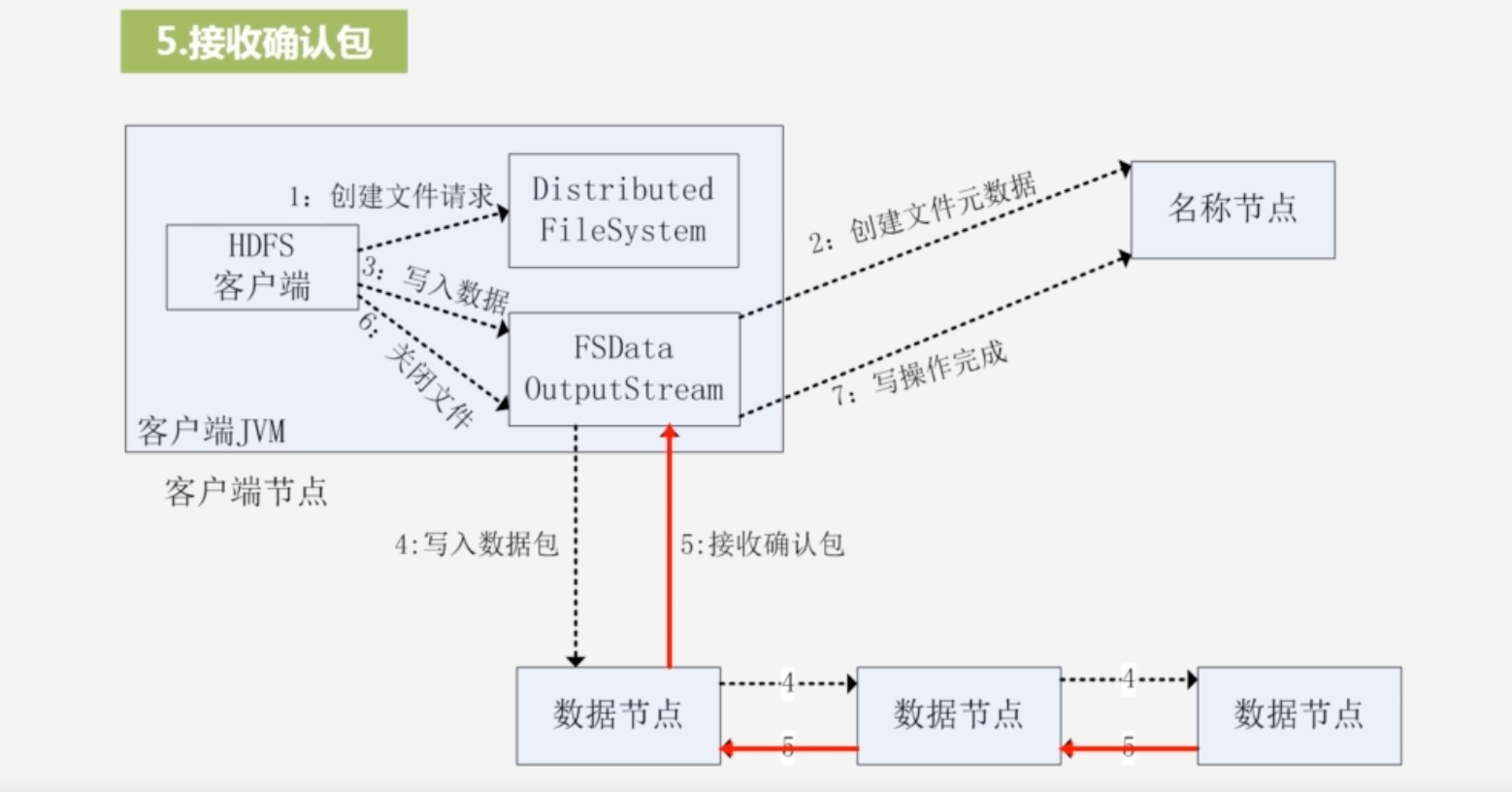
5.接受确认包
- 确认包由最后一个数据节点传到前一个数据节点,一直往前传,客户端收到确认信息,说明全都写完
-
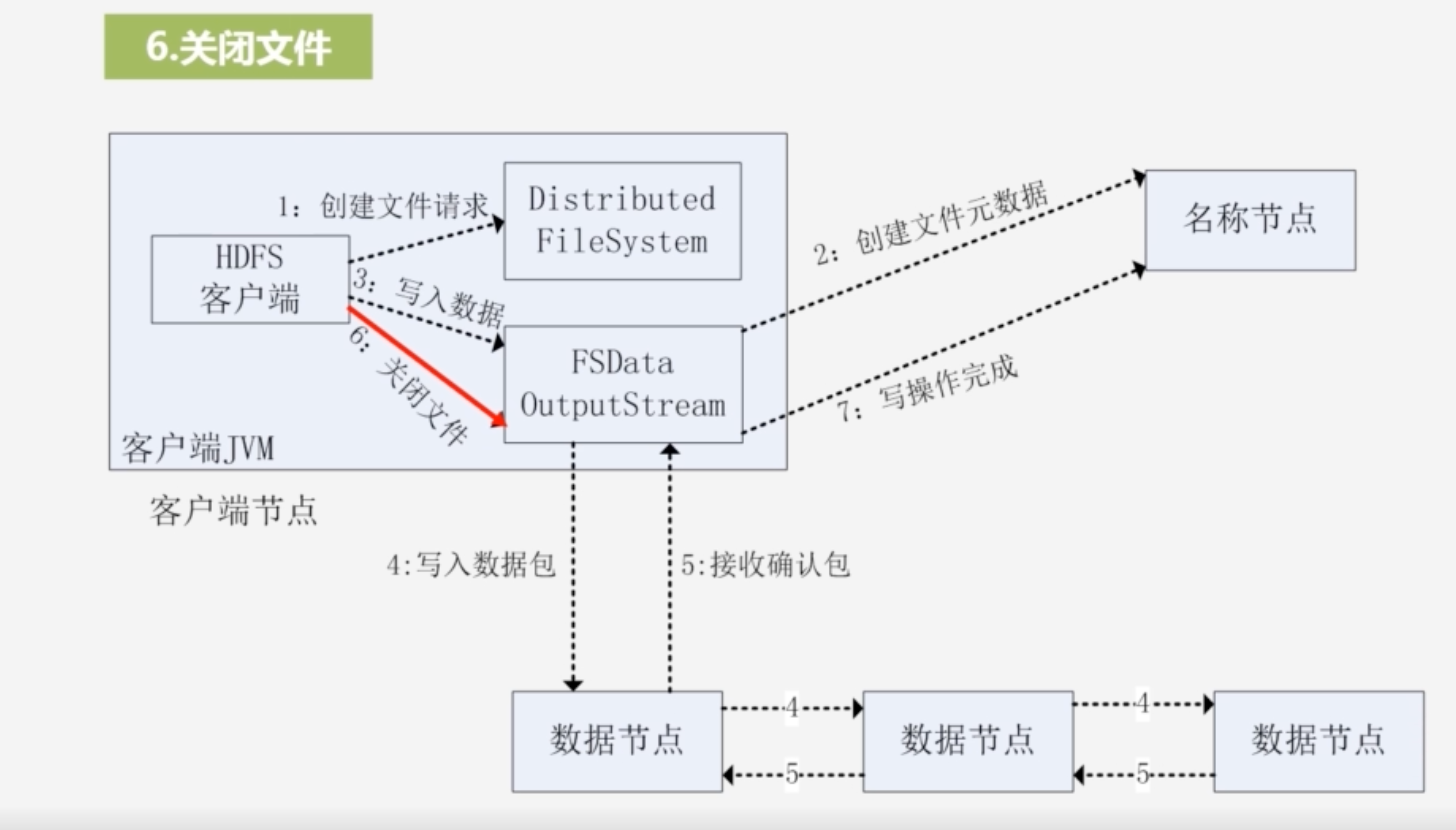
6.最后关闭文件
3.6 HDFS编程实战
见:HDFS编程实践(Hadoop3.3.5)_厦大数据库实验室博客 (xmu.edu.cn)