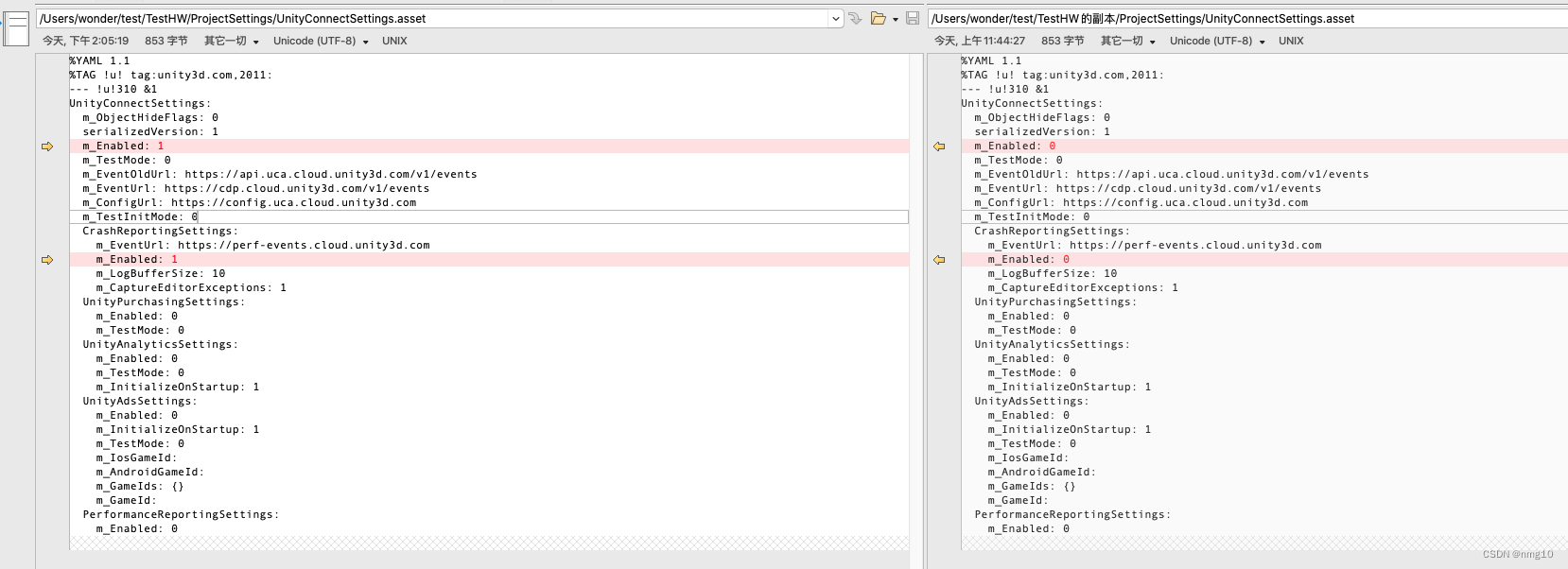
方法
结果
在这一部分,我们展示对于每个模型比较的聚合的统计分析当涉及到计算特征和独立的特征组(表格1),抽取功能组和对齐重要功能组(表格2),并且最后,我们提供从模型比较(LANGUAGE模型v.s.MAIN IDEA模型)中获取的样例。由于长度限制,我们只展示了这个比较的细节样例。相似的图片和相关性分析展示在Github上。
1.独立特征组
- 因为每个训练好的模型都从他们的训练集合中留出一个不同集合的主题,分析集中相同的主题需要被识别出来,并且那么,抽取的特征的数量和导致的独立特征组在每个模型比较中不同。
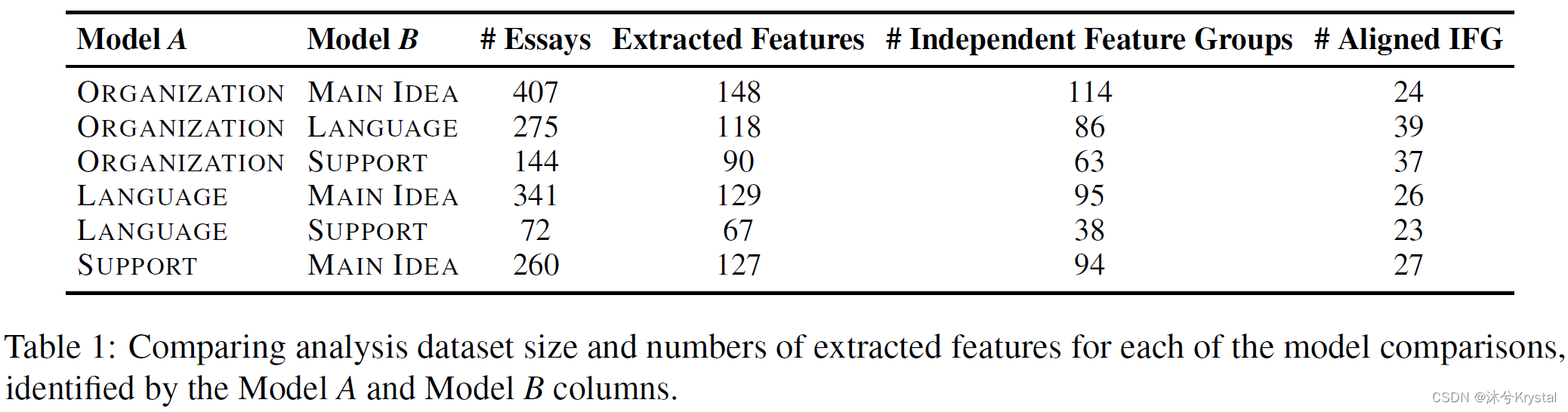
- 为每个模型比较计算独立的特征组(表格1),对所有的比较,都产生了在原先70%和77%之间的抽取的特征,除了LANGUAGE V SUPPORT,和原先的特征相比只产生了57%独立特征组;不同比较之间所对齐的特征组类型差异很大。
2.功能组件组
-
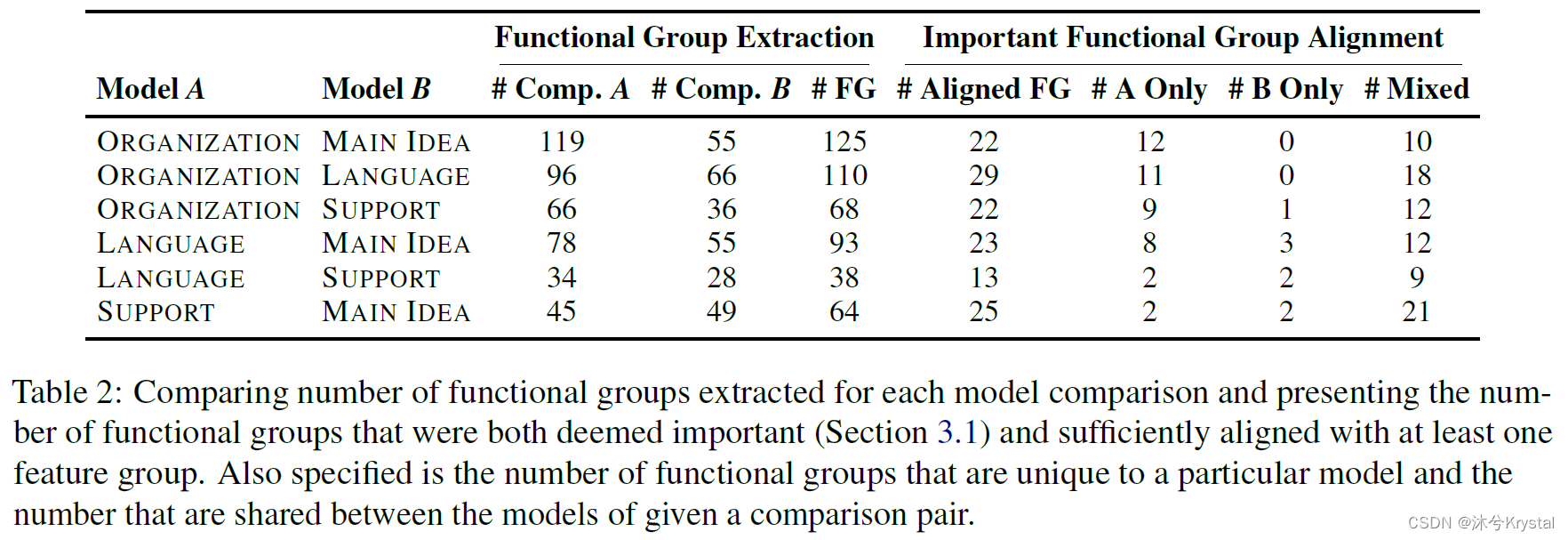
每个模型的初始功能组件提取引发了28到119个功能组件的数量。表格1和2展示了对于一个给定的模型,更少的功能组件被抽取,如果在分析数据集中有更少的样例。
-
除去这一噪声,一个清晰的模型出现,也就是ORGANIZATION模型有最多的功能组件,其次是LANGUAGE模型。MAIN IDEA模型有着更少的功能组件,SUPPORT模型的最少。
-
当执行降维操作来计算功能组的时候,功能组件的总数减少到了大约61-71%左右。
3.重要功能组
- 重要功能组有至少一个足够的对一个特征组的对齐。
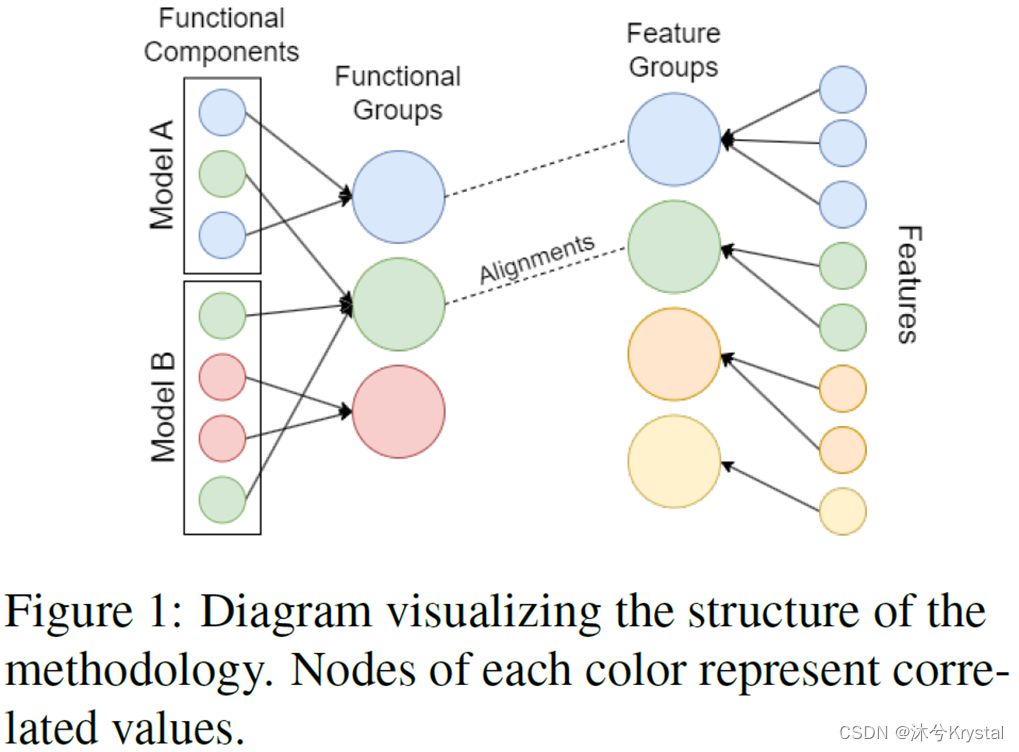
- 作为重要功能组的一个视觉辅助,可以看图2和3的左侧。

4.功能组的对齐
- 对于所有的模型比较的对齐的发现的整个部分可能太大量而不能以一个会议论文的形式进行展示。但是我们可以展示在我们的分析中发现的主要的趋势。
- 第一个主要的趋势是所有模型都具有与文章的统计特征相关的功能组。此外,通过计算该类型内部特征之间的相关性,可以确定段落数量可能是最显著的贡献因素。
- 第二个趋势的集合被展示在表4中,在表中,每个模型的总共的对齐的特征组的占比被计算。
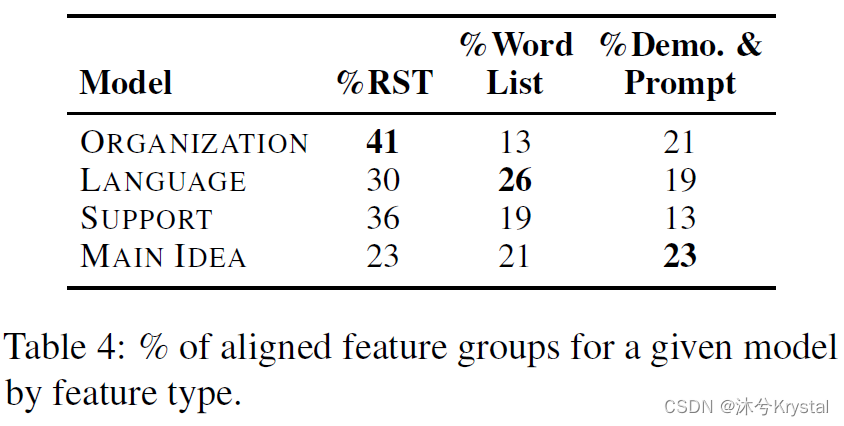
- 这一结果揭示了:ORGANIZATION模型,比较其他模型,相对更加对齐基于RST的特征;同时,MAIN IDEA模型有最小的占比。LANGUAGE模型最对齐词列表特征,它是算法生成的和人工创建的词列表特征的结合。
- 对于最后一个百分比,我们结合了主题和人口统计的特征,发现SUPPORT模型趋向于最少对齐这类特征。
5.定性分析
- 尽管我们展示的方法能够很快得增强一个人对于一个模型的理解,直接从黑箱神经网络到对齐的特征组,理解什么函数/功能一个儿子组表示是更加困难的。所以,解决一个特征组表示什么函数/功能,来形成一个强的陈述解释模型在做什么是必要的。
- 比如说,我们发现很多模型和包含人口统计特征的特征组是连接的(在图2和3中被标红)。然而,对包含主题的数据集进行定性分析时,我们发现,在控制作文长度时,不同学校的主题分布存在差异,某些学校(带有其人口统计特征)是特定主题的唯一来源。因此,许多这些特征组很可能更多地基于主题,而不是潜在的更为问题复杂的基于人口统计的特征组。
6.讨论
- 我们进一个深入分析结果,强调在功能组和他们与作文特征的相关性的对齐中的主要趋势。
- 值得注意的是,LANGUAGE V SUPPORT对比出现作为一个异常点在我们的各个分析中。这个差异很有可能是因为相对而言更少的文章被两个模型的分析集所共享,这可能导致一个具有更多噪声的分析,并且暴露了方法的一个局限性。
- 在非ORGANIZATION模型中,几乎没有或根本没有独特存在于ORGANIZATION模型中的功能组。