今天我学习了DeepLearning.AI的 Building Systems with LLM 的在线课程,我想和大家一起分享一下该门课程的一些主要内容。之前我们已经学习了下面这些知识:
- 使用大型语言模(LLM)构建系统(一):分类
- 使用大型语言模(LLM)构建系统(二):内容审核、预防Prompt注入
- 使用大型语言模(LLM)构建系统(三):思维链推理
- 使用大型语言模(LLM)构建系统(四):链式提示
- 使用大型语言模(LLM)构建系统(五):输出结果检查
- 使用大型语言模(LLM)构建系统(六):构建端到端系统
在之前的博客,我们已经完成了大型语言模(LLM)构建端到端系统,在系统开发完成后,我们需要对系统功能进行评估,所谓评估是指我们需要设计一下测试用例来对系统功能进行测试,并观察测试结果是否符合要求。这里我们要测试的系统是在上一篇博客中开发的端到端系统。 下面是我们访问LLM模型的主要代码,这里我加入了backoff包,它的功能主要是为了防止API调用时出现Rate limit错误,报错的原因我在之前的博客中已经说明,这里不在赘述。:
import openai
import backoff #您的openai的api key
openai.api_key ='YOUR-OPENAI-API-KEY' @backoff.on_exception(backoff.expo, openai.error.RateLimitError)
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0, max_tokens=500):response = openai.ChatCompletion.create(model=model,messages=messages,temperature=temperature, max_tokens=max_tokens,)return response.choices[0].message["content"]获取相关的产品和类别
在上一篇博客中我们开了一个端到端的系统,该系统的主要功能开发一个个性化的客服机器人来回答用户对相关电子产品的问题,当用户提出问题时,系统首先需要识别用户问题中提到的电子产品是否包含在系统中的电子产品目前清单中,下面的代码是查看目前系统中所有的电子产品目前清单:
products_and_category = utils.get_products_and_category()
products_and_category
下面我们看一下产品目前清单中的所有类别,目前在产品目前清单中一个有6个类别:
#所有类别
list(products_and_category.keys())
这里看到我们的电子产品包含了6个大类,在每个大类下面都有若干个具体的电子产品,我们会用一个python字典来存储产品目录清单,其中key对应的是类别,value对应的是具体的产品。
查找相关的产品和类别名称(版本1)
下面我们要定义一个查找相关产品和分类的名称的函数,该函数接收客户的问题,并返回和问题相关的产品和分类的目录清单:
def find_category_and_product_v1(user_input,products_and_category):delimiter = "####"system_message = f"""You will be provided with customer service queries. \The customer service query will be delimited with {delimiter} characters.Output a python list of json objects, where each object has the following format:'category': <one of Computers and Laptops, Smartphones and Accessories, Televisions and Home Theater Systems, \Gaming Consoles and Accessories, Audio Equipment, Cameras and Camcorders>,AND'products': <a list of products that must be found in the allowed products below>Where the categories and products must be found in the customer service query.If a product is mentioned, it must be associated with the correct category in the allowed products list below.If no products or categories are found, output an empty list.List out all products that are relevant to the customer service query based on how closely it relatesto the product name and product category.Do not assume, from the name of the product, any features or attributes such as relative quality or price.The allowed products are provided in JSON format.The keys of each item represent the category.The values of each item is a list of products that are within that category.Allowed products: {products_and_category}"""few_shot_user_1 = """I want the most expensive computer."""few_shot_assistant_1 = """ [{'category': 'Computers and Laptops', \
'products': ['TechPro Ultrabook', 'BlueWave Gaming Laptop', 'PowerLite Convertible', 'TechPro Desktop', 'BlueWave Chromebook']}]"""messages = [ {'role':'system', 'content': system_message}, {'role':'user', 'content': f"{delimiter}{few_shot_user_1}{delimiter}"}, {'role':'assistant', 'content': few_shot_assistant_1 },{'role':'user', 'content': f"{delimiter}{user_input}{delimiter}"}, ] return get_completion_from_messages(messages)这里我们将system_message翻译成中文,这样便于大家理解:
System_message = f"""
您将获得客户服务查询。
客户服务查询将用{delimiter}字符分隔。
输出json对象的python列表,其中每个对象具有以下格式:
“category”:<电脑和笔记本电脑,智能手机和配件,电视和家庭影院系统之一,
游戏机及配件、音响设备、照相机及摄像机>、
和
'products': <必须在下面允许的产品中找到的产品列表>其中类别和产品必须在客户服务查询中找到。
如果提到某个产品,它必须与下面允许的产品列表中的正确类别相关联。
如果没有找到任何产品或类别,则输出一个空列表。列出与客户服务查询相关的所有产品
到产品名称和产品类别。
不要从产品的名称中假设任何特征或属性,例如相对质量或价格。允许的产品以JSON格式提供。
每个项目的键代表类别。
每个项目的值是属于该类别的产品列表。
允许的产品:{products_and_category}
"""在这里我们除了提供system_message以外,我们还提供了一对自问自答的少量学习样本few_shot_user_1和few_shot_assistant_1 ,这样做的目的是训练LLM让它知道如何正确的按指定格式来输出查询结果。
评估 find_category_and_product_v1
定义好了find_category_and_product_v1方法,下面我们设计几个用户的问题来评估一下find_category_and_product_v1的实际效果。
customer_msg_0 = f"""Which TV can I buy if I'm on a budget?"""products_by_category_0 = find_category_and_product_v1(customer_msg_0,products_and_category)
print(products_by_category_0)
customer_msg_1 = f"""I need a charger for my smartphone"""products_by_category_1 = find_category_and_product_v1(customer_msg_1,products_and_category)
products_by_category_1
customer_msg_2 = f"""What computers do you have?"""
products_by_category_2 = find_category_and_product_v1(customer_msg_2,products_and_category)
products_by_category_2
customer_msg_3 = f"""
tell me about the smartx pro phone and the fotosnap camera, the dslr one.
Also, what TVs do you have?"""products_by_category_3 = find_category_and_product_v1(customer_msg_3,products_and_category)
print(products_by_category_3)
这里的4个用户问题,LLM都按指定的格式输出了查询结果,注意,这里的查询结果都是以字符串的形式输出。
更复杂的测试用例
下面我们需要设计更为复杂一点的测试用例看看find_category_and_product_v1还能否按要求来输出结果。
customer_msg_4 = f"""
tell me about the CineView TV, the 8K one, Gamesphere console, the X one.
I'm on a budget, what computers do you have?"""products_by_category_4 = find_category_and_product_v1(customer_msg_4,products_and_category)
print(products_by_category_4) 
从上面的输出结果可以看到当客户的问题稍微复杂一点的时候,LLM输出的结果中除了我们要求的指定格式的信息以外,还有一部分文本信息,但是这部分文本信息是我们不需要的,因为我们的系统需要需要把输出结果转换成指定的python的List格式,如果输出结果中混有文本信息就无法进行格式转换。
修改prompt(提示语)以处理更复杂的测试用例(版本2)
下面我们需要修改system_message,以便让它可以处理类似之前那种复杂的用户问题。主要的目的是防止LLM输出不必要的文本信息。
def find_category_and_product_v2(user_input,products_and_category):"""Added: Do not output any additional text that is not in JSON format.Added a second example (for few-shot prompting) where user asks for the cheapest computer. In both few-shot examples, the shown response is the full list of products in JSON only."""delimiter = "####"system_message = f"""You will be provided with customer service queries. \The customer service query will be delimited with {delimiter} characters.Output a python list of json objects, where each object has the following format:'category': <one of Computers and Laptops, Smartphones and Accessories, Televisions and Home Theater Systems, \Gaming Consoles and Accessories, Audio Equipment, Cameras and Camcorders>,AND'products': <a list of products that must be found in the allowed products below>Do not output any additional text that is not in JSON format.Do not write any explanatory text after outputting the requested JSON.Where the categories and products must be found in the customer service query.If a product is mentioned, it must be associated with the correct category in the allowed products list below.If no products or categories are found, output an empty list.List out all products that are relevant to the customer service query based on how closely it relatesto the product name and product category.Do not assume, from the name of the product, any features or attributes such as relative quality or price.The allowed products are provided in JSON format.The keys of each item represent the category.The values of each item is a list of products that are within that category.Allowed products: {products_and_category}"""few_shot_user_1 = """I want the most expensive computer. What do you recommend?"""few_shot_assistant_1 = """ [{'category': 'Computers and Laptops', \
'products': ['TechPro Ultrabook', 'BlueWave Gaming Laptop', 'PowerLite Convertible', 'TechPro Desktop', 'BlueWave Chromebook']}]"""few_shot_user_2 = """I want the most cheapest computer. What do you recommend?"""few_shot_assistant_2 = """ [{'category': 'Computers and Laptops', \
'products': ['TechPro Ultrabook', 'BlueWave Gaming Laptop', 'PowerLite Convertible', 'TechPro Desktop', 'BlueWave Chromebook']}]"""messages = [ {'role':'system', 'content': system_message}, {'role':'user', 'content': f"{delimiter}{few_shot_user_1}{delimiter}"}, {'role':'assistant', 'content': few_shot_assistant_1 },{'role':'user', 'content': f"{delimiter}{few_shot_user_2}{delimiter}"}, {'role':'assistant', 'content': few_shot_assistant_2 },{'role':'user', 'content': f"{delimiter}{user_input}{delimiter}"}, ] return get_completion_from_messages(messages)这里我们在system_message 中增加了两句提示语:

这两句话的意思是:不要输出任何非 JSON 格式的附加文本。输出请求的 JSON 后不要写任何解释性文字。
除此之外我们修改了原先的学习样本ew_shot_user_1 和few_shot_assistant_1 ,又增加了一对学习样本few_shot_user_2 和few_shot_assistant_2 。这样我们就有2对学习样本供LLM学习。
评估修改后的prompt对复杂问题的效果
customer_msg_4 = f"""
tell me about the CineView TV, the 8K one, Gamesphere console, the X one.
I'm on a budget, what computers do you have?"""products_by_category_4 = find_category_and_product_v2(customer_msg_4,products_and_category)
print(products_by_category_4)
从上面的结果上看,这次LLM按正确的格式输出了相关的产品和分类的内容,并且没有附带任何文本信息。因此说明我们修改后的prompt起了作业。
回归测试:验证模型在以前的测试用例上仍然有效
我们需要对之前的测试用例进行再次测试,以确保修改后的提示语对之前的测试用例仍然有效。这里我们抽取几个之前的测试用例进行测试。
customer_msg_0 = f"""Which TV can I buy if I'm on a budget?"""products_by_category_0 = find_category_and_product_v2(customer_msg_0,products_and_category)
print(products_by_category_0)
customer_msg_3 = f"""
tell me about the smartx pro phone and the fotosnap camera, the dslr one.
Also, what TVs do you have?"""products_by_category_3 = find_category_and_product_v2(customer_msg_3,products_and_category)
print(products_by_category_3)
这里我们测试2条之前的测试用例,从输出结果上看完全满足要求。
建立用于自动化测试的测试用例集
下面我们要建立一个用于自动化测试的测试用例集,每个测试用例包含了客户的问题(customer_msg)和理想答案(ideal_answer)两部分内容,我们的目的是评估LLM的回复是否和理想答案一致,并以此给LLM打分。
msg_ideal_pairs_set = [# eg 0{'customer_msg':"""Which TV can I buy if I'm on a budget?""",'ideal_answer':{'Televisions and Home Theater Systems':set(['CineView 4K TV', 'SoundMax Home Theater', 'CineView 8K TV', 'SoundMax Soundbar', 'CineView OLED TV'])}},# eg 1{'customer_msg':"""I need a charger for my smartphone""",'ideal_answer':{'Smartphones and Accessories':set(['MobiTech PowerCase', 'MobiTech Wireless Charger', 'SmartX EarBuds'])}},# eg 2{'customer_msg':f"""What computers do you have?""",'ideal_answer':{'Computers and Laptops':set(['TechPro Ultrabook', 'BlueWave Gaming Laptop', 'PowerLite Convertible', 'TechPro Desktop', 'BlueWave Chromebook'])}},# eg 3{'customer_msg':f"""tell me about the smartx pro phone and \the fotosnap camera, the dslr one.\Also, what TVs do you have?""",'ideal_answer':{'Smartphones and Accessories':set(['SmartX ProPhone']),'Cameras and Camcorders':set(['FotoSnap DSLR Camera']),'Televisions and Home Theater Systems':set(['CineView 4K TV', 'SoundMax Home Theater','CineView 8K TV', 'SoundMax Soundbar', 'CineView OLED TV'])}}, # eg 4{'customer_msg':"""tell me about the CineView TV, the 8K one, Gamesphere console, the X one.
I'm on a budget, what computers do you have?""",'ideal_answer':{'Televisions and Home Theater Systems':set(['CineView 8K TV']),'Gaming Consoles and Accessories':set(['GameSphere X']),'Computers and Laptops':set(['TechPro Ultrabook', 'BlueWave Gaming Laptop', 'PowerLite Convertible', 'TechPro Desktop', 'BlueWave Chromebook'])}},# eg 5{'customer_msg':f"""What smartphones do you have?""",'ideal_answer':{'Smartphones and Accessories':set(['SmartX ProPhone', 'MobiTech PowerCase', 'SmartX MiniPhone', 'MobiTech Wireless Charger', 'SmartX EarBuds'])}},# eg 6{'customer_msg':f"""I'm on a budget. Can you recommend some smartphones to me?""",'ideal_answer':{'Smartphones and Accessories':set(['SmartX EarBuds', 'SmartX MiniPhone', 'MobiTech PowerCase', 'SmartX ProPhone', 'MobiTech Wireless Charger'])}},# eg 7 # this will output a subset of the ideal answer{'customer_msg':f"""What Gaming consoles would be good for my friend who is into racing games?""",'ideal_answer':{'Gaming Consoles and Accessories':set(['GameSphere X','ProGamer Controller','GameSphere Y','ProGamer Racing Wheel','GameSphere VR Headset'])}},# eg 8{'customer_msg':f"""What could be a good present for my videographer friend?""",'ideal_answer': {'Cameras and Camcorders':set(['FotoSnap DSLR Camera', 'ActionCam 4K', 'FotoSnap Mirrorless Camera', 'ZoomMaster Camcorder', 'FotoSnap Instant Camera'])}},# eg 9{'customer_msg':f"""I would like a hot tub time machine.""",'ideal_answer': []}]测试自动化测试集
print(f'Customer message: {msg_ideal_pairs_set[7]["customer_msg"]}')
print(f'Ideal answer: {msg_ideal_pairs_set[7]["ideal_answer"]}')
通过比较理想答案来评估测试用例
这里我们定义一个评估函数用以评估LLM的返回结果和自动测试用例集中的理想答案做比较并计算得分。
import json
def eval_response_with_ideal(response,ideal,debug=False):if debug:print("response")print(response)# json.loads() expects double quotes, not single quotesjson_like_str = response.replace("'",'"')# parse into a list of dictionariesl_of_d = json.loads(json_like_str)# special case when response is empty listif l_of_d == [] and ideal == []:return 1# otherwise, response is empty # or ideal should be empty, there's a mismatchelif l_of_d == [] or ideal == []:return 0correct = 0 if debug:print("l_of_d is")print(l_of_d)for d in l_of_d:cat = d.get('category')prod_l = d.get('products')if cat and prod_l:# convert list to set for comparisonprod_set = set(prod_l)# get ideal set of productsideal_cat = ideal.get(cat)if ideal_cat:prod_set_ideal = set(ideal.get(cat))else:if debug:print(f"did not find category {cat} in ideal")print(f"ideal: {ideal}")continueif debug:print("prod_set\n",prod_set)print()print("prod_set_ideal\n",prod_set_ideal)if prod_set == prod_set_ideal:if debug:print("correct")correct +=1else:print("incorrect")print(f"prod_set: {prod_set}")print(f"prod_set_ideal: {prod_set_ideal}")if prod_set <= prod_set_ideal:print("response is a subset of the ideal answer")elif prod_set >= prod_set_ideal:print("response is a superset of the ideal answer")# count correct over total number of items in listpc_correct = correct / len(l_of_d)return pc_correct下面我们要让LLM来回答自动化测试集中的某个问题,然后将输出结果与自动化测试集中的理想回答做比较并计算得分。
response = find_category_and_product_v2(msg_ideal_pairs_set[7]["customer_msg"],products_and_category)
print(f'Resonse: {response}')eval_response_with_ideal(response,msg_ideal_pairs_set[7]["ideal_answer"])
从输出结果上看,LLM返回的结果Resonse中的产品数量小于理想答案中的产品数量,所以Resonse只是理想结果的一个子集,由此看来Resonse的结果并不完整。
对所有测试用例进行评估并计算正确回复的比例
下面我们要对所有的测试用来进行评估,并计算正确的resonse所占比例。
# Note, this will not work if any of the api calls time out
score_accum = 0
for i, pair in enumerate(msg_ideal_pairs_set):print(f"example {i}")customer_msg = pair['customer_msg']ideal = pair['ideal_answer']# print("Customer message",customer_msg)# print("ideal:",ideal)response = find_category_and_product_v2(customer_msg,products_and_category)# print("products_by_category",products_by_category)score = eval_response_with_ideal(response,ideal,debug=False)print(f"{i}: {score}")score_accum += scoren_examples = len(msg_ideal_pairs_set)
fraction_correct = score_accum / n_examples
print(f"Fraction correct out of {n_examples}: {fraction_correct}")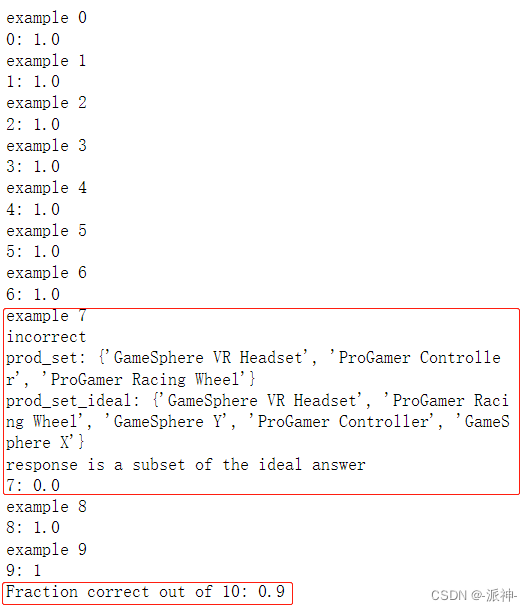
我们测试了所有的测试用来,从返回的结果上看只有第7个问题的返回结果不完全正确,这个前面已经讨论过了,所以正确的回复是9个,不正确的回复有1个,所以最后得分是0.9。
总结
今天我们学习了如何评估LLM的回复的正确性,通过建立测试用例来测试LLM的回复,当LLM的回复不符合要求时,我们需要修改prompt来让LLM输出正确的结果,在修改prompt时我们在system_message中增加了控制输出结果的语句,同时增加少量学习样本(few-shot prompt),这样更好的微调了LLM,确保LLM按正确格式输出结果,最后我们通过建立自动化测试用例来评估LLM的回复是否与理想答案一致,并得到了LLM的评估分数。


![[MMDetection]COCO数据集可视化验证](https://img-blog.csdnimg.cn/img_convert/ed161824548e0b2b45d0271becde6a45.png)