一、实验目的:
(1)理解一元线性回归和多元线性回归的数学原理,能够利用sklearn中相关库解决现实世界中的各类回归问题;
(2)掌握利用matplotlib对一元线性回归模型进行可视化的方法,并分析模型的优劣;
(3)掌握利用statsmodels进行线性回归并进行模型评价的方法;
(4)掌握利用回归模型对现实问题进行分析和解释的能力。
二、实验仪器及实验环境
(1)硬件:PC机;
(2)软件:Anaconda Jupyter Notebook,Spyder,Pandas
三、实验内容:
(一)基于伊春市木材剩余物数据利用回归模型预测木材剩余物
伊春林区位于黑龙江省东北部。全区有森林面积218.9732万公顷,木材蓄积量为2.324602亿m3。森林覆盖率为62.5%,是我国主要的木材工业基地之一。1999年伊春林区木材采伐量为532万m3。按此速度44年之后,1999年的蓄积量将被采伐一空。所以目前亟待调整木材采伐规划与方式,保护森林生态环境。为缓解森林资源危机,并解决部分职工就业问题,除了做好木材的深加工外,还要充分利用木材剩余物生产林业产品,如纸浆、纸袋、纸板等。因此预测林区的年木材剩余物是安排木材剩余物加工生产的一个关键环节。下面,利用一元线性回归模型预测林区每年的木材剩余物。显然引起木材剩余物变化的关键因素是年木材采伐量。
给出伊春林区16个林业局1999年木材剩余物和年木材采伐量数据见“木材剩余物.csv”。
1.读取伊春市木材剩余物数据集,并显示输入
OSError: Initializing from file failed
解决方法:http://t.csdnimg.cn/afyEh
import numpy as np
import pandas as pdfilepath=r"D:\木材剩余物.csv"
df=pd.read_csv(filepath,sep=",",index_col=0,engine='python')#engine='python'
columns=["剩余物","采伐量"]
df.columns=columns
df.head()
#因为\在python中时转义的意思,这里所表示的路径在编码时无法被正确识别,加上r可强制不转义。
#因为\在python中时转义的意思,这里所表示的路径在编码时无法被正确识别,加上r可强制不转义。
index_col=0告诉Pandas使用第一列作为索引。
2、利用分割X和Y数据集。
X=df[["采伐量"]]#这里如果不加两层中括号没有表格
Y=df["剩余物"]
X.head()
3、对数据进行可视化显示。
import matplotlib.pyplot as plt#调用模块进行可视化显示
plt.scatter(X,Y)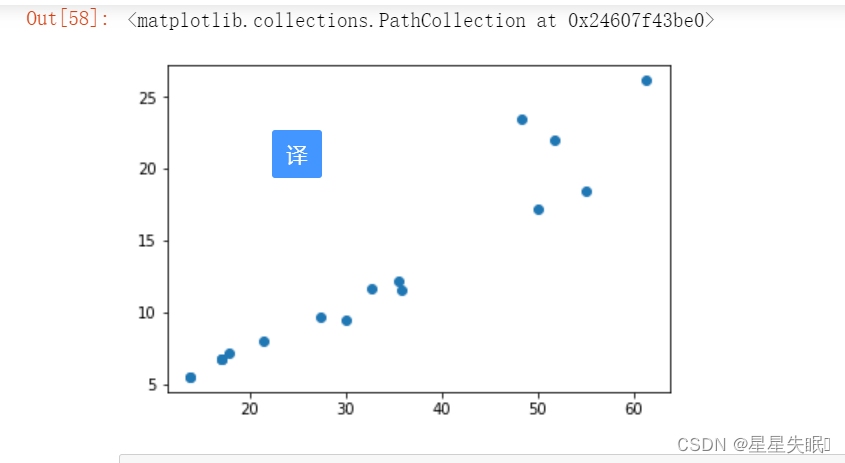
4、利用sklearn中的线性回归模型建立回归模型,对模型进行训练,输出模型参数。
from sklearn.linear_model import LinearRegression
regr=LinearRegression()
regr.fit(X,Y)
regr.coef_,regr.intercept_#regr.coef代表y=ax+b中的a,权值,而regr.intercept代表截距,就是b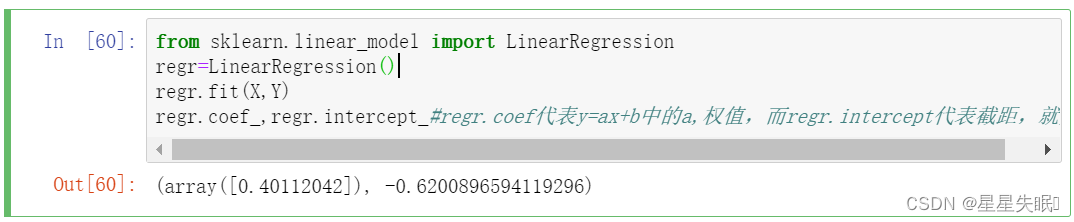
5、假设乌伊岭林业局2000年计划采伐木材20万m3,求木材剩余物的点预测值。

regr.predict([[20]])#可以进行预测了通过计算,置信度为0.95的2000年平均木材剩余物E(y2000)的置信区间是
从而得出预测结果,2000年若采伐木材20万m3,产生木材剩余物的点估计值是7.3231万m3。平均木材剩余物产出量的置信区间估计是在 [5.8736, 8.7726] 万m3之间。从而为恰当安排2000年木材剩余物的加工生产提供依据。

6、利用statsmodels实现线性回归并对模型进行评估。
import statsmodels.api as sm
X2=sm.add_constant(X)
est=sm.OLS(Y,X2).fit()
print(est.summary())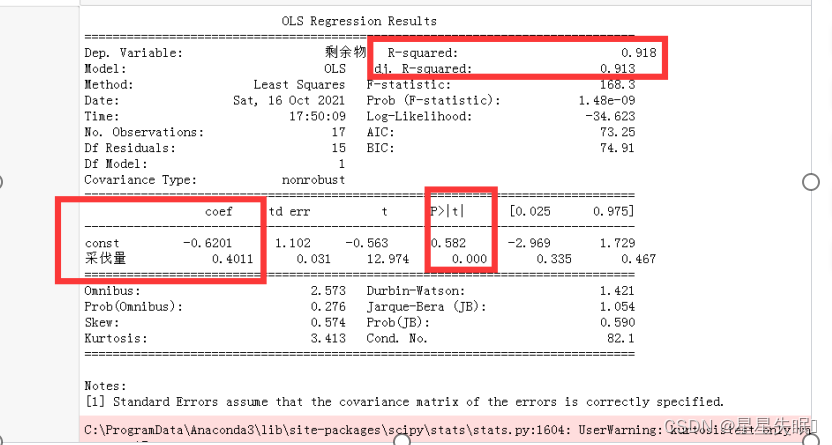
代码解读:
sm.add_constant()函数用于增加截距项,也就是增加一个常数项。
sm.OLS()函数使用OLS(普通最小二乘法)建立线性回归模型est。
est.summary()用于输出模型评估结果。
1、statsmodels.api
x = sm.add_constant(x)是给加上一列常数项的原因是该模型是一条直线,其在轴上是有截距的,这个常数就是反映此截距。
model = sm.OLS(y, x)就是用最小二乘法来进行建模,最小二乘法(ordinary least squares,即OLS)是回归分析中最常用的方法。
2、summary 结果介绍
Summary内容较多,其中重点考虑参数R-squared、Prob(F-statistic)以及P>|t|的两个值,通过这4个参数就能判断的模型是否是线性显著的,同时知道显著的程度如何。
R-squared决定系数,其值=SSR/SST,SSR是Sum of Squares for Regression,SST是Sum of Squares for Total,这个值范围在[0, 1],其值越接近1,说明回归效果越好。
P>|t|统计检验中的P值,这个值越小越能拒绝原假设
X2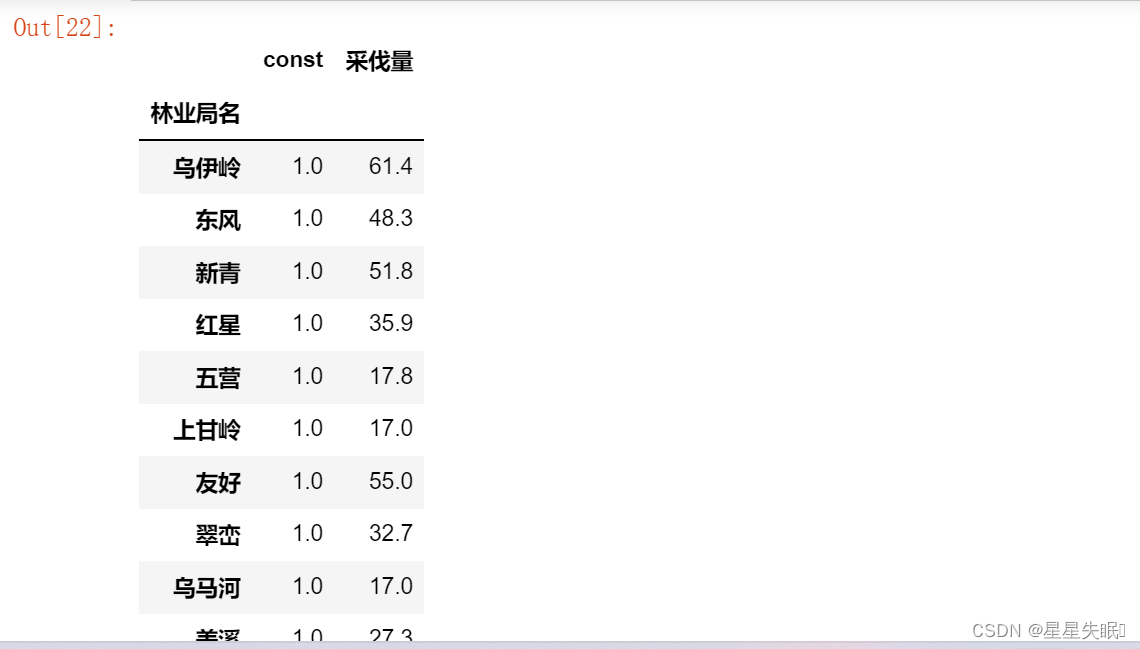
可以发现增加了一列常数,用来反映截距
7、将模型进行可视化显示。
plt.scatter(X,Y)
plt.plot(X,regr.predict(X),color='b')
plt.text(20,20,"y={:.3f}x{:+.3f}".format(regr.coef_[0],regr.intercept_),fontsize=15)
plt.show()
8、预测并查看结果
df_zn["预测剩余物"]=regr.predict(X)
df_zn["误差"]=df_zn["预测剩余物"]-df_zn["剩余物"]
df_zn
9、利用残差qq图进行回归诊断
plt.rcParams['font.sans-serif']=['SimHei']#用来正常显示中文标签、
plt.rcParams['axes.unicode_minus']=False#用来正常显示负号
sm.qqplot(est.resid,line='r')
plt.show()
10、进一步绘制线性回归模型诊断
fig=plt.figure(figsize=(12,8))
fig=sm.graphics.plot_regress_exog(est,"采伐量",fig=fig)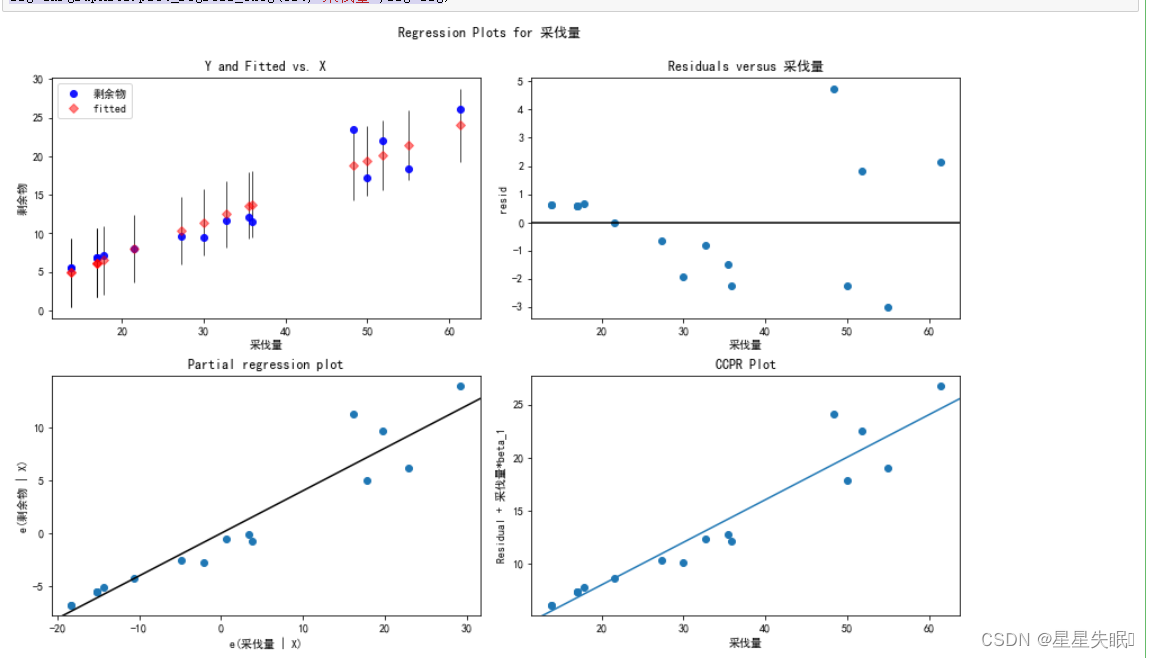
实验结论:
(1)查看模型结果时,红色警告指峰度检验需要样本数大于等于20。
(2)残差qq图存在多个弯曲,不满足残差正态性,暗示模型可能需要拟合多次项。
(3)模型R-squared为0.918,可以解释91.8%的信息。
(4)采伐量每增加一个单位,剩余物增加0.4个单位。
(5)问题:估计结果中截距项没有显著性,依据实际意义可知,没有木材采伐量就没有木材剩余物,所以理论上本案例中截距项是可以取零的。但是而有些问题就不可以。例如家庭消费和收入的关系。即使家庭收入为零,消费仍然非零。一般来说,截距项的估计量没有显著性时,也不做剔除处理。
本案例剔除截距项后的估计结果如下图所示,R2从0.918上升到0.982:
X2=sm.add_constant(X)
est=sm.OLS(Y,X).fit()
print(est.summary())
未完
(二)利用广告投入与销售量数据集进行多元线性回归
1、读取广告投入与销售量数据集,并显示数据。
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.linear_model import LinearRegressiondf_zn=pd.read_csv("D:/Advertising.csv")
df_zn
2、分割X和Y数据集。
X=df_zn.iloc[:,:-1]# iloc[ : , : ] 前面的冒号就是取行数,后面的冒号是取列数”
Y=["sales"]3、查看数据集的特征
df_zn.describe()
4、利用散点图查看各电视、收音机和报纸广告投入量和销售额的关系。
import numpy as np
plt.figure(figsize=(15,5))
plt.subplot(1,3,1)
plt.scatter(X["TV"],Y)
plt.xticks(np.arange(0,300,30))
plt.subplot(1,3,2)
plt.scatter(X["radio"],Y)
plt.xticks(np.arange(0,50,30))
plt.subplot(1,3,3)
plt.scatter(X["newspaper"],Y)
plt.show()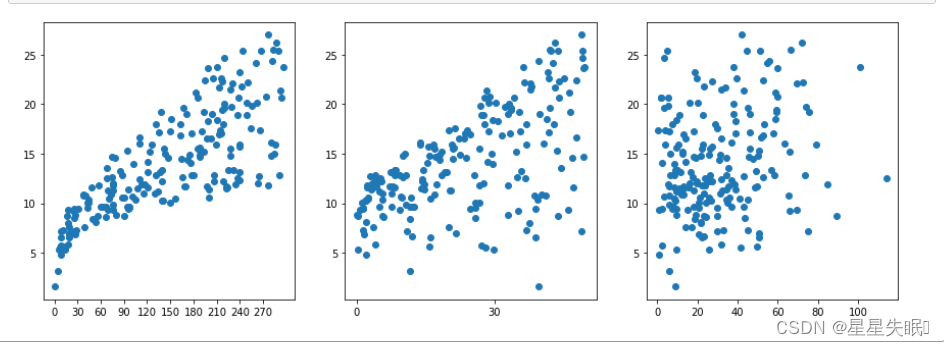
从中可以看出,电视广告投入量与销售额的相关性最好,但是并不是线性关系,报纸广告投入量相关性最差,收音机居中。
5、建立多元线性回归模型根据各平台广告投入量预测销售额。
import statsmodels.api as sm
X2=sm.add_constant(X)
est=sm.OLS(Y,X2).fit()
print(est.summary())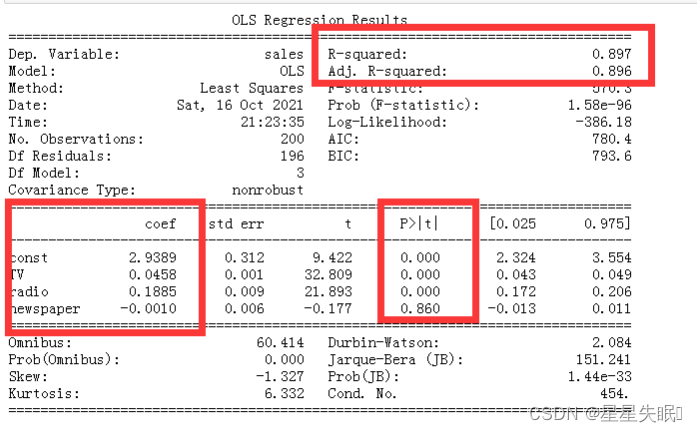
![2023年中国自动化微生物样本处理系统竞争现状及行业市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/8a992190ec65e1fdaf8ba53927d8de0f.png)