【如何成功加载 HuggingFace 数据集】不使用Colab,以ChnSentiCorp数据集为例
- 前置
- 加载数据集
- 尝试一:标准加载数据库代码
- 尝试二:科学上网
- 尝试三:把 Huggingface 的数据库下载到本地
- 尝试3.5 创建 state.json
- 彩蛋
前置
- Huggingface ChnSentiCorp
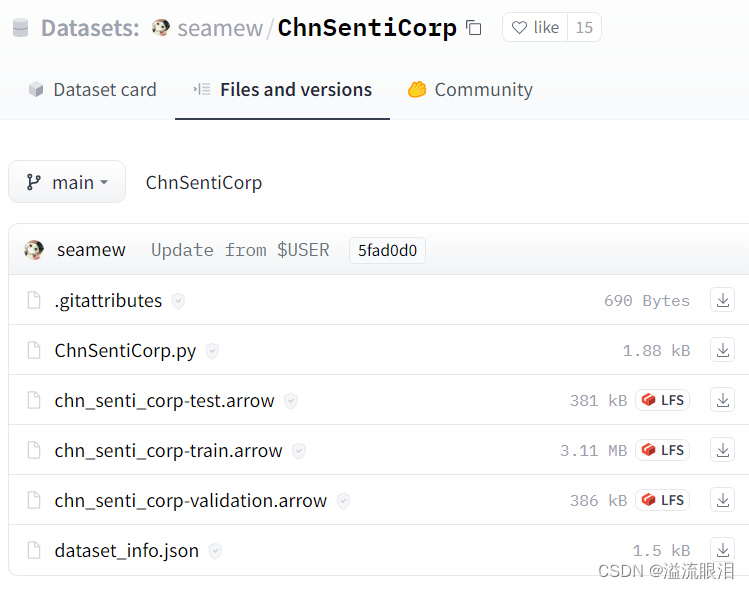
可以看到,该huggingface库中是优测试集,训练集,验证集数据的指针,真正的数据挂载在GoogleDrive 中
加载数据集
尝试一:标准加载数据库代码
- 使用如下代码加载,这也是 一些B站博主 视频中的给出的代码
import torch
from datasets import load_datasetclass Dataset(torch.utils.data.Dataset):def __init__(self, split):self.dataset = load_dataset(path = "seamew/ChnSentiCorp",split = split)def __len__(self):return len(self.dataset)def __getitem__(self, i):text = self.dataset[i]["text"]label = self.dataset[i]["label"]return text, labeldataset = Dataset("train")print(len(dataset), dataset[0])
命令台输出:
Using the latest cached version of the module from C:\Users\admin\.cache\huggingface\modules\datasets_modules\datasets\seamew--ChnSentiCorp\1f242195a37831906957a11a2985a4329167e60657c07dc95ebe266c03fdfb85 (last modified on Fri Jul 7 21:11:26 2023) since it couldn't be found locally at seamew/ChnSentiCorp., or remotely on the Hugging Face Hub.
Using custom data configuration default
D:\Softwares\Anaconda3\Anaconda3\lib\site-packages\scipy\__init__.py:155: UserWarning: A NumPy version >=1.18.5 and <1.25.0 is required for this version of SciPy (detected version 1.25.0warnings.warn(f"A NumPy version >={np_minversion} and <{np_maxversion}"
Downloading and preparing dataset chn_senti_corp/default to C:\Users\admin\.cache\huggingface\datasets\seamew___chn_senti_corp\default\0.0.0\1f242195a37831906957a11a2985a4329167e60657c07dc95ebe266c03fdfb85...
在运行 train_path = dl_manager.download_and_extract(_TRAIN_DOWNLOAD_URL) 这一行的时候报错
报错 ConnectionError
原因:链接不到谷歌云盘
尝试二:科学上网
- 使用科学上网
运行同一份代码
报错FileNotFoundError
原因:什么鬼,莫名奇妙找不到文件,难道是库版本太老了?
尝试三:把 Huggingface 的数据库下载到本地
- 可以使用
git命令等方式把这些文件下载本地
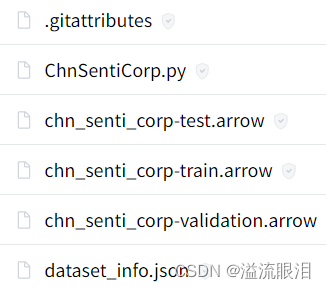
- 使用新的加载方式(
load_from_disk)加载数据库
import torch
from datasets import load_from_diskclass Dataset(torch.utils.data.Dataset):def __init__(self, split):self.dataset = load_from_disk("E:/Repo/NLP/23.7.7 Huggingface_Learn/ChnSentiCorp")def __len__(self):return len(self.dataset)def __getitem__(self, i):text = self.dataset[i]["text"]label = self.dataset[i]["label"]return text, labeldataset = Dataset("train")print(len(dataset), dataset[0])
再次报错 File Not Found

尝试3.5 创建 state.json
- 在刚刚下载的数据集的那个文件夹中创建一个
state.json文件
filename为目录下希望加载的文件,这里加载train数据
_split也同步改成train
其他的东西原样不动,鬼知道_fingerprint后面是啥玩意儿…
{"_data_files": [{"filename": "chn_senti_corp-train.arrow"}],"_fingerprint": "24c4fd9824d8b978","_format_columns": null,"_format_kwargs": {},"_format_type": null,"_indexes": {},"_output_all_columns": false,"_split": "train"}
- 结果,运行成功

彩蛋
- 某博主的教程的
json文件如下:
{"_data_files": [{# 对应上图中的文件名 "filename": "chn_senti_corp-train.arrow"}],"_fingerprint": "24c4fd9824d8b978","_format_columns": null,"_format_kwargs": {},"_format_type": null,"_indexes": {},"_output_all_columns": false,# 加载训练集数据 若为验证集 'validation' 测试集 'test'"_split": "train"}
- 我调用之后,产生新的错误
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb6 in position 43: inv
且改 vscode 的编码到gbk也不管用 - 摸索之后,发现删除 json 中的中文注释即可…
顺带一提 ,这已经是我人生中第二次遇到中文注释删掉就能跑的情况了呢,真不错。