SwinTransformer自问世以来,凭借其优秀的性能,受到无数研究者的青睐,因此作为一个通用的骨干网络,其再目标检测,语义分割,去噪等领域大杀四方,可谓是风光无限,今天,我们便来一睹SwinTranformer的风采。
SwinTransformer是在ViT的基础上进行改进的,但ViT直接使用Transformer,由于其计算复杂度极高,因此需要消耗极大的计算代价,正因如此,SwinTransformer的设计才显得如此巧妙,SwinTransformer最大的特点便是将注意力计算限制在一个个窗口内容,从而大幅的减少了计算量,相比于PVT使用下采样的方式来缩减KV维度,从而减少计算量,SwinTransformer的设计更为复杂,接下来我们便进入正题,开始SwinTransformer模型的学习,博主使用的是swin_T_224_1k版本,这是Swin家族最为轻量级的了,话不多说,开始了。
整体架构
首先给出整体架构,从图中可以看到,与PVT网络相同,其分为4个阶段(每个阶段的输出特征图皆不相同。除第一阶段外,每个阶段都有一个Patch Merging模块,该模型块的作用便是用于缩减特征图,因为Transformer在进行计算时是不会改变特征图大小的,那么要获取多尺度特征,就需要Patch Merging模块了,这里的patch的作用,与PVT中的Patch Embedding,抑或是ViT中的patch都是相同的,只是构造上有所不同而已。
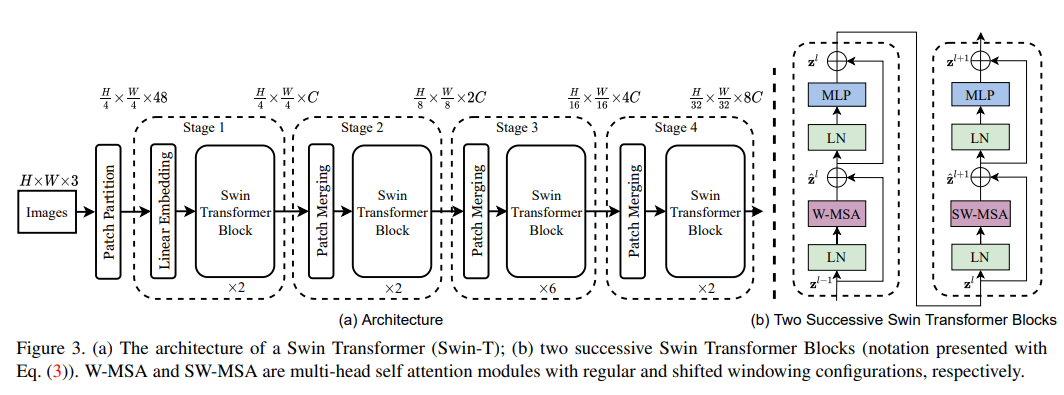
除了Patch Merging模块,接下来便是Swin Transformer Block模块了,这才是重头戏,其主要包含LayerNorm,Window Attention(W-MSA) ,Shifted Window Attention(SW-MSA)和MLP模块。为方便对整个架构的理解,我们先从外部梳理一遍其具体变换:
Swin Transformer整体外部变换过程
def forward_raw(self, x):"""Forward function."""x = self.patch_embed(x)Wh, Ww = x.size(2), x.size(3)if self.ape:# interpolate the position embedding to the corresponding sizeabsolute_pos_embed = F.interpolate(self.absolute_pos_embed, size=(Wh, Ww), mode='bicubic')x = (x + absolute_pos_embed).flatten(2).transpose(1, 2) # B Wh*Ww Celse:x = x.flatten(2).transpose(1, 2)x = self.pos_drop(x)outs = []for i in range(self.num_layers):layer = self.layers[i]x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)if i in self.out_indices:norm_layer = getattr(self, f'norm{i}')x_out = norm_layer(x_out)out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()outs.append(out)return tuple(outs)
输入:x torch.Size([2, 3, 640, 480])
经过Patch Embed后变为:torch.Size([2, 64, 160, 120]),这里的64是我们自己设定的,然后宽高分别缩减为原来的四分之一。
x = self.patch_embed(x)
Wh, Ww = x.size(2), x.size(3) 记录此时的特征图大小:160, 120
随后是判断是否进行位置编码,这里用ape来表示,默认为False
随后将 x 展平并变换维度位置:x = x.flatten(2).transpose(1, 2) 得到:torch.Size([2, 19200, 64])
随后便是进入各个特征提取阶段,共有4个。
for i in range(self.num_layers):layer = self.layers[i]x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)if i in self.out_indices:norm_layer = getattr(self, f'norm{i}')x_out = norm_layer(x_out)out = x_out.view(-1, H, W, self.num_features[i]).permute(0, 3, 1, 2).contiguous()outs.append(out)
其核心代码即:x_out, H, W, x, Wh, Ww = layer(x, Wh, Ww)
第一阶段:x_out:torch.Size([2, 19200, 64]),out:torch.Size([2, 64, 160, 120])

第二阶段:x_out:torch.Size([2, 4800, 64]),out:torch.Size([2, 64, 80, 60])

第三阶段:x_out:torch.Size([2, 1200, 256]),out:torch.Size([2,256, 40, 30])

第三阶段:x_out:torch.Size([2, 1200, 256]),out:torch.Size([2,256, 40, 30]),与第三阶段相同

可以看到,这里的输出特征图并没有严格与整体图一致,我们以代码为准。
四个特征提取阶段的具体构造如下:不要轻易打开,很多
然而在对照下面的模型时却发现,该模块里面似乎没有Shifted Window Attention(SW-MSA),而且在代码的定义中,似乎也没有与之相匹配的定义,这是由于Shifted Window Attention(SW-MSA)事实上可以通过 Window Attention(W-MSA)来实现,只需要给定一个参数shift-size即可。而shift-size的设定则与windows-size有关,如下图所示:
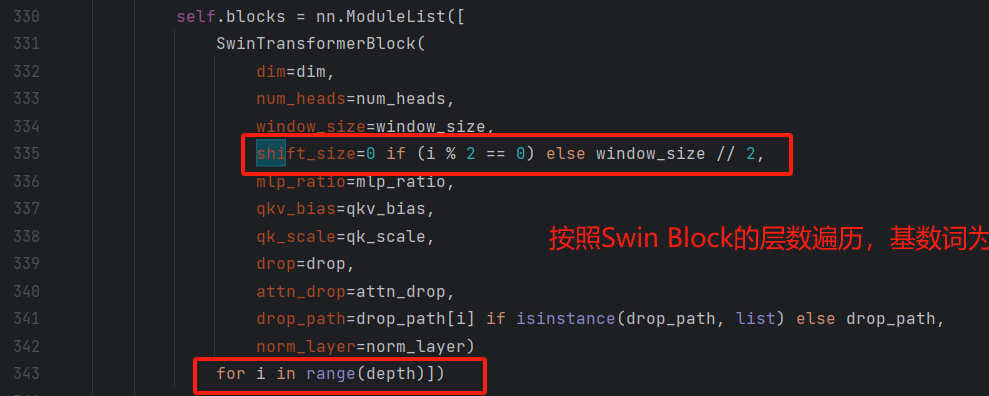
然而从给出的模型结构图上,两者似乎没有区别。
ModuleList((0): BasicLayer((blocks): ModuleList((0): SwinTransformerBlock((norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=64, out_features=192, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=64, out_features=64, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): Identity()(norm2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=64, out_features=256, bias=True)(act): GELU()(fc2): Linear(in_features=256, out_features=64, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock((norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=64, out_features=192, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=64, out_features=64, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.018)(norm2): LayerNorm((64,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=64, out_features=256, bias=True)(act): GELU()(fc2): Linear(in_features=256, out_features=64, bias=True)(drop): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging((reduction): Linear(in_features=256, out_features=128, bias=False)(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)))(1): BasicLayer((blocks): ModuleList((0): SwinTransformerBlock((norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=128, out_features=384, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=128, out_features=128, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.036)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=128, out_features=512, bias=True)(act): GELU()(fc2): Linear(in_features=512, out_features=128, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock((norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=128, out_features=384, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=128, out_features=128, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.055)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=128, out_features=512, bias=True)(act): GELU()(fc2): Linear(in_features=512, out_features=128, bias=True)(drop): Dropout(p=0.0, inplace=False))))(downsample): PatchMerging((reduction): Linear(in_features=512, out_features=256, bias=False)(norm): LayerNorm((512,), eps=1e-05, elementwise_affine=True)))(2): BasicLayer((blocks): ModuleList((0): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.073)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.091)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))(2): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.109)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))(3): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.127)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))(4): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.145)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))(5): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.164)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))))(3): BasicLayer((blocks): ModuleList((0): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.182)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))(1): SwinTransformerBlock((norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(attn): WindowAttention((qkv): Linear(in_features=256, out_features=768, bias=True)(attn_drop): Dropout(p=0.0, inplace=False)(proj): Linear(in_features=256, out_features=256, bias=True)(proj_drop): Dropout(p=0.0, inplace=False)(softmax): Softmax(dim=-1))(drop_path): DropPath(drop_prob=0.200)(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)(mlp): Mlp((fc1): Linear(in_features=256, out_features=1024, bias=True)(act): GELU()(fc2): Linear(in_features=1024, out_features=256, bias=True)(drop): Dropout(p=0.0, inplace=False)))))
)
接下来对其逐一介绍。