作者:钰诚
可观测性
可观测性(Observability)是指系统、应用程序或服务的运行状态、性能和行为能够被有效地监测、理解和调试的能力。
随着系统架构从单体架构到集群架构再到微服务架构的演进,业务越来越庞大,也越来越复杂。云原生时代背景下,随着微服务、Service Mesh、 Serverless 等新技术的出现,业务的复杂度很快就超过了个人的极限,可观测性在现代分布式系统的设计和运维中变得越来越重要。传统的监控和告警方法往往只关注系统的一些基本指标,而忽略了更细粒度的信息和上下文。可观测性的目标是通过全面的数据收集和分析,提供更深入和全面的洞察力,使运维和开发人员能够更好地理解系统的行为、排查问题、预测性能瓶颈和应对故障。
日志、指标和分布式追踪被称为可观测性的三大支柱:
- 日志(Logging): 日志是记录系统运行过程中产生的事件和信息的记录。通过记录应用程序的日志,可以了解系统的运行状态、错误和异常信息,方便故障排查和系统分析。常见的日志系统包括 ELK(Elasticsearch、Logstash、Kibana)和 Splunk 等。
- 指标(Metrics): 指标是用于衡量系统各个方面性能的度量标准。通过采集和记录指标数据,可以实时监控系统的运行情况,包括 CPU 使用率、内存占用、请求响应时间等。常用的指标系统有 Prometheus 和 InfluxDB 等。
- 分布式追踪(Distributed Tracing): 分布式追踪是用于跟踪和监控分布式系统中请求的路径和性能的技术。通过将请求在系统中的不同组件之间传递一个唯一标识符,可以追踪请求的流程和耗时,帮助分析和优化系统性能。常见的分布式追踪系统有 Zipkin 和 Apache Skywalking 等。
通过提供全面且精确的可观测性,系统的开发和运维人员可以更快速地发现问题、理解系统行为,并做出相应的优化和决策,从而提高系统的性能、稳定性和可靠性。
云原生网关可观测体系
MSE 云原生网关依托阿里云现有的云产品(日志服务 SLS、应用实时监控服务 ARMS)以及对开源软件的良好支持构建了丰富的可观测体系,为用户提供了强大的日志、监控、链路追踪以及告警功能,功能大图如下所示:
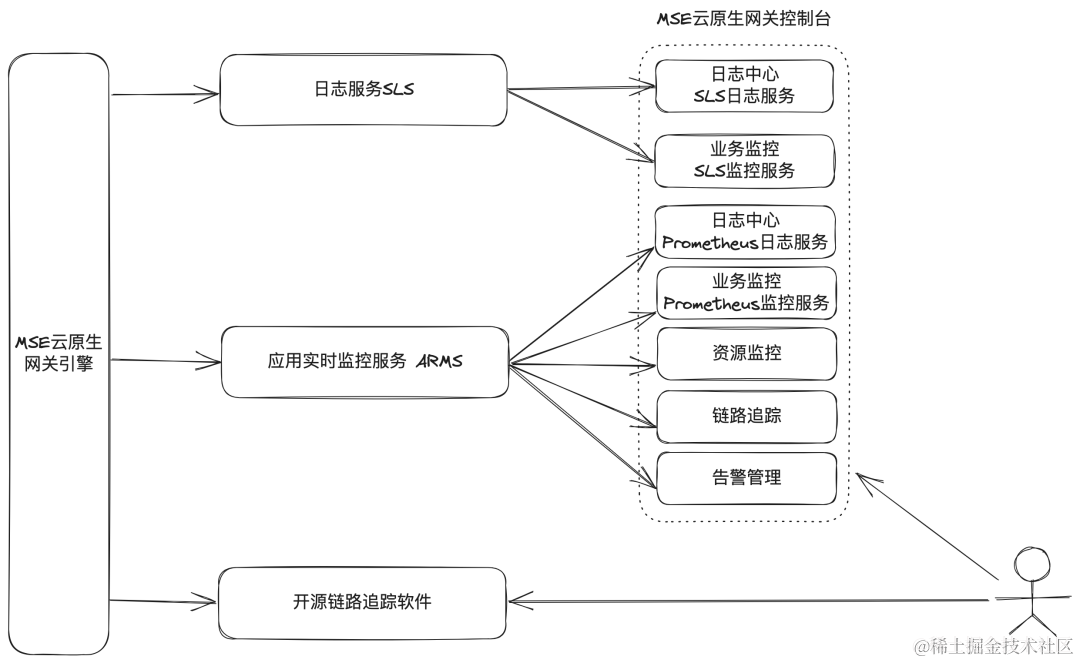
网关的可观测性能力致力于帮助客户构建产品的可靠性体验,为客户提供故障发现与故障定位的能力,减少故障的发生以及降低故障的影响面。 基于网关的监控与告警管理功能,实现故障的及时发现与通知到客户;基于监控与日志,实现故障的快速定位;基于链路追踪,实现请求调用的全链路故障根因排查。
云原生网关可观测实践
过程概览
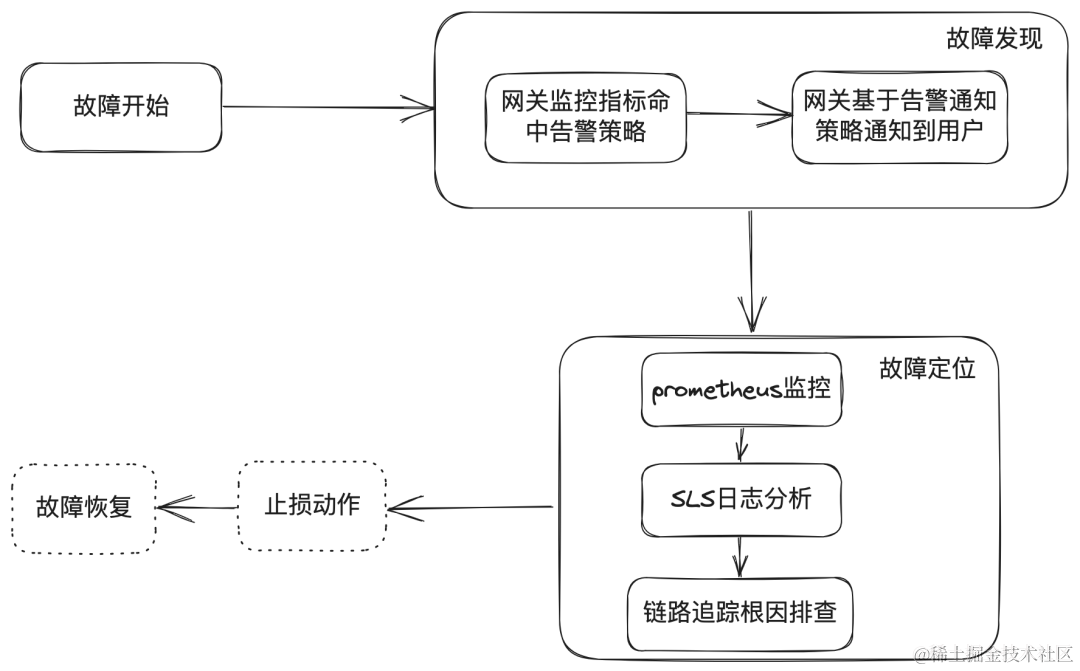
本文将依据下图中标注的功能模块出发,帮助读者体验网关可观测性在故障发现与故障定位中的能力。

整体流程如下图所示:
- 用户收到网关发出的告警
- 用户查看 prometheus 监控找到出问题的路由、服务
- 用户查看 SLS 日志获取更详细的报错信息
- 用户通过链路追踪排故障的根因
测试环境架构概览
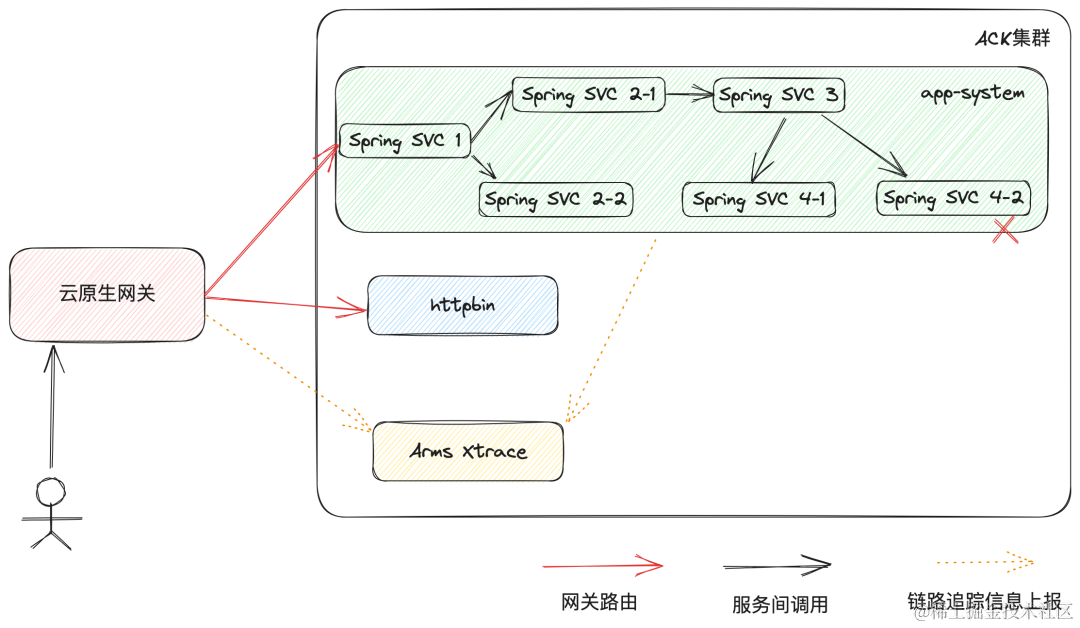
本文在 ACK 集群中部署了一系列 Springboot 的服务,调用关系如上图所示,其中 Spring SVC 4-2 发生了 crash。通过网关接入 ACK 集群,创建路由如下:

测试过程中会通过以下三种请求去访问网关:
- 正常的请求,网关路由到 httpbin
- 在网关处就返回错误的请求,本文使用无法命中路由的请求
- 在上游服务返回错误的请求,网关路由到 Spring SVC 1
此时网关的错误率会出现明显上升。
故障发现与定位过程
通过告警策略及时发现故障
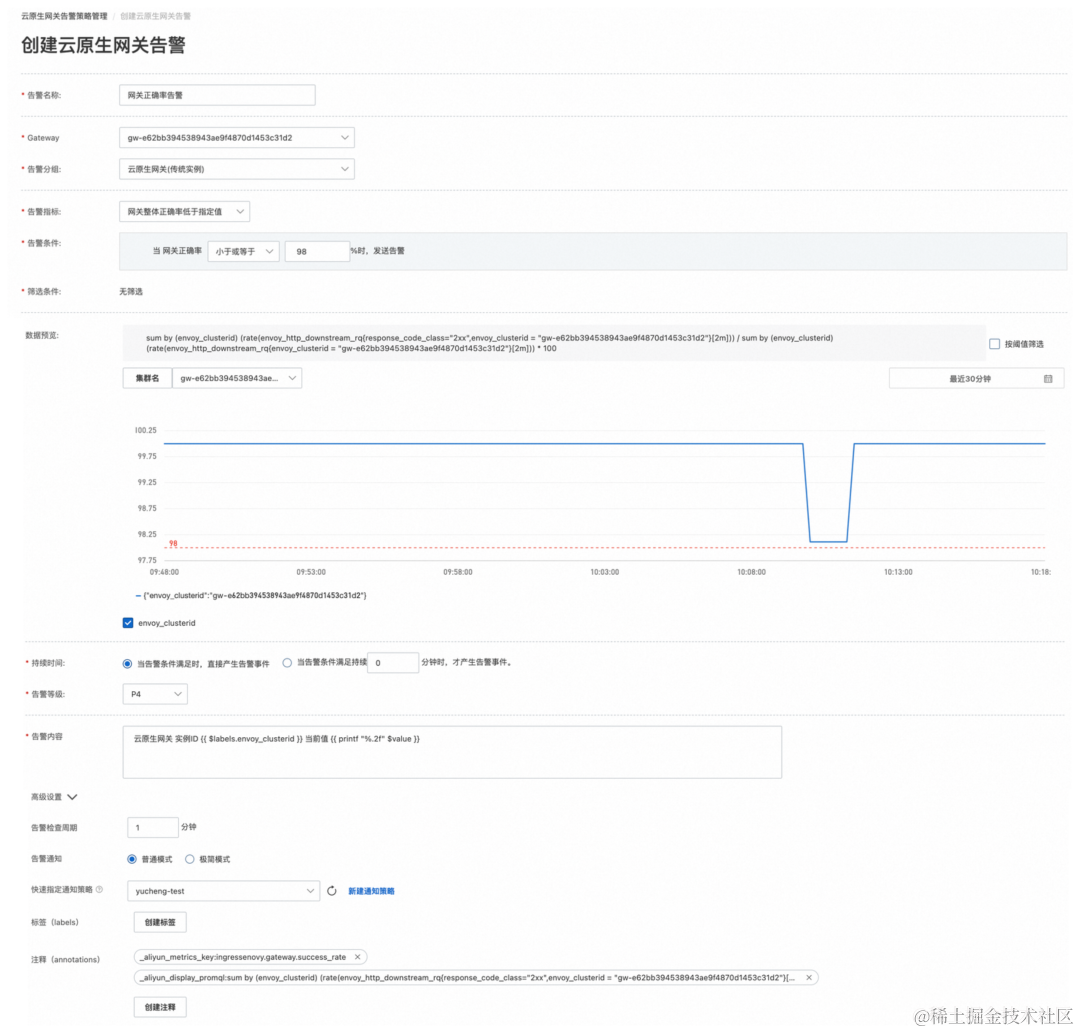
首先配置网关的告警策略,从网关实例粒度设置告警规则与通知策略,本文中采用了邮件通知的方式,除此之外还有电话、短信等方式。配置告警策略的示例如下图所示:
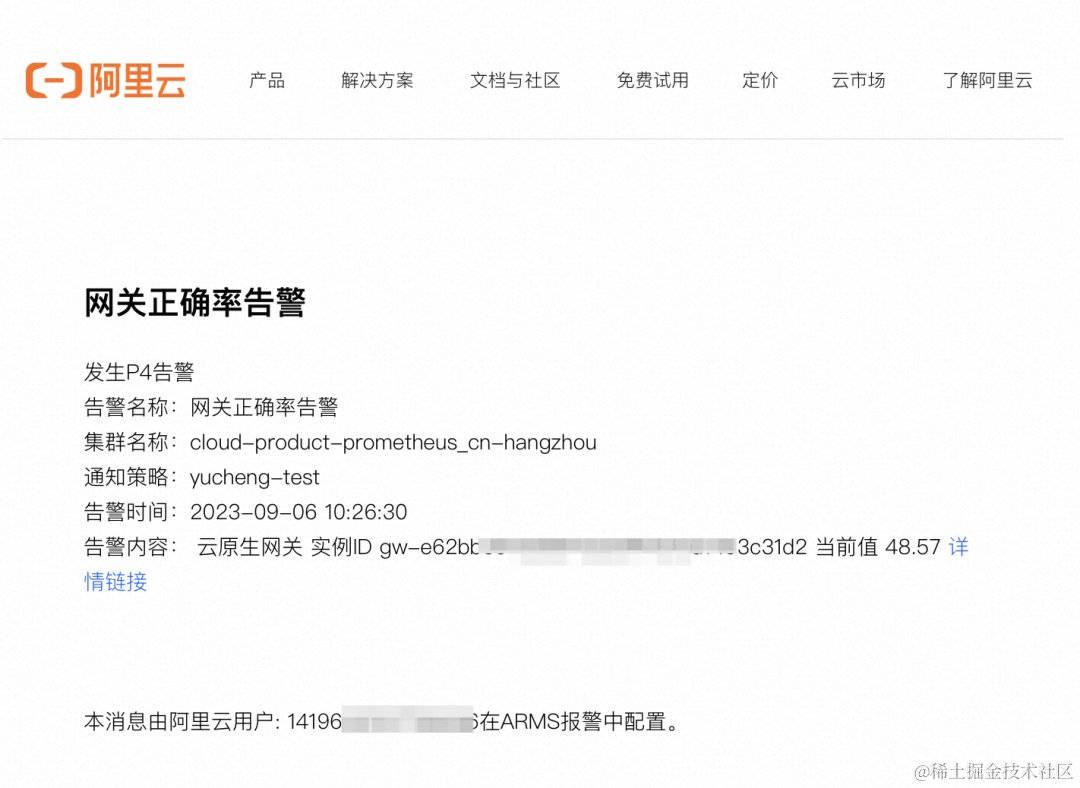
通过以下邮件信息可以得知网关出现了故障:
通过 Arms Prometheus 监控初步定位问题
接下来,查看网关观测分析->业务监控->全局看板的错误信息概览板块,当前监控信息如下:
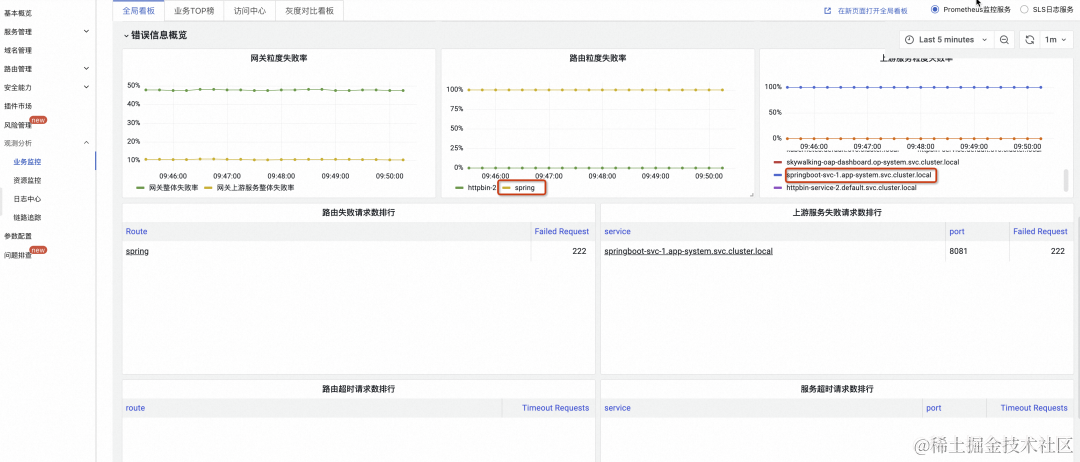
根据图中内容,可以得到以下信息:
- “网关粒度失败率”看板中,网关整体失败率是大于上游服务失败率的,这意味着一部分请求在网关处返回了错误码,一部分请求在上游服务处返回了错误码
- “路由粒度失败率”看板中,能够看到只有路由名称为 “spring” 的路由失败率不是 0
- “上游服务粒度失败率”看板中,能够看到只有服务名称为 “springboot-svc-1.app-system.svc.cluster.local” 的服务失败率不是 0
点击图中“路由失败请求数排行”或者“上游服务失败请求数排行”中的路由名或者服务名可以查看路由或者服务的详细信息。
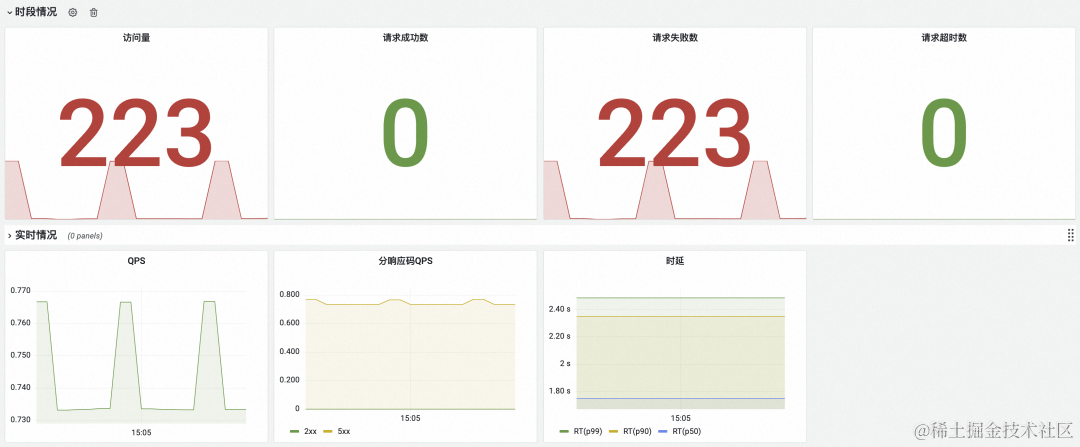
路由名为 “spring” 的路由监控信息如下图所示:
服务名为 “springboot-svc-1.app-system.svc.cluster.local” 的服务监控信息如下图所示:
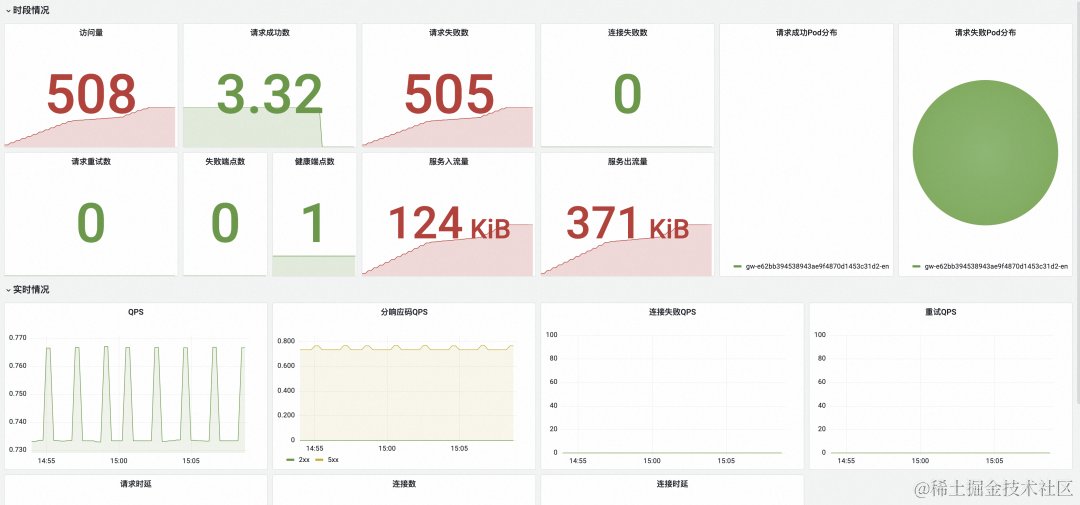
上图中显示出现错误的路由和服务返回的错误码为 5xx,至此,已经初步定位到问题所在:
路由 “spring” 指向的上游服务 “springboot-svc-1.app-system.svc.cluster.local” 出现了问题。
但是,目前还有两个问题需要解决:
- 在网关处返回错误的请求是什么原因?
- 服务 “springboot-svc-1.app-system.svc.cluster.local” 的错误是什么原因造成的?
通过 SLS 网关日志获取详细信息
接下来通过网关日志中心的 SLS 日志获取更详细的信息。
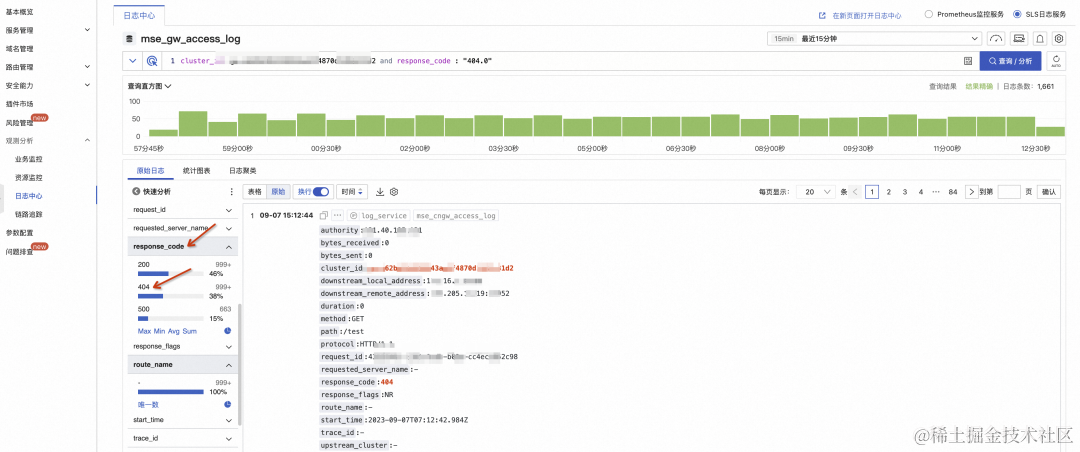
首先点击 response_code,此时会自动生成查询请求,可以看到这段时间内网关的响应码只有三种:200,404,500。
在网关问题排查页面,输入响应码,可以查看错误码可能的原因:
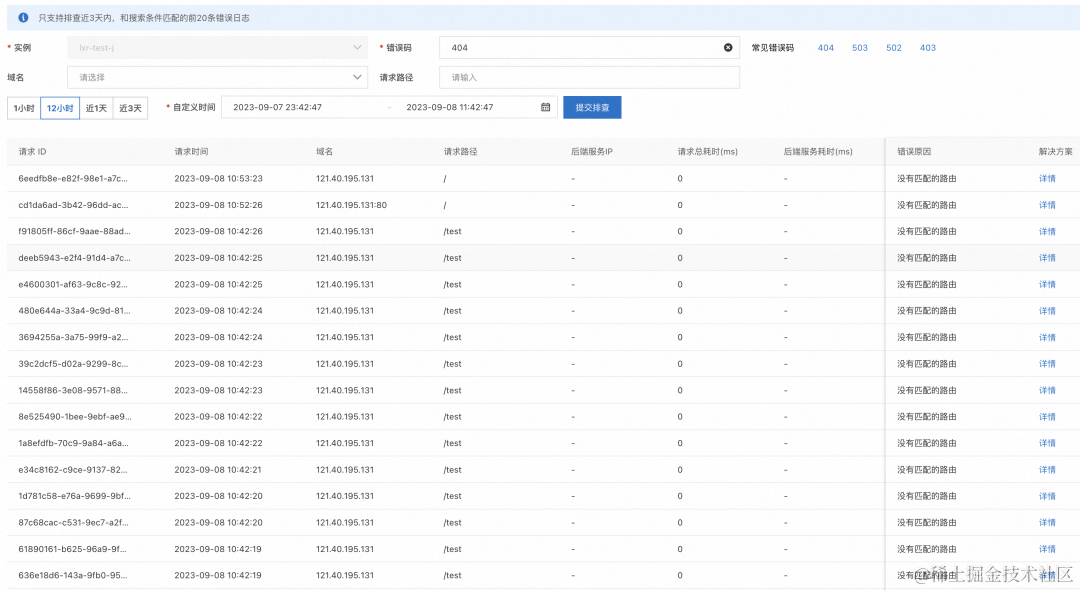
可以看到返回 404 响应码的原因是没有命中路由导致。
类似的,当选择响应码为 500 时,可以看到相应的路由名以及服务名,如下图所示:
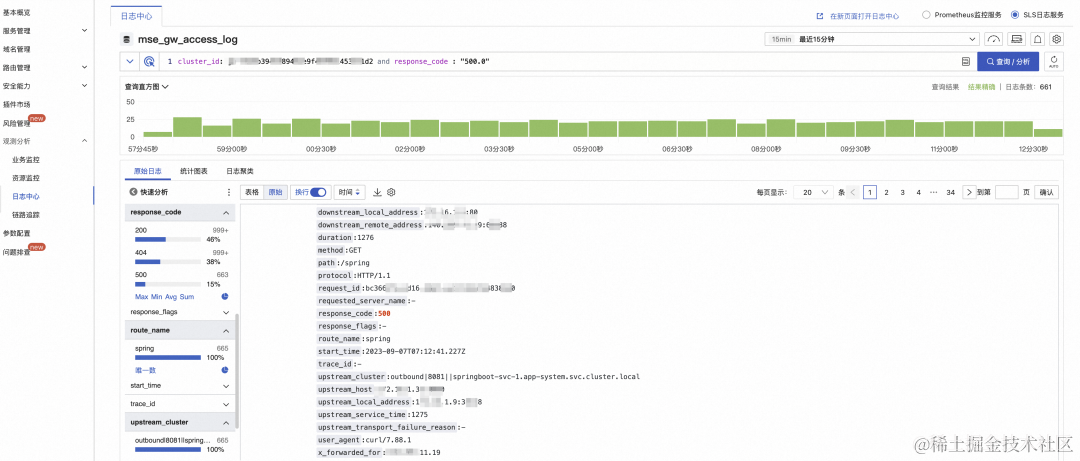
通过问题排查工具可以看到,错误是后端服务造成的:
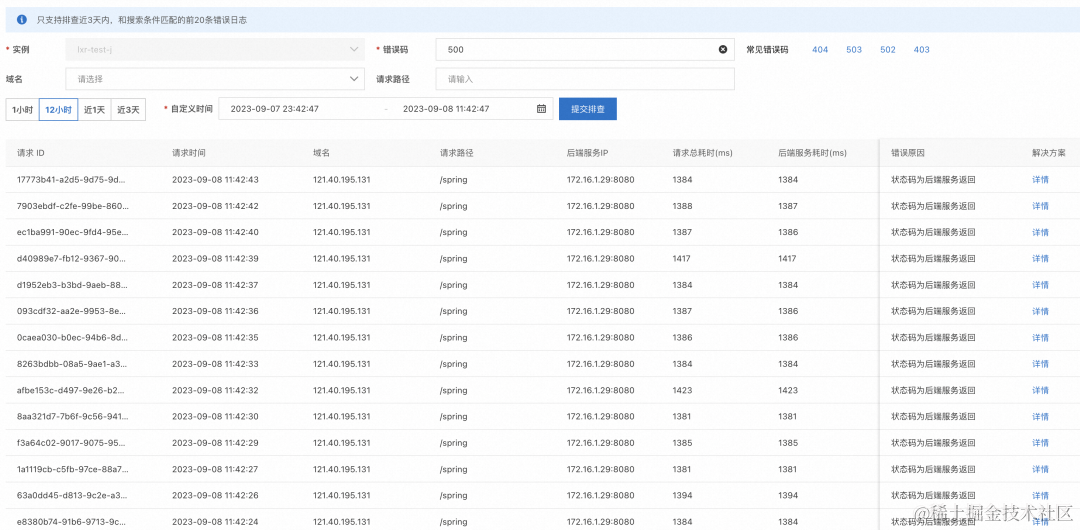
到现在为止,只剩下一个问题:
服务 “springboot-svc-1.app-system.svc.cluster.local” 的错误根因是什么?
通过 Arms xtrace 链路追踪分析调用链
借助于链路追踪技术,可以获取更细粒度的错误信息。只需要简单的配置,网关即可接入 Arms xtrace:
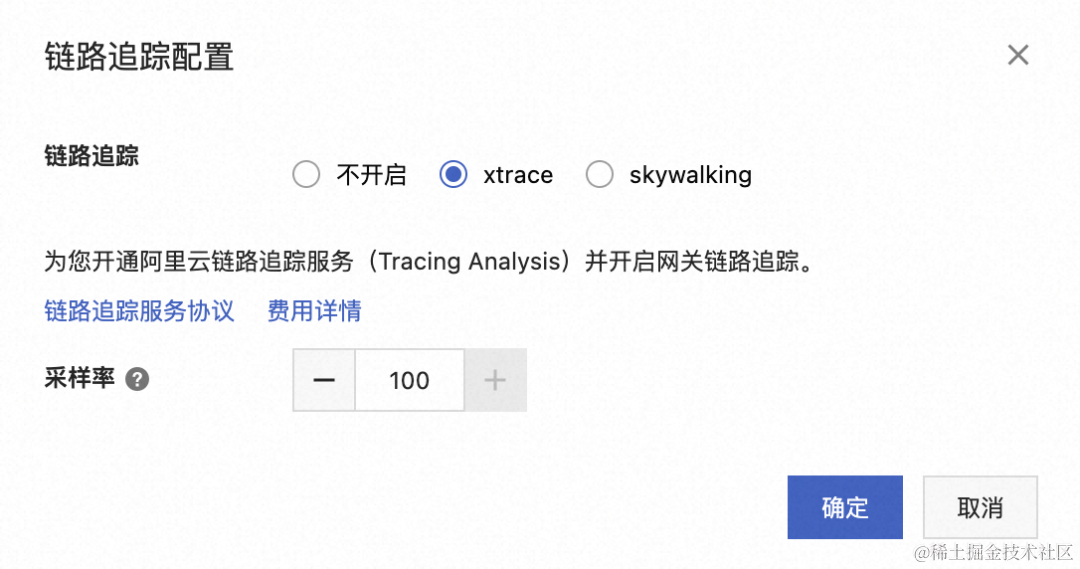
ACK 集群上的 Java 应用按照以下文档进行配置:为容器服务 Kubernetes 版 Java 应用安装探针 [ 1] 。
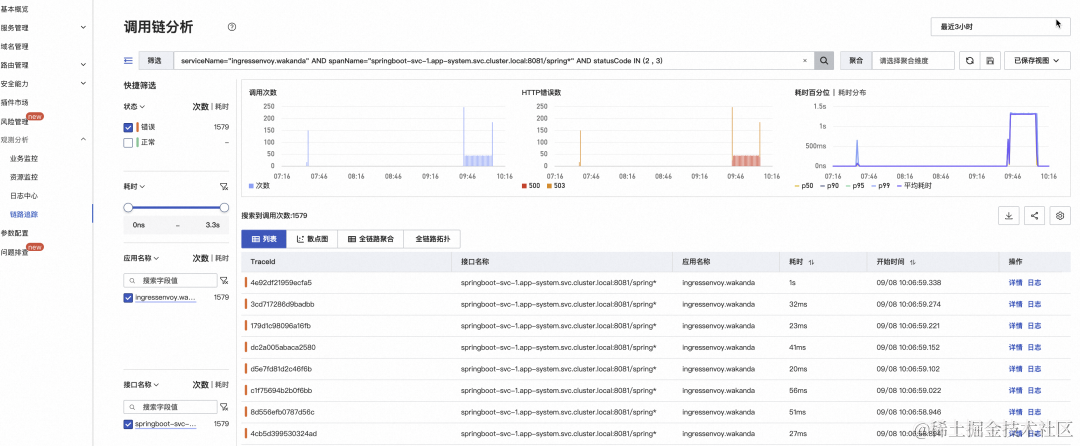
在 SLS 日志中找到一条错误请求的 traceid,根据 traceid 在链路追踪页面搜索相应的调用链路分析调用链路错误的根因:
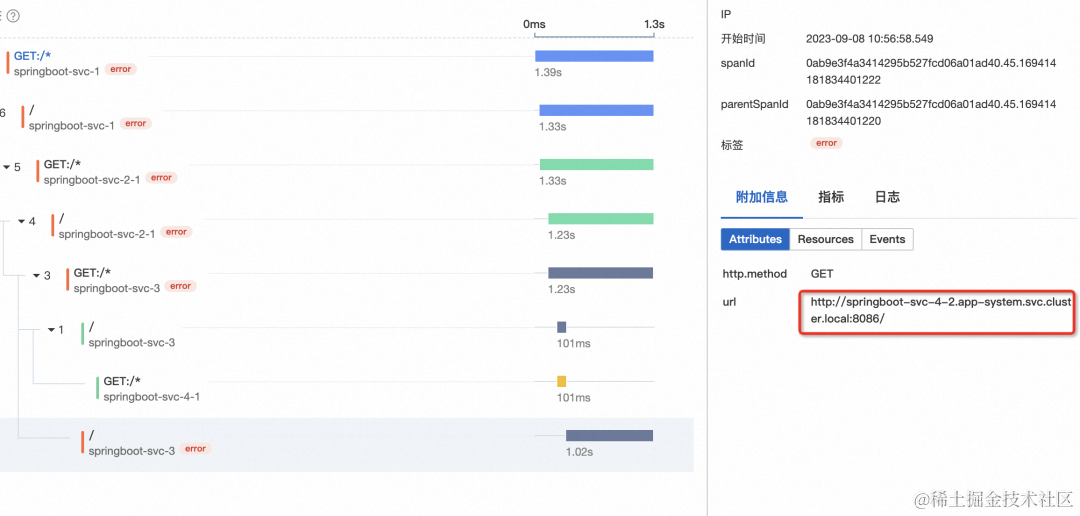
从链路追踪结果看,故障根因是 springboot-svc-4-2 服务错误,至此,一次完整的故障发现与故障定位已经完成。
总结
本次通过云原生网关可观测性进行故障发现和故障定位的实践过程中,首先通过网关的告警策略将故障通知到用户,然后通过 arms 提供的 prometheus 监控服务初步定位到出现故障的路由以及服务,之后通过 SLS 日志服务提供的网关的结构化日志进行查询分析,排查出部分错误是客户端请求路径错误导致,最后通过链路追踪对服务调用链路进行分析,最终成功对故障根因进行定位。
相关链接:
[1] 为容器服务 Kubernetes 版 Java 应用安装探针****
https://help.aliyun.com/zh/arms/application-monitoring/getting-started/install-arms-agent-for-java-applications-deployed-in-ack?spm=a2c4g.11186623.0.i6#arms-cs-k8s-java