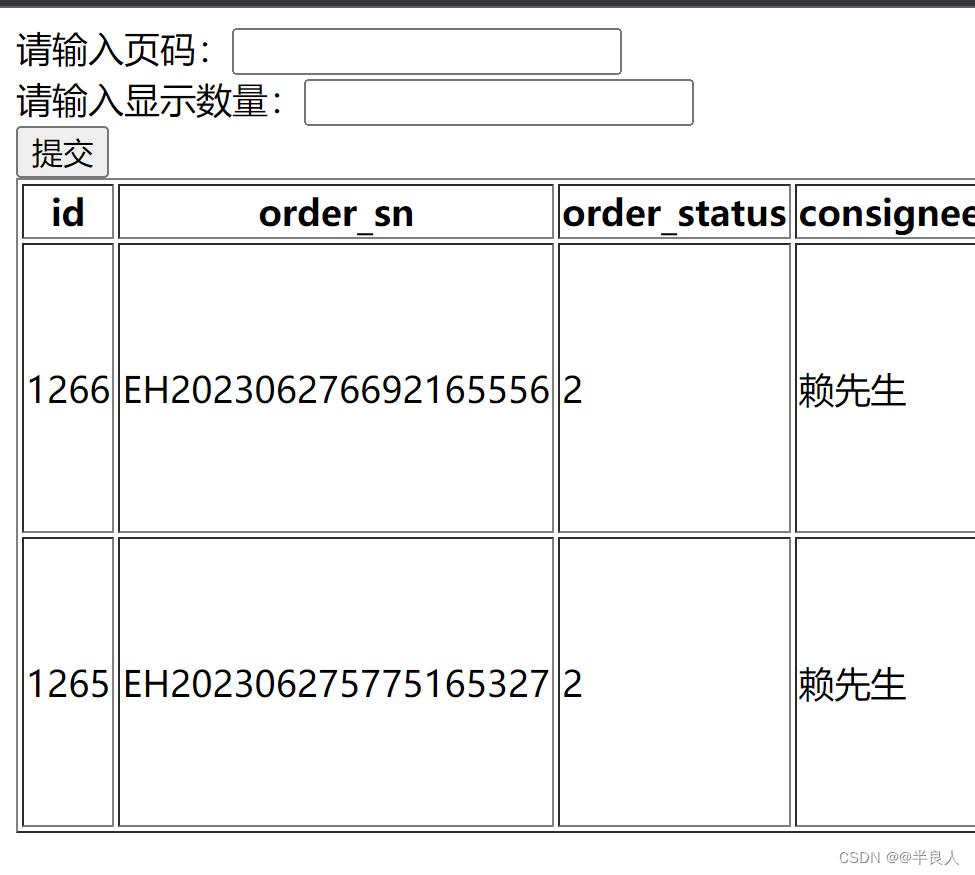
以下脚本可以根据创建VOC格式数据集转换为COCO数据集
其中文件组织格式如下
VOC2007
------Annotations
------***********.xml
------***********.xml
-------ImageSets
------train.txt
------test.txt
-------JPEGImages
------***********.jpg
------***********.jpg
COCO2017
------train
------annotations
------train.json
------images
------***********.jpg
------***********.jpg
-------test
------annotations
------train.json
------images
------***********.jpg
------***********.jpg
#!/usr/bin/python
# xml是voc的格式
# json是coco的格式
import sys, os, json, glob
import xml.etree.ElementTree as ET
import shutil
INITIAL_BBOXIds = 1
# PREDEF_CLASSE = {}
PREDEF_CLASSE = {'DT_SUBSIDENCE':0, 'PIP':1, 'NET':2, 'GROUND_LAMP':3, 'DT_CRACK':4, 'PIP_S':5, 'DT_GAP':6}# function
def get(root, name):return root.findall(name)def get_and_check(root, name, length):vars = root.findall(name)if len(vars) == 0:raise NotImplementedError('Can not find %s in %s.' % (name, root.tag))if length > 0 and len(vars) != length:raise NotImplementedError('The size of %s is supposed to be %d, but is %d.' % (name, length, len(vars)))if length == 1:vars = vars[0]return varsdef convert(xml_paths, out_json, mode = "train"):json_dict = {'images': [], 'type': 'instances','categories': [], 'annotations': []}categories = PREDEF_CLASSEbbox_id = INITIAL_BBOXIdsfor image_id, xml_f in enumerate(xml_paths):# 进度输出# sys.stdout.write('\r>> Converting image %d/%d' % (# image_id + 1, len(xml_paths)))# sys.stdout.flush()tree = ET.parse(xml_f)root = tree.getroot()# filename = get_and_check(root, 'frame', 1).text# print(type(xml_f))filename = xml_f.split(r"E:\VOC2007\Annotations")[1] # VOC的annotations的路径filename = filename.split("\\")[1]filename = filename.split(".xml")[0]+".jpg"print("########################",filename,xml_f)if mode == "test":src = os.path.join(r"E:\VOC2007\JPEGImages",filename) # VOC的JPEGImages的路径dst = os.path.join(r"E:\COCO2017\test\images",filename) # 需要存放的COCOimage路径shutil.copyfile(src, dst)if mode == "train":src = os.path.join(r"E:\VOC2007\JPEGImages",filename)dst = os.path.join(r"E:COCO2017\train\images",filename)shutil.copyfile(src, dst)size = get_and_check(root, 'size', 1)width = int(get_and_check(size, 'width', 1).text)height = int(get_and_check(size, 'height', 1).text)image = {'file_name': filename, 'height': height,'width': width, 'id': image_id + 1}json_dict['images'].append(image)## Cruuently we do not support segmentation# segmented = get_and_check(root, 'segmented', 1).text# assert segmented == '0'for obj in get(root, 'object'):category = get_and_check(obj, 'name', 1).textif category not in categories:new_id = max(categories.values()) + 1categories[category] = new_idcategory_id = categories[category]bbox = get_and_check(obj, 'bndbox', 1)xmin = int(get_and_check(bbox, 'xmin', 1).text) - 1ymin = int(get_and_check(bbox, 'ymin', 1).text) - 1xmax = int(get_and_check(bbox, 'xmax', 1).text)ymax = int(get_and_check(bbox, 'ymax', 1).text)if xmax <= xmin or ymax <= ymin:continueo_width = abs(xmax - xmin)o_height = abs(ymax - ymin)ann = {'area': o_width * o_height, 'iscrowd': 0, 'image_id': image_id + 1,'bbox': [xmin, ymin, o_width, o_height], 'category_id': category_id,'id': bbox_id, 'ignore': 0, 'segmentation': []}json_dict['annotations'].append(ann)bbox_id = bbox_id + 1for cate, cid in categories.items():cat = {'supercategory': 'none', 'id': cid, 'name': cate}json_dict['categories'].append(cat)# json_file = open(out_json, 'w')# json_str = json.dumps(json_dict)# json_file.write(json_str)# json_file.close() # 快json.dump(json_dict, open(out_json, 'w'), indent=4) # indent=4 更加美观显示 慢if __name__ == '__main__':# 1、读取VOC2007\ImagesSets\Main中的文件 得到测试集和训练集的图片名test_filenames = []train_filenames = []with open(r"E:\lijunjie\GPR\radar_data\AUD_VOC\VOC2007\ImageSets\Main\test.txt") as f:for filename in f.readlines():test_filenames.append(filename.split('\n')[0]) # 去掉换行符 \n with open(r"E:\lijunjie\GPR\radar_data\AUD_VOC\VOC2007\ImageSets\Main\train.txt") as f:for filename in f.readlines():train_filenames.append(filename.split('\n')[0]) print(test_filenames)print(train_filenames)# 2、分别拼凑出 训练 和 测试 所需要的xml 路径xml_path = r'E:\VOC2007\Annotations' # 改一下读取xml文件位置train_xml_files = []test_xml_files = []for train_filename in train_filenames:train_xml_file = os.path.join(xml_path,train_filename) + '.xml' # 拼接路径 加上后缀# print(train_xml_file)train_xml_files.append(train_xml_file)for test_filename in test_filenames:test_xml_file = os.path.join(xml_path,test_filename) + '.xml'# print(test_xml_file)test_xml_files.append(test_xml_file)print(test_xml_files)print(train_xml_files)# 3、转换数据convert(test_xml_files, r'E:\COCO2017\test\annotations\test.json',mode="test") # 这里是生成的json保存位置,改一下convert(train_xml_files, r'E:\COCO2017\train\annotations\train.json',mode="train") # 这里是生成的json保存位置,改一下