数据处理是将数据从给定形式转换为更有用和更期望的形式的任务,即使其更有意义和信息。使用机器学习算法,数学建模和统计知识,整个过程可以自动化。这个完整过程的输出可以是任何所需的形式,如图形,视频,图表,表格,图像等等,这取决于我们正在执行的任务和机器的要求。
数据处理是机器学习(ML)中的关键步骤,因为它为构建和训练ML模型准备数据。数据处理的目标是以适合建模的格式清理、转换和准备数据。
数据处理中涉及的主要步骤通常包括:
- 数据收集:这是从各种源(例如传感器、数据库或其他系统)收集数据的过程。数据可以是结构化的或非结构化的,并且可以以诸如文本、图像或音频的各种格式出现。
- 数据预处理:此步骤包括清理、过滤和转换数据,使其适合进一步分析。这可能包括删除缺失值、缩放或规范化数据,或将其转换为不同的格式。
- 数据分析:在该步骤中,使用诸如统计分析、机器学习算法或数据可视化的各种技术来分析数据。此步骤的目标是从数据中获得见解或知识。
- 数据解释:这一步骤涉及解释数据分析的结果,并根据所获得的见解得出结论。它还可能涉及以清晰和简洁的方式呈现调查结果,例如通过报告,仪表板或其他可视化。
- 数据存储和管理:一旦数据被处理和分析,它必须以安全且易于访问的方式存储和管理。这可能涉及将数据存储在数据库、云存储或其他系统中,并实施备份和恢复策略以防止数据丢失。
- 数据可视化和报告:最后,数据分析的结果以易于理解和可操作的格式呈现给利益相关者。这可能涉及创建可视化、报告或仪表板,以突出显示数据中的关键发现和趋势。
有许多工具和库可用于ML中的数据处理,包括Python的pandas,以及RapidMiner中的数据转换和清理工具。工具的选择将取决于项目的具体要求,包括数据的大小和复杂性以及预期的结果。
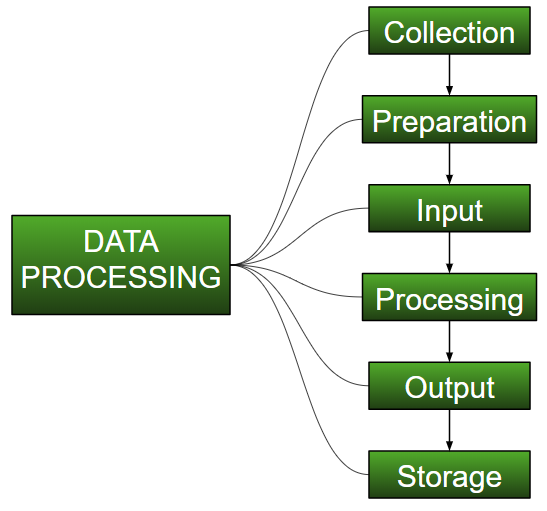
收集:
从ML开始时,最关键的一步是拥有高质量和准确性的数据。数据可以从任何经过认证的来源收集,如data.gov.in,Kaggle或UCI数据集存储库。例如,在准备竞争性考试时,学生从他们可以访问的最好的学习材料中学习,以便他们学习最好的内容以获得最好的结果。同样,高质量和准确的数据将使模型的学习过程更容易和更好,并且在测试时,模型将产生最先进的结果。
大量的资金、时间和资源被消耗在收集数据上。组织或研究人员必须决定他们需要什么样的数据来执行他们的任务或研究。
示例:在面部表情识别器上工作,需要具有各种人类表情的大量图像。良好的数据确保模型的结果是有效的,并且可以信任。
准备:
收集的数据可以是原始形式,不能直接馈送到机器。因此,这是一个从不同来源收集数据集,分析这些数据集,然后构建新数据集以进行进一步处理和探索的过程。该准备可以手动或从自动方法执行。数据也可以以数字形式准备,这也将加快模型的学习。
例如:一个图像可以转换成一个N X N维的矩阵,每个单元格的值将指示图像像素。
输入:
现在准备好的数据可能是机器可读的形式,因此要将此数据转换为可读形式,需要一些转换算法。为了执行该任务,需要高计算和精度。例如:可以通过MNIST Digit数据(图像),豆瓣评论,音频文件,视频剪辑等来源收集数据。
处理:
在这个阶段,需要算法和ML技术来执行在大量数据上提供的具有准确性和最佳计算的指令。
输出:
在该阶段,结果由机器以用户可以容易地推断的有意义的方式获得。输出可以是报告、图表、视频等形式
储存:
这是最后一步,其中保存所获得的输出和数据模型数据以及所有有用的信息以供将来使用。
机器学习中数据处理的优势:
- 改进的模型性能:数据处理通过清理数据并将其转换为适合建模的格式来帮助提高ML模型的性能。
- 更好地表示数据:数据处理允许将数据转换为更好地表示数据中的底层关系和模式的格式,使ML模型更容易从数据中学习。
- 提高准确性:数据处理有助于确保数据准确、一致且无错误,这有助于提高ML模型的准确性。
机器学习中数据处理的缺点:
- 耗时:数据处理可能是一项耗时的任务,特别是对于大型和复杂的数据集。
- 易出错:数据处理可能容易出错,因为它涉及到数据的转换和清理,这可能导致重要信息的丢失或引入新的错误。
- 对数据的理解有限:数据处理可能导致对数据的有限理解,因为经变换的数据可能不代表数据中的潜在关系和模式。