你是否曾经想过,当你在 Intellij IDEA 中输入一个段代码时,GitHub 是如何给你返回相关的结果的?其实,这背后的秘密就是围绕 Prompt 生成而构建的架构设计。
Prompt 是一个输入的文本段落或短语,用于引导 AI 生成模型执行特定的任务或生成特定类型的输出。不同的 Prompt 会导致不同的搜索结果,因为它们会影响模型对信息的处理方式。而通过巧妙构建Prompt,我们可以让模型在广泛的任务中执行特定的操作,从而提高搜索效率和用户满意度。
Prompt 的设计不仅影响 AIGC 模型的行为和输出,还影响软件架构的设计和优化。那么,Prompt 和软件架构之间有什么关系呢?为什么 Prompt 对软件架构如此重要呢?
在本文中,我们将探讨这一关系,并基于我们对一些卓越的人工智能生成代码(AIGC)相关应用的研究,以及一些内部 AIGC 应用的观察,这些应用都是基于 LLM 优先理念下来构建和设计软件架构的。这些应用包括:
GitHub Copilot:一个基于 OpenAI Codex/Codex 2 模型的代码生成器,它可以根据用户提供的注释或代码片段来生成完整的代码。
JetBrains AI Assistant:一个围绕开发人员日常活动构建的伴随性 AI 辅助的 IDE 插件。
Bloop:一个根据用户提供的自然语言描述或问题,来生成对应答案或者代码的工具。
而究其背后的原因,我想只有围绕 LLM 优先来考虑架构,才有可能对应这种复杂性。
PS:本文讨论的背景是复杂的 AIGC 应用,诸如于 Copliot 型、Agent 型应用,普通的 AIGC 不具备这种复杂性。
AIGC 优先应用的架构特征(初步)
在我们先前的文章《上下文工程:基于 Github Copilot 的实时能力分析与思考》里,介绍了 Copilot 如何结合用户行为,以及当前代码上下文,光标位置(行内、块间、块外)来生成三种不同类型的代码。其基本特质便是围绕用户的潜在意图,来设计对应的生成内容。并结合当前的代码文件,来调整生成的内容,以符合对应语言的基本语法。
而 Bloop 则是围绕于检索增强生成(RAG)来推测用户的潜在意图,诸如通过查询扩展的方式,来更好地匹配潜在的代码。并通过输出更多的上下文交互过程,以让用户来调整自己的问题,获得更准确的答案。
再结合 JetBrains AI Assistant 的语言上下文模块化架构,我们简单将复杂 AIGC 应用总结了三个核心特征(未来还将继续优化这个版本):
感知用户意图,以构建清晰的指令: 这一特征涉及捕获和分析用户的操作,以全面理解用户的目标和偏好。应用程序需要能够识别用户的需求,提供相应的内容生成方案,从而建立清晰的指令。这可以包括收集和解释用户输入,行为分析,以及利用历史数据来更好地了解用户需求。通过这个特征,AIGC 应用可以更好地满足用户的期望。
围绕用户意图地交互设计,以让用户输出更多上下文: 这个特征旨在创建友好和灵活的用户界面,鼓励用户提供更多上下文信息。用户通常通过输入和修改内容生成的参数和条件来表达他们的需求。此外,AIGC 应用还可以隐式地获取用户的上下文信息,例如 v0.dev、数据智能和流式交互。这些信息可以包括用户的操作历史、上下文语言信息、位置信息等,以提供更个性化和智能化的内容生成服务,从而增强用户体验。
基于数据的反馈改进与模型优化: 这一特征通过不断收集和分析用户对生成内容的反馈,如评分、评论、分享等,以实现内容生成模型和算法的不断调整和优化。通过利用这些反馈数据,AIGC 应用可以提高生成内容的质量和多样性,确保用户满意度不断提高。
而对于这些应用来说,并不是需要复杂的 prompt 技巧。技巧性、复杂的 Prompt 在工程化面前都是灾难性的。
复杂 AIGC 应用的基本 Prompt 策略
对于复杂 AIGC 应用来说,难点是在于 Prompt 的策略,也就是如何构建自动的上下文收集?。通常来说,其设计过程要考虑:
鲁棒性:Prompt 的设计应该能够处理各种输入情况,并在不同任务和领域中表现良好。它们应该是通用的,而不仅仅适用于特定任务。
评估和反馈循环:Prompt 设计的成功与否通常需要不断的迭代和反馈。开发者可能需要花时间来调整Prompt以提高模型的性能,这也可能影响软件架构。
而鲁棒性也意味着,复杂的 Prompt 会变成一种灾难,因为作为一个生成模型,它无法考虑到你的每个 MUST/HAVE TO/必须,以及你交给他的,你不应该 xxx。太长的 prompt,不仅显得 LLM 很愚蠢,也间接地让你觉得自己很愚蠢。你应该将长 prompt 分为多个 stage(人及 GPT 会在阅读很长的文本之后,忽略这句要求),即复杂问题应该先进行拆解 —— 参考领域驱动设计的方式。
在 AIGC 工具里,我们可以将 Prompt 分为多种类型,强指令型,强结果型。
Prompt 策略 1:精短地指令,精准上下文
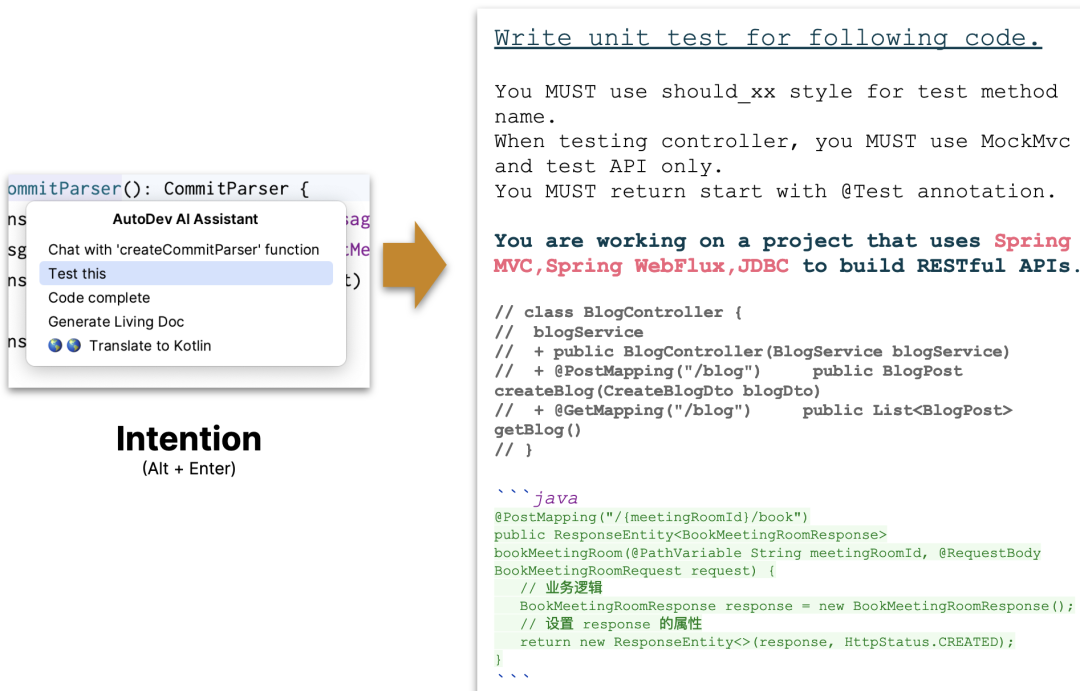
在非聊天的场景下,诸如于编写文档、编写报告等等,工具中的指令往往都非常简洁: Write documentation ,而为了让 LLM 生成更精准的结果,我们还需要进行更多的上下文补充,诸如于:
Write documentation for given method ,它结合着不同的语言的语法形式(类声明、方法声明等)。
随后,还需要考虑不同的文档工具,诸如于 write PHPDoc 。而使用 Python 语言时,则又需要使用 """ 来作为文档的起始标志。而为了编写更规范的文档,还需要结合 use @param tag 来进行示例,告诉 LLM 应该写什么样的文档。
那么,问题就来了,要让 AIGC 构建出这个上下文,我们需要:
获取语言相关的信息,诸如版本信息等
配置或者获取该语言的文档工具
获取待写文档的代码信息
如果是方法的话,需要提醒
method has return type。根据不同的语言配置基本的规范。如 Python 到底是用 Tab 还是用空格。
指令本身很简单,但是要构建精准的上下文,则是要回到工程化问题上来。
Prompt 策略 2:围绕结果设计交互,获取用户的上下文
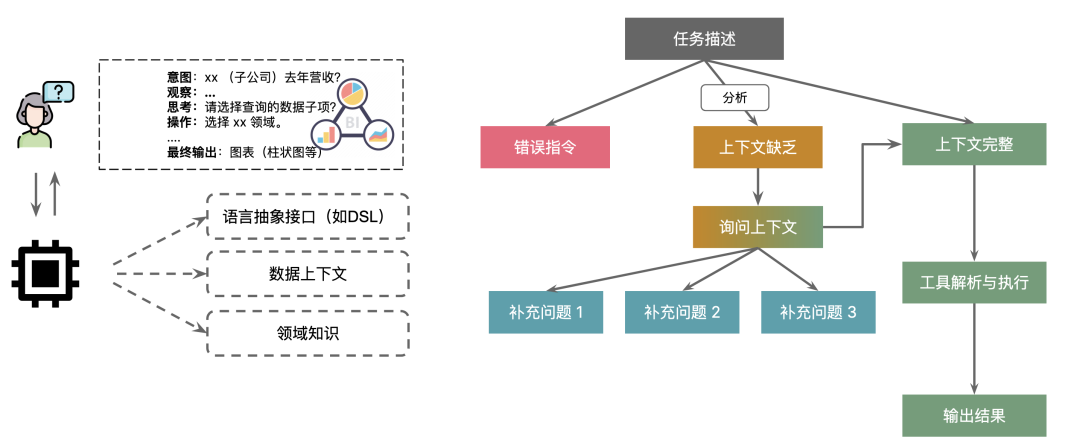
在非编码场景的其他 RAG 场景之下,通常我们会围绕于:感知-分析-执行 来分析用户的意图,进而根据用户的意图来生成更多的上下文。先看个数据问答的示例:
意图:xx (子公司)去年营收?
观察:...
思考:请选择查询的数据子项?
操作:选择 xx 领域。
….
最终输出:图表(柱状图等)这里就存在一个问题,用户最终要的是图表,还是文字信息?我们要不要帮用户做这个决定?如果要做这个决定,那么我们是不是需要根据用户以往的历史经验?
所以,在这个场景里,在进入解决方案之前,我们一直在围绕用户的问题进行澄清。
围绕 Prompt 策略的架构设计示例
现在,再回到架构设计上,让我们看看对应的示例。
语言插件化架构
我们在理解了 JetBrains 的 AI 工具的架构设计上,参考(复制)了相似的设计。在 JetBrains 的 IDE 里,不同的语言后缀会调用不同的 IDE 插件功能来实现对应的重构等等的方式。所以,在设计对应的功能时,也是将不同的语言划分到不同的模块,以借由其实现其动态加载。
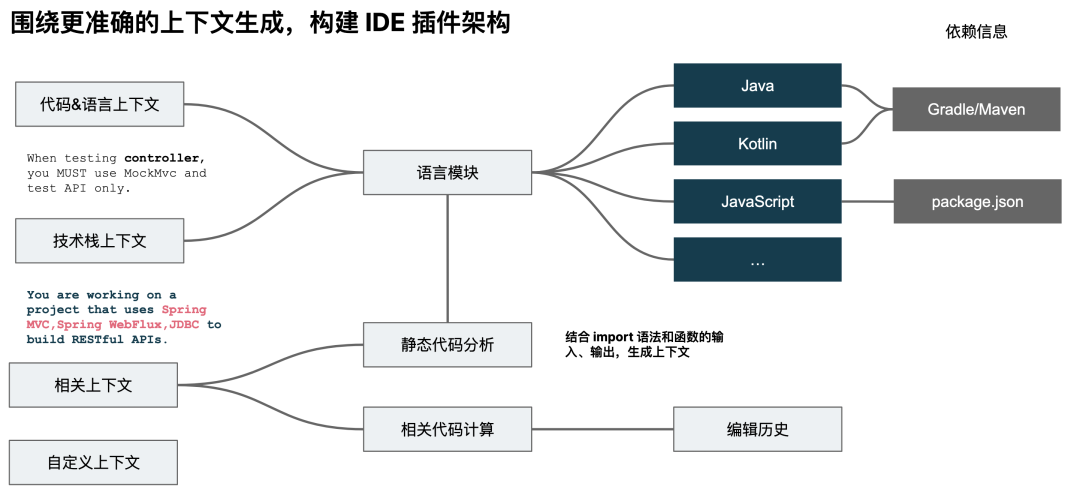
举个例子:为了生成测试代码的准确性,我们需要获取被测试代码、测试框架等信息,因此需要语言上下文、技术栈上下文、相关上下文、以其它上下文。
所以,仔细拆解下来,我们就需要围绕于插件化架构来构建 IDE 插件,即在 Core 模块里定义 Prompt 和我们的抽象接口,在不同语言模块里,实现对应的上下文获取方式。
而如果我们只是一个简单的聊天功能,就不需要这么复杂的架构,只是生成内容的精准性会下降。
发散-收敛式上下文
而在诸如于 Bloop 这一类以 RAG(检索增强生成) 为主的应用设计里,更重要的则是如何从不同渠道丰富用户的上下文,其难点主要在于如何匹配最相似的答案。
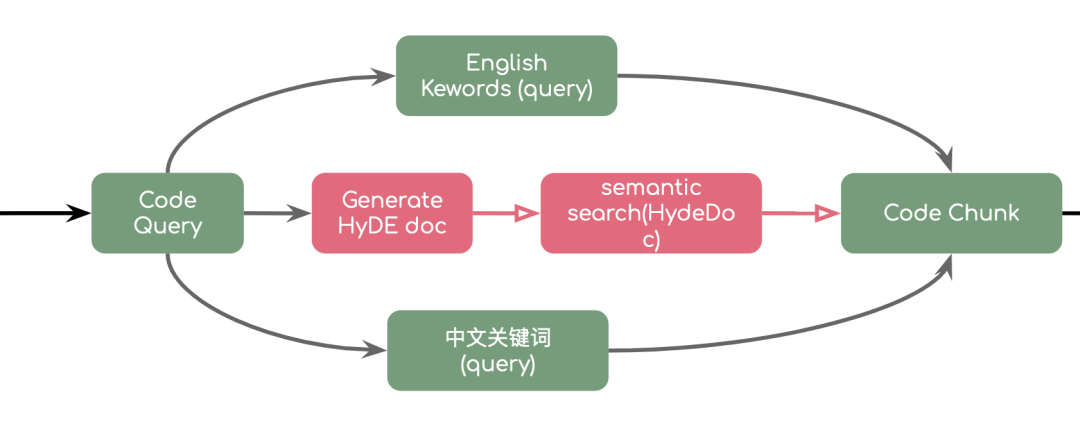
发散。其使用方式有多种多样的,诸如于分析用户的意图,使之能进行内容检索 —— 代码检索、文档检索、网络检索等等。
收敛。结合发散的结果,对检索到的内容进行处理,进而做最后的过程呈现与内容的总结。
而这部分内容本身是作为策略的一部分存在的,它可以作为基础设施的一部分,诸如 LLM SDK,又或者是代码服务。
其它场景
而在其他一些场景中,诸如于 Code Review,我们会结合提交信息中的 story id、代码变更、业务信息,三部分来进行最后的总结。与语义化代码搜索的场景相似,但是与普通的 Code Review 相比,为了达成更精准的上下文,则花费的成本更高。
平衡 Prompt 策略与架构演进路线
尽管 AIGC 能显著地加速我们编写代码的时间,但是花费更多的时间在上下文架构上,则意味着架构的复杂度。我们是否应该花费如此多的时间在构建 prompt 上,它带来的 ROI 是否合理,就需要根据不同的场景去考虑。
除此,我们还需要围绕于 Prompt 演进策略,来构建架构的演进路线。诸如于,对于一个 Code Review 工具,我们应该如何去规划?
实现基本的 code review 接口调用与 comments 调用?
结合提交信息,来 review 代码,分析两者是否一致?
从提交信息中获取业务上下文,来分析代码是否与业务一致?
……
随后,则是根据我们能获取到的数据,来设计最终的 prompt,并以此作为版本来规划架构演进路线。
小结
由 ChatGPT 生成:
本文讨论了复杂 AIGC 应用中的 Prompt 和架构设计的关键性。Prompt 是引导 AI 生成的文本段落,其设计直接影响AIGC应用的性能。
复杂 AIGC 应用具有三核心特征:感知用户意图、设计用户交互以获取更多上下文和基于数据反馈的模型优化。两种 Prompt 策略包括精简指令和围绕结果的设计,有助于构建更有效的Prompt。示例架构设计采用语言插件化,可根据不同语言后缀实现不同功能,提高 AIGC 应用的多语言支持。
文章突出强调 Prompt 的重要性,指出 Prompt 和架构设计在提高生成内容质量和用户满意度方面至关重要。在实践中,需要平衡 Prompt 策略和架构设计,以满足不同 AIGC 应用的需求。