文章目录
- 01、初识 Elasticsearch
- 正向索引和倒排索引
- 索引
- MySQL与ES的概念映射
- 安装ES
- 分词器
- 分词器的设置
01、初识 Elasticsearch
本次ES基于:7.12.1 版本
学习资源为:https://www.bilibili.com/video/BV1Gh411j7d6
什么是ES(Elasticsearch)
elasticsearch 结合 kibana、Loastash、Beats,也就是elastic stack (ELK)。被广泛应用在日志数据分析、实时监控等领域。
elasticsearch 是 elastic stack 的核心,负责存储、搜索、分析数据。

ES的发展
ES底层基于 Lucene
Lucene 是一个 Java 语言的搜索引擎类库,是 Apache 公司的顶级项目,由 DougCutting 于1999年研发官网地址: https://lucene.apache.org/。
Lucene的优势:
- 易扩展
- 高性能(基于倒排索引)
Lucene的缺点:
- 只限于Java语言开发
- 学习曲线陡峭
- 不支持水平扩展
2004年shay Banon基于Lucene开发了Compass
2010年shay Banon 重写了 Compass,取名为Elasticsearch。官网地址: https://www.elastic.co/cn/。相比与lucene,elasticsearch具备下列优势:
- 支持分布式,可水平扩展
- 提供 Restful 接口,可被任何语言调用
为什么学习elasticsearch?
搜索引擎技术排名:
-
Elasticsearch:开源的分布式搜索引擎
-
Splunk:商业项目
-
Solr:Apache的开源搜索引擎
正向索引和倒排索引
传统数据库(如MySQL)采用正向索引,例如给下表 (tb goods)中的id创建索引
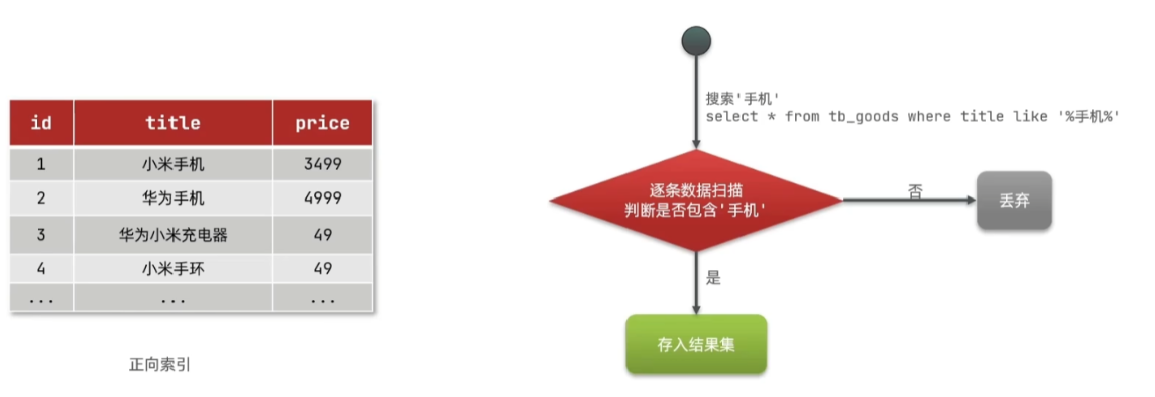
elasticsearch采用倒排索引:
-
文档
(document):每条数据就是一个文档 -
词条
(term):文档按照语义分成的词语
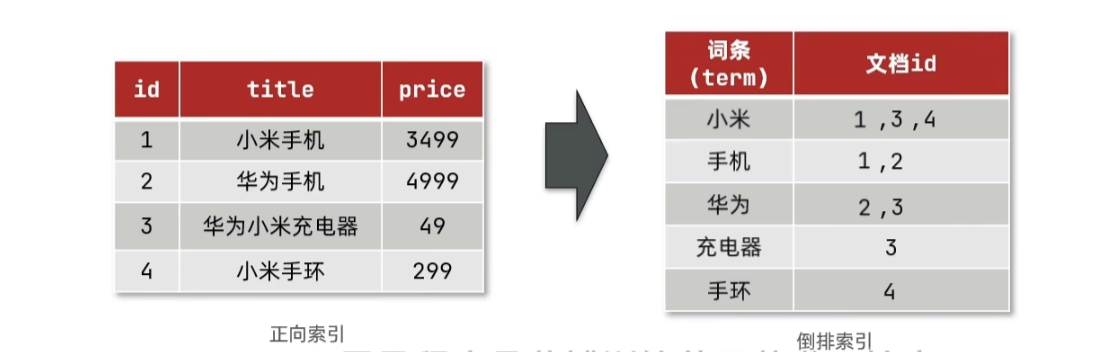
倒排索引是根据词条查找文档。
索引
索引(index):相同类型的文档的集合。不同的JSON结构就代表一个不同的索引。
映射 (mapping):索引中文档的字段约束信息,类似表的结构约束
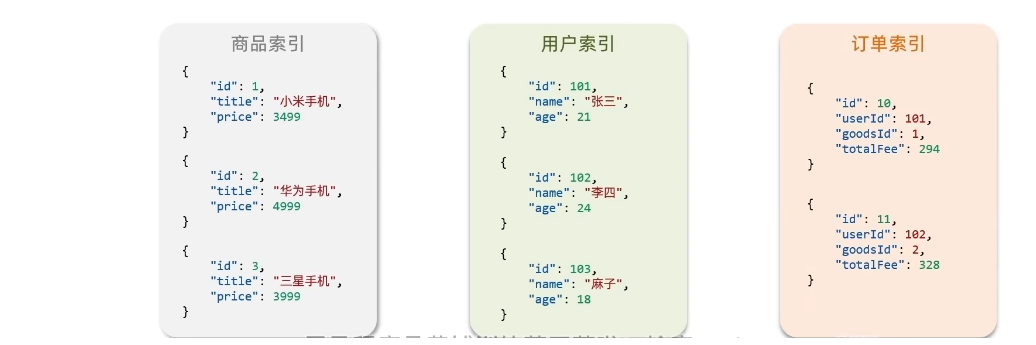
MySQL与ES的概念映射
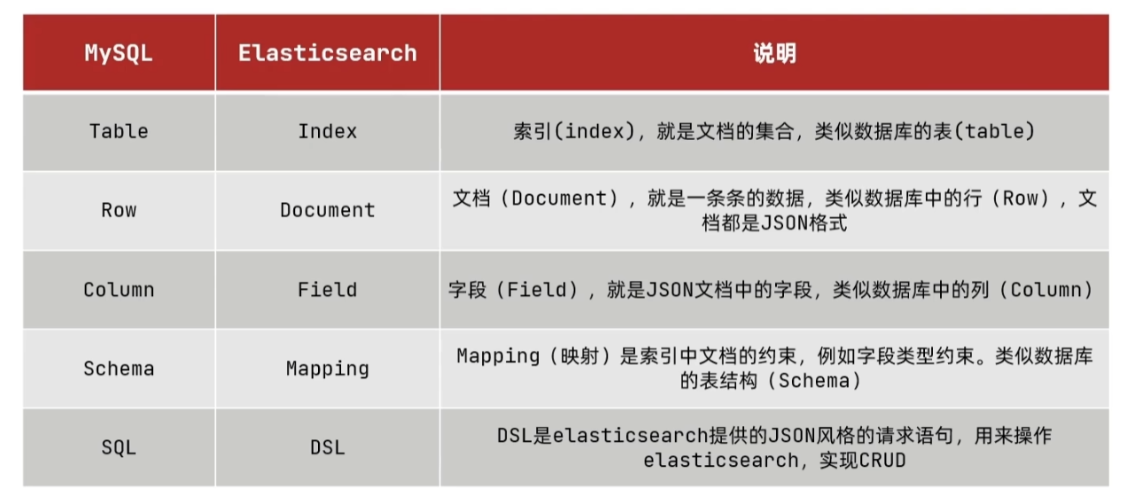
Mysql: 擅长事务类型操作,可以确保数据的安全和一致性。
Elasticsearch:擅长海量数据的搜索、分析、计算。
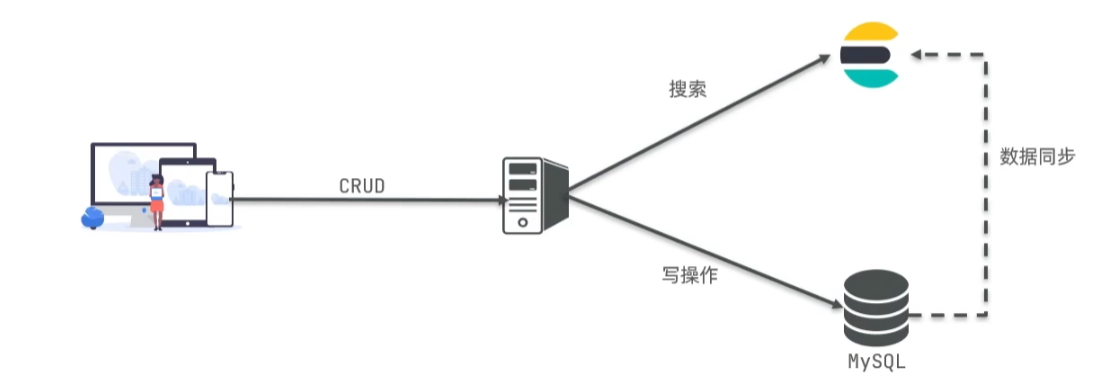
安装ES
使用docker创建网络,拉取镜像。
docker network create es-net
docker pull elasticsearch:7.12.1
docker pull kibana:7.12.1
运行命令
docker run -d \
--name es \
-e"ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e"discovery.type=single-node" \
-v es-data:/usr/share/eTasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
discovery.type=single-node:单点模式es-data:数据目录es-plugins:插件目录- 9200:HTTP端口。9300:各个ES容器互联的端口。
访问
http://ip:9200/
{
"name": "a340f52223b0",
"cluster_name": "docker-cluster",
"cluster_uuid": "ppw1gfsiQbqDdsNfmivM0A",
"version": {"number": "7.12.1","build_flavor": "default","build_type": "docker","build_hash": "3186837139b9c6b6d23c3200870651f10d3343b7","build_date": "2021-04-20T20:56:39.040728659Z","build_snapshot": false,"lucene_version": "8.8.0","minimum_wire_compatibility_version": "6.8.0","minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
运行Kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
- ELASTICSEARCH_HOSTS=http://es:9200 : es:9200 为上述
--name es \时设置的名字。
分词器
es在创建倒排索引时需要对文档分词;在搜索时,需要对用户输入内容分词。但默认的分词规则对中文处理并不友好。
我们在kibana的DevTools中测试:
POST /_analyze
{"analyzer": "standard","text": "南京市长江大桥。"
}
安装分词器
下载:https://github.com/medcl/elasticsearch-analysis-ik/releases?page=6
解压后上传到 es-plugins 中,可通过如下目录查看。
docker volume inspect es-plugins
{"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
}
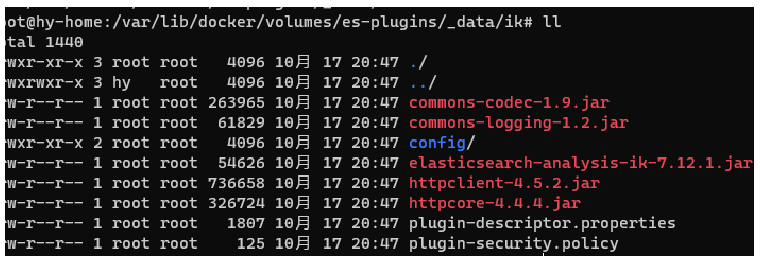
docker restart es
测试ik分词
ik_smart:粗粒度
请求:
POST /_analyze
{"analyzer": "ik_smart","text": "南京市长江大桥。"
}
响应:
{"tokens" : [{"token" : "南京市","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "长江大桥","start_offset" : 3,"end_offset" : 7,"type" : "CN_WORD","position" : 1}]
}
请求:ik-max-word:细粒度
请求:
POST /_analyze
{"analyzer": "ik_max_word","text": "南京市长江大桥。"
}
-----------------------------
{"tokens" : [{"token" : "南京市","start_offset" : 0,"end_offset" : 3,"type" : "CN_WORD","position" : 0},{"token" : "南京","start_offset" : 0,"end_offset" : 2,"type" : "CN_WORD","position" : 1},
....]
}
分词器的设置
添加字典
要拓展ik分词器的词库,只需要修改一个ik分词器目录中的config目录中的IkAnalyzer.cfg.xml文件。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict">ext_dict.dic</entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords">stopword.dic</entry><!--用户可以在这里配置远程扩展字典 --><!-- <entry key="remote_ext_dict">words_location</entry> --><!--用户可以在这里配置远程扩展停止词字典--><!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
去除停用词
<entry key="ext_stopwords">stopword.dic</entry>