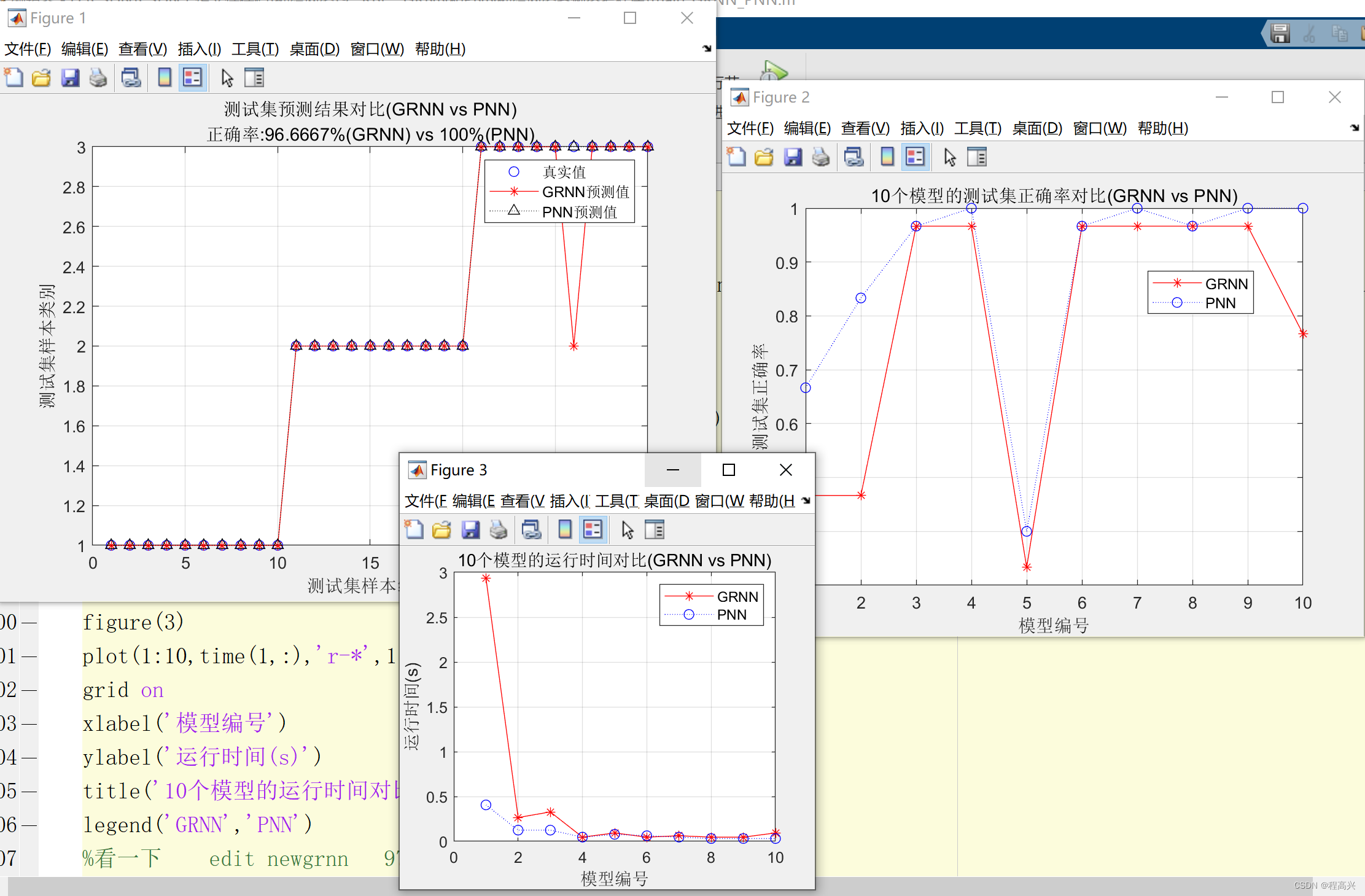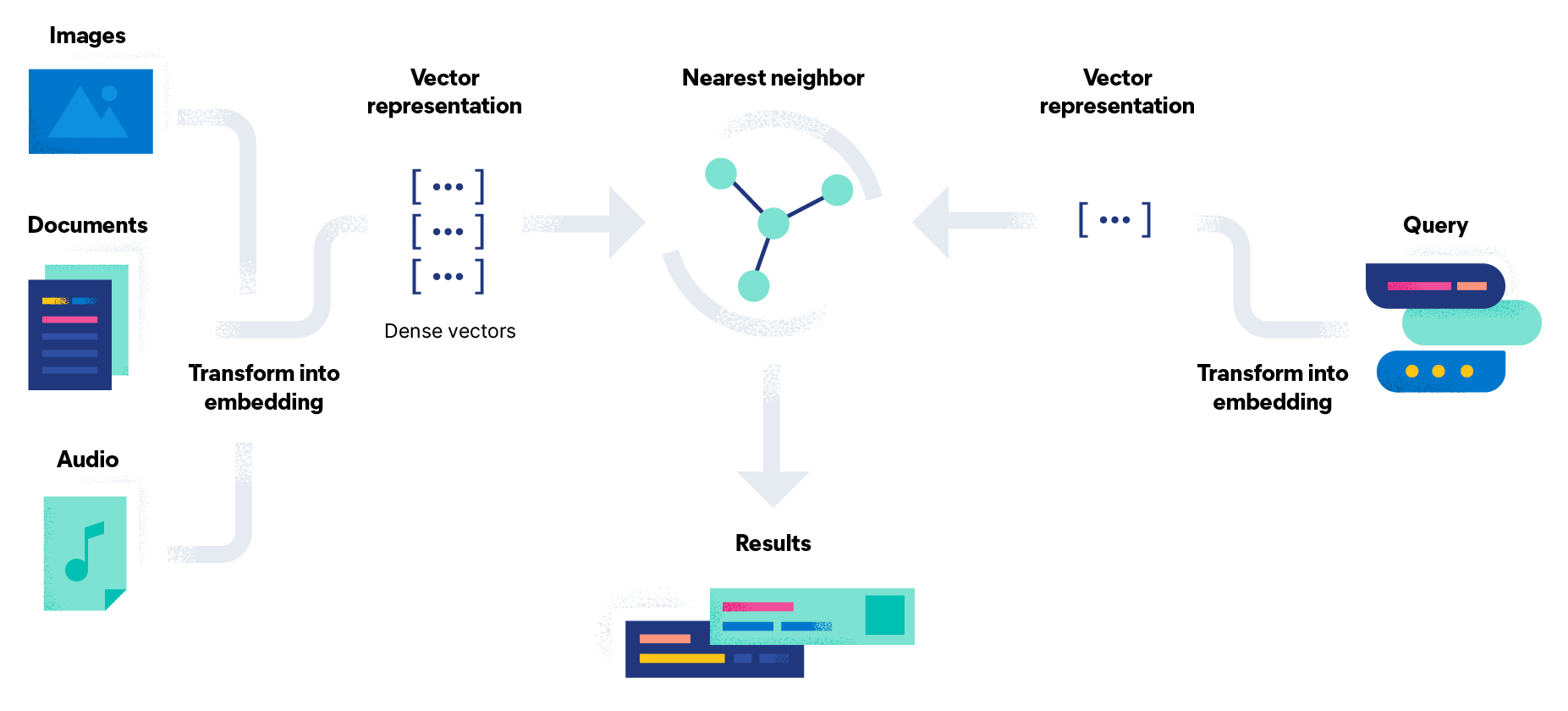
Elasticsearch 是一个非常强大且灵活的搜索和分析引擎。 虽然其主要用例围绕全文搜索,但它的用途广泛,足以用于各种其他功能。 其中一项引起许多开发人员和数据科学家关注的功能是使用 Elasticsearch 作为向量数据库。 随着 dense_vector 数据类型的出现以及利用 script_score 函数的能力,Elasticsearch 的功能已经扩展,可以促进向量相似性搜索。
向量搜索对于语义搜索的重要性
向量搜索彻底改变了我们理解和执行搜索操作的方式,特别是在语义搜索方面。 但在深入研究其意义之前,有必要了解句法 (syntatical) 搜索和语义 (semantic) 搜索之间的区别。
句法搜索与语义搜索
想象一下对 “apple alcoholic beverage” 进行搜索查询。 在句法搜索中,引擎将查找包含该确切短语的文档。 如果文档中的 “apple”、“alcoholic” 和 “beverage” 这些词不很接近或没有按照特定的顺序,则它可能不会排名靠前,甚至不会显示在结果中。 此方法是有限的,因为它严格依赖于查询的语法,并且可能会错过上下文相关的文档。
输入由向量搜索提供支持的语义搜索。 在这里,搜索引擎不是查看确切的短语,而是尝试理解查询背后的含义或意图。 在语义搜索领域,查询 “apple alcoholic beverage” 不仅仅会为你提供包含该确切短语的文档。 它将理解你查询的本质并获取与 “appletini”、“apple Brandy”、“apple bourbon” 等相关的文档。

为什么向量搜索对于语义搜索至关重要?
向量搜索在实现这种语义理解方面发挥着重要作用。 使用各种嵌入技术(例如 Word2Vec、BERT 或 FastText),可以将单词、短语甚至整个句子表示为高维空间中的向量。 在这个向量空间中,向量之间的 “距离” 表示语义相似度。 具有相似含义的单词或短语的向量彼此更接近。
当你搜索 “apple alcoholic beverage” 时,其向量表示可能接近于 “appletini”、“apple brandy” 或 “apple bourbon” 的向量。 然后,向量搜索获取这些语义相似的术语,从而实现对用户意图的语义理解。
嵌入模型背景下的向量空间
在较高的层次上,向量空间是一种数学结构,其中存在向量,并且可以执行加法和标量乘法等运算。 在嵌入模型和自然语言处理的背景下,向量空间用于将单词、句子甚至整个文档映射到数值向量
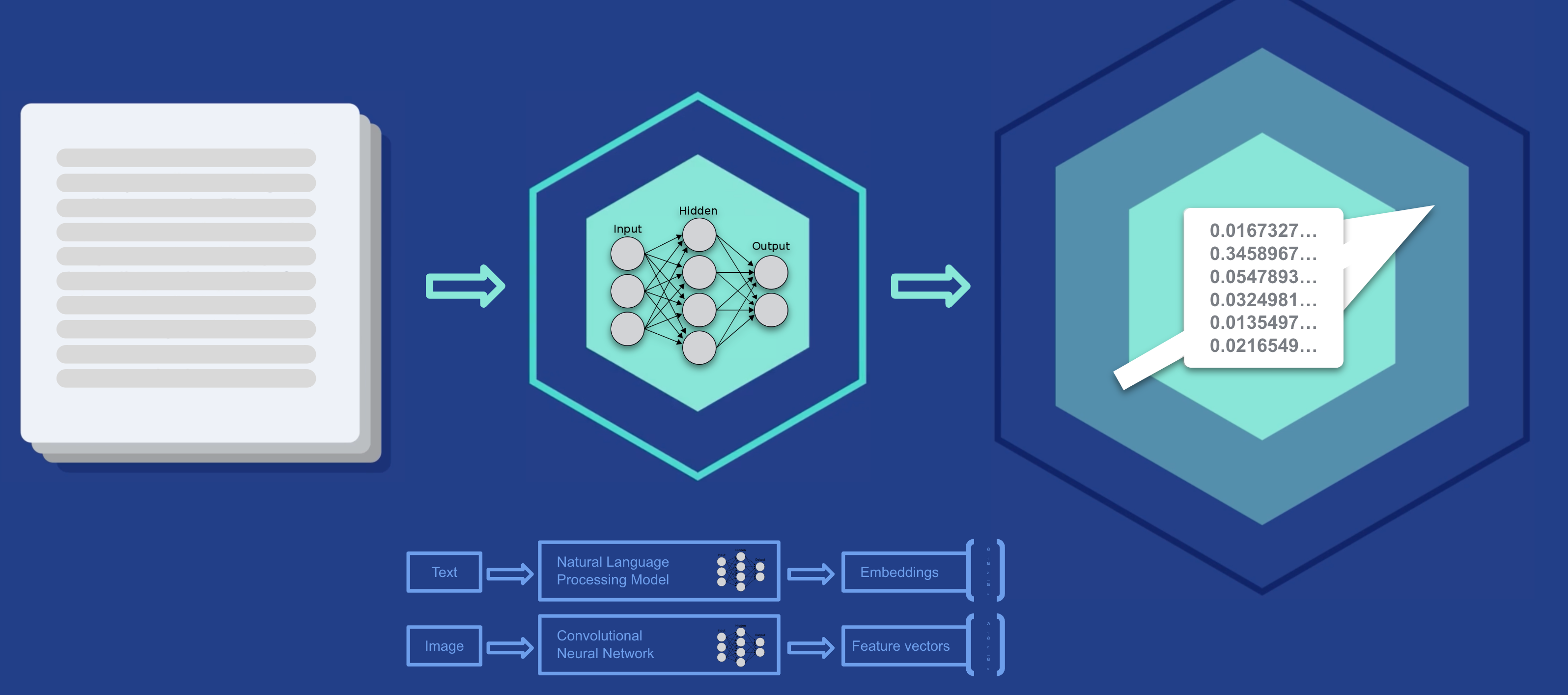
- 维度 (dimensionality):该空间中的每个维度都可以被视为数据的一个特征或特征。 对于单词或句子,这些维度可以捕获句法角色、语义含义、上下文或各种抽象语言属性。 维度越多,表示就越细致,但也需要更多的计算资源。
- 距离和相似度 (distance and similarity):将单词或句子转换为向量的主要原因是为了测量相似度。 在这些向量空间中,任何两个向量之间的 “距离”(通常使用余弦相似度或欧几里德距离等度量)可以指示这两个项目的相似程度。 向量越接近,它们就越相似。 例如,在训练有素的嵌入模型中,“king” 的向量减去 “man” 的向量加上 “woman” 的向量可能接近 “queen” 的向量,从而捕获关系语义。
- 训练和上下文 (training & context):嵌入模型(例如 Word2Vec 或 BERT)通过对大量文本数据进行训练来生成这些向量。 在此训练期间,模型学习以在向量空间中捕获上下文相似性(单词与其他单词的关系如何使用)的方式来表示单词或句子。 这就是为什么同义词或主题相关的单词最终在空间中具有彼此接近的向量。
向量搜索的机制
一旦有了一组向量(无论是单词、句子还是文档),进行向量搜索涉及:
- 查询转换:使用相同的嵌入模型将搜索查询转换为其向量表示。
- 距离计算:对于数据库中的每个项目(或子集,取决于优化),计算查询向量和项目向量之间的距离(或相似度得分)。
- 排名:根据项目与查询向量的距离或相似度对项目进行排名。 向量最接近查询向量的项目被认为是最相关的,并作为顶部结果返回。
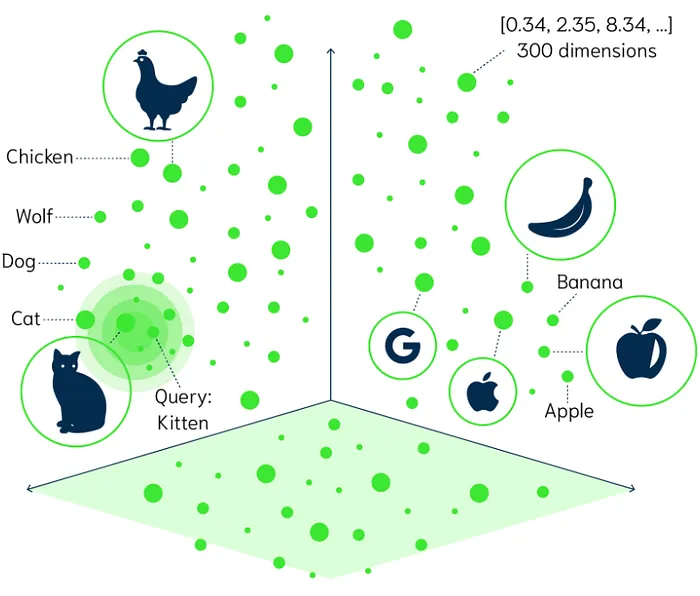
密集向量数据类型的兴起
Elasticsearch 的密集矢量数据类型旨在存储浮点值的向量。 这些向量通常用于机器学习,特别是对于在高维空间中将项目表示为向量的嵌入。 例如,来自 Word2Vec 等模型的词嵌入或来自 BERT 等模型的句子嵌入可以使用密集向量数据类型进行存储。
要存储向量,你可以定义如下映射:
{"properties": {"text-vector": {"type": "dense_vector","dims": 512}}
}这里,dims 表示向量的维数。
利用 script_score 的强大功能来实现向量相似度
为了执行向量相似性搜索,我们需要测量给定向量与数据库中其他向量的接近程度。 一种常见的方法是计算向量之间的点积。 Elasticsearch 中的 script_score 函数允许我们根据脚本计算文档的自定义分数。 通过使用此功能,我们可以计算查询向量与数据库中存储的向量之间的点积。
dotProduct 函数可以在 script_score 中使用,如下所示:
{"query": {"script_score": {"query": {"match_all": {}},"script": {"source": "dotProduct(params.queryVector, 'text-vector') + 1.0","params": {"queryVector": [...]}}}}
}这里,params.queryVector 是你要搜索的向量,“text-vector” 是指存储向量的字段。
为什么是“+1.0”?
精明的观察者可能会对在 dotProduct 函数之外添加 + 1.0 感到好奇。 由于 Elasticsearch 内的限制,这一添加至关重要:它无法处理负分数值。 通过添加 1.0,我们确保查询返回的所有得分值均保持为正值。
然而,重要的是要记住,这种加法可能会扭曲向量之间的相对相似性测量,特别是当点积接近于零时。 如果需要精确的相似度值,开发人员应在查询返回后手动对分数进行后处理,减去 1.0 加法以检索原始点积值。
Elasticsearch 相对于其他向量搜索库的优势
使用 Elasticsearch 作为向量数据库的不可否认的优势之一是其内置功能可以过滤特定数据子集的查询。 当你想要缩小搜索空间或当你的应用程序需要上下文感知向量搜索时,此功能非常有用。
相比之下,虽然 ChromaDB 和 Faiss 等其他专用矢量搜索库为纯向量搜索提供了无可挑剔的速度和效率,但它们缺乏 Elasticsearch 中提供的全功能查询功能。 例如,ChromaDB 确实允许查询元数据,但它仅限于字符串的精确匹配。 这种限制有时会阻碍复杂搜索场景中所需的灵活性和粒度。
将 Elasticsearch 丰富的查询环境与向量相似性搜索相结合意味着用户可以两全其美:基于矢量的精确结果,并通过使用细致入微的上下文感知过滤器对这些搜索进行分层的能力来增强。 这种合并使 Elasticsearch 成为需要深度和广度搜索功能的开发人员的一个令人信服的选择。
Elasticsearch 版本 8 的进步:值得注意的是,虽然版本 7 存在一些限制,但由原始 Elasticsearch 团队开发的最新 Elasticsearch 版本 8 已经合并了 HNSW,从而提高了其在向量搜索领域的功能。
Elasticsearch 进入向量搜索领域的旅程凸显了它的多功能性和适应性。 虽然最初并未设计为向量数据库,但其功能已通过诸如 dense_vector 数据类型和 script_score 函数等创新进行了扩展。 这些进步使 Elasticsearch 成为向量相似性搜索的可行工具,弥合了传统全文搜索与向量表示实现的语义理解的微妙领域之间的差距。Elasticsearch 的灵活性和广泛的查询功能使其在多方面的搜索场景中具有无价的价值。