文章目录
- 来源
- Transformer起源
- Self-Attention
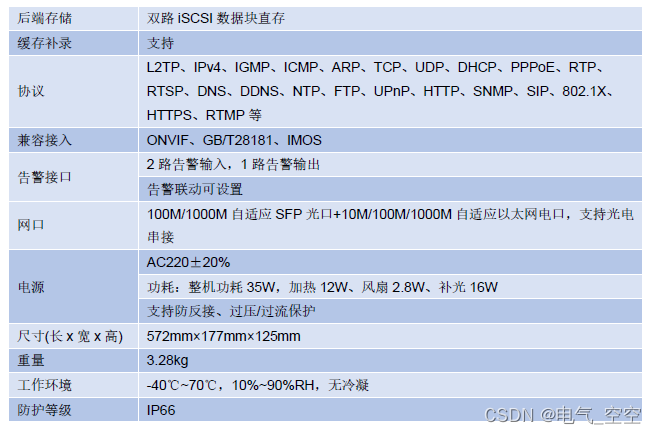
- 1. 求q、k、v
- 2. 计算 a ^ ( s o f t m a x 那块 ) \hat{a} (softmax那块) a^(softmax那块)
- 3. 乘V,计算结果
- Multi-Head Attention
- 位置编码
来源
b站视频
前天啥也不懂的时候点开来一看,各种模型和公式,直接头大,看完DASOU的视频后,重新来看,串起来了,一下子明白了,霹雳吧啦对细节有了更好的描述。
【DASOU视频记录】Transformer从零详细解读
Transformer起源
Transformer是2017年Google在Computation and Language上发表的,当时主要是针对自然语言处理领域提出的
Self-Attention
1. 求q、k、v
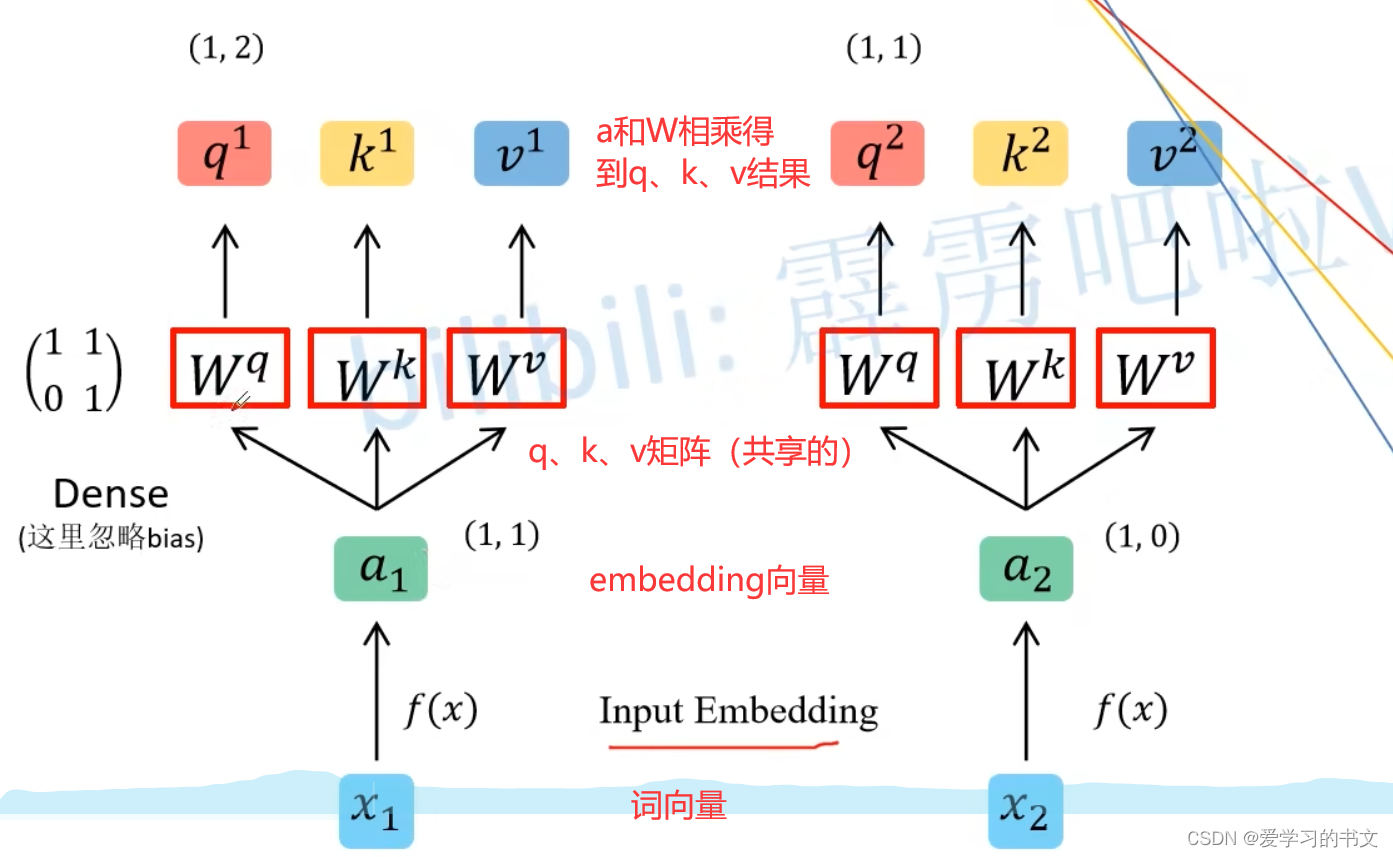
多个q、k、v可以叠在一起用矩阵来做
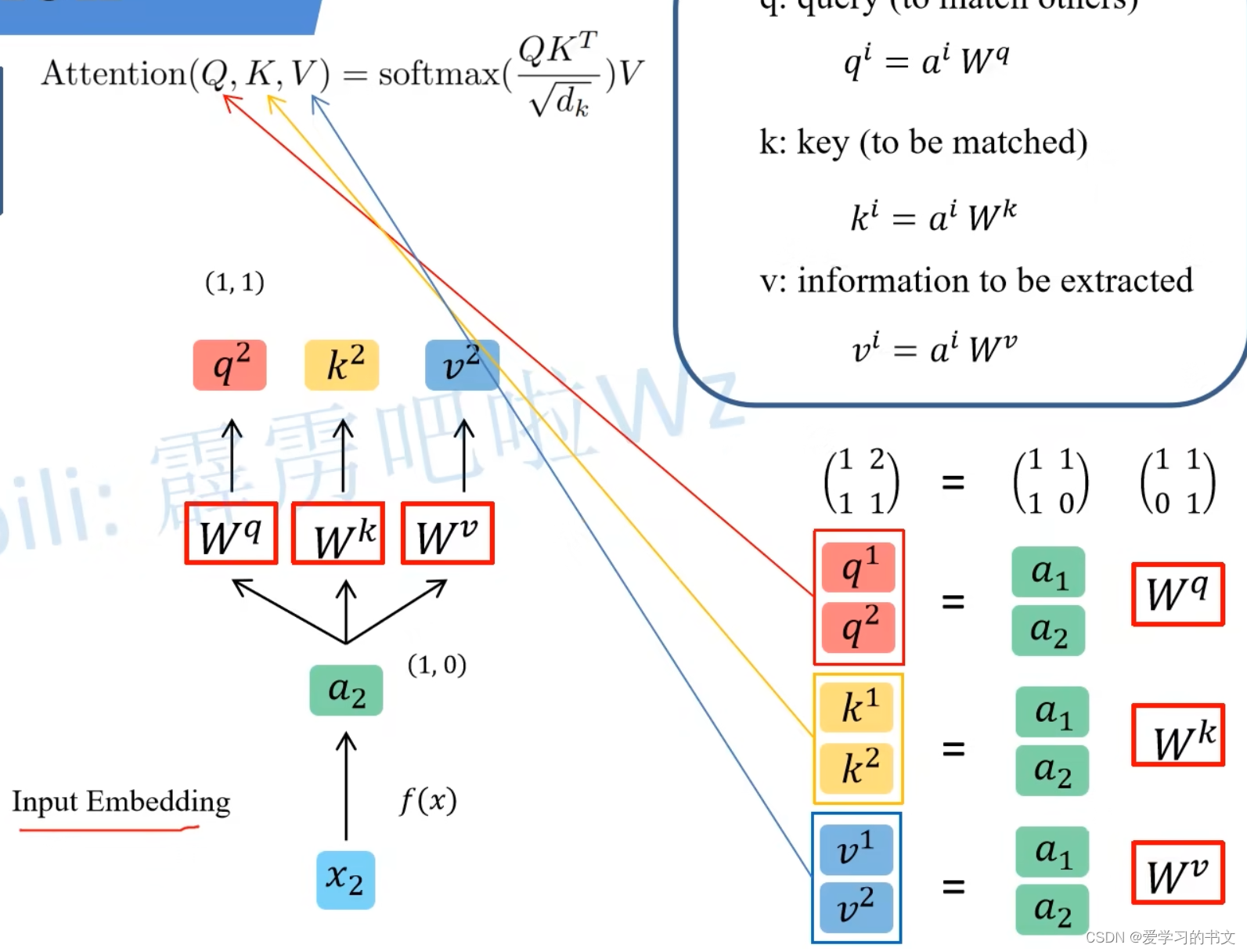
2. 计算 a ^ ( s o f t m a x 那块 ) \hat{a} (softmax那块) a^(softmax那块)
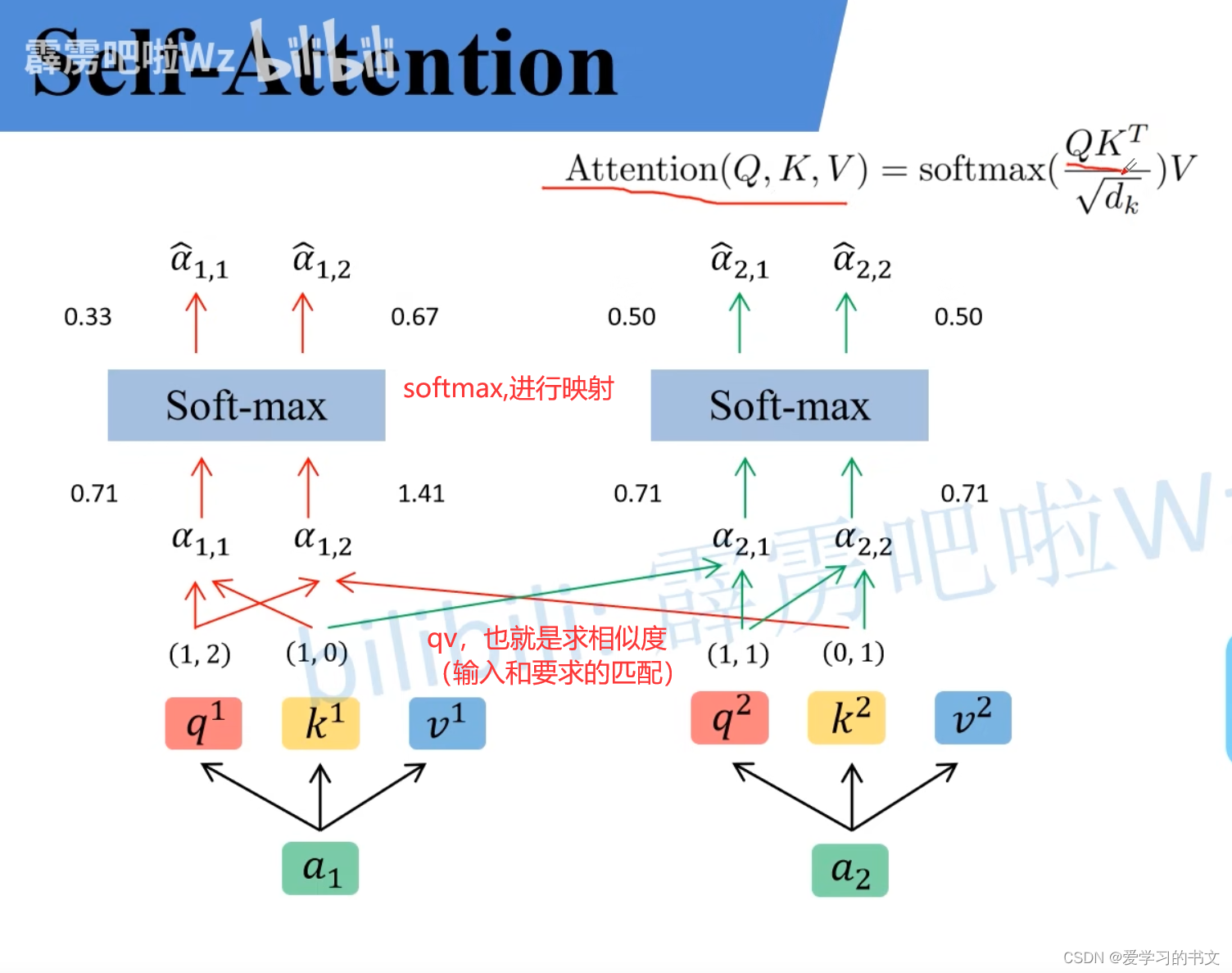 同样可以堆在一起计算
同样可以堆在一起计算

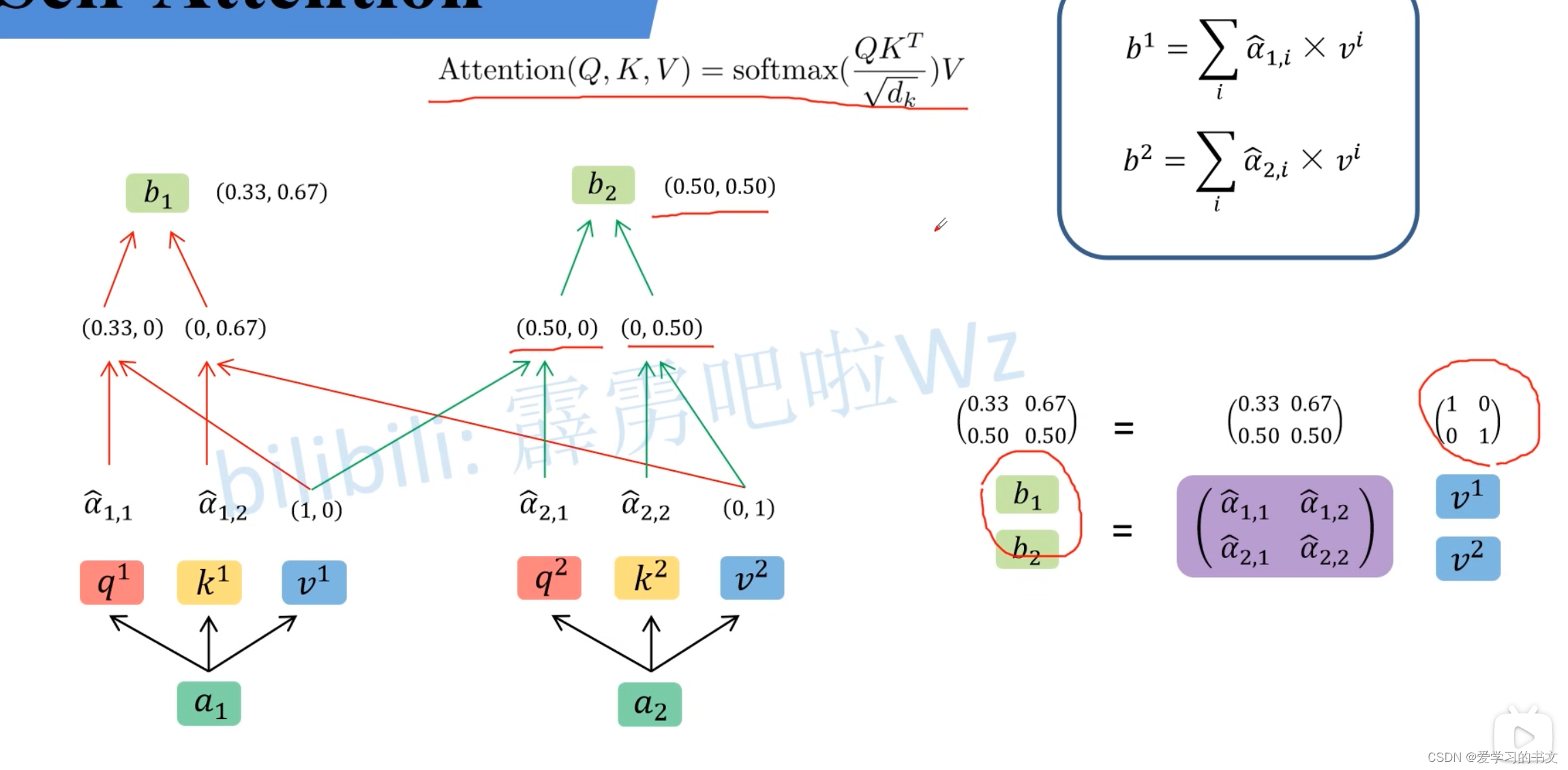
3. 乘V,计算结果
Multi-Head Attention
多头就是给定多套q、k、v矩阵
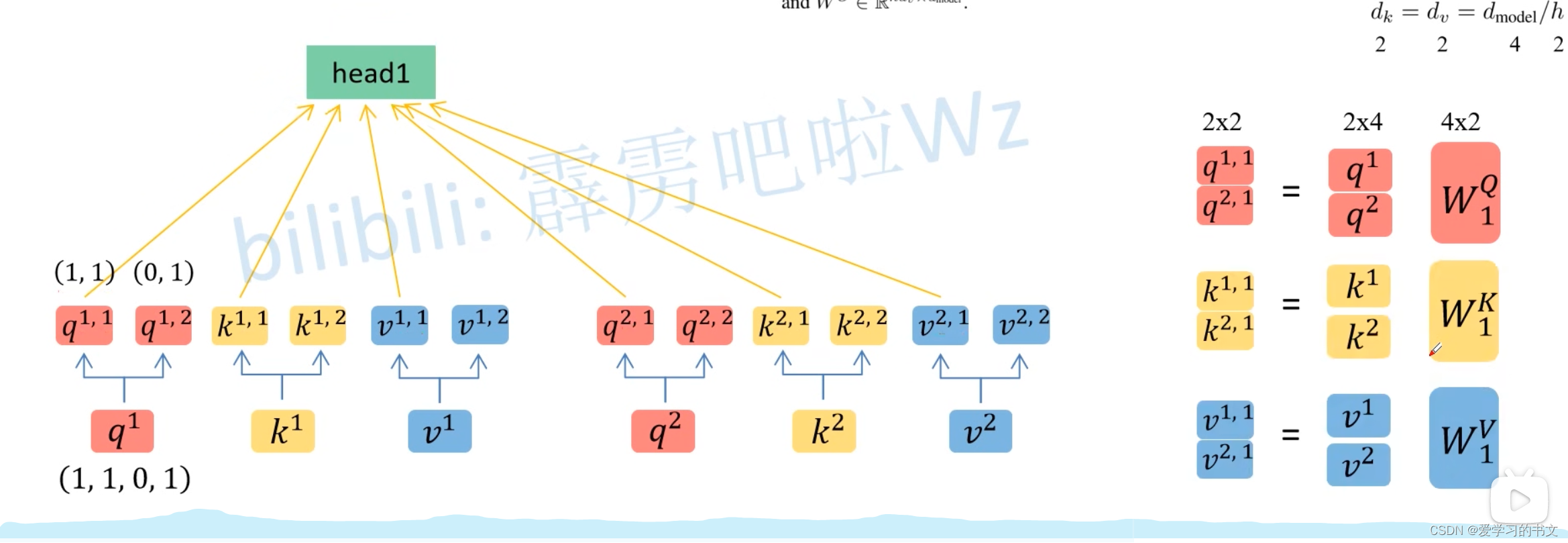
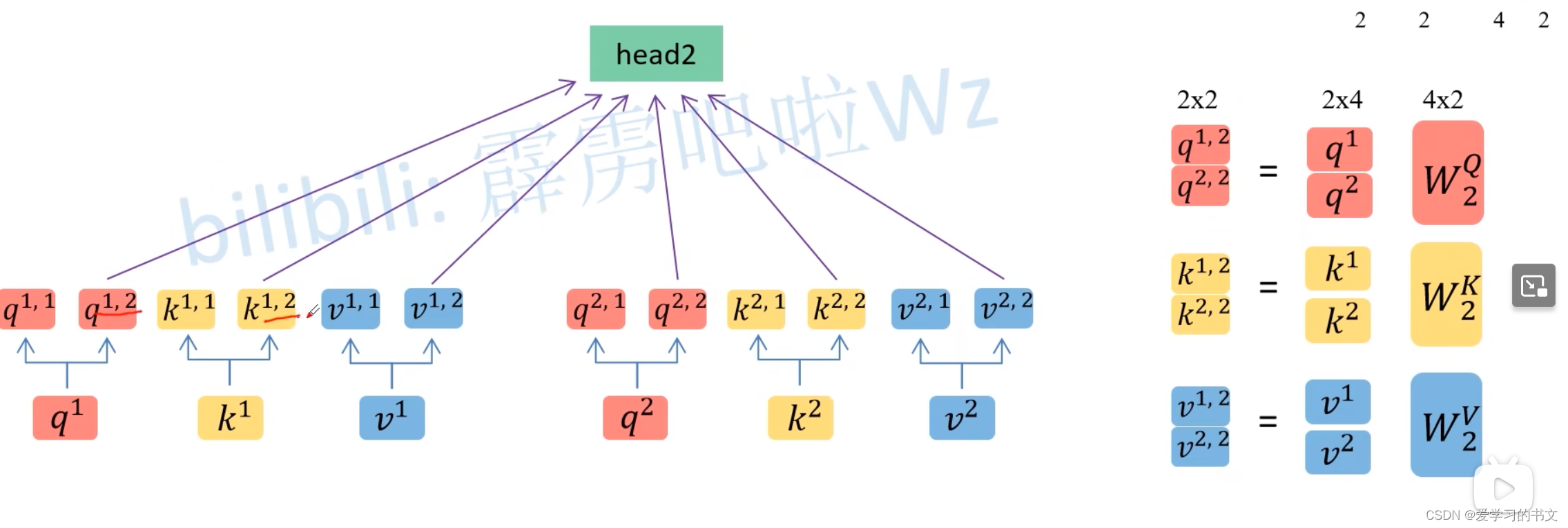 q第一个上标 表示第几个词向量,第二个上标 表示第几头
q第一个上标 表示第几个词向量,第二个上标 表示第几头
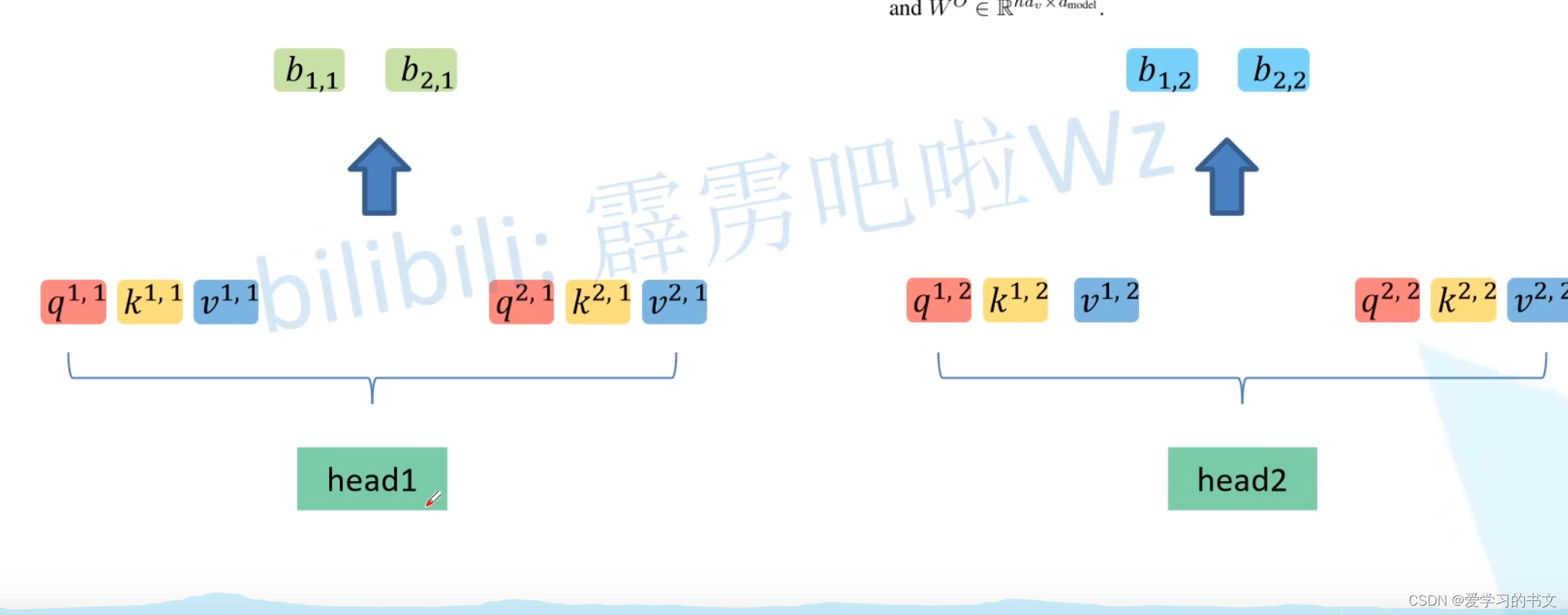

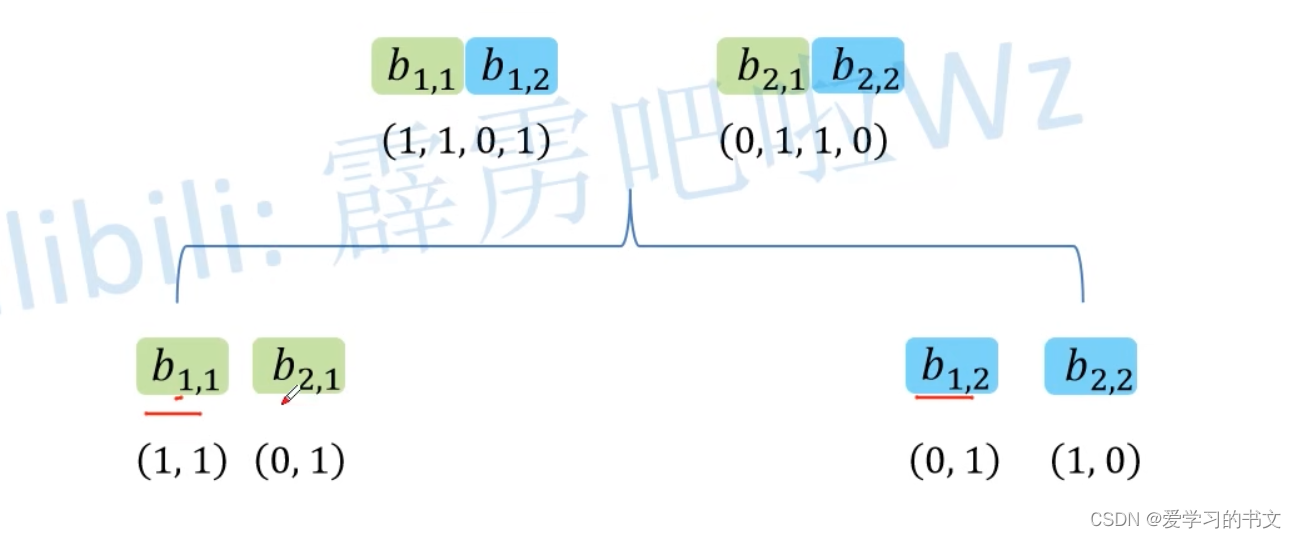
合并:将所有词向量合并在一起,得到x头个b

位置编码
如果没有位置编码,输入的顺序改变会导致不同的结果(不同线程抢占可能导致输入顺序改变。
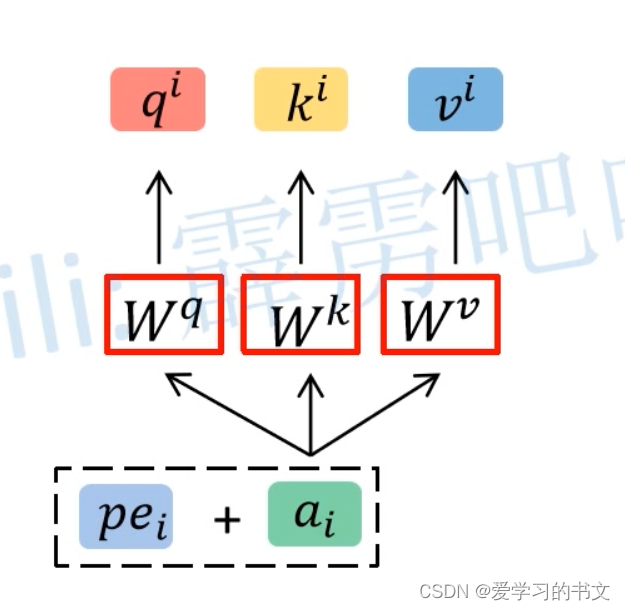
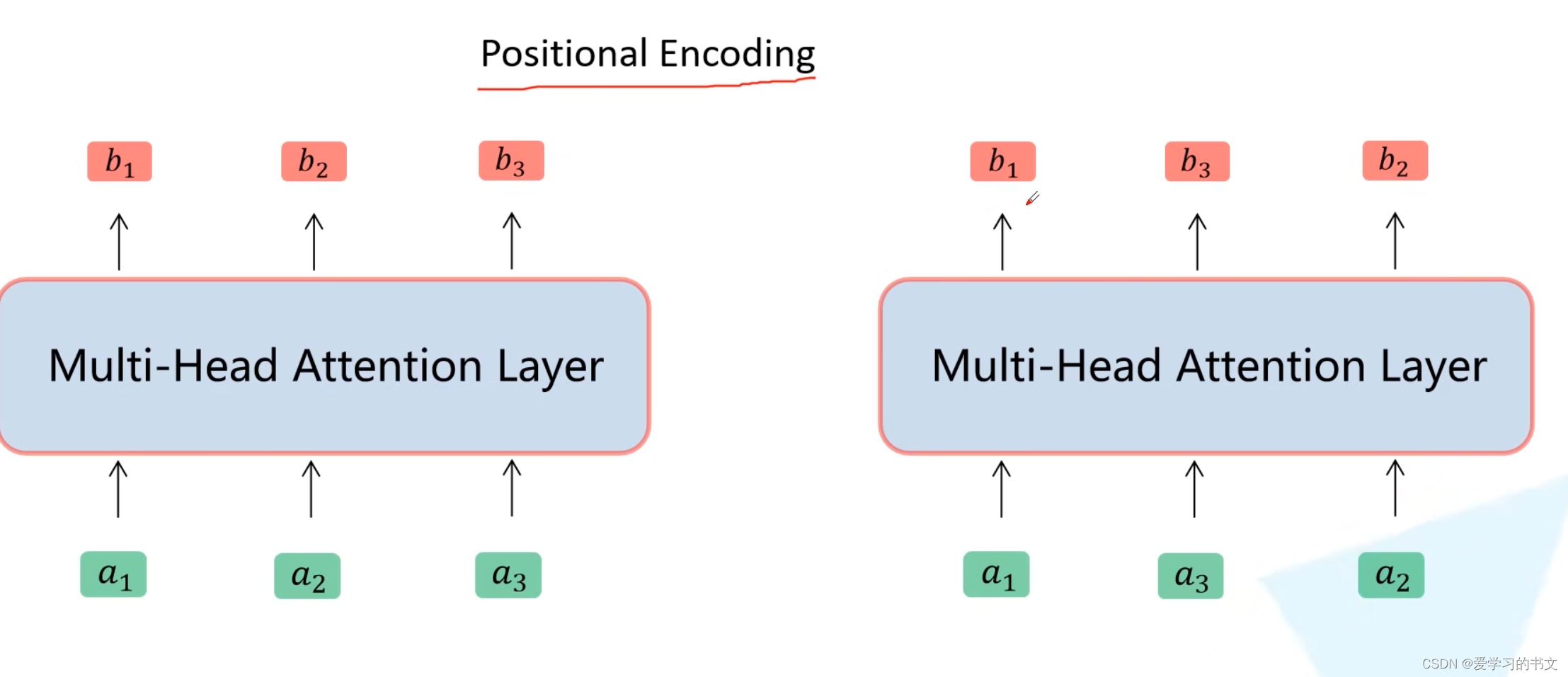 所以输入词向量embedding后加上位置编码结果作为模型输入。
所以输入词向量embedding后加上位置编码结果作为模型输入。
这个视频主要用小例子将公式过了一遍,可以用来加深对整体过程细节的认识和把控。