"都甩掉吧,我们的世界一定会更美好!其他不重要!"
前面呢,我们讲了如何在Linux环境下安装Protobuf所需的库,那么本篇的着眼点在于Protobuf的编写以及语法规则。
什么是proto3?
ProtocolBuffers语⾔版本3,简称proto3,是.proto⽂件最新的语法版本。proto3简化了ProtocolBuffers语⾔,既易于使⽤,⼜可以在更⼴泛的编程语⾔中使⽤。它允许你使⽤Java,C++,Python等多种语⾔⽣成protocolbuffer代码。
我们在创建一个.proto⽂件中时,需要首行使用,syntax = "proto3" 来指定文件的语法为proto3并且必须写在除去注释内容的第⼀⾏。如果没有指定,编译器会使⽤proto2语法。
![]()
一、Protobuf初始
(1) package包声明
package是⼀个可选的声明符,能表⽰.proto⽂件的命名空间,在项⽬中要有唯⼀性。它的作⽤是为了避免我们定义的消息出现冲突。

(2) 定义(message)消息
消息(message):要定义的结构化对象,我们可以给这个结构化对象中定义其对应的属性内容。
在实际的网络传输中,我们所谓的一些协议,如http/https、tcp、udp、websocket等等,说白了这些协议本质上就是一个一个的结构化数据。所以ProtoBuf就是以message的⽅式来⽀持我们定制协议字段。
.proto⽂件中定义⼀个消息类型的格式为:
# 消息类型命名规范:使⽤驼峰命名法,⾸字⺟⼤写
message msg_name{// 属性字段
}
(3) 定义消息字段
在message中我们可以定义其属性字段,字段定义格式为:
# 字段类型 字段名 = 字段唯⼀编号;
例如:
message PeopleInfo{string name = 1;int32 age = 2;
}当然字段类型会在之后细讲,这里面我们只是了解个大概。
(4) 编译.proto文件
我们仍然举例上一份proto代码的例子,要将它进行编译。
protoc [--proto_path=IMPORT_PATH] --cpp_out=DST_DIR path/to/file.proto
● protoc: 是Protobuf的编译器
● --proto_path: 指定被编译的.proto文件的所在目录,如果.proto文件不在当前目录下,就需要带上-I进行指明。
● --cpp_out=: 编译后生产cpp文件
● DST_DIR: 编译后生成的文件的目录路径
● path/to/file.proto: 要编译的.proto文件
编译.proto文件之后,会生成什么呢?
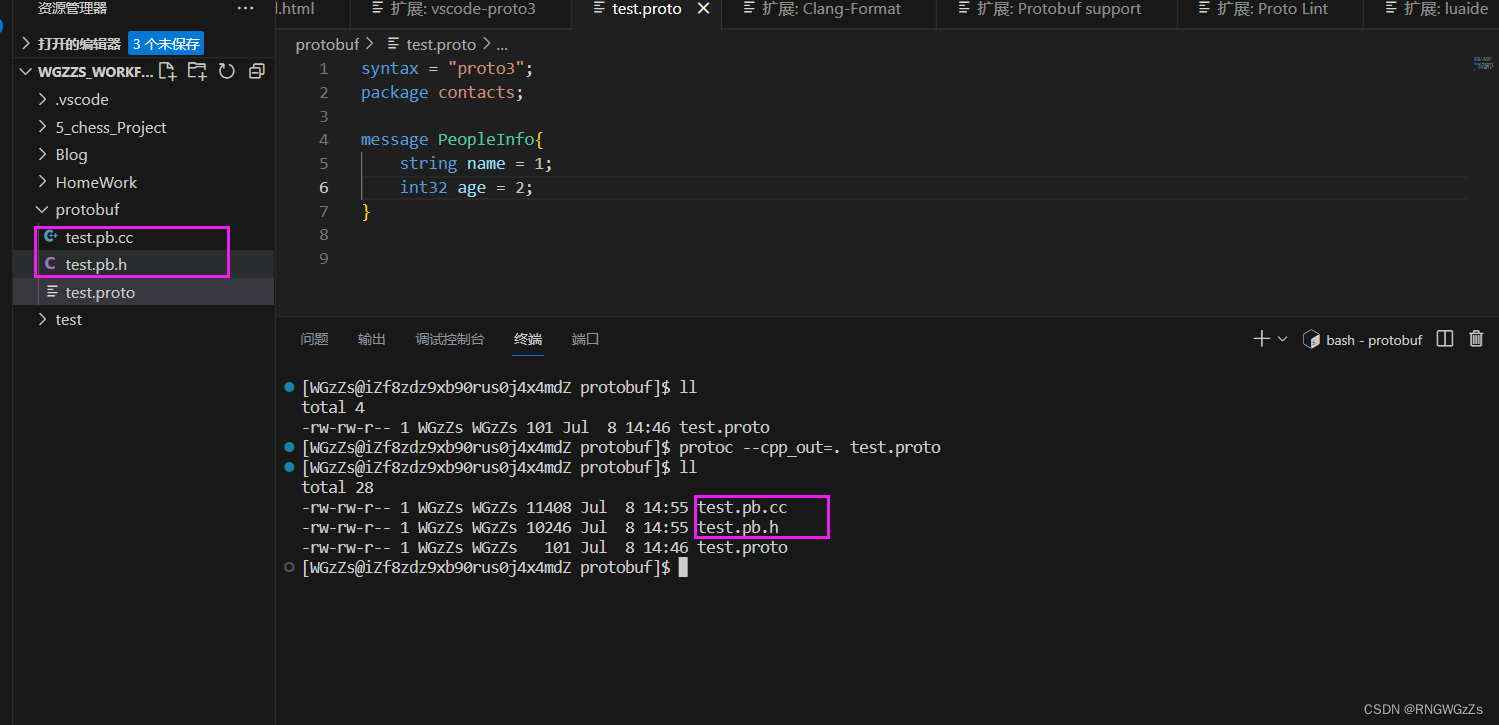
我们对举例的那份代码进行编译,立马就生成了两个新的文件:
test.pb.cc test.pb.h,这难道不就是C++文件的后缀格式?
以及,我们发现我们定义的message消息,最终会被用来构造一个类,并为获取该消息字段提供了一定的方法。

对于编译⽣成的C++代码,包含了以下内容:
• 对于每个message,都会⽣成⼀个对应的消息类。
• 在消息类中,编译器为每个字段提供了获取和设置⽅法,以及⼀下其他能够操作字段的⽅法。
• 编辑器会针对于每个 .proto ⽂件⽣成 .h 和 .cc ⽂件,分别⽤来存放类的声明与类的实现。
test.pb.h部分代码展⽰
(5) 序列化与反序列化
对现在我了解到了protobuf C++做出数据存储的本质是在于,生成另一个新的.cc\.h文件,并通过里面的类来重新定义message里的消息字段,可是作为数据交换格式语言,你现在扯这么多还没有到如何进行序列化、反序列化?那这个方法在哪里有呢?
在消息类的⽗类MessageLite 中,提供了读写消息实例的⽅法,包括序列化⽅法和反序列化⽅法。
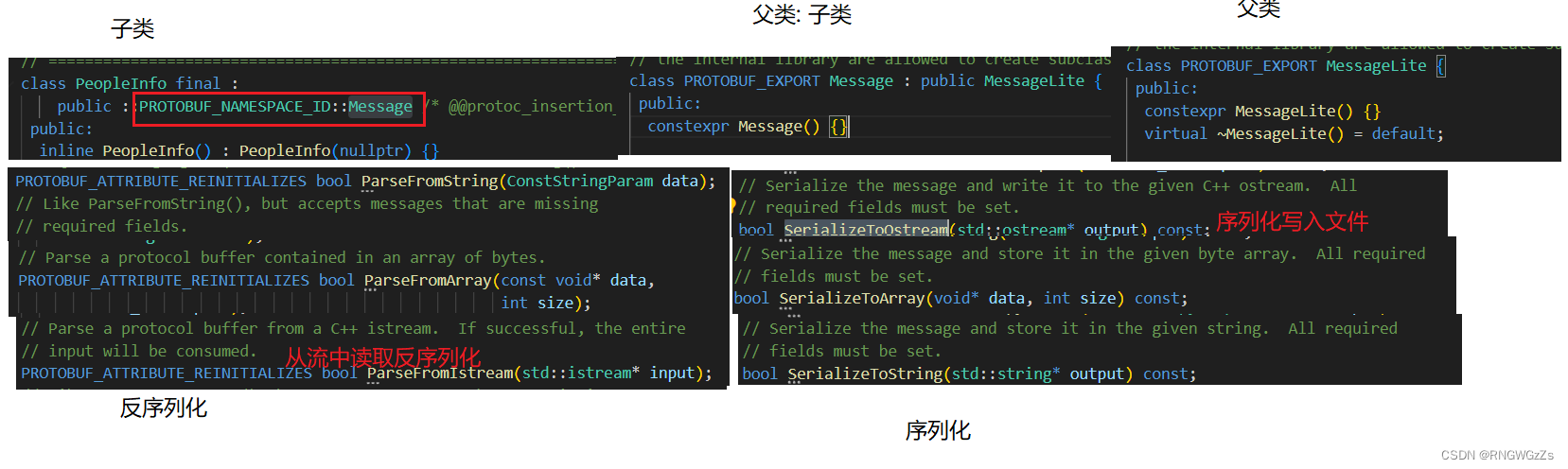 注:
注:
• 序列化的结果为⼆进制字节序列,⽽⾮⽂本格式。
• 以上三种序列化的⽅法没有本质上的区别,只是序列化后输出的格式不同,可以供不同的应⽤场景使⽤。
• 序列化的API函数均为const成员函数,因为序列化不会改变类对象的内容,⽽是将序列化的结果保存到函数⼊参指定的地址中。
• 详细messageAPI可以参⻅: 这里
序列化、反序列化如何使用呢?
说了这么多,但是你就是不会使用,那也是白搭。
#include "test.pb.h"#include <iostream>
#include <string>
using namespace std;int main()
{string serlization_people_info;// 序列化{Contacts::PeopleInfo pf;/*message PeopleInfo{string name = 1;int32 age = 2;}*/pf.set_name("张三");pf.set_age(18);// 进行序列化if (!pf.SerializeToString(&serlization_people_info)){std::cout << "序列化失败" << std::endl;return;}std::cout << "序列化成功: " << serlization_people_info << std::endl;}// 反序列化{Contacts::PeopleInfo dpf;if (!dpf.ParseFromString(serlization_people_info)){std::cout << "反序列化失败" << std::endl;return;}// 序列化结果cout << "姓名: " << dpf.name() << endl;cout << "年龄: " << dpf.age() << endl;}return 0;
}进行编译,这里使用的makefile:
test:test.cc test.pb.cc
g++ -o $@ $^ -std=c++11 -lprotobuf
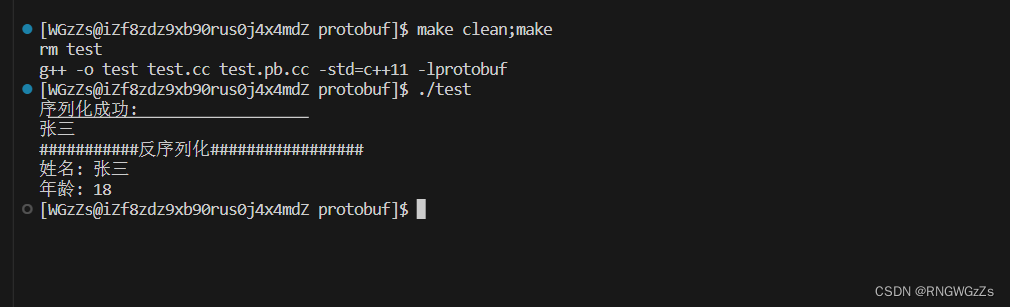
为什么我们打印"serlization_people_info"是这样的结果呢? 是因为ProtoBuf是把联系⼈对象序列化成了⼆进制序列,但这⾥⽤string来作为接收⼆进制序列的容器,因此在终端打印的时候会有换⾏等⼀些乱码显⽰。
所以相对于对于xml和JSON来说,因为被编码成⼆进制,破解成本增⼤,ProtoBuf编码是相对安全的。
二、proto3语法规则详解
(1) 字段规则
消息的字段可以⽤下⾯⼏种规则来修饰:
● singular:消息中可以包含该字段零次或⼀次(不超过⼀次)。proto3语法中,字段默认使⽤该规则。
● repeated:消息中可以包含该字段任意多次(包括零次),其中重复值的顺序会被保留。可以理解为定义了⼀个数组。
message PeopleInfo{string name = 1;int32 age = 2;// 一个人的电话号码可以重复repeated string phone_number = 3;
}
(2) 消息类的定义与嵌套
在单个.proto⽂件中可以定义多个消息体,且⽀持定义嵌套类型的消息(任意多层)。每个消息体中的字段编号可以重复。
// 嵌套写法
message PeopleInfo{string name = 1;int32 age = 2;message Phone{string number = 1;}
}// 非嵌套
message Phone{string number = 1;
}message PeopleInfo{string name = 1;int32 age = 2;
}①消息类型可作为字段类型使⽤:
// 嵌套写法
message PeopleInfo{string name = 1;int32 age = 2;message Phone{string number = 1;}// 消息类型repeated Phone phone = 3;
}
② 可导⼊其他.proto⽂件的消息并使⽤
syntax = "proto3";
package contacts;
import "phone.proto"; // 使⽤ import 将 phone.proto ⽂件导⼊进来 !!!message PeopleInfo {string name = 1;int32 age = 2;// 引⼊的⽂件声明了package,使⽤消息时,需要⽤ ‘命名空间.消息类型’ 格式repeated phone.Phone phone = 3;
}三、Proto3类型
(1) 数值类型
字段类型分为:标量数据类型和特殊类型(包括枚举、其他消息类型等)。
该表格展⽰了定义于消息体中的标量数据类型,以及编译.proto⽂件之后⾃动⽣成的类中与之对应的字段类型。在这⾥展⽰了与C++语⾔对应的类型。
| .proto Type | Notes | C++ Type |
| double | double | |
| float | float | |
| int32 | 使用变长编码[1],负数的编码效率较低——若字段可能为负值,应使用sint32替代。 | int32 |
| int64 | 使用变长编码[1],负数的编码效率较低——若字段可能为负值,应使用sint64替代。 | int64 |
| uint32 | 使用变长编码[1] | uint32 |
| uint64 | 使用变长编码[1] | uint64 |
| sint32 | 使用变长编码[1],有符号整型。负值的编码效率高于常规的int32 | int32 |
| sint64 | 使用变长编码[1],有符号整型。负值的编码效率高于常规的int64 | int64 |
| fixed32 | 定长4字节,若值常大于2^28次方,则会比uint32更高效 | uint32 |
| fixed64 | 定长8字节,若值常大于2^56次方,则会比uint64更高效 | uint64 |
| sfixed32 | 定长4字节 | int32 |
| sfixed64 | 定长8字节 | int64 |
| bool | bool | |
| string | 包括UTF-8和ASCII编码的字符串,长度不能超过2^32 。 | string |
| bytes | 可包含任意的字节序列但长度不能超过2^32 | string |
注:"[1]变⻓编码是指:经过protobuf编码后,原本4字节或8字节的数可能会被变为其他字节数"
(2) 特殊类型
① enum枚举类型:
语法⽀持我们定义枚举类型并使⽤。在.proto⽂件中枚举类型的书写规范为:
枚举类型名称:
使⽤驼峰命名法,⾸字⺟⼤写。
常量值名称:
全⼤写字⺟,多个字⺟之间⽤ _ 连接。
enum Phone_Type{// 移动MP = 0;// 固定TEL = 1;
}注:
● 0值常量必须存在,且要作为第⼀个元素。这是为了与proto2的语义兼容:第⼀个元素作为默认值,且值为0.
● 枚举类型可以在消息外定义,也可以在消息体内定义(嵌套).
● 枚举的常量值在32位整数的范围内。但因负值⽆效因⽽不建议使⽤(与编码规则有关).
● 同级(同层)的枚举类型,各个枚举类型中的常量不能重名.
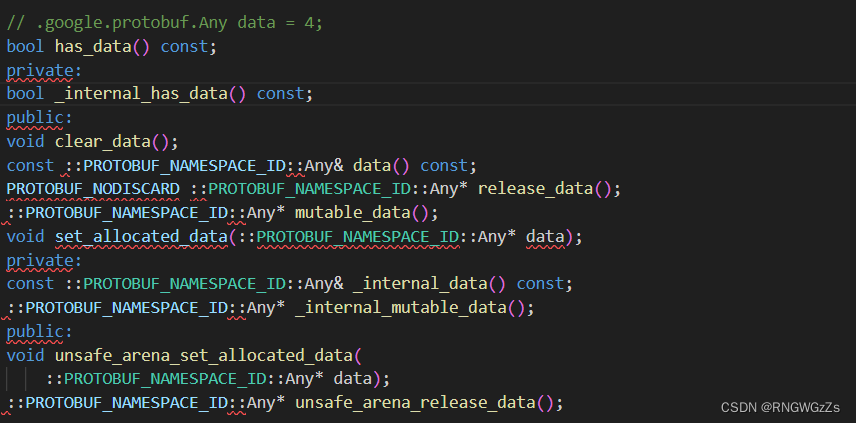
② Any类型:
字段还可以声明为Any类型,可以理解为泛型类型。使⽤时可以在Any中存储任意消息类型。Any类型的字段也⽤repeated来修饰。
Any类型是google已经帮我们定义好的类型,在安装ProtoBuf时,其中的include⽬录下查找所有google已经定义好的.proto⽂件。
// 导入文件
import "google/protobuf/any.proto";message PeopleInfo{string name = 1;int32 age = 2;message Phone{string number = 1;}repeated Phone phone = 3;// Any字段google.protobuf.Any data = 4;
}Any类型字段有独有的方法:
● 设置和获取:获取⽅法的⽅法名称与⼩写字段名称完全相同。设置⽅法可以使⽤mutable_⽅
法,返回值为Any类型的指针,这类⽅法会为我们开辟好空间,可以直接对这块空间的内容进⾏
修改。
③ oneof类型:
如果消息中有很多可选字段,并且将来同时只有⼀个字段会被设置,那么就可以使⽤ oneof 加强这个⾏为,也能有节约内存的效果。
message PeopleInfo{string name = 1;int32 age = 2;message Phone{string number = 1;}oneof other_contact{string qq = 5;string wx = 6;}
}注:
● 可选字段中的字段编号,不能与⾮可选字段的编号冲突.
● 不能在oneof中使⽤repeated字段.
● 将来在设置oneof字段中值时,如果将oneof中的字段设置多个,那么只会保留最后⼀次设置的成员,之前设置的oneof成员会⾃动清除.
④ map类型:
语法⽀持创建⼀个关联映射字段,也就是可以使⽤map类型去声明字段类型,格式为:
"map<key_type, value_type> map_field = N"
要注意的是:
● key_type是除了float和bytes类型以外的任意标量类型,value_type 可以是任意类型.
● map字段不可以⽤repeated修饰.
● map中存⼊的元素是⽆序的.
四、Proto3其他项
(1) 默认值
反序列化消息时,如果被反序列化的⼆进制序列中不包含某个字段,反序列化对象中相应字段时,就会设置为该字段的默认值。不同的类型对应的默认值不同:
• 对于字符串,默认值为空字符串。
• 对于字节,默认值为空字节。
• 对于布尔值,默认值为false。
• 对于数值类型,默认值为0。
• 对于枚举,默认值是第⼀个定义的枚举值,必须为0。
• 对于消息字段,未设置该字段。它的取值是依赖于语⾔。
• 对于设置了repeated的字段的默认值是空的(通常是相应语⾔的⼀个空列表)。
• 对于 消息字段 、 oneof字段 和 any字段 ,C++和Java语⾔中都有has_⽅法来检测当前字段是否被设置。
(2) 更新消息
有时候,因为场景的变化现有的消息类型已经不再满⾜我们的需求,例如需要扩展⼀个字段,在不破坏任何现有代码的情况下更新消息类型⾮常简单。遵循如下规则即可:
● 禁⽌修改任何已有字段的字段编号。
● 若是移除⽼字段,要保证不再使⽤移除字段的字段编号。正确的做法是保留字段编号(reserved之后会细讲),以确保该编号将不能被重复使用。不建议直接删除或注释掉字段。
● int32,uint32,int64,uint64和bool是完全兼容的。可以从这些类型中的⼀个改为另⼀个,⽽不破坏前后兼容性。若解析出来的数值与相应的类型不匹配,会采⽤与C++⼀致的处理⽅案(例如,若将64位整数当做32位进⾏读取,它将被截断为32位)。
● sint32和sint64相互兼容但不与其他的整型兼容。● string和bytes在合法UTF-8字节前提下也是兼容的。
● bytes包含消息编码版本的情况下,嵌套消息与bytes也是兼容的。
● fixed32与sfixed32兼容,fixed64与sfixed64兼容。● enum与int32,uint32,int64和uint64兼容(注意若值不匹配会被截断)。但要注意当反序列化消息时会根据语⾔采⽤不同的处理⽅案:例如,未识别的proto3枚举类型会被保存在消息中,但是当消息反序列化时如何表⽰是依赖于编程语⾔的。整型字段总是会保持其的值。
● oneof
◦ 将⼀个单独的值更改为新oneof类型成员之⼀是安全和⼆进制兼容的。
◦ 若确定没有代码⼀次性设置多个值那么将多个字段移⼊⼀个新oneof类型也是可⾏的。
◦ 将任何字段移⼊已存在的oneof类型是不安全的。
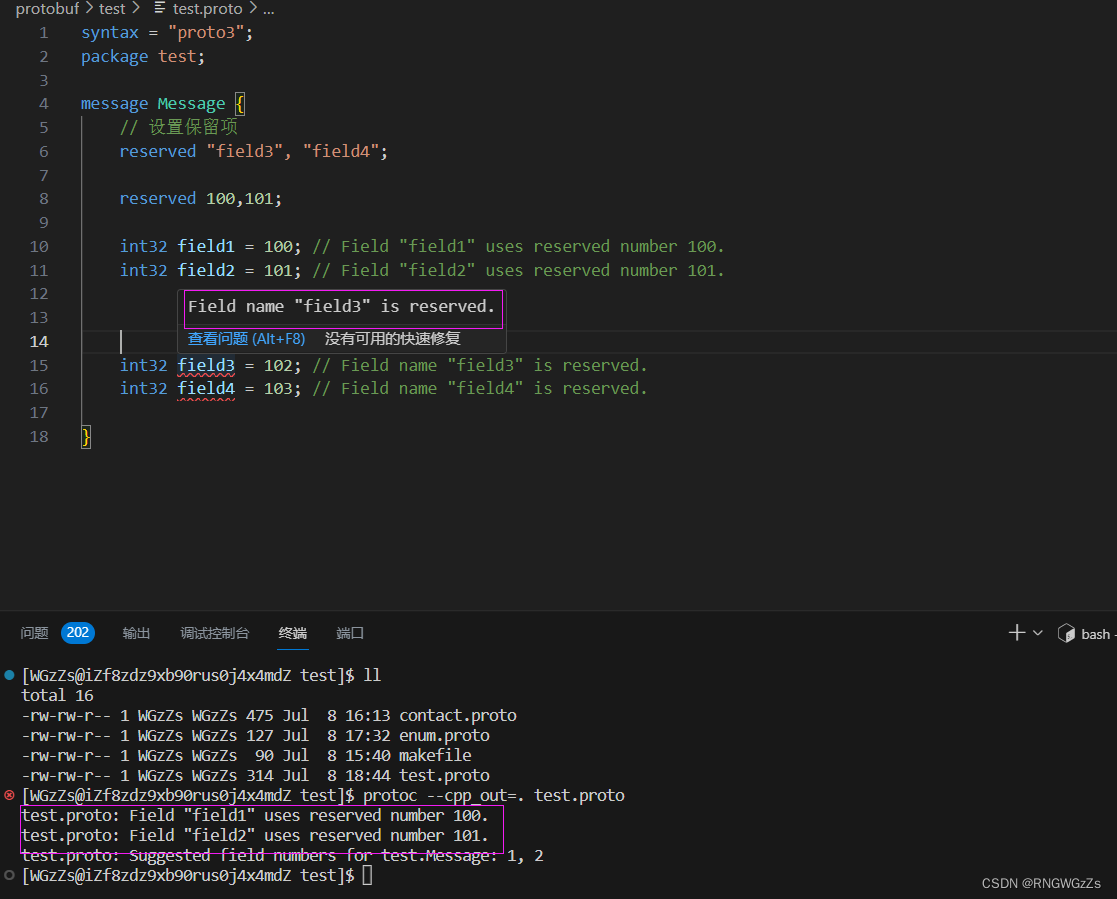
(3) 保留字段 reserved
如果通过"删除"或"注释掉"字段来更新消息类型,未来的⽤⼾在添加新字段时,有可能会使⽤以前已经存在,但已经被删除或注释掉的字段编号。
确保不会发⽣这种情况的⼀种⽅法是:使⽤ reserved 将指定 ”字段的编号” 或 ”名称” 设置为保留项。当我们再使⽤这些编号或名称时,protocolbuffer的编译器将会警告这些编号或名称不可⽤。
就像这样:
总结:
① protbuf通过定义message类完成对数据的格式化存储,其序列化、反序列化的方法是继承自父类MessageLite里的。
② proto3语法的类型可以分为两类: 标量数据类型和特殊类型(enum\map\oneof\any)。
③ 如果存在没有值的类型,protobuf会根据其类型填补默认值,并且如果确认旧的"编号"或"名称"不会再继续使用,请使用reserved保留字段。
本篇到此结束,感谢你的阅读。
祝你好运,向阳而生~


![[期末网页作业]-精仿华为官网10个网页(html+css+js)](https://img-blog.csdnimg.cn/ec54a795084a48d0b583f4d236a371ac.png)