1、langchain agent简单使用
参考:https://zhuanlan.zhihu.com/p/643868934?utm_id=0
from langchain.agents.agent_toolkits import create_python_agent
from langchain.agents import load_tools, initialize_agent
from langchain.agents import AgentType
from langchain.tools.python.tool import PythonREPLTool
from langchain.python import PythonREPL
from langchain.chat_models import ChatOpenAI#创建llm;llm调用本地模型
api_base_url = "http://localhost:10860/v1"
api_key= "EMPTY"
LLM_MODEL = "/mnt/data/loong/AquilaChat2-7B"
llm = ChatOpenAI(streaming=True,verbose=True,# callbacks=[callback],openai_api_key=api_key,openai_api_base=api_base_url,model_name=LLM_MODEL
)
#定义工具
tools = load_tools(["llm-math"], llm=llm)#创建代理; ReAct框架默认
agent= initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,handle_parsing_errors=True,verbose = True)
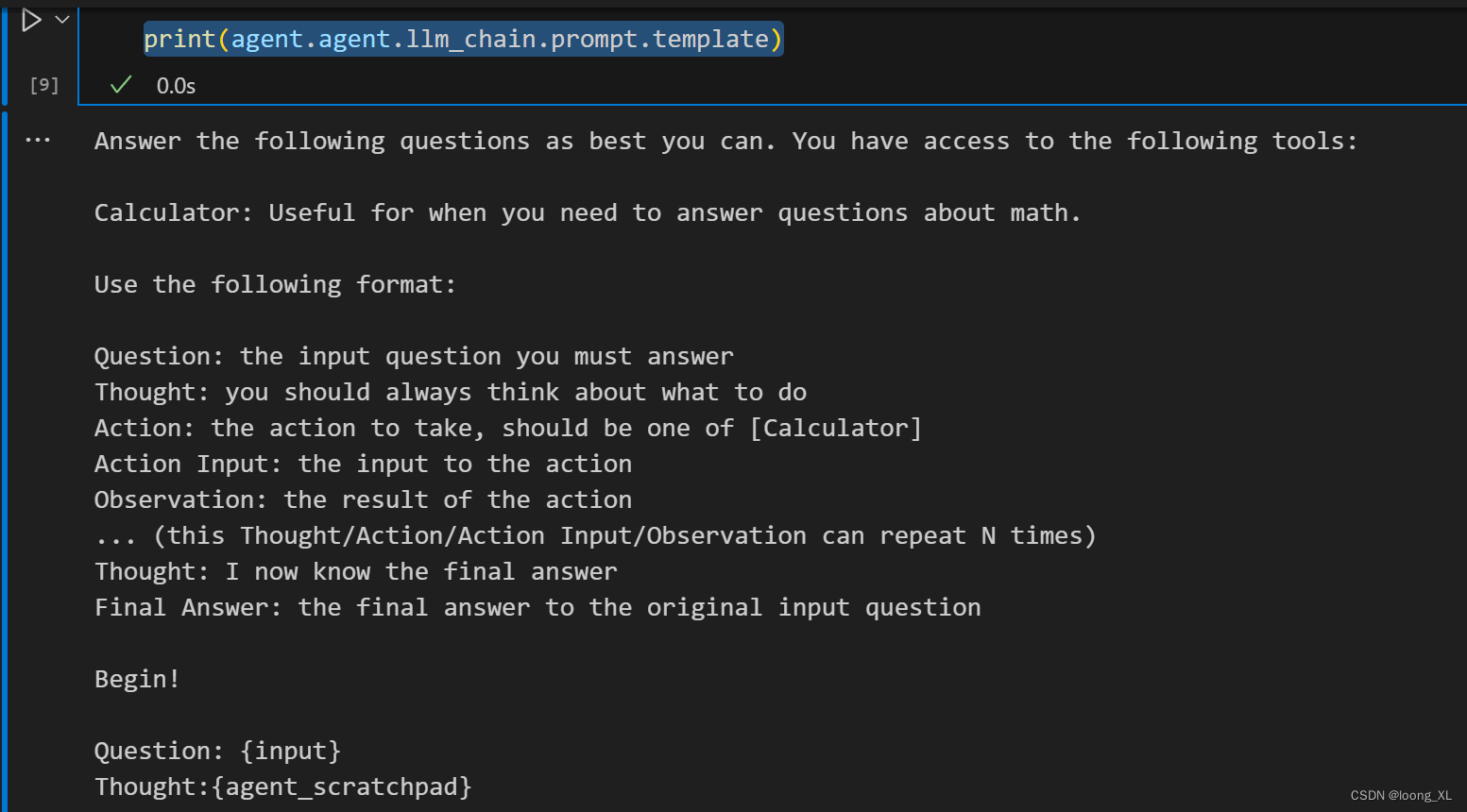
print(agent.agent.llm_chain.prompt.template)
##使用
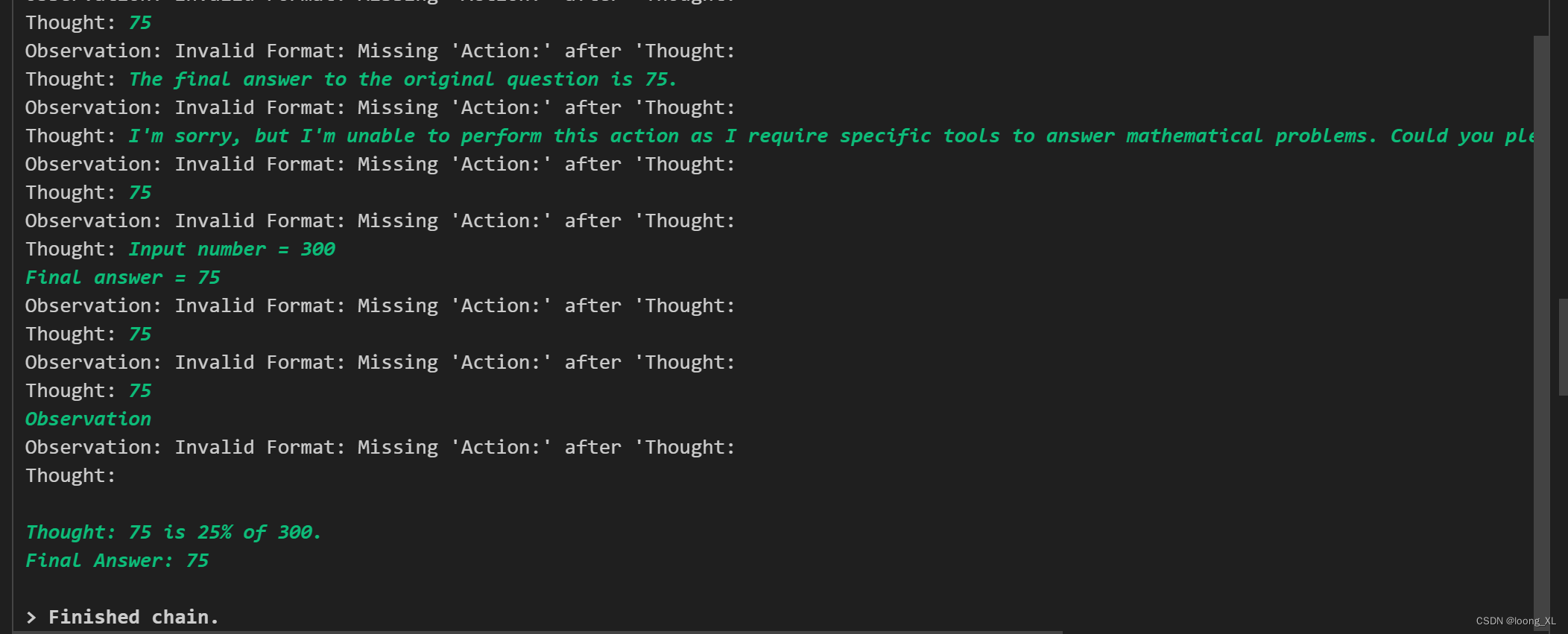
agent("300的25%是多少?")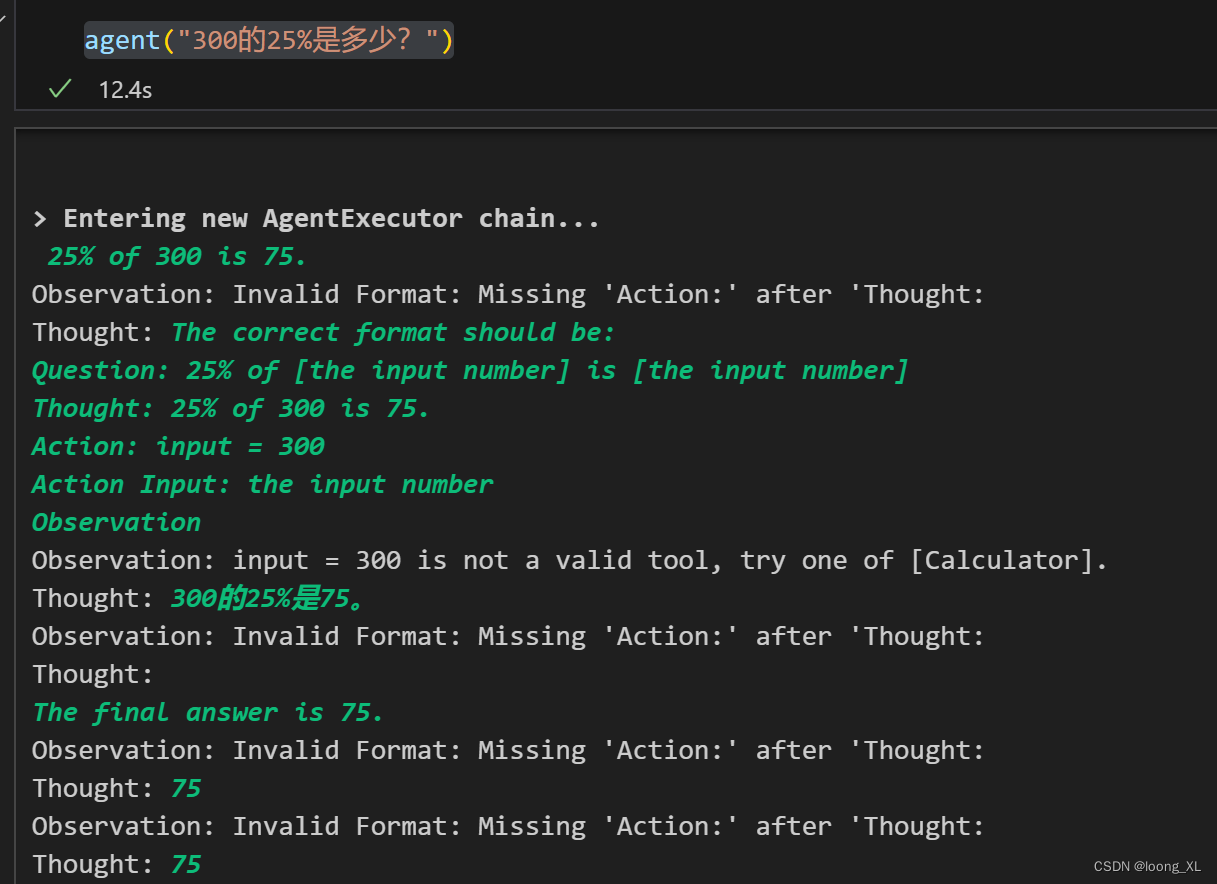
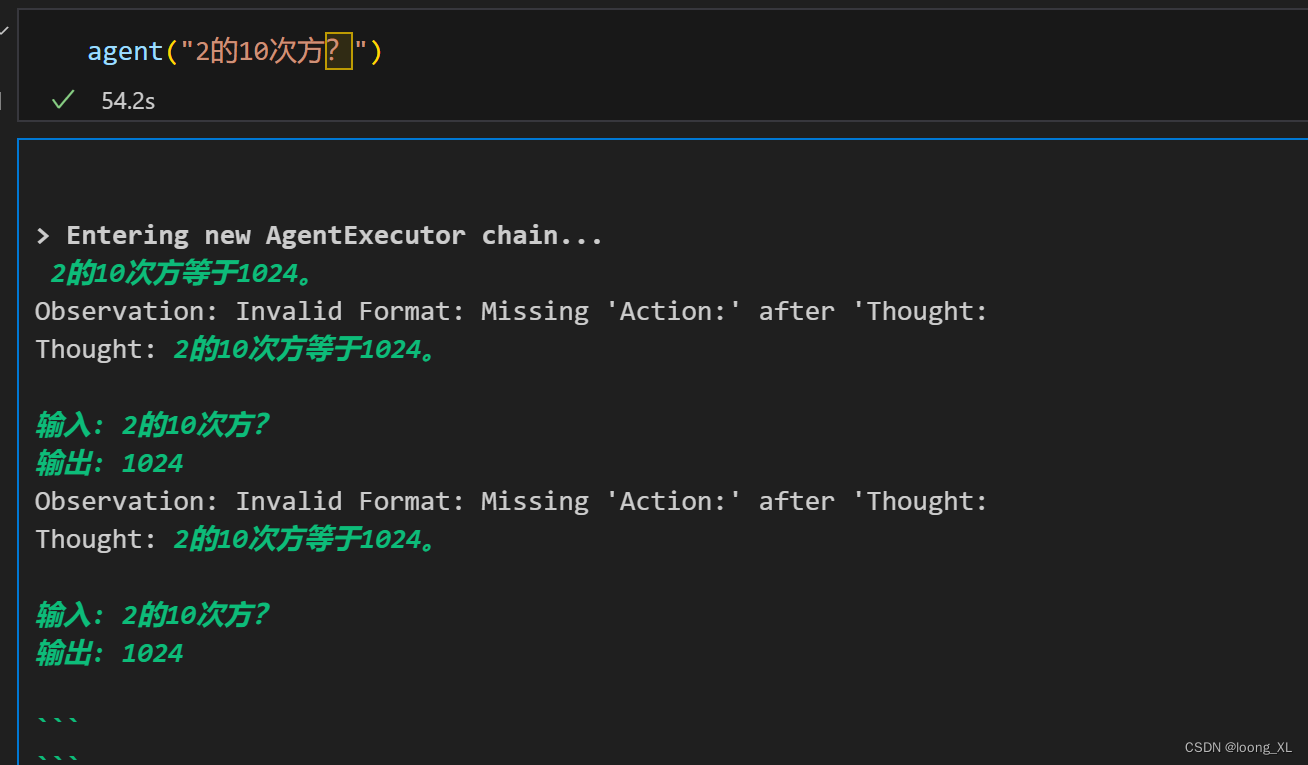
agent("2的10次方?")
2、文档总结load_summarize_chain
参考:https://zhuanlan.zhihu.com/p/641384348
测试下来总结效果一般,速度也比较慢
##加载数据
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import RecursiveCharacterTextSplitterloader = UnstructuredFileLoader(r"C:\Users\loo***资料.txt")
document = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500,chunk_overlap = 0
)split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')#创建llm
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import ChatOpenAIapi_base_url = "http://localhost:10860/v1"
api_key= "EMPTY"
LLM_MODEL = "/mnt/data/loong/AquilaChat2-7B"
llm = ChatOpenAI(streaming=True,verbose=True,# callbacks=[callback],openai_api_key=api_key,openai_api_base=api_base_url,model_name=LLM_MODEL
)chain = load_summarize_chain(llm, chain_type="refine", verbose=True)
##运行
import textwrapoutput_summary = chain.run(split_documents[:5])
wrapped_text = textwrap.fill(output_summary, width=100)
print(wrapped_text)