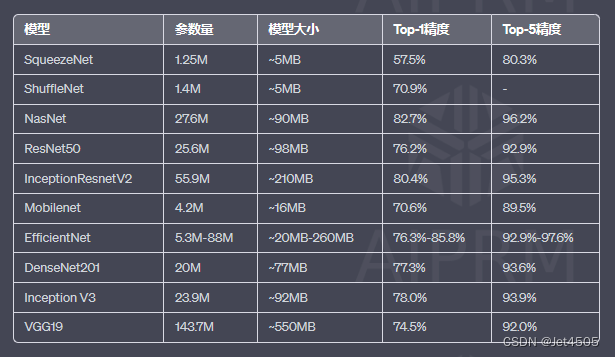
前言
系统上线时,非常容易出问题。
即使之前在测试环境,已经执行过SQL脚本了。但是有时候,在系统上线时,在生产环境执行相同的SQL脚本,还是有可能出现一些问题。
有些小公司,SQL脚本是开发自己执行的,有很大的风险。
有些大厂,有专业的DBA把关,但DBA也不是万能的,还是有可能会让一些错误的SQL脚本被生产环境执行了,比如:update语句的顺序不对。
今天跟大家一起聊聊,系统上线时SQL脚本的9大坑,以便于大家吸取教训,能够防微杜渐,希望对你会有所帮助。
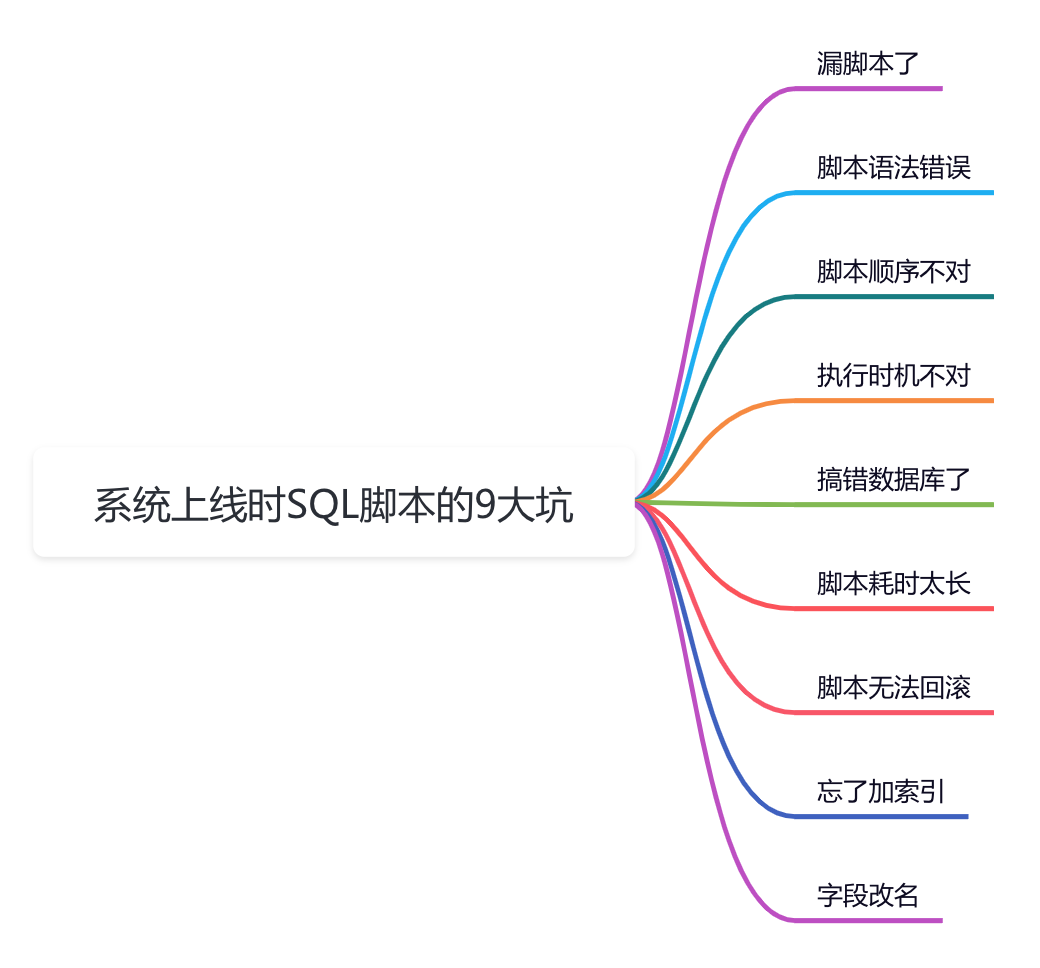
1 漏脚本了
我们上线时执行的SQL脚本,出现次数最多的问题,应该是漏脚本了。
-
有时候少加了一个字段。
-
有时候字段的注释没有及时修改。
-
有时候有些新表没创建。
-
有时候字段类型忘了修改。
等等。
我们的SQL脚本中漏脚本的情况有很多。
那么,如何解决这个问题呢?
答:将SQL脚本做成代码的一部分。在项目的代码中,创建一个专门的sql目录,在该目录下根据每个迭代创建一个子目录,比如:mv3.2.1,将SQL脚本存放到mv3.2.1下。
我们在开发环境任何对表的相关操作,比如:增加字段、修改字段类型、修改注释、增加索引、创建表等等,都需要通过SQL语句操作,然后把该SQL语句,整理到SQL脚本中。
最后提交到公司的GitLab上,我们在测试环境和生产环境发版时,去GitLab上找相关迭代版本的SQL脚本执行。
通过该方式基本可以解决漏脚本的问题。
2 脚本语法错误
有些小伙伴看到这个标题可能有点懵,SQL脚本不是已经在测试环境执行过了吗?为什么还会出现语法错误?
比如说有这样的场景:原本你的SQL脚本没问题的,但没有按照规范,给一张表的添加多个字段,你写了多条ALTER语句。
例如:
alter table t_user add column `work` varchar(30) DEFAULT NULL COMMENT '工作';
alter table t_user add column `provice` varchar(10) DEFAULT NULL COMMENT '籍贯';
在上线时,你给DBA提SQL工单时,该工单被DBA审核拒绝打回来了。
然后为了赶时间,你急急忙忙把多条ALTER语句改成一条ALTER语句。
例如:
alter table t_user add `work` varchar(30) DEFAULT NULL COMMENT '工作',
add `provice` varchar(10) DEFAULT NULL COMMENT '籍贯';
但在修改的过程中,有地方少了一个逗号,就可能会出现SQL语法错误。
因此,不管是什么SQL语句,要养成好习惯,只要修改了一定要记得到开发环境的数据库中,先执行测试一下,切勿直接提到生产环境,即使你有很大的把握,也需要再更慎重一些。
这样基本可以避免SQL语法错误的问题。
3 脚本顺序不对
有些时候,我们在上线系统时,DBA在执行SQL脚本的时候,没有报错,但最后的数据就是不对。
有可能是脚本顺序不对导致的。
比如有这样一种场景:你往某张表通过insert初始化了一条数据。
例如:
INSERT INTO `sue`.`t_user`(`id`, `code`, `age`, `name`, `height`, `address`, `work`, `provice`) VALUES (1, '101', 21, '周星驰', 173, '香港', NULL, NULL);
另外一个人要基于你这条数据,通过update修改数据。
例如:
update t_user set age=25 where id=1;
你们提了两条SQL脚本。
另外一个人先提的,你后提的。
DBA先把他的SQL工单审核通过了,先update数据,此时通过id是没法找到那条数据的,影响行数为0。
然后DBA再审核你的SQL工单,审核通过了,插入了一条数据。
由于SQL脚本的顺序不对,导致最终系统上线时的数据不对。
那么这个问题要如何解决呢?
双方要事先沟通好,把另外一个同事的SQL脚本加到你的初始化脚本中,你的脚本在初始化时,直接去修改数据即可。
例如:
INSERT INTO `sue`.`t_user`(`id`, `code`, `age`, `name`, `height`, `address`, `work`, `provice`) VALUES (1, '101', 25, '周星驰', 173, '香港', NULL, NULL);
这样可以避免执行顺序问题。
4 执行时机不对
有些系统功能已经上线了,在后面的迭代中,为了尽量避免少影响线上功能,可以增加一个pre(即预生产环境)。
该环境跟生产环境是差不多的,连接了相同的数据库,使用了相同的apollo配置。
但唯一的区别是pre环境没有实际的用户流量,只能公司内部人员才能访问。
一般在迭代版本上线之前,先要把系统功能发布到pre环境中,测试通过之后,才能发布到prod(即生产环境)。
但有些SQL脚本,却没法再pre环境中执行,不然会影响生产环境。
比如:修改了字段类型,int改成varchar了,或者初始化数据时,初始化了一条新加的枚举数据。
由于pre环境是运行的最新代码,但prod环境还是运行的老代码。
如果在发布pre环境时,直接执行SQL脚本,可能会导致prod环境的功能异常。
因此要搞清楚SQL脚本的执行时机,哪些是要在pre环境执行的,哪些是要在prod环境执行的。
我们在提SQL工单时,千万不要一股脑就提了,一定要区分时机。
在发pre环境时,要么不提发prod环境的SQL脚本。要么,在工单的名称上做区分,比如增加prod_开头的标识。
这样可以解决SQL脚本执行时机的问题。
5 搞错数据库了
有时候,我们的数据库做了分库分表,或者增加备份库。
在执行SQL脚本的时候,由于我们自己的疏忽,提SQL工单时选错数据库了,或者DBA的疏忽,在执行SQL工单时搞错数据库了,就会出现问题。
建议我们的SQL脚本增加库名,比如:
alter table sue.t_user add `work` varchar(30) DEFAULT NULL COMMENT '工作';
这里增加库名:sue。
这样基本可以避免选错数据库的问题。
6 脚本耗时太长
有时候,我们的SQL脚本需要批量修改生产环境的一些数据,正常情况下一条update语句就能搞定。
例如:
update user set status=0 where status=1;
但由于user表的数据量非常大,我们在执行该SQL脚本之前,没有预先评估该SQL脚本的耗时情况,而选择直接在生产环境的数据库中执行。
假如该SQL脚本耗时非常长,比如要10分钟才能执行完,可能会导致user表长期锁表,影响正常的业务功能。
在该SQL脚本执行的过程中,极有可能会出现业务功能操作,导致的死锁问题。
因此,建议这种大批量的数据更新操作,要在用户较少的凌晨,分批多次执行。
我们要尽可能少的影响线上用户的功能。
此外,在生产环境增加字段,增加索引等操作,也能会导致长期锁表。也要避免在用户访问高峰期执行相关的SQL脚本。
7 脚本无法回滚
绝大多数系统上线是能够成功的,虽然过程中会遇到很多问题,但如果能够及时解决,也能够上线成功。
但如果有些问题,没法再规定的时间内解决,很有可能会导致上线失败。
如果上线失败,意味着代码和数据库的SQL脚本要回滚。
如果只回滚了代码,不回滚数据库,可能会导致很多系统异常。
因此,我们在准备SQL语句时,要留点心眼,顺便想想该SQL语句能否回滚。
对于update语句可以加上修改时间:
update t_user set age=25,time=now(3) where id=1;
这样可以通过该时间追溯一次SQL操作修改的数据,方便后面做回滚。
有些时候我们要update的数据,是要通过多条sql语句查询出来的,比如:需要使用的id。
为了方便回滚我们可以增加临时表,保存这些id,后面就能追溯了。
当然有些开源的数据库管理平台,比如:Archery,是有自带SQL审核和回滚的功能。
8 忘了加索引
我们在增加了字段之后,非常容易忽略的一件事是:加索引。
特别是当前表数据量很大,而且增加的字段是另外一张表的id时,这种情况强烈建议增加索引。
如果我们上线系统时,在SQL脚本中,忘了给该字段增加索引。如果该id字段被大批量访问,全部走的全表扫描,可能会导致数据库性能直线下降,出现大量的超时问题。
所以建议我们在开发的时候,如果要增加字段的话,要养成良好习惯,想一想这个字段需不需要建索引。
如果不确定数据量的话,可以先到生产环境查询一下真实的用户数据,不然后续可能会引起比较大的生产事故。
9 字段改名
对于生产环境的表字段,通常情况下,我们不允许修改名称。
如果你在发布pre环境时,通过SQL脚本把某张表的某个字段名称修改了,pre环境代码使用了新的名称,系统没有问题。
但prod环境还是使用老的名称,所有使用该名称的sql语句,在代码执行过程中都会报错。
因此,禁止在生产环境通过SQL脚本修改字段名称。
当然系统上线时除了SQL脚本的这些坑之外,还有系统发版失败,代码合错分支,mq消息被pre消费了,无法回滚等等,还有很多问题。