Sift(尺度不变特征变换),全称是Scale Invariant Feature Transform
Sift提取图像的局部特征,在尺度空间寻找极值点,并提取出其位置、尺度、方向信息。
Sfit的应用范围包括物体辨别、机器人地图感知与导航、影像拼接、3D模型建立、手势识别、影像追踪等。
Sift特征的特点:
1. 对视角变化、噪声等也存在一定程度的稳定性;
2. 独特性,信息量丰富,适用于在海量特征数据中进行快速,准确的匹配;
3. 多量性,即使少数几个物体也可以产生大量的Sfit特征向量;
Sfit算法的实质是在不同的尺度空间上查找关键点(特征点),计算关键点的大小、方向、尺度信息,利用这些信息组成关键点对特征点进行描述的问题。Sift所查找的关键点都是一些十分突出,不会因光照,仿射变换和噪声等因素而变换的“稳定”特征点,如角点、边缘点、暗区的亮点以及亮区的暗点等。匹配的过程就是对比这些特征点的过程:

SIFT函数注册了专利,在商业用途上是收费的。将在opencv > 3.4.3中,不再提供。
解决办法:
安装opencv-python 3.4.2.16
以及opencv-contrib-python 3.4.2.16
使用conda和pip安装
pip install opencv-python==3.4.2.16
pip install opencv-contrib-python==3.4.2.16
SIFT特征提取和匹配具体步骤
1. 生成高斯差分金字塔(DOG金字塔),尺度空间构建
什么是尺度空间:
试图在图像领域中模拟人眼观察物体的概念与方法。
举个栗子:你拍了一张美女照,看到的肯定是整体,然后在你细看的时候,化身成了列文虎克,发现了华点,那么这个时候,你运用你灵巧的双指,放大了图片,华点的细节展现无遗,你发现了新大陆,然后默默打开了浏览器,接着一套连招。

简而言之,大尺度看整体(即轮廓),小尺度看细节。
图像金字塔:
把一张图片按照不同的比例对原始分辨率进行减少,然后从小到大叠加在一起,形成了金字塔的亚子。
图像金字塔是一种以多分辨率来解释图像的结构,通过对原始图像进行多尺度像素采样的方式,生成N个不同分辨率的图像。把具有最高级别分辨率的图像放在底部,以金字塔形状排列,往上是一系列像素(尺寸)逐渐降低的图像,一直到金字塔的顶部只包含一个像素点的图像,这就构成了传统意义上的图像金字塔。

获得图像金字塔一般包括二个步骤:
1. 利用滤波器平滑图像 (高斯滤波)
2. 对平滑图像进行抽样(采样)
有两种采样方式——上采样(分辨率逐级升高)和下采样(分辨率逐级降低)
高斯金字塔
主要思想是通过对原始图像进行尺度变换,获得图像多尺度下的尺度空间表示序列,对这些序列进行尺度空间主轮廓的提取,并以该主轮廓作为一种特征向量,实现边缘、角点检测不同分辨率上的关键点提取等。
各尺度下图像的模糊度逐渐变大,能够模拟人在距离目标由近到远时目标物体在视网膜上的形成过程。
尺度空间构建的基础是DOG金字塔,DOG金字塔构建的基础是高斯金字塔。
如何构建高斯金字塔:
1. 先将原图像扩大一倍之后作为高斯金字塔的第1组第1层,将第1组第1层图像经高斯卷积(其实就是高斯平滑或称高斯滤波)之后作为第1组金字塔的第2层。
2. 将σ乘以一个比例系数k,得到一个新的平滑因子σ=k*σ,用它来平滑第1组第2层图像,结果图像作为第3层。
3. 如此这般重复,最后得到L层图像,在同一组中,每一层图像的尺寸都是一样的,只是平滑系数不一样。它们对应的平滑系数分别为:0,σ,kσ,k^2σ,k^3σ……k^(L-2)σ。
4. 将第1组倒数第三层图像作比例因子为2的降采样(尺寸减半),得到的图像作为第2组的第1层,然后对第2组的第1层图像做平滑因子为σ的高斯平滑,得到第2组的第2层,就像步骤2中一样,如此得到第2组的L层图像,同组内它们的尺寸是一样的,对应的平滑系数分别为:0,σ,kσ,k^2σ,k^3σ……k^(L-2)σ。但是在尺寸方面第2组是第1组图像的一半。
反复执行,就可以得到一共O组,每组L层,共计O*L个图像,这些图像一起就构成了高斯金字塔:
• 在同一组内,不同层图像的尺寸是一样的,后一层图像的高斯平滑因子σ是前一层图像平滑因子的k倍;
• 在不同组间,后一组第一个图像是前一组倒数第三个图像的二分之一采样,图像大小是前一组的一半;
插个嘴:
高斯平滑:就是高斯滤波,过滤相关噪声
σ是啥玩意儿:平滑系数,系数越小,细节越多,系数越大,细节越少,下图是高斯滤波公式,骚年,你悟了吗,悟了请给两千缘

构建尺度空间:
在高斯金字塔中一共生成O组L层不同尺度的图像,这两个量合起来(O,L)就构成了高斯金字塔的尺度空间,也就是说以高斯金字塔的组O作为二维坐标系的一个坐标,不同层L作为另一个坐标,则给定的一组坐标(O,L)就可以唯一确定高斯金字塔中的一幅图像。

尺度空间中的某张图就是根据不同的高斯平滑度进行卷积而来的。
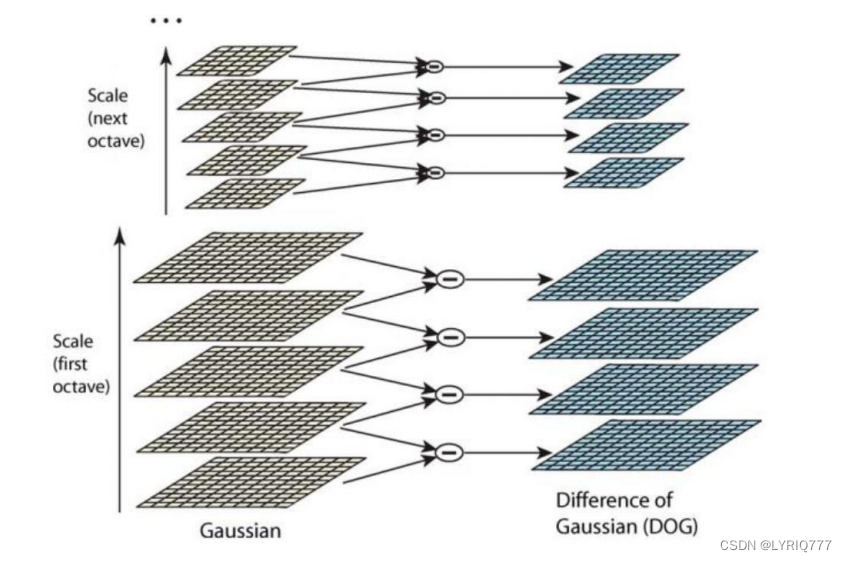
高斯金字塔弄出来了,下面就是差分(DOG)金字塔了,DOG?嗯?dog?emmmmmmmm...........
差分金字塔,DOG(Difference of Gaussian)金字塔 是在高斯金字塔的基础上构建起来的,其实生成高斯金字塔的目的就是为了构建DOG金字塔。
DOG金字塔的第1组第1层是由高斯金字塔的第1组第2层减第1组第1层得到的。以此类推,逐组逐层生成每一个差分图像,所有差分图像构成差分金字塔。
概括为DOG金字塔的第o组第l层图像是由高斯金字塔的第o组第l+1层减第o组第l层得到的。
上图!
2. 空间极值点检测(关键点的初步查探)
特征点是由DOG空间的局部极值点组成的。为了寻找DoG的极值点,每一个像素点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。
如下图,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。

注意, 局部极值点都是在同一个组当中进行的,所以肯定有这样的问题,某一组当中的第一个图和最后一个图层没有前一张图和下一张图,那该怎么计算? 解决办法是,再用高斯模糊,在高斯金字塔多“模糊”出3张来凑数,所以在DOG中多出两张。
比如某高斯金字塔中原先有5张图片,那么对应的差分金字塔中则有4张图片,当差分金字塔最底层和最顶层要进行计算的时候,怎么办,在高斯金字塔当中追加,那么这个时候,差分金字塔有6张图片,高斯是7张。诶???!!!不对啊。
不是说3张吗,怎么是两张,如果差分正常是3张的时候,需要的高斯金字塔是不是3+1张,这个时候加上上下两层,那么实际需要差分的是不是应该是3+2张?对吧,那么这个时候对应的高斯金字塔是不是就是3+2+1张,明白了吧,不明白没关系,睡一觉起来,明天再想。
结合下图食用

3. 稳定关键点的精确定位
DOG值对噪声和边缘比较敏感,所以在第2步的尺度空间中检测到的局部极值点还要经过进一步的筛选,去除不稳定和错误检测出的极值点。
利用阈值的方法来限制,在opencv中为contrastThreshold。
4. 稳定关键点方向信息分配
方法:获取关键点所在尺度空间的邻域,然后计算该区域的梯度和方向,根据计算得到的结果创建方向直方图。可以做如下设定:直方图的峰值为主方向的参数,其他高于主方向百分之80的方向被判定为辅助方向。


5. 关键点描述
对于每一个关键点,都拥有位置、尺度以及方向三个信息。为每个关键点建立一个描述符,用一组向量将这个关键点描述出来,使其不随各种变化而改变,比如光照变化、视角变化等等描述子不但包含关键点,也包括关键点周围对其有贡献的邻域点。
描述的思路是: 对关键点周围像素区域分块,计算块内梯度直方图,生成具有独特性的向量,这个向量是该区域图像信息的一种抽象表述。
如下图,对于2*2块,每块最终取8个方向,即可以生成2*2*8维度的向量,以这2*2*8维向量作为中心关键点的数学描述。

实验结果表明:对于每个关键点采用4×4×8=128维向量表征,综合效果最优(不变性与独特性)。

6. 特征点匹配
特征点的匹配是通过计算两组特征点的128维的关键点的欧式距离实现的。
欧式距离越小,则相似度越高,当欧式距离小于设定的阈值时,可以判定为匹配成功。
具体步骤:
1、分别对模板图(参考图,reference image)和实时图(观测图,observation image)建立关键点描述子集合。目标的识别是通过两点集内关键点描述子的比对来完成。具有128维的关键点描述子的相似性度量采用欧式距离。
2、匹配可采取穷举法完成。
怎么理解这个东西,就是参考图的关键点描述子和观测图中的描述子,然后4*4个格子里面的8个向量分别进行计算,然后求和,如果小于某个值,那就是匹配成功,