📝 学技术、更要掌握学习的方法,一起学习,让进步发生
👩🏻 作者:一只IT攻城狮 ,关注我,不迷路 。
💐学习建议:1、养成习惯,学习java的任何一个技术,都可以先去官网先看看,更准确、更专业。
💐学习建议:2、然后记住每个技术最关键的特性(通常一句话或者几个字),从主线入手,由浅入深学习。
❤️ 《SpringCloud入门实战系列》解锁SpringCloud主流组件入门应用及关键特性。带你了解SpringCloud主流组件,是如何一战解决微服务诸多难题的。
👉🏻 👉🏻 👉🏻 SpringCloud 入门实战系列不迷路 👈🏻 👈🏻👈🏻:
- SpringCloud 入门实战(一)什么是SpringCloud?
- SpringCloud 入门实战(二)-SpringCloud项目搭建
- SpringCloud 入门实战(三)-Eureka注册中心集成
- SpringCloud入门 实战(四)-Zookeeper、Consul注册中心集成
- SpringCloud入门实战(五)-Ribbon负载均衡集成
- SpringCloud入门实战(六)-OpenFeign服务调用集成
- SpringCloud入门实战(七)-Hystrix入门简介
- SpringCloud入门实战(七)-Hystrix服务降级
- SpringCloud入门实战(七)-Hystrix服务熔断
- SpringCloud入门实战(七)-Hystrix服务限流
- SpringCloud入门实战(七)-Hystrix Dashboard图形化监控
- SpringCloud入门实战(八)-Gateway服务网关集成
- SpringCloud入门实战(九)- Config配置中心
- SpringCloud入门实战(十)- SpringCloud Bus消息总线
- SpringCloud入门实战(十一)- SpringCloud Stream 消息驱动
- SpringCloud入门实战(十二)-Sleuth+Zipkin分布式请求链路跟踪详解
文章目录
- 一、Spring Cloud Sleuth概述
- 二、基本术语
- 1、Span (跨度)
- 2、Trace(跟踪)
- 3、Annotation (标注)
- 三、Sleuth与Zipkin的关系
- 四、Sleuth特性
- 五、项目集成
- 1、zipkin搭建安装
- 2、添加依赖
- 3、添加配置
- 4、修改业务代码
- 5、测试
一、Spring Cloud Sleuth概述
Spring Cloud Sleuth:官网
Spring Cloud Sleuth为Spring Cloud实现分布式跟踪解决方案。
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
SpringCloudSleuth有几个特点:
| 特点 | 说明 |
|---|---|
| 提供链路追踪 | 通过sleuth可以很清楚的看出一个请求经过了哪些服务, 可以方便的理清服务间的调用关系 |
| 性能分析 | 通过sleuth可以很方便的看出每个采集请求的耗时,分析出哪些服务调用比较耗时,当服务调用的耗时,随着请求量的增大而增大时,也可以对服务的扩容提供一定的提醒作用 |
| 数据分析及优化链路 | 对于频繁地调用一个服务,或者并行地调用等, 可以针对业务做一些优化措施 |
| 可视化 | 对于程序未捕获的异常,可以在zipkpin界面上看到 |
二、基本术语
Spring Cloud Sleuth借用了Dapper的术语。
1、Span (跨度)
工作的基本单位。通俗的理解span就是一次请求信息,发送一个远程调度任务就会产生一个Span。 Span 由一个64位ID唯一标识的,Trace 是用另一个64位ID唯一标识的,Span 还有其他数据信息,比如摘要、时间戳事件、Span的ID、进度ID、键值注释(标签),导致它们的跨度的ID以及进程ID(通常是IP地址)。创建跨度后,必须在将来的某个时刻停止。
2、Trace(跟踪)
类似于树结构的span集合,表示一条调用链路,存在唯一标识。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
启动跟踪的初始范围称为root span。该跨度的跨度id的值等于跟踪ID。
3、Annotation (标注)
用来及时记录一个事件的存在,一些核心注解用来定义一个请求的开始和结束。这些注解包括以下:
cs - 客户端发送 - 客户端发送一个请求,这个注解描述了这个跨度的开始
sr - 服务器接收 - 服务器端得到请求,并将开始处理它。如果从此时间戳中减去cs时间戳,可得到网络传输的时间。
ss - 服务器发送 - 该注解表明请求处理的完成(当请求返回客户端)。如果从此时间戳中减去sr时间戳,就可以得到服务器请求的时间。
cr - 客户端接收 - 表示跨度的结束。客户端已成功接收到服务器端的响应。如果从此时间戳中减去cs时间戳,则会收到客户端从服务器接收响应所需的整个时间,即整个请求所消耗的时间。
三、Sleuth与Zipkin的关系
1、这里需要提一下Sleuth与Zipkin的关系,为什么链路跟踪经常围绕着二者一起叙述?
- sleuth :链路追踪器
- zipkin:链路分析器。可以理解为可视化界面,配合Sleuth可以清晰定位请求流程。
zipkin是Twitter基于google的分布式监控系统Dapper(论文)的开发源实现
2、可视化Span和Trace将与Zipkin注释一起查看系统:
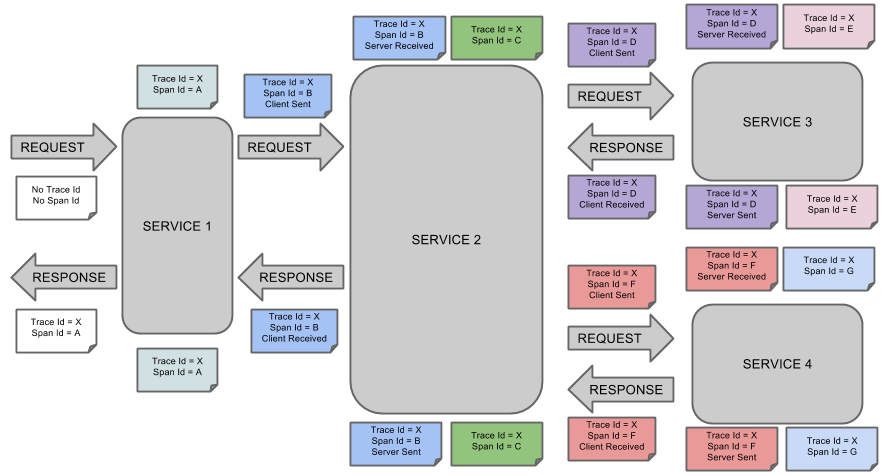
一个音符的每个颜色表示跨度(7 spans - 从A到G)。如果您在笔记中有这样的信息:
Trace Id = X
Span Id = D
Client Sent
这意味着,当前的跨度痕量-ID设置为X,Span -编号设置为ð。它也发出了 客户端发送的事件。
这样,spans的父/子关系的可视化将如下所示:
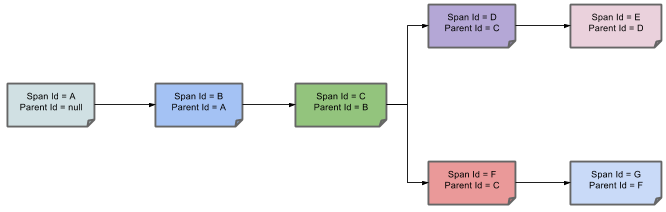
可以在Zipkin中查看痕迹:共有7个spans,如果选择特定的跟踪,将看到合并后的4个spans
四、Sleuth特性
1、将跟踪和跨度添加到Slf4J MDC,以便可以从日志聚合器中的给定跟踪或跨度中提取所有日志。示例日志:
2023-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ...
2023-02-02 15:30:58.372 ERROR [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ...
2023-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ...## 注意MDC中的[appname,traceId,spanId,exportable]条目:
spanId - 发生特定操作的ID
appname - 记录跨度的应用程序的名称
traceId - 包含跨度的延迟图的ID
导出 -日志是否应该被导出到Zipkin与否。你什么时候希望跨度不能出口?在这种情况下,你想在Span中包装一些操作,并将它写入日志。
顺便提一下常用的日志聚合工具Kibana, Splunk、Logstash等
2、从Spring应用程序(servlet过滤器、rest模板、调度操作、消息通道、外部客户端)中插入常见的入口和出口点。
3、提供对共同分布式跟踪数据模型的抽象:trace,spans(形成DAG),注释,键值注释。松散地基于HTrace,但Zipkin(Dapper)兼容。
4、Sleuth记录定时信息以辅助延迟分析。Sleuth被写入不会记录太多,并且不会导致您的生产应用程序崩溃。
5、Sleuth包括在http或消息传递边界上加入跟踪的默认逻辑。例如,http传播通过Zipkin兼容的请求标头工作。该传播逻辑是通过SpanInjector和SpanExtractor实现来定义和定制的。
6、Sleuth可以在进程之间传播上下文(也称为行李)。这意味着如果您设置了Span行李元素,那么它将通过HTTP或消息传递到其他进程发送到下游。
7、提供创建/继续spans并通过注释添加标签和日志的方法。
8、提供接受/删除spans的简单指标。
9、如果spring-cloud-sleuth-zipkin,则应用程序将生成并收集Zipkin兼容的跟踪。默认情况下,它通过HTTP将其发送到localhost上的Zipkin服务器(端口9411)。使用spring.zipkin.baseUrl配置服务的位置。
10、如果spring-cloud-sleuth-stream,则该应用将通过Spring Cloud Stream生成和收集跟踪。您的应用程序自动成为通过您的代理商发送的跟踪消息的生产者(例如RabbitMQ,Apache Kafka,Redis))。
重要:
如果使用Zipkin或Stream,请使用spring.sleuth.sampler.percentage(默认0.1,即10%)配置spans的百分比。否则你可能认为Sleuth不工作,因为它省略了一些spans。
五、项目集成
1、zipkin搭建安装
首先你要清楚zipkin也是分客户端服务端的。
Spring Boot 2.0不支持@EnableZipkinServer,所以需要下载Zipkin的服务器到本地
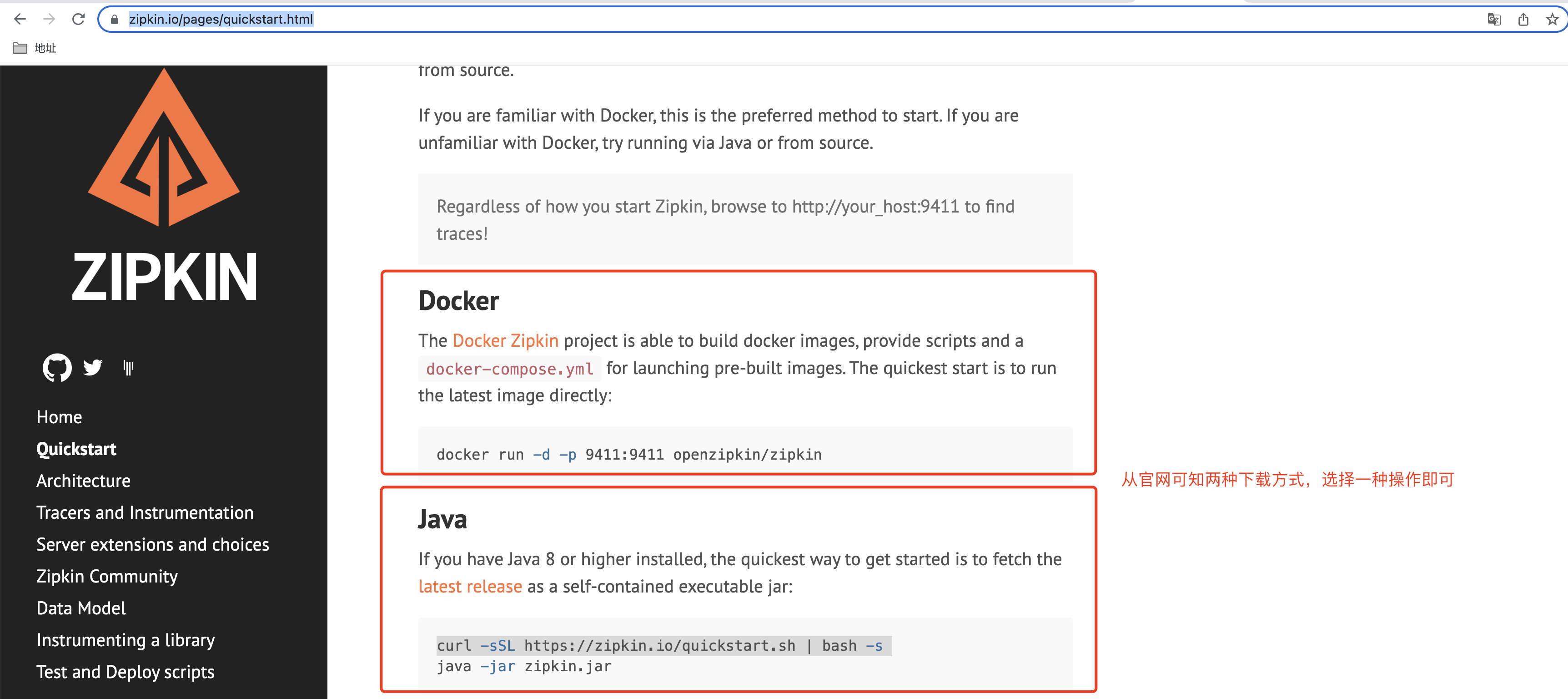
按照提示操作即可:

访问控制台:
若启动失败由于端口(zipkin默认端口9411)占用,mac环境下执行:lsof -i tcp:9411 查看端口占用程序,然后sudo kill -9 PID 即可。
SpringCloud从F版开始起就不需要自己构建ZipKin Server了,只需要
调用jar包即可。
2、添加依赖
服务提供者(payment)和消费者(order)工程均添加依赖:
<!--依赖包含了sleuth,所以不需要再单独引入sleuth--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
这里小编有话要说,如果上边的依赖飘红引不进来,那么原因可能是你使用的cloud版本已经移除了spring-cloud-starter-zipkin,需要使用下边的来替代:
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId></dependency><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-sleuth-zipkin</artifactId></dependency>
查看我的SpringBoot2.5.6对应的cloud的官方文档后看到已经被移除了
3、添加配置
服务提供者(payment)和消费者(order)工程均添加配置:
spring:zipkin:#zipkin服务所在地址base-url: http://localhost:9411/sender:type: web #使用http的方式传输数据#配置采样百分比sleuth:sampler:probability: 1 # 将采样比例设置为 1.0,也就是全部都需要。默认是0.1也就是10%,一般情况下,10%就够用了
##打开debug日志
logging:level:org.springframework.web.servlet.DispatcherServlet: DEBUG
值得一提的是这里配置的type=web:
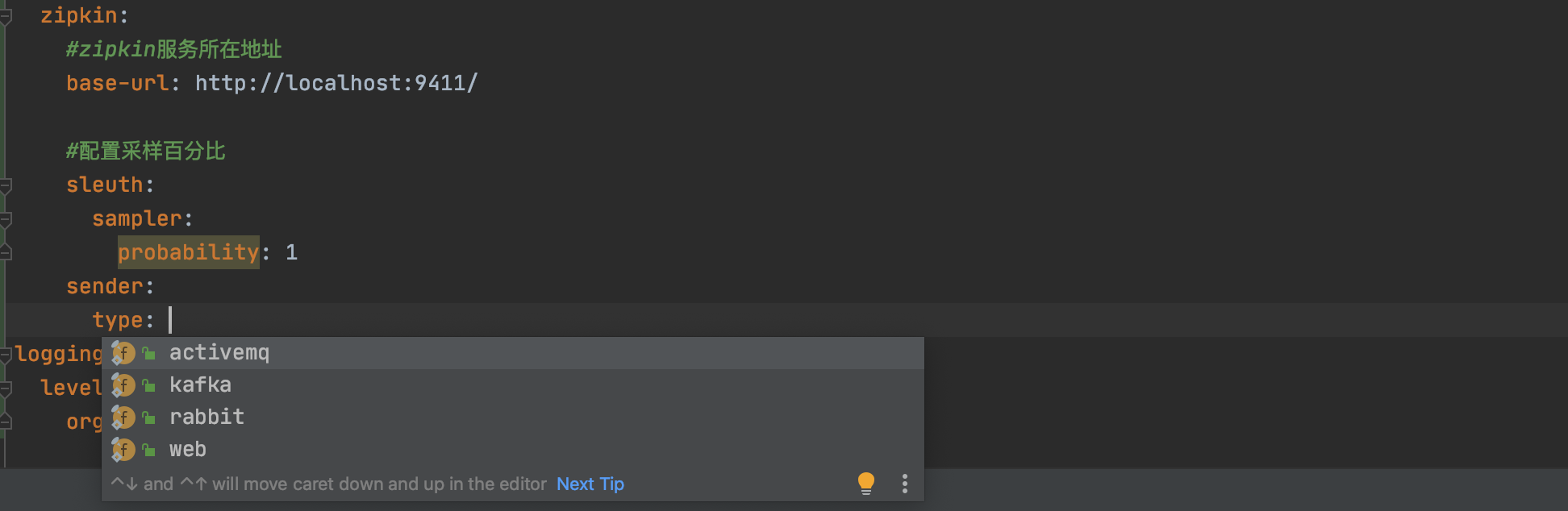
type=web也就是通过 HTTP 的方式发送数据到 Zipkin ,如果请求量比较大,这种方式其实性能是比较低的,一般情况下我们都是通过消息中间件来发送,比如 RabbitMQ 。
如果日志数据量比较大,一般推荐拥有更高吞吐量的 Kafka 来进行日志推送。
这种方式就是让服务将 Sleuth 收集的日志推给 MQ ,让 Zipkin 去监控 MQ 的信息,通过 MQ 的队列获取到服务的信息。这样就提高了性能。
而日志的存储则可以采用 Elasticsearch 对数据进行持久化,这样可以保证 Zipkin 重启后,链路信息不会丢失。
4、修改业务代码
oreder工程:
@RestController
@RequestMapping("/feign")
@Slf4j
public class OrderFeignController {@Resourceprivate PaymentFeignService paymentFeignService;@GetMapping(value = "/order/zipkin")public CommonResult<Payment> paymentZipKin() {return paymentFeignService.paymentZipKin();}
}
payment工程:
@RestController
@RequestMapping("/payment")
@Slf4j
public class PaymentController {@Resourceprivate PaymentService paymentService;@Value("${server.port}")private String serverPort;@GetMapping("/zipkin")public CommonResult<Object> paymentZipKin() {return new CommonResult<>(200, "hi,I am paymentZipKin server O(∩_∩)O哈哈~", serverPort);}
}
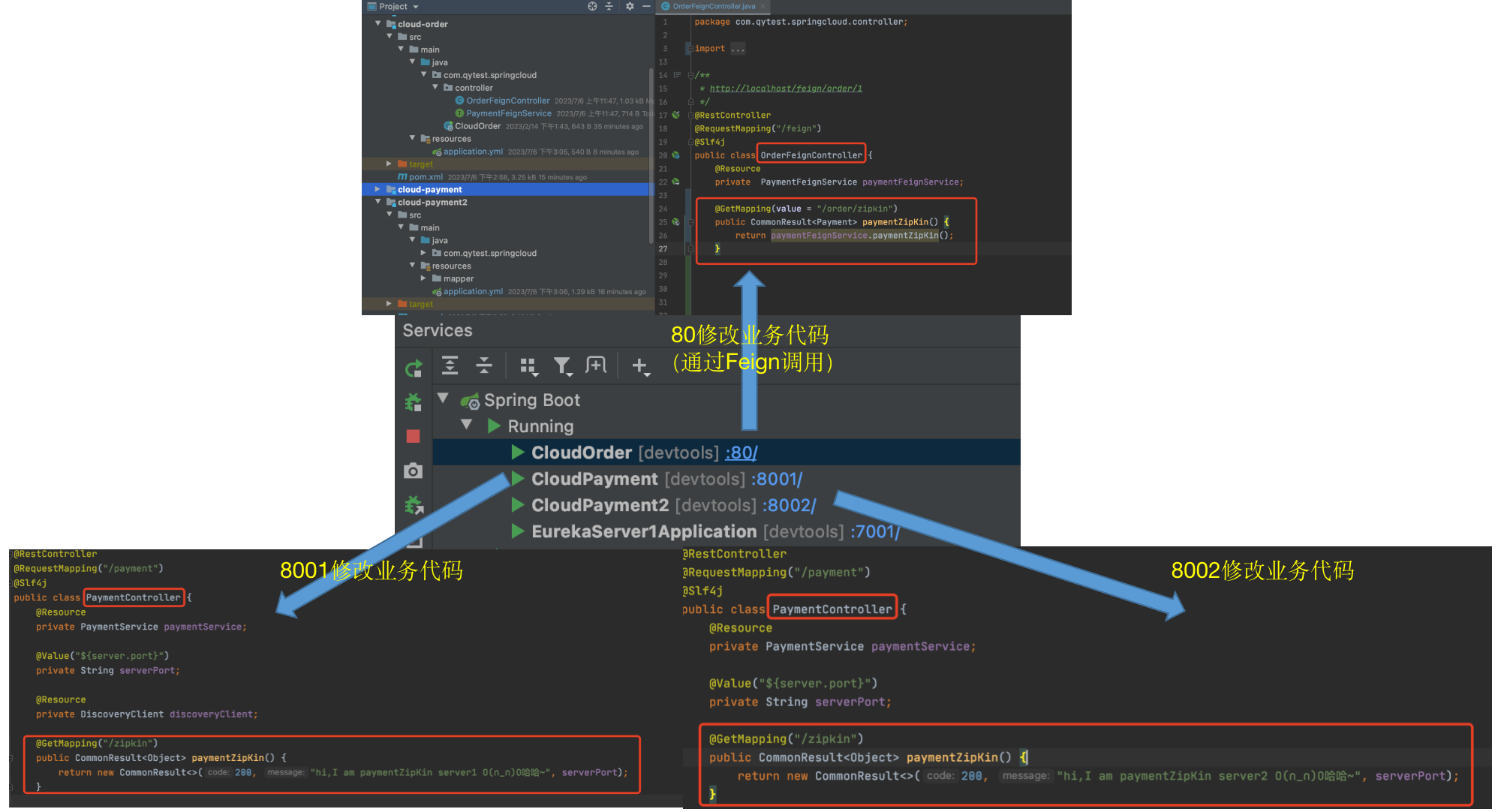
5、测试
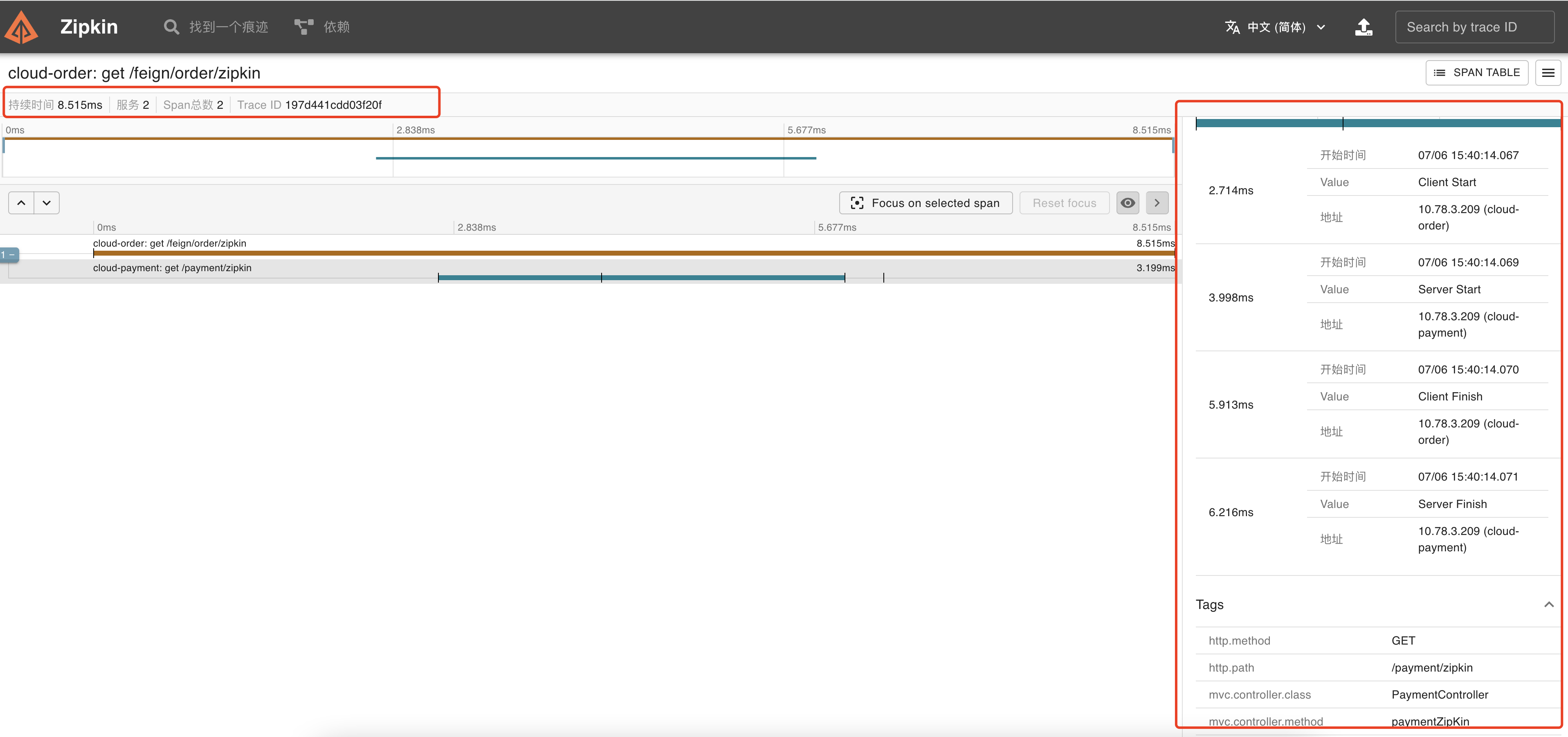
访问http://localhost/feign/order/zipkin

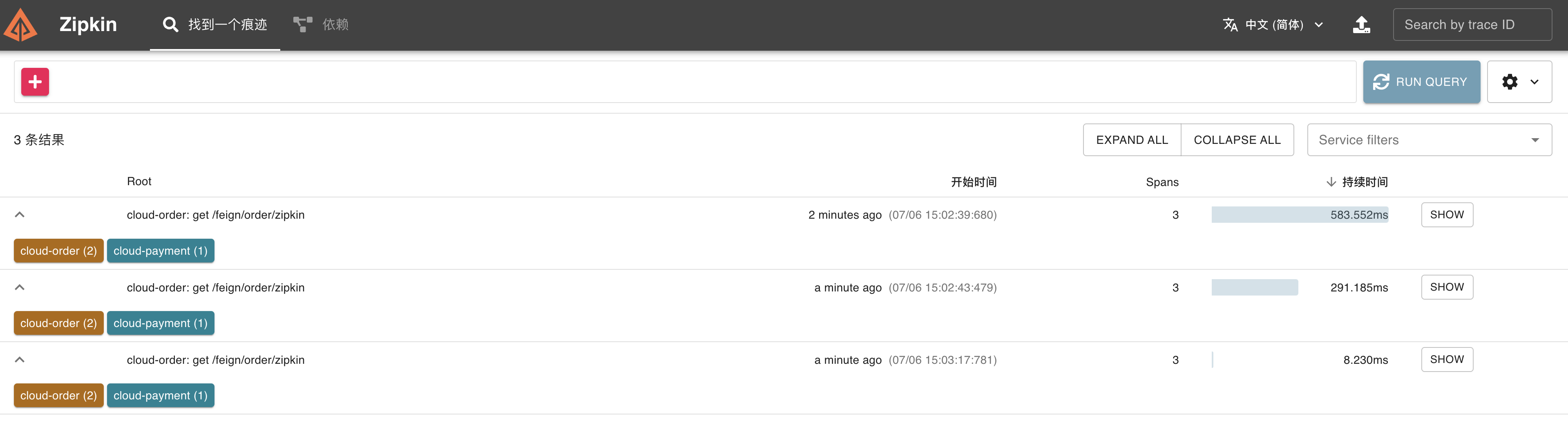
点击run query查询请求链路-》点击show查看详情: