文 | 小戏、ZenMoore
要说当下制约大模型释放更大规模潜力的桎梏,除了机器幻觉,肯定当属受限的上下文长度,前两天微软的 LongNet 正将 Transformer 的上下文长度扩展到夸张的 10 亿量级,这两天撑起了开源大模型一片天的 LLaMA 家族再添新成员,LongLLaMA 横空出世,作为加长(强)版 LLaMA 模型成功的扩展了 LLaMA 的上下文长度

要说 LongLLaMa 到底有多 Long,从这个贯穿全文的 Logo 就可以看出来(吐槽:整个长颈鹿不好吗?为什么要拉长身子玩行为艺术???),LongLLaMA 通过引入 Focused Transformer(FOT)方法,在保持性能的同时,将 LLaMA 的上下文长度扩展到 100k!

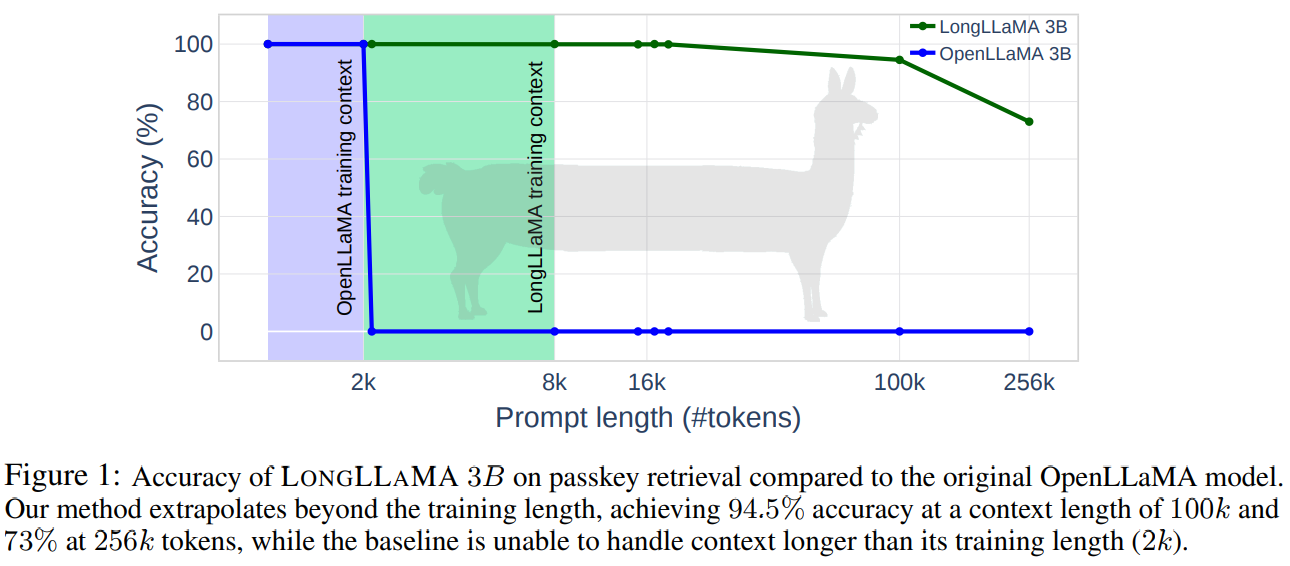
如下图所示,对标原始的 LLaMA 模型,伴随着 Prompt 长度的增加,LongLLaMA 表现出了极佳的性能,在上下文长度为 100k 时正确率才出现明显的下降,并且仍然可以达到 94.5% 的正确率,而在上下文长度为 256k 时,LongLLaMA 也能拥有 73% 的正确率。而对比原始 LLaMA,在上下文长度为 2k 时性能就已经出现了断崖式的下降,完全无法处理长文本的 Prompt 输入
大模型研究测试传送门
GPT-4传送门(免墙,可直接测试,遇浏览器警告点高级/继续访问即可):
Hello, GPT4!
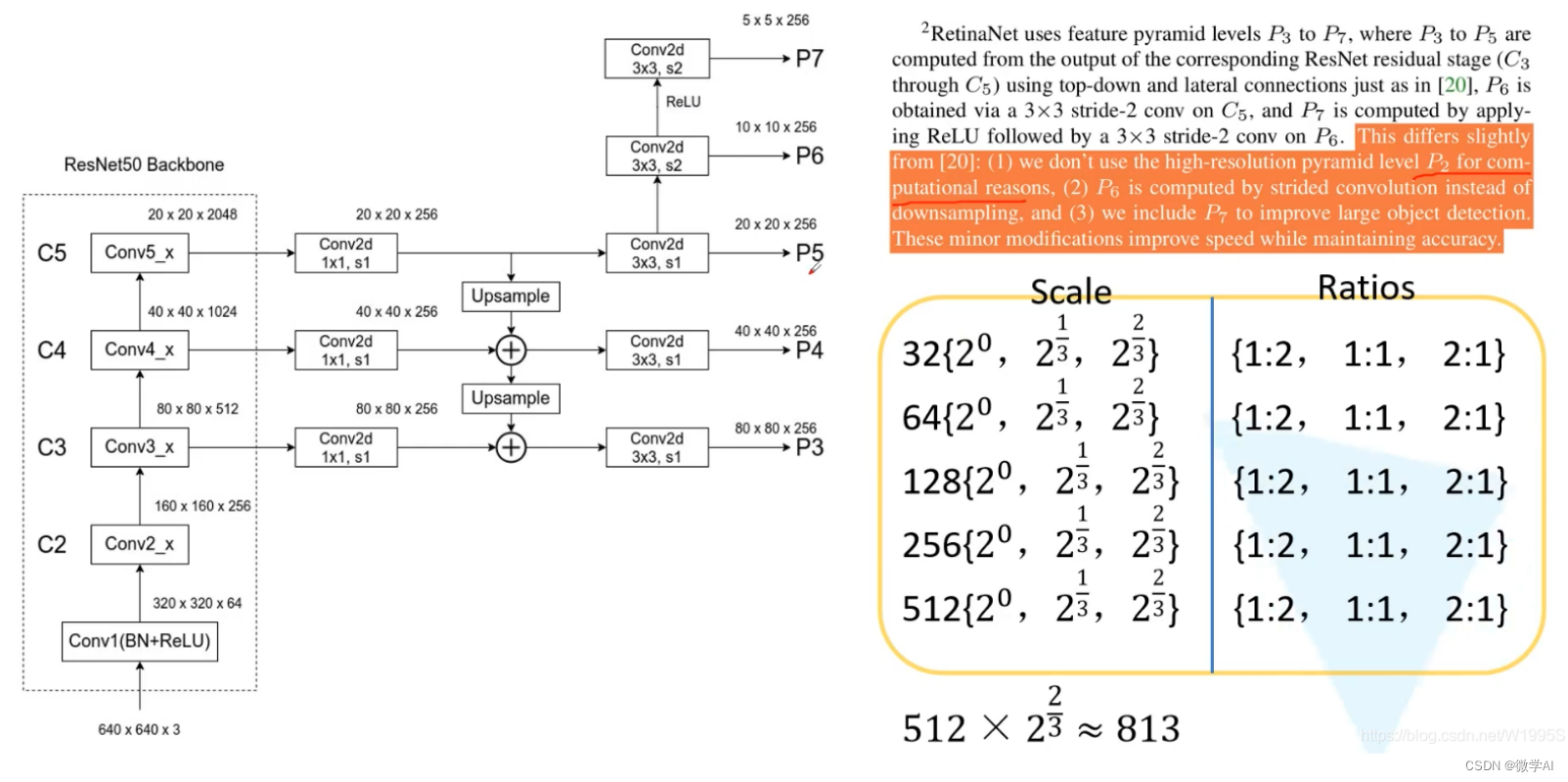
为了实现大模型上下文的扩展,LongLLaMA 的论文作者们首先考虑这样一个问题“为什么大模型无法有效处理长文本的 Prompt”,诚然,这事实上与 Transformer 模型的基础架构有关,但是论文作者看到,除了增加的时间复杂度以外,伴随着文档数量的增加,其中相关的 tokens 对不相关 tokens 的比例会减少,从而导致与不相关 value 相关的 key 和与相关 value 相关的 key 发生重叠,致使模型需要额外区分不同语义的 key,作者们将这一问题命名为分心问题(Distraction Issue),在论文中,作者团队认为分心问题是导致大模型受限于上下文长度的核心问题,因此针对此问题提出了一个 Transformer 模型的简单扩展 Focused Transformer(FOT)如下图所示:
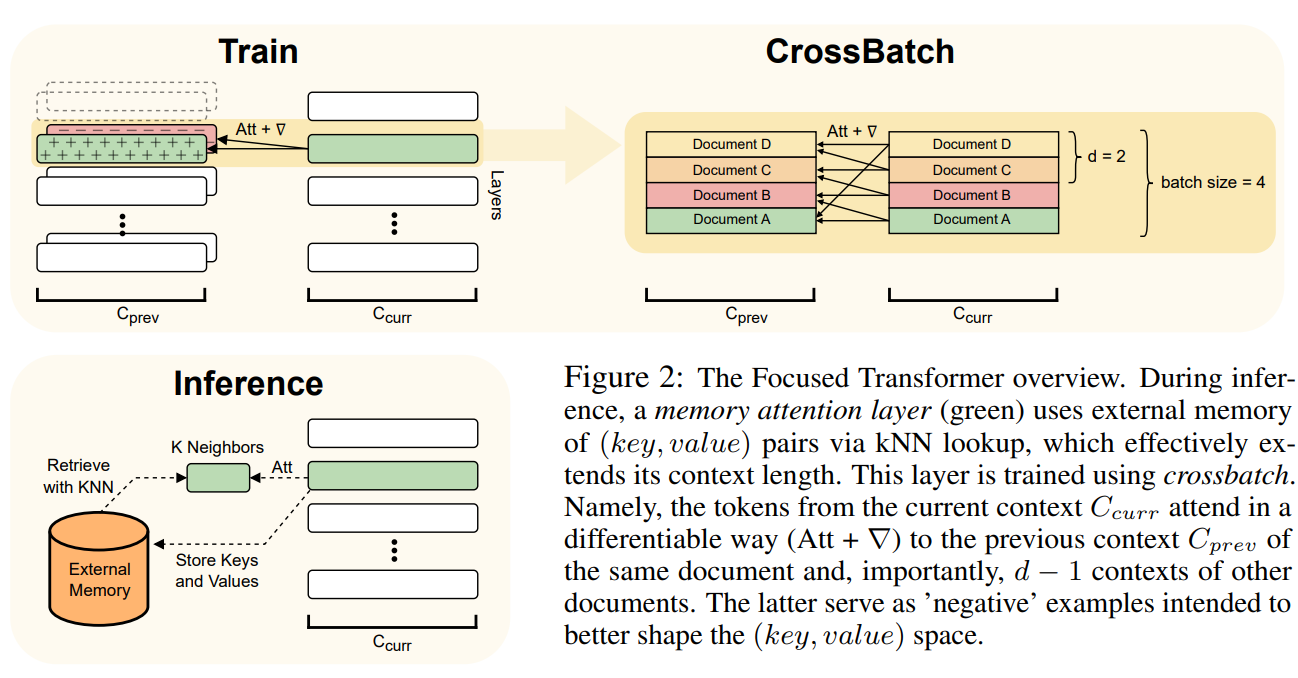
Focused Transformer 主要使用了 Memory Attention Layers 以及 CrossBatch 技术,在 Inference 的过程中,绿色的 Memory Attention Layers 使用 kNN 对外部的 Memory 进行查询,从而有效延长了上下文长度,而 Memory Attention Layers 则主要使用 CrossBatch 进行训练。
具体而言,Memory Attention Layers 中的每个 query 在 中会关注局部的上下文以及 Memory 中使用 kNN 计算出的最匹配的 k 个键,而整个 Memory 则根据 之前处理的 key,value 进行填充。而 CrossBatch 则期望使得 Memory Attention Layers 更加关注长文本之中的“相关 value 的 key”,CrossBatch 的处理借鉴了对比学习的思想,以相关文档之中的 d-1 个上下文作为正样本,以不相关文档之中的 d-1 个上下文作为负样本,通过对比学习的方式使得 Memory Attention Layers 可以更好的分辨相关与无关的 key-value。

通过与标准的 Transformer 进行对比,如上图所示,在一般的 Transformer 的训练过程中,相关与不相关文档没有被得到有效区分(正负样本分散均匀),当文档数量扩展时,注意力变得越来越分散,而 Focused Transformer 则通过 CrossBatch 的训练目标使得模型有效的关注与区分的长文本下的相关与无关的 key-value 的空间结构,从而解决了分心的问题。
论文作者在两个下游任务 TREC 问题分类与 WebQS 问题回答中测试了 LongLLaMA 拥有的更长上下文长度对小样本学习中准确率的加成,如下图所示,在两个任务之中增加上下文长度都会有效提升准确率,并且在 TREC 问题分类中表现得格外优异,论文作者认为,TREC 数据集的分类有 50 个类别,而 2k 的上下文长度仅仅能支持 100 个示例,而很有可能一些类别在这 100 个示例之中不会出现,从而导致任务根本无法完成,而长下文长度的扩展则可以大大减轻这种风险
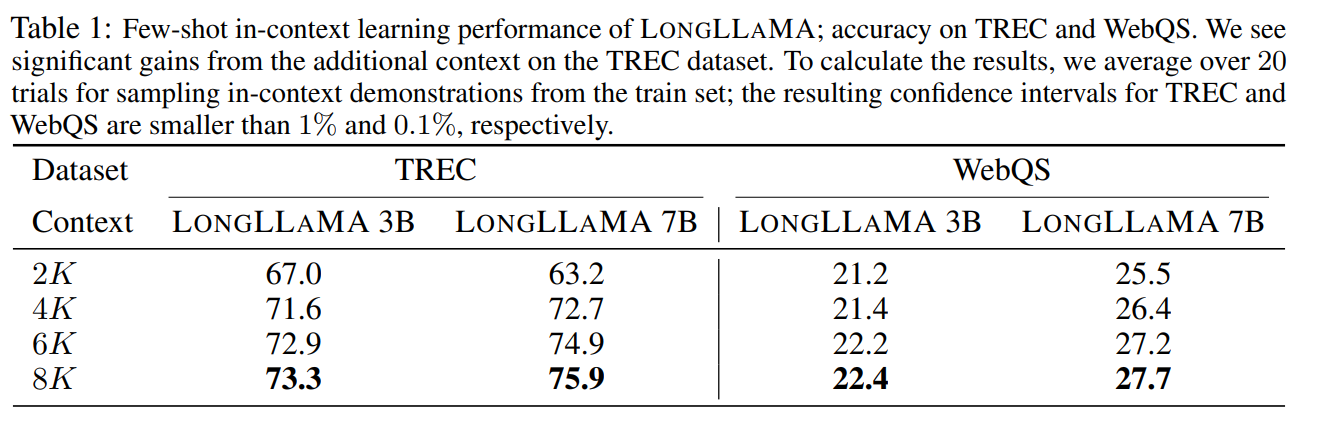
同时,作者也对比了在这两个任务中 FOT 方法与传统方法在性能上的差异,可以看到 FOT 方法不但超越了传统方法的上下文长度,并且也获得了更好的效果

而哪怕不在长上下文的任务之中,在普通的任务之下, LongLLaMA 也可以维持与传统 LLaMA 相似的性能,表明 LongLLaMA 完全可以作为 LLaMA 更强的替代

除了对 LongLLaMA 的性能分析以外,作者团队还做了大量实验测试 FOT 的表现,具体而言,作者希望回答以下三个问题:
-
在推断时,FOT 的性能如何随上下文长度的变化而变化?
-
是否可以使用 FOT 作为当前预训练模型扩展上下文长度的方法?
-
FOT 面对不相关文档的增多表现如何?
首先,回答第一个问题,面对一个给定的 key:value 映射作为外部的 Memory,模型需要回答与特定键相关的值是什么,如下图所示,FOT 可以有效的利用 16M 的内存并达到 92% 的准确率,而普通的 Transfomer 则在 4k 作用正确率就遭遇滑铁卢

其次,对于第二个问题,如果使用 FOT 对现有的模型进行微调,那么是否会增加现有模型的上下文长度?作者首先训练了一个标准的 Transformer 模型,进行了 100k 步预训练,然后使用 FOT 进行了 10k 步的微调,并在 4 个数据集上评测其困惑度,可以看到 FOT 微调方法在 64k 上下文中得到了有效的提升,并且战胜了其他对标的模型扩展方法,表明 FOT 有潜力作为一种方法增加当前其他大模型的上下文长度

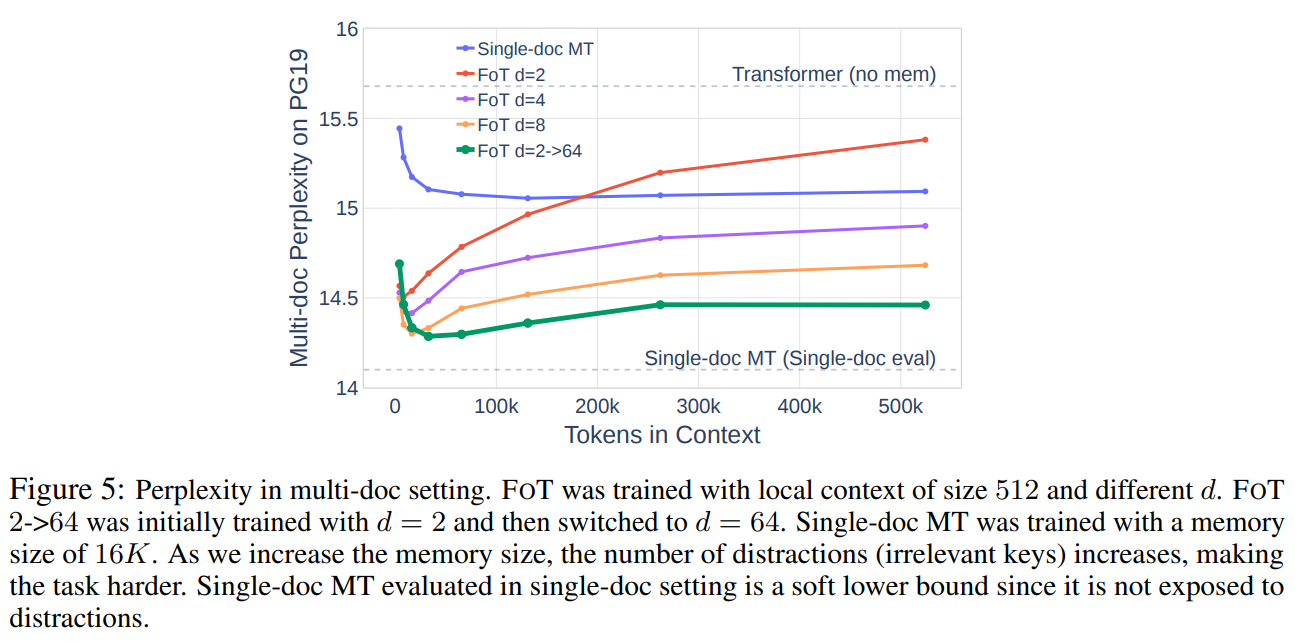
最后,对于第三个问题,作者使用 PG-19 数据集,伴随着 Memory size 的增加,不相关的文档可以被视为一种对模型的“干扰”让模型分心,而从下图中可以看出,更高的 d 会带来更低的困惑度,表明 FOT 方法可以有效处理不相关数据增加带来的干扰,面对干扰更加稳健
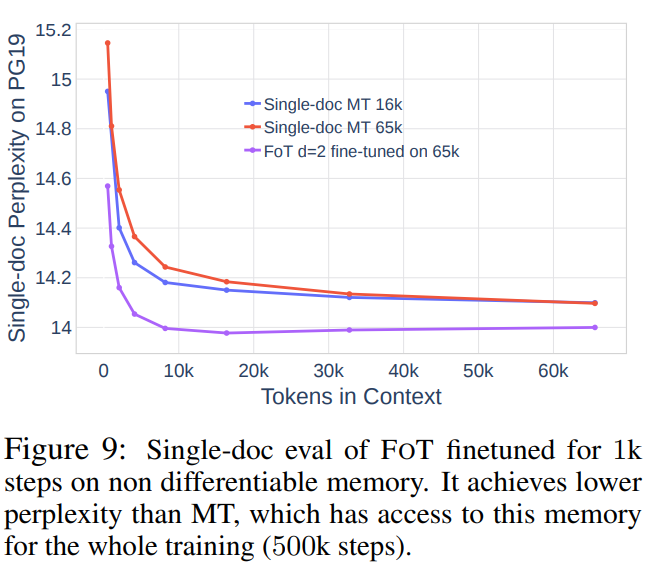
事实上,从 FOT 的设计之中,可以看到这种方法与 Memorizing Transformer 关系密切,论文作者认为,区别于 Memorizing Transformer,FOT 方法有两种不同,分别是训练协议(Training protocol)——对比学习目标,与内存集成(Memory integration)——kNN 检索。论文作者认为 FOT 方法有潜力与 Memorizing Transformer 结合以获得更好的性能,在通过使用 CrossBatch 方法进行了 499k 步的训练后,再使用 Memorizing Transformer 的目标进行 1k 步微调,可以看到模型效果出现了显著的改善
这只被拉长的羊驼(LongLLaMA)已经被论文作者开源在了 Github 之中,并在 Hugging Face 上发布了 LONGLLAMA-3B 的 Checkpoint,可以与任何现有的 LLaMA 代码一起使用,论文地址与项目地址如下:
论文题目:
Focused Transformer: Contrastive Training for Context Scaling
论文链接:
https://arxiv.org/pdf/2307.03170.pdf
项目地址:
https://github.com/CStanKonrad/long_llama
Hugging Face:
https://huggingface.co/syzymon/long_llama_3b