logstash 与ElasticSearch:从CSV文件到搜索宝库的导入指南
使用 logstash 导入数据到 ES 时,由三个步骤组成:input、filter、output。整个导入过程可视为:unix 管道操作,而管道中的每一步操作都是由 “插件” 实现的。使用 ./bin/logstash-plugin list 查看 logstash 已安装的插件。
每个插件的选项都可以在官网查询,先明确是哪一步操作,然后去官方文档看是否有相应的插件是否支持这种操作。比如 output 配置选项:plugins-outputs-elasticsearch-options),其中的 doc_id 选项就支持 指定 docid 写入 ES。在这里,简要说明一些常用的插件,要想了解它们实现的功能可参考官方文档。
- mutate 插件 用于字段文本内容处理,比如 字符替换
- csv 插件 用于 csv 格式文件导入 ES
- convert 插件 用于字段类型转换
- date 插件 用于日期类型的字段处理
使用 logstash 导入时,默认以 “message” 标识 每一行数据,并且会生成一些额外的字段,比如 @version、host、@timestamp,如果用不着,这些字段可以去除掉 ,此外,要注意 ES 中的索引的格式 (Mapping 结构),最好是指定自定义的索引模板,保证索引最 “精简”。
另外这里记录一些常用的参数及其作用,更具体的解释可查看官方文档。
- sincedb_path 告诉 logstash 记录文件已经处理到哪一行了,从而当 logstash 发生故障重启时,可从故障点处开始导入,避免从头重新导入。
- remove_field 删除某些字段
配置文件完成后,执行以下命令./bin/logstash -f csvfile_logstash.conf 即可启动 logstash 执行导入操作。
以下是各种错误解决:
错误一:
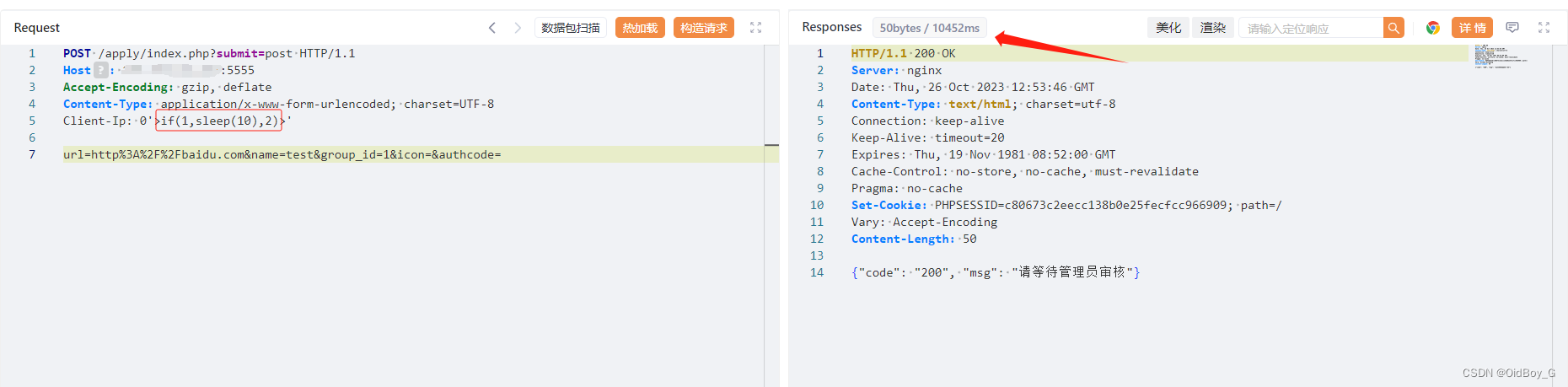
ConfigurationError”, :message=>”Expected one of #, input, filter, output at line 1, column 1
如果 配置文件内容是正确的,用 Notepad++ 检查一下文件的编码,确保是:UTF-8 无 BOM 格式编码
1.解决 SOH 分隔符问题
由于 csv 插件的 separator 选项不支持转义字符,因此无法用\u0001来代表 SOH。如果 csv 文件以 SOH 分隔符 (\u0001) 分割,一种方案是使用 mutate 插件替换,将\u0001替换成逗号。如下所示:
mutate{# 每一行内容默认是message, 将分隔符 \u0001 替换成 逗号gsub => [ "message","\u0001","," ]# @timestamp 字段是默认生成的, 名称修改成 createdrename => ["@timestamp", "created"]}但是实际上 logstash6.8.3 是支持按 SOH 分割的。在 Linux shell 下,先按 ctrl+v,再按 ctrl+a,输入的就是 SOH。那么在 vim 中打开配置文件,在 vim 的 insert 模式下,先按 ctrl+v,再按 ctrl+a,将 SOH 作为 csv 插件的 separator 分割符。

csv {# 每行按逗号分割, 生成2个字段: topsid 和 title, (如果分割超过2列了,第三列则以 column3 命名)separator => ""columns => ["topsid", "title"]# 删除一些不需要索引到ES中去的字段(logstash默认生成的一些字段)remove_field => ["host", "@timestamp", "@version", "message","path"]} 一个将 csv 文件内容导入 ES 的示例配置模板如下:(csv 文件中的每一行以 SOH 作为分割符)
- logstash input 插件支持多种数据来源,比如 kafka、beats、http、file 等。在这里我们的数据来源是文件,因此采用了 logstash input file 插件。
- 把数据从文件中读到 logstash 后,可能需要对文件内容 / 格式 进行处理,比如分割、类型转换、日期处理等,这由 logstash filter 插件实现。在这里我们进行了文件的切割和类型转换,因此使用的是 logstash filter csv 插件和 mutate 插件。
- 处理成我们想要的字段后,接下来就是导入到 ES,那么就需要配置 ES 的地址、索引名称、Mapping 结构信息 (使用指定模板写入),这由 logstash output 插件实现,在这里我们把处理后的数据导入 ES,因此使用的是 logstash output elasticsearch 插件。
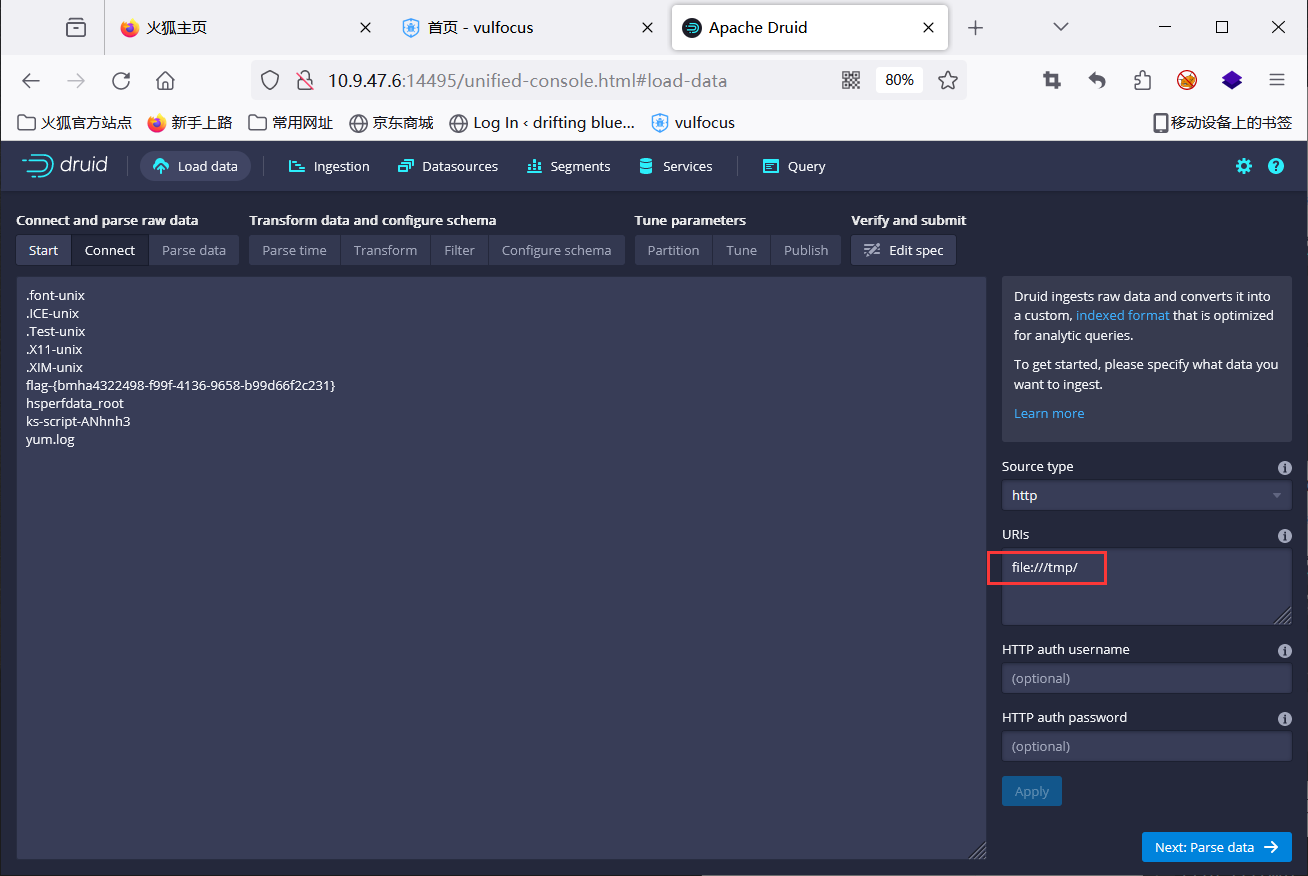
input {file {path => "/data/psj/test/*.csv"start_position => "beginning"sincedb_path => "/dev/null"}
}filter {csv {# 每行按逗号分割, 生成2个字段: topsid 和 title, (如果分割超过2列了,第三列则以 column3 命名)separator => ""columns => ["topsid", "title"]# 删除一些不需要索引到ES中去的字段(logstash默认生成的一些字段)remove_field => ["host", "@timestamp", "@version", "message","path"]} mutate {convert => {# 类型转换"topsid" => "integer""title" => "string"}}
}output {elasticsearch {hosts => "http://http://127.0.0.1:9200"index => "chantitletest"# 指定 文档的 类型为 "_doc"document_type => "_doc"# 指定doc id 为topsid字段的值document_id => "%{topsid}"manage_template => true# 使用自定义的模板写入,否则将会以logstash默认模板写入template => "/data/services/logstash-6.8.3/config/chantitletpe.json"template_overwrite => truetemplate_name => "chantitletpe"}stdout{codec => json_lines}
}(也可以采用 logstash filter 插件的 mutate 选项 将 SOH 转换成逗号):
filter {mutate{# 每一行内容默认是message, 将分隔符 \u0001 替换成 逗号gsub => [ "message","\u0001","," ]# @timestamp 字段是默认生成的, 名称修改成 createdrename => ["@timestamp", "created"]}csv {# 每行按逗号分割, 生成2个字段: topsid 和 title, (如果分割超过2列了,第三列则以 column3 命名)separator => ","columns => ["topsid", "title"]# 删除一些不需要索引到ES中去的字段(logstash默认生成的一些字段)remove_field => ["host", "@timestamp", "@version", "message","path"]} mutate {convert => {# 类型转换"topsid" => "integer""title" => "string"}}
}使用的自定义模板如下:
{"index_patterns": ["chantitle_v1","chantitletest"],"settings": {"number_of_shards": 3,"analysis": {"analyzer": {"my_hanlp_analyzer": {"tokenizer": "my_hanlp"},"pinyin_analyzer": {"tokenizer": "my_pinyin"}},"tokenizer": {"my_hanlp": {"enable_normalization": "true","type": "hanlp_standard"},"my_pinyin": {"keep_joined_full_pinyin": "true","lowercase": "true","keep_original": "true","remove_duplicated_term": "true","keep_first_letter": "false","keep_separate_first_letter": "false","type": "pinyin","limit_first_letter_length": "16","keep_full_pinyin": "true"}}}},"mappings": {"_doc": {"properties": {"created": {"type": "date","doc_values": false,"format": "yyyy-MM-dd HH:mm:ss"},"title": {"type": "text","fields": {"pinyin": {"type": "text","boost": 10,"analyzer": "pinyin_analyzer"},"raw": {"type": "keyword","doc_values": false}},"analyzer": "my_hanlp_analyzer"},"topsid": {"type": "long","doc_values": false}}}}
}上面给了一个 csv 文件导入 ES,这里再给个 txt 文件导入 ES 吧。txt 以逗号分割,每列的内容都在冒号里面,只需要前 4 列内容,一行示例数据如下:
“12345”,“12345”,“研讨区”,“12345”,“500”,“xxxx”,“2008-08-04 22:20:24”,“0”,“300”,“0”,“5”,“0”,“”,“0”,“0”,“”,“”,“0”,“0”
这里采用的是 logstash filter 的 dissect 插件。相比于 grok 插件,它的优点不是采用正规匹配的方式解析数据,速度较快,但不能解析复杂数据。只能够对较为规律的数据进行导入。logstash 配置文件如下:
input {file {path => "/data/psj/test/*.txt"start_position => "beginning"# sincedb_path => "/dev/null"}
}filter {dissect {mapping => {# 插件输入的每一行数据默认名称是message,由于每列数据在双引号里面,因此解析前4列数据的写法如下:"message" => '"%{topsid}","%{subsid}","%{subtitle}","%{pid}"'}# 删除自动生成的、用不着的一些字段remove_field => ["host", "@timestamp", "@version", "message","path"]convert_datatype => {# 类型转换"topsid" => "int""subsid" => "int""pid" => "int"}}
}output {elasticsearch {hosts => "http://127.0.0.1:9200"index => "chansubtitletest"document_type => "_doc"# 指定doc id 为topsid字段的值document_id => "%{subsid}"manage_template => true# 使用自定义的模板写入,否则将会以logstash默认模板写入template => "/data/services/logstash-6.8.3/config/chansubtitle.json"template_overwrite => truetemplate_name => "chansubtitle"}stdout{codec => json_lines}
}ubsid}"manage_template => true# 使用自定义的模板写入,否则将会以logstash默认模板写入template => "/data/services/logstash-6.8.3/config/chansubtitle.json"template_overwrite => truetemplate_name => "chansubtitle"}stdout{codec => json_lines}
}

![buuctf_练[CISCN2019 华东南赛区]Web4](https://img-blog.csdnimg.cn/img_convert/f6347a1efc00665ffd6b106652a3eef5.png)