文章目录
- 前言
- 论文 《Deformable DETR: Deformable Transformers for End-to-End Object Detection》的多尺度变形注意力的解读
- DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
- **2.** Deformable Attention Module
- Deformable Attention Module
- 3. Multi-Scale Deformable Attention Module
- Multi-scale Deformable Attention Module
- Deformable Transformer Encoder
- Deformable Transformer Decoder.
- A.2 CONSTRUCTING MULT-SCALE FEATURE MAPS FOR DEFORMABLE DETR
- 参考
前言
1、大多数现代物体检测框架受益于多尺度特征图 (Liu等人,2020)。
2、Deformable DETR: Deformable Transformers for End-to-End Object Detection 提出的可变形注意力模块可以自然地扩展为多尺度特征图。
论文 《Deformable DETR: Deformable Transformers for End-to-End Object Detection》的多尺度变形注意力的解读
DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION
2. Deformable Attention Module
- Given an input feature map x with size of CHW, let q index a query element with content feature zq and a 2-d reference point pq, the deformable attention feature is calculated by:
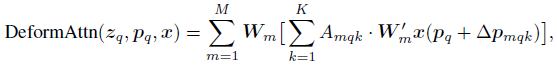
- where m indexes the attention head (M is number of heads), k indexes the sampled keys, and K is the total sampled key number (K≤HW).
Deformable Attention Module
- Δpmqk and Amqk denote the sampling offset and attention weight of the kth sampling point in the mth attention head, respectively.
- As pq+Δpmqk is fractional**, bilinear interpolation is applied.
- Both Δpmqk and Amqk are obtained via linear projection over the query feature zq.
- The query feature zq is fed to a linear projection operator of 3MK channels, where the first 2MK channels encode the sampling offsets Δpmqk, and the remaining MK channels are fed to a softmax operator to obtain the attention weights Amqk.
To be brief, two sets of channels are used to encode offsets in x and y directions. The remaining one set of channels is to encode attention weight.
These two sets of offsets are learnt, which has the similar concept in DCN.
- Let Nq be the number of query elements, when MK is relatively small, the complexity of the deformable attention module is of:
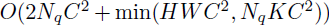
- When it is applied in DETR encoder, where Nq=HW, the complexity becomes O(HWC²), which is of linear complexity with the spatial size.
- When it is applied as the cross-attention modules in DETR decoder, where Nq=N (N is the number of object queries), the complexity becomes O(NKC²), which is irrelevant to the spatial size HW.
Deformable Attention Module
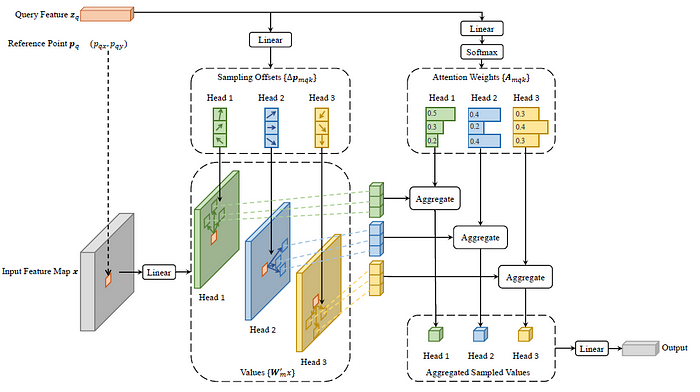
Deformable Attention Module,在图像特征上,应用Transformer注意力的核心问题是:it would look over all possible spatial locations。
为了解决这个问题,我们提出了一个可变形的注意模块(deformable attention module)。
受可变形卷积的启发 (Dai等,2017; Zhu等,2019b),可变形注意模块只关注参考点周围的一小部分关键采样点,而与特征图的空间大小无关,如图2所示,通过为每个查询仅分配少量固定数量的键,可以减轻收敛和特征空间分辨率的问题。
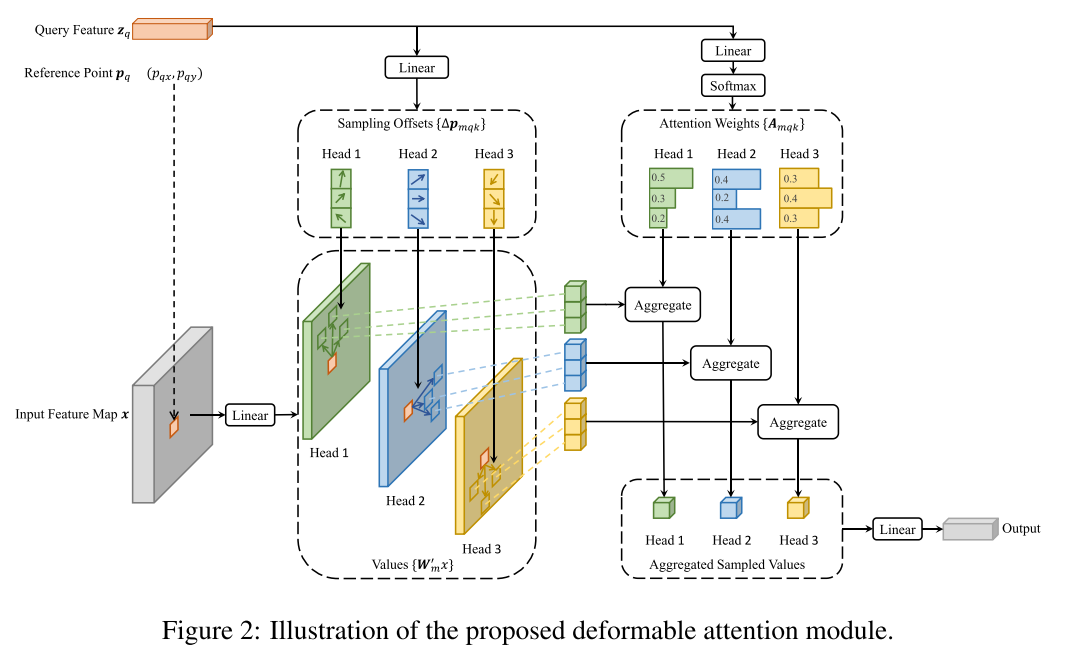
Given an input feature map x ∈ R C × H × W x ∈ R^{C×H×W} x∈RC×H×W, let q q q index a query element with content feature z q z_q zq and a 2-d reference point p q p_q pq,让 q q q索引一个具有内容特征 z q z_q zq和二维参考点 p q p_q pq的查询元素
the deformable attention feature is calculated by

where m m m indexes the attention head,
k k k indexes the sampled keys, and K K K is the total sampled key number (K << HW).
∆ p m q k ∆p_{mqk} ∆pmqk and A m q k A_{mqk} Amqk denote the sampling offset and attention weight of the k t h k_{th} kth sampling point in the m t h m_{th} mth attention head, respectively.
其中,m为注意头索引,k为采样键索引,K为总采样键数 (K << HW)。∆ pmqk和Amqk分别表示第m个注意头中第k个采样点的采样偏移和注意权重。
The scalar attention weight A m q k A_{mqk} Amqk lies in the range [0, 1], normalized by
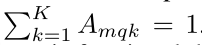
∆ p m q k ∈ R 2 ∆p_{mqk} ∈ R^2 ∆pmqk∈R2是具有无约束范围的二维实数
当 p q + ∆ p m q k p_q+∆p_{mqk} pq+∆pmqk为分数时,应用双线性插值,如Dai等人 (2017) 在计算 x ( p q + ∆ p m q k ) x(p_q + ∆p_{mqk}) x(pq+∆pmqk) 时
∆ p m q k ∆p_{mqk} ∆pmqk和 A m q k A_{mqk} Amqk都是通过对query feature z q z_q zq 的线性投影获得的
In implementation, the query feature z q z_q zq is fed to a linear projection operator of 3MK channels, where the first 2MK channels encode the sampling offsets ∆ p m q k ∆p_{mqk} ∆pmqk, and the remaining MK channels are fed to a softmax operator to obtain the attention weights A m q k A_{mqk} Amqk.
可变形注意模块设计用于将卷积特征图作为key elements进行处理。
设 N q N_q Nq为query elements的数量,当mk相对较小时,可变形注意模块的复杂度为 O ( 2 N q C 2 m i n ( H W C 2 , N q K C 2 ) ) O(2N_qC^2 min(HWC^2,N_qKC^2)) O(2NqC2min(HWC2,NqKC2)) (详见附录A.1)。
当它应用于DETR编码器时,其中 q = H W q = HW q=HW,复杂度变为 O ( H W C 2 ) O(HWC^2) O(HWC2),它与空间大小呈线性复杂度。
When it is applied as the cross-attention modules in DETR decoder, where Nq = N (N is the number of object queries), the complexity becomes O ( N K C 2 ) O(NKC^2) O(NKC2), which is irrelevant to the spatial size H W HW HW.
3. Multi-Scale Deformable Attention Module
Multi-scale deformable attention modules to replace the Transformer attention modules processing feature maps.
- Let {xl}, where l from 1 to L, be the input multi-scale feature maps, where xl has the size of C×Hl×Wl. Let ^pq ∈ [0, 1]² be the normalized coordinates of the reference point for each query element q, then the multi-scale deformable attention module is applied as:
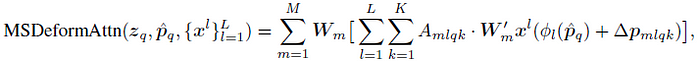
- The normalized coordinates (0, 0) and (1, 1) indicate the top-left and the bottom-right image corners, respectively. Φl(^pq) re-scales the normalized coordinates ^pq to the input feature map of the l-th level.
- The multi-scale deformable attention is very similar to the previous single-scale version, except that it samples LK points from multi-scale feature maps instead of K points from single-scale feature maps.
- The proposed attention module will degenerate to deformable convolution, as in DCN, when L=1, K=1, and W’m is fixed as an identity matrix.
The proposed (multi-scale) deformable attention module can also be perceived as an efficient variant of Transformer attention, where a pre-filtering mechanism is introduced by the deformable sampling locations.
Multi-scale Deformable Attention Module
Multi-scale Deformable Attention Module.大多数现代物体检测框架受益于多尺度特征图 (Liu等人,2020)。我们提出的可变形注意力模块可以自然地扩展为多尺度特征图。
Let x l l = 1 L {x^l}^L_{l=1} xll=1L be the input multi-scale feature maps, where x l ∈ R C × H l × W l x^l ∈ R^{C×H_l×W_l} xl∈RC×Hl×Wl.
Let p q ∈ [ 0 , 1 ] 2 p_q∈ [0, 1]^2 pq∈[0,1]2 be the normalized coordinates of the reference point for each query element q q q,
then the multi-scale deformable attention module is applied as
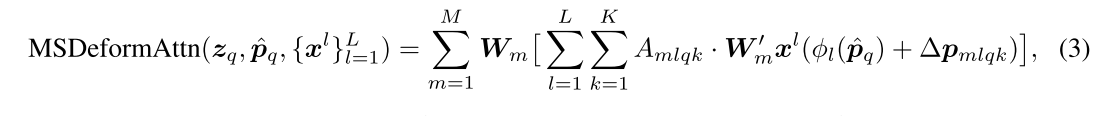
where m m m indexes the attention head,
l l l indexes the input feature level,
k k k indexes the sampling point.
∆ p m l q k ∆p_{mlqk} ∆pmlqk and A m l q k A_{mlqk} Amlqk denote the sampling offset and attention weight of the k t h k^{th} kth sampling point in the lth feature level and the m t h m^{th} mth attention head, respectively.
The scalar attention weight A m l q k A_{mlqk} Amlqk is normalized by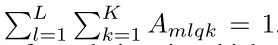
Here, we use normalized coordinates p q ∈ [ 0 , 1 ] 2 p_q ∈ [0, 1]^2 pq∈[0,1]2 for the clarity of scale formulation, in which the normalized coordinates (0, 0) and (1, 1) indicate the top-left and the bottom-right image corners, respectively.
Function φ l ( p q ) φ_l(p_q) φl(pq) in Equation 3 rescales the normalized coordinates p q p_q pq to the input feature map of the l t h l^{th} lth level.
方程3中的函数 φ将归一化坐标 p q p_q pq重新缩放到第 l l l级的输入特征图
多尺度可变形注意力与以前的单尺度版本非常相似,不同之处在于它从多尺度特征图中采样LK点,而不是从单尺度特征图中采样K点
The proposed attention module will degenerate to deformable convolution when L=1 K=1 and W ’ m ∈ R C v ∗ C W’_m ∈ R^{C_v*C} W’m∈RCv∗C is
fixed as an identity matrix单位矩阵
Deformable convolution is designed for single-scale inputs, focusing only on one sampling point for each attention head. How-
ever, our multi-scale deformable attention looks over multiple sampling points from multi-scale in-puts. The proposed (multi-scale) deformable attention module can also be perceived as an efficient variant of Transformer attention, where a pre-filtering mechanism is introduced by the deformable sampling locations
当采样点遍历所有可能的位置时,the (multi-scale) deformable attention module is equivalent to Transformer attention
Deformable Transformer Encoder
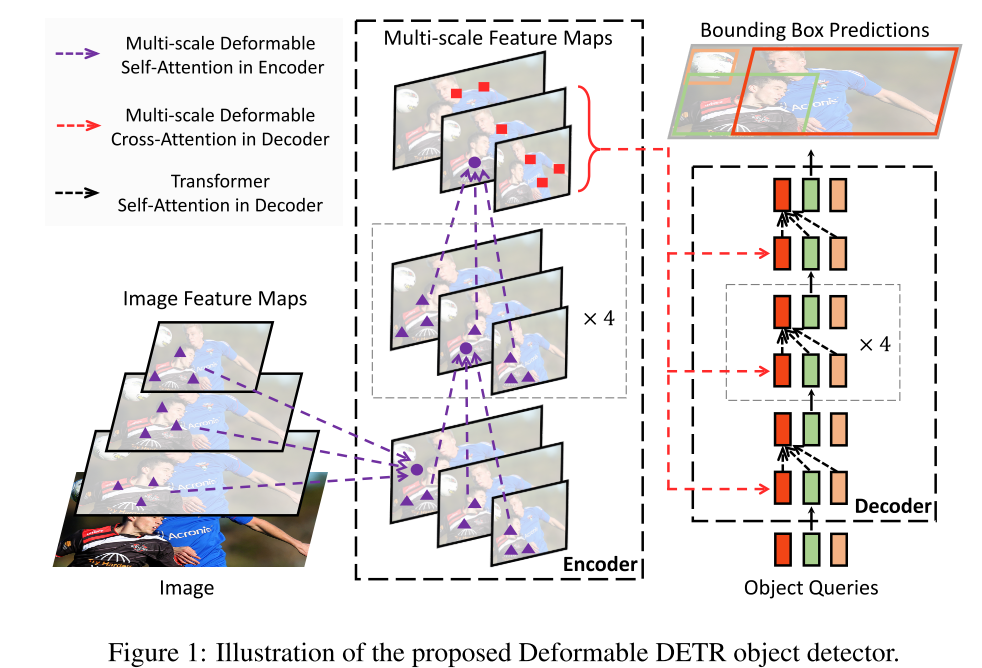
我们用提出的多尺度可变形注意模块代替了DETR中处理特征图的Transformer 注意模块。编码器的输入和输出都是具有相同分辨率的多尺度特征图。
在编码器中,我们从ResNet (He等人,2016) 中的阶段C3到C5的输出特征图中提取多尺度特征图(通过1 × 1卷积变换),其中 C l C_l Cl的分辨率比输入图像低 2 l 2_l 2l。最低分辨率特征图 x L x_L xL是通过最终C5阶段的3 × 3步幅2卷积获得的,表示为 C 6 C_6 C6。所有多尺度特征图都是C = 256通道。注意,FPN (Lin等,2017a) 中的自顶向下结构没有使用,因为我们提出的多尺度可变形注意力本身可以在多尺度特征图之间交换信息。附录a2还说明了多尺度特征图的构建。5.2部分的实验表明,添加FPN不会改善性能。
In application of the multi-scale deformable attention module in encoder, the output are of multi-scale feature maps with the same resolutions as the input. Both the key and query elements are of pixels from the multi-scale feature maps.
对于每个查询像素,参考点是其自身。为了确定每个查询像素位于哪个特征级别,除了位置嵌入之外,我们还在特征表示中添加了比例级别嵌入 (表示为el)。 与固定编码的位置嵌入不同,比例级嵌入 {el} 是随机初始化的,并与网络联合训练。
Deformable Transformer Decoder.
There are cross-attention and self-attention modules in the decoder. The query elements for both types of attention modules are of object queries. In the cross-attention modules, object queries extract features from the feature maps, where the key elements are of the output feature maps from the encoder. In the self-attention modules, object queries interact with each other, where the key elements are of the object queries. Since our proposed deformable attention module is designed for processing convolutional feature maps as key elements, we only replace each cross-attention module to be the multi-scale deformable attention module, while leaving the self-attention modules unchanged.
For each object query, the 2-d normalized coordinate of the reference point p q p_q pq is predicted from its object query embedding via a learnable linear projection followed by a sigmoid function.参考点 “p” 是通过可学习的线性投影和sigmoid函数从其object query embedding中预测的。
因为多尺度可变形注意模块提取参考点周围的图像特征,所以我们让检测头预测边界框作为相对偏移w.r.t.参照点,进一步降低优化难度。参考点用作框中心的初始猜测。检测头预测相对偏移w.r.t.参考点。查看附录A.3的详细信息。这样,学习的解码器注意力将与预测的边界框具有很强的相关性,这也加速了训练收敛。
通过用DETR中的可变形注意模块替换Transformer注意模块,我们建立了一个高效且快速的会聚检测系统,称为可变形DETR (参见图1)。
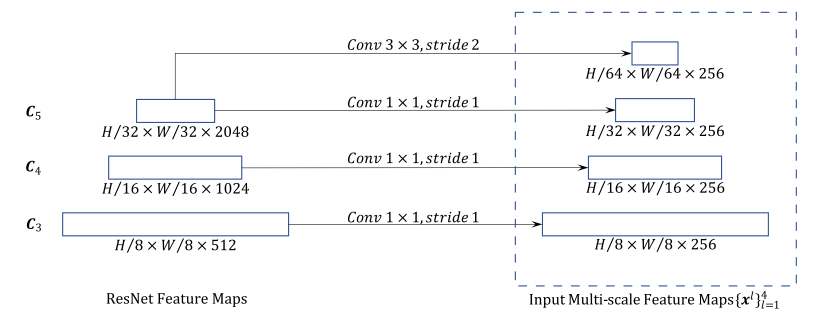
A.2 CONSTRUCTING MULT-SCALE FEATURE MAPS FOR DEFORMABLE DETR
正如4.1节所讨论并在图4中所示,编码器{xl}L−1 L =1 (L = 4)的输入多尺度特征映射是从ResNet中C3到C5阶段的输出特征映射中提取的(He et al., 2016)(通过1×1卷积进行转换)。最低分辨率的feature map xL是通过在最后的C5 stage上的3×3 stride 2卷积获得的。注意,我们没有使用FPN (Lin et al., 2017a),因为我们提出的多尺度变形注意本身可以在多尺度特征图之间交换信息。
参考
https://sh-tsang.medium.com/review-deformable-transformers-for-end-to-end-object-detection-e29786ef2b4c
(正文完)