文章目录
- 1.集群配置
- 2.zookeeper的群起脚本
- 3. Zookeeper节点的创建和删除相关
- 4. Zookeeper的选举机制
1.集群配置
-
Zookeeper的集群个数最好保证是奇数个数,因为Zookeeper的选举过程有一个“半数机制”。
-
5台服务器,可以设置Zookeeper的集群为3或者5,本文将Zookeeper的集群设置为5。
s1 s2 s3 s4 gracal Server1(follower) Server2(follower) Server3(may be learder) Server4(follower) Server5(follower) -
第一次启动时,会采用半数选举机制,选出learder
2.zookeeper的群起脚本
-
每次都需要在各个服务器分别启动zookeeper比较麻烦,因此可以编写脚本群起zookeeper集群
-
在s1的
/home/gaochuchu/bin目录下创建zk.sh脚本来启停zookeeper集群#启动zookeeper集群 zk.sh start #停止zookeeper集群 zk.sh stop #查看所有的zookeeper的状态 zk.sh status
3. Zookeeper节点的创建和删除相关
- 节点类型
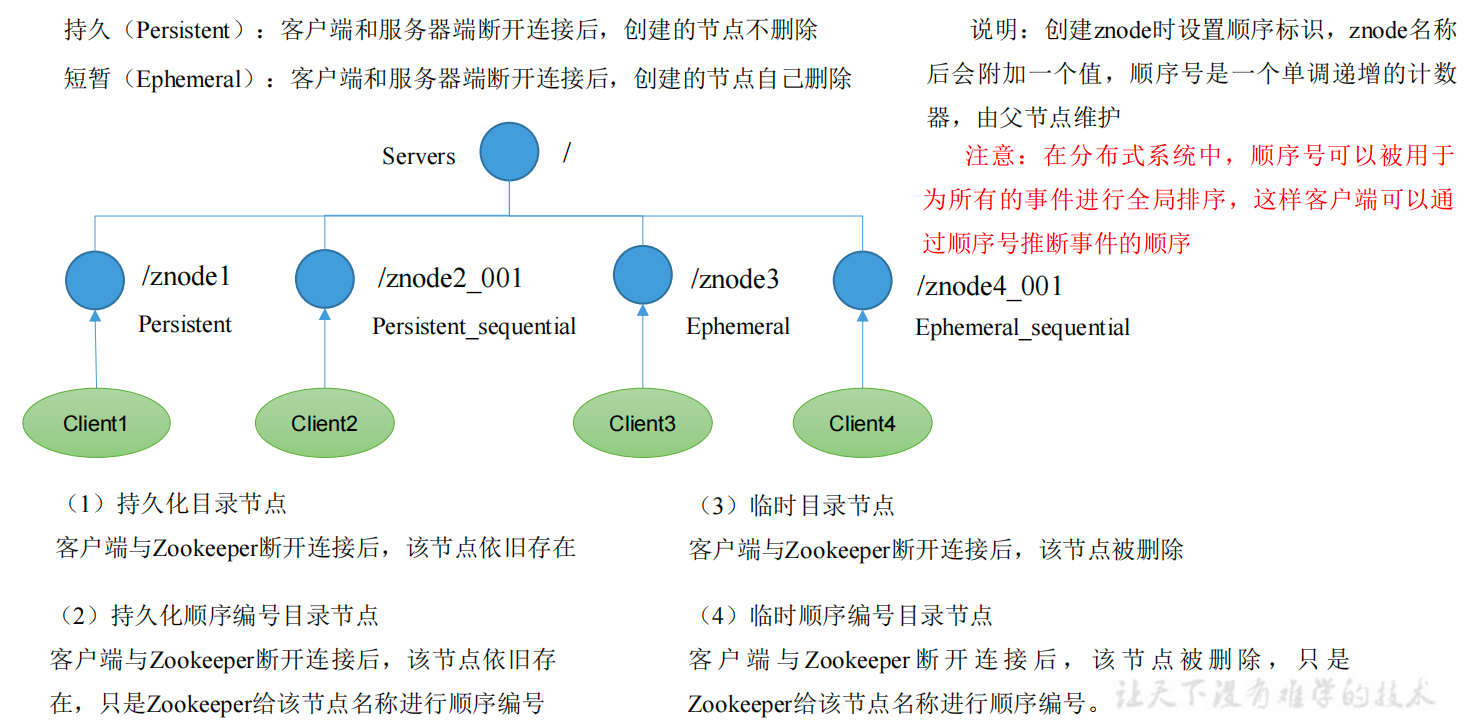
-
创建普通节点(永久节点+不带序号)
#create 节点目录位置 值 create /a "ainfo" -
获得节点的值
#get -s 获取节点的值 get -s /a -
创建带序号的节点(永久节点+带序号)
#create -s create -s /a/b/c "cinfo" -
创建短暂节点(短暂节点+不带序号)
#create -e create -e /a/b "binfo" -
创建短暂节点(短暂节点+带序号)
#create -e -s create -e -s /a/b/c "cinfo" -
查看当前znode所包含的内容
ls /a -
查看当前节点的详细数据
ls -s /a -
删除节点
delete /a/b -
若是一个节点目录下有多个子节点,若要删除该目录下的所有子节点,以及子节点的子节点
deleteall /sanguo/shuguo
4. Zookeeper的选举机制
Zookeeper的选举机制的理解,有助于理解后续对于Spark等各种分布式框架配置高可用的备用主节点的替换流程
-
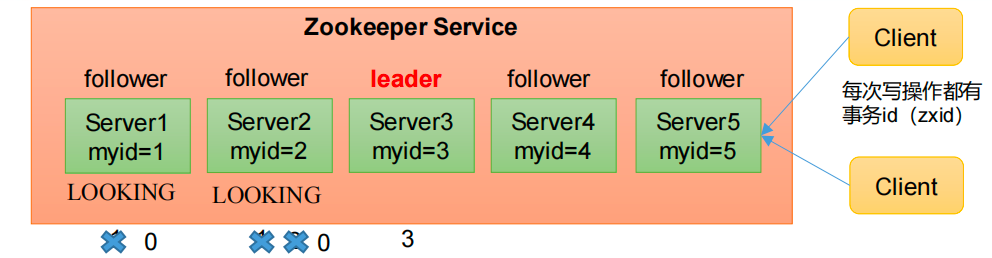
如果是第一次启动,采用半数选举机制
-
假设Zookeeper集群中有五台服务器,其具体的流程如下:
-
1.首先Server1启动,发起一次选举。Server1投自己一票,此时Server1的票数1票,不够半数以上(3票),选举无法完成,Server1的状态保持为LOOKING;
-
2.Server2启动,再发起一次选举。Server1和Server2分别投自己一票并交换选票信息:此时Server1发现Server2的maid(服务器编号,唯一)比自己目前投票选举的(Server1)大,因此Server1更改选票为推选Server2.此时Server1的票数是0票,而Server2的票数是2票,没有半数以上结果,选举无法完成,此时Server1和Server2都保持LOOKING状态。
-
3.Server3启动,发次一次选举。通过Server1、Server2、Server3分别投自己一票并且交换选票信息:此时Server1和Server2发现Server3的myid大于自身,因此Server1和Server2都转投Server3,此时Server3的票数为3,因此Server3当选Leader。Server1和2更改状态为FOLLOWING,Server3更改为LEADING
-
4.Server4启动,此时发起选组,但是由于Server1和Server2都已经不是LOOKING状态,因此不会更改选票信息;Server3为3票,Server4为1票。Server4服从多数,更改选票信息为Server3,并更改状态为FOLLOWING;
-
5.Server5启动,情况同Server4,也更改状态为FOLLOWING;
因此可以得出结论:第一次启动时,只要确定的Leader之后,后续的选举过程不会再改变Leader,只是修改Server的状态为FOLLOWING
-
-
-
如果不是第一次启动,Zookeeper的选举机制为:
如果不是第一次启动,可能涉及了几个概念:
-
SID:服务器ID。用来唯一标识一台Zookeeper集群的机器,每台机器不能重复,和myid一致。
-
ZXID:事务ID。ZXID是事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID不一定完全一致,这和Zookeeper服务器对于客户端“更新请求”的处理逻辑有关。
-
每次对节点数据的变更都会更新事务id,事务id的值越大就说明数据越新,在选举算法中数据越新权重越大。
-
关于ZXID的组成部分,其有更详细的解释:
实现中 zxid 是一个 64 位的 数字,它高32位是epoch(ZAB协议通过epoch编号来 区分 Leader 周期变化的策略)用来标识 leader 关系是否 改变,每次一个 leader 被选出来,它都会有一个新的 epoch=(原来的epoch+1),标识当前属于那个leader的 统治时期。低32位用于递增计数
epoch :可以理解为当前集群所处的年代或者周期,每个 leader就像皇帝,都有自己的年号,所以每次改朝换代, leader 变更之后,都会在前一个年代的基础上加 1 。这样就算旧的leader崩溃恢复之后 ,也没有人听他的了,因为follower只听从当前年代的leader的命令
-
Epoch:每个Leader任期的代号。没有Leader的时同一轮投票过程中的逻辑时钟的值是相同的。每投完一次票这个数据就会增加。
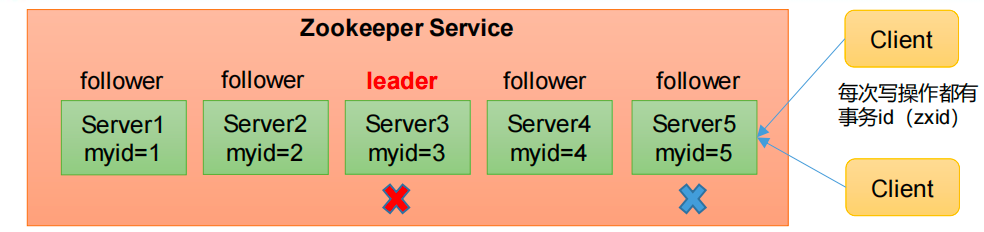
其具体的选举过程如下:
-
当Zookeeper集群中的一台服务器出现以下两种情况之一的时候,会进入Leader的选举:
- 服务器初始化启动
- 服务器运行期间无法和Leader保持连接
-
而当一台机器进入Leader选举流程的时候,当前集群中也会出现两种状态:
-
集群中本来已经存在一个Leader
假设Server5断开连接,这对应第一种已经存在leader的状态,如果此时试图去选举Leader时,会被告知当前服务器的Leader的信息,仅仅需要和Leade r机器重新建立连接,并进行状态同步。
-
集群中确实不存在Leader的情况。
假设此时的Server3也突然出现故障挂了,此时就需要进行Leader的选举。
Leader选举时的优先级:EPOCH>ZXID>SID
服务器 Server1 Server2 Server4 (EPOCH,ZXID,SID) (1,8,1) (1,8,2) (1,8,4) 此时按照选举优先级:
1.EPOCH大的直接胜出
2.EPOCH相同,则ZXID大的胜出
3.ZXID相同,则SID大的胜出
因此此时的Server2应该胜出,成为新的Leader,且EPOCH加一
-
-
问题:当此时的Server3和Server5故障恢复重新加入集群时,会发生什么?
此时会同步Leader的EPOCH的值,因为当前Leader的EPOCH值比之前未更新的大,因此会自动和Leader更新EPOCH的值,自己会转为FOLLOWING状态
-
-
-





![[减脂期食谱] 自制千岛酱](https://img-blog.csdnimg.cn/b8efb22f8cf44d63a0957f078b2dbcdd.png)