1.概述
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。其核心组件包含Producer、Broker、Consumer,以及依赖的Zookeeper集群。其中Zookeeper集群是Kafka用来负责集群元数据的管理、控制器的选举等。
2.内容
目前,Kafka在使用的过程当中,会出现一些问题。由于重度依赖Zookeeper集群,当Zookeeper集群性能发生抖动时,Kafka的性能也会收到很大的影响。因此,在Kafka发展的过程当中,为了解决这个问题,提供KRaft模式,来取消Kafka对Zookeeper的依赖。
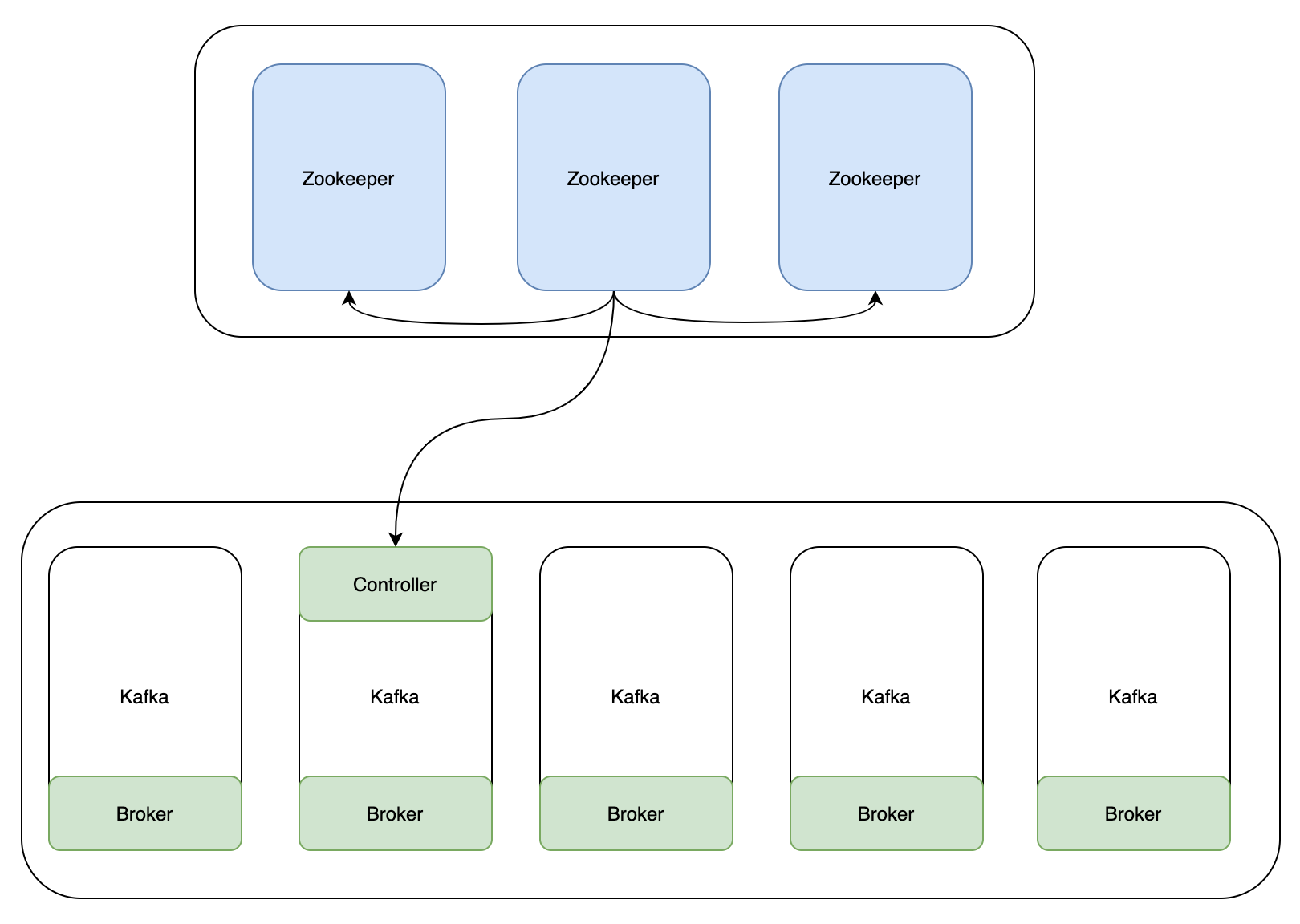
上图是在未使用KRaft模式时,Kafka的一个架构,在做元数据管理、Controller的选举等都需要依赖Zookeeper集群。

在Kafka引入KRaft新内部功能后,对Zookeeper的依赖将会被取消。在 KRaft 中,一部分 broker 被指定为控制器,这些控制器提供过去由 ZooKeeper 提供的共识服务。所有集群元数据都将存储在 Kafka 主题中并在内部进行管理。
2.1 KRaft模式的优势
- 更简单的部署和管理——通过只安装和管理一个应用程序,Kafka 现在的运营足迹要小得多。这也使得在边缘的小型设备中更容易利用 Kafka;
- 提高可扩展性——KRaft 的恢复时间比 ZooKeeper 快一个数量级。这使我们能够有效地扩展到单个集群中的数百万个分区。ZooKeeper 的有效限制是数万;
- 更有效的元数据传播——基于日志、事件驱动的元数据传播可以提高 Kafka 的许多核心功能的性能。
1. KRaft集群节点角色

在 KRaft 模式下,Kafka 集群可以以专用或共享模式运行。在专用模式下,一些节点将其process.roles配置设置为controller,而其余节点将其设置为broker。对于共享模式,一些节点将process.roles设置为controller, broker并且这些节点将执行双重任务。采用哪种方式取决于集群的大小。
2. KRaft模式控制器
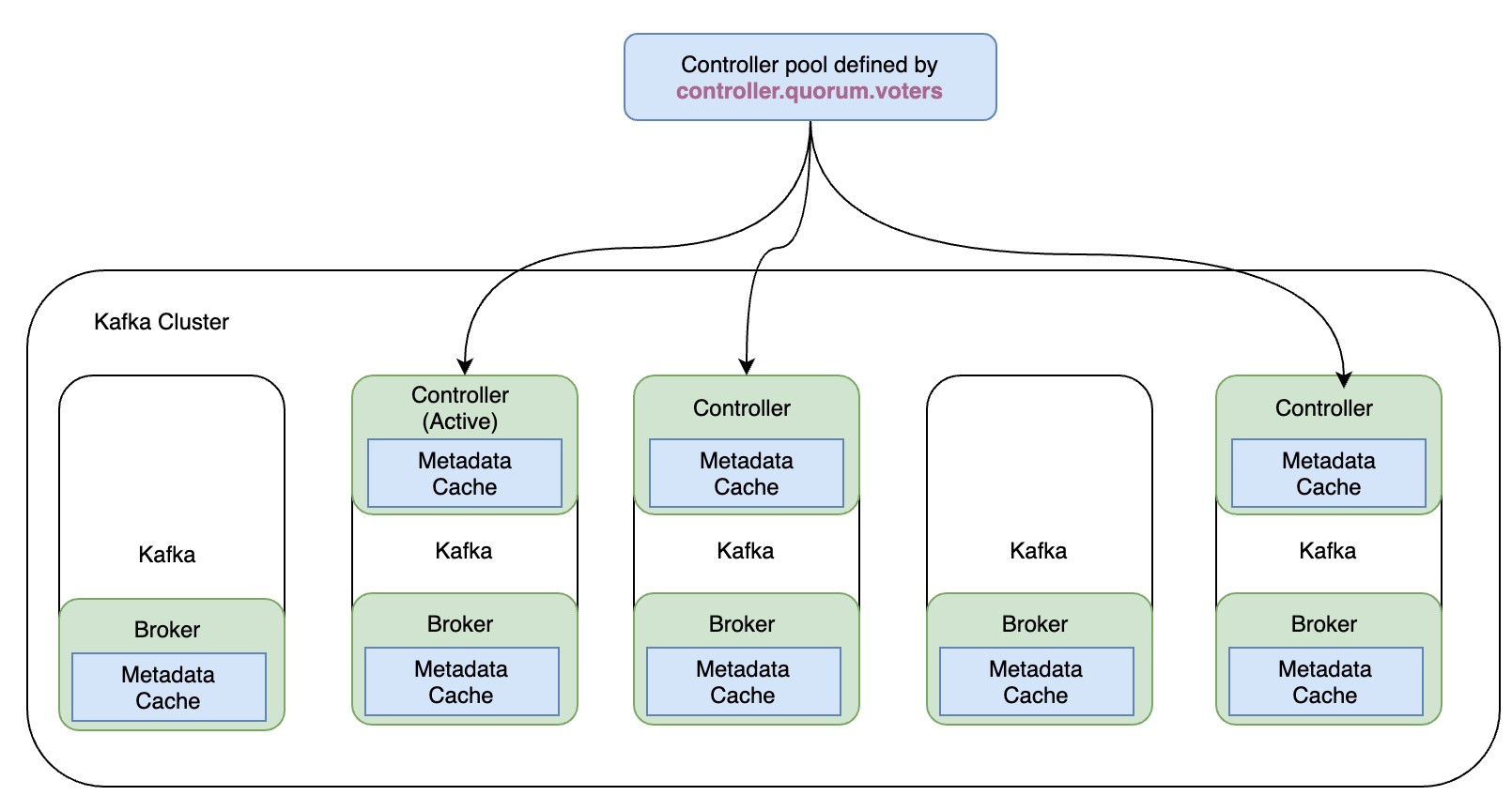
在 KRaft 模式集群中充当控制器的代理列在controller.quorum.voters每个代理上设置的配置属性中。这允许所有代理与控制器进行通信。这些控制器代理之一将是活动控制器,它将处理与其他代理通信对元数据的更改。
所有控制器代理都维护一个保持最新的内存元数据缓存,以便任何控制器都可以在需要时接管作为活动控制器。这是 KRaft 的特性之一,使其比基于 ZooKeeper 的控制平面高效得多。
3. KRaft集群元数据

KRaft 基于 Raft 共识协议,该协议作为 KIP-500 的一部分引入 Kafka,并在其他相关 KIP 中定义了更多细节。在 KRaft 模式下,集群元数据(反映所有控制器管理资源的当前状态)存储在名为__cluster_metadata. KRaft 使用这个主题在控制器和代理节点之间同步集群状态更改。
活动控制器是这个内部元数据主题的单个分区的领导者。其他控制器是副本追随者。经纪人是副本观察者。因此,不是控制器将元数据更改广播给其他控制器或代理,而是它们各自获取更改。这使得保持所有控制器和代理同步非常有效,并且还缩短了代理和控制器的重启时间。
4. KRaft元数据复制

由于集群元数据存储在 Kafka 主题中,因此该数据的复制与我们在数据平面复制模块中看到的非常相似。活动控制器是元数据主题的单个分区的领导者,它将接收所有写入。其他控制器是跟随者,将获取这些更改。我们仍然使用与数据平面相同的偏移量和领导者时期。但是,当需要选举领导者时,这是通过仲裁完成的,而不是同步副本集。因此,元数据复制不涉及 ISR。另一个区别是元数据记录在写入每个节点的本地日志时会立即刷新到磁盘。
5. Leader选举
当集群启动时以及当前领导者停止时,无论是作为滚动升级的一部分还是由于故障,都需要进行控制器领导者选举。现在让我们看一下 KRaft 领导人选举所涉及的步骤。
- 投票请求:
- 当需要选举leader控制器时,其他控制器将参与选举新的leader。一个控制器,通常是第一个意识到需要新领导者
VoteRequest的控制器,将向其他控制器发送一个。该请求将包括候选者的最后一个偏移量以及与该偏移量关联的时期。它还将增加该时期并将其作为候选时期传递。候选控制器也将为该时期投票给自己;
- 当需要选举leader控制器时,其他控制器将参与选举新的leader。一个控制器,通常是第一个意识到需要新领导者
- 投票响应:
- 当跟随者控制器接收到 a
VoteRequest时,它将检查它是否看到了比候选者传入的时期更高的时期。如果它有,或者如果它已经在同一时期投票给了不同的候选人,它将拒绝该请求。否则,它将查看候选人传递的最新偏移量,如果它与自己的相同或更高,它将授予投票。该候选控制器现在有两票:它自己的票和刚刚被授予的票。第一个获得多数票的控制器成为新的领导者。
- 当跟随者控制器接收到 a
- 完成:
-
一旦候选人获得了多数票,它将认为自己是领导者,但它仍然需要将此通知其他控制者。为此,新领导者将向
BeginQuorumEpoch其他控制器发送包括新纪元在内的请求。现在选举已经完成。当旧的leader控制器重新上线时,它将在新的epoch跟随新的leader,并将自己的元数据日志与leader同步。
-
3.KRaft 集群元数据快照

没有明确的点我们知道不再需要集群元数据,但我们不希望元数据日志无休止地增长。此要求的解决方案是元数据快照。每个控制器和代理都会定期对其内存中的元数据缓存进行快照。这个快照被保存到一个用结束偏移和控制器纪元标识的文件中。现在我们知道元数据日志中所有早于该偏移量和纪元的数据都已安全存储,并且可以将日志截断到该点。快照连同元数据日志中的剩余数据仍然会为我们提供整个集群的完整元数据。
3.1 读取快照
元数据快照的两个主要用途是代理重新启动和新代理上线。
当现有代理重新启动时,它 (1) 将其最近的快照加载到内存中。然后EndOffset从其快照开始,它 (2) 从其本地__cluster_metadata日志中添加可用记录。然后它 (3) 开始从活动控制器中获取记录。如果获取的记录偏移量小于活动控制器LogStartOffset,则控制器响应包括其最新快照的快照 ID。然后代理 (4) 获取此快照并将其加载到内存中,然后再次继续从__cluster_metadata分区领导者(活动控制器)获取记录。
当一个新的代理启动时,它 (3) 第一次开始从活动控制器中获取记录。通常,此偏移量将小于活动控制器LogStartOffset,并且控制器响应将包括其最新快照的快照 ID。代理 (4) 获取此快照并将其加载到内存中,然后再次继续从__cluster_metadata分区领导者(活动控制器)获取记录。
该__cluster_metadata主题将snapshot作为cleanup.policy。Kafka 控制器和元数据缓存将在内存中表示复制的日志,最多可达高水位线。在执行快照时,Kafka 控制器和元数据缓存会将这个内存状态序列化到磁盘。磁盘上的此快照文件由已包含的复制日志的结束偏移量和纪元描述。
Kafka 控制器和元数据缓存将在 Kafka Raft 客户端完成生成新快照时通知它。将日志的前缀截断到最新的快照是安全的。主题分区将__cluster_metadata拥有最新的快照和零个或多个旧快照。这些额外的快照必须被删除,这在“何时删除快照”中有描述。
3.2 快照设计
Kafka Raft 主题分区如下所示:
![]()
Kafka Replicated Log:LogStartOffset -- high-watermark -- LEO --V V V-----------------------------------------------offset: | x | ... | y - 1 | y | ... | | ... | |epoch: | b | ... | c | d | ... | | ... | |-----------------------------------------------Kafka Snapshot Files:<topic_name>-<partition_index>/x-a.checkpoint <topic_name>-<partition_index>/y-c.checkpoint
![]()
需要注意的是,checkpoint将使用扩展名,因为 Kafka 已经有一个带有snapshot扩展名的文件。
-
LEO - 日志结束偏移量 - 要写入磁盘的下一个偏移量。
-
high-watermark - 已复制到 N/2 + 1 个副本的最大偏移量和 epoch。
-
LogStartOffset - 日志开始偏移量 - 复制日志中的最小偏移量。
3.3 快照格式
Kafka 控制器和元数据缓存负责快照的内容。每个快照都由一个唯一标识SnapshotId,即快照中包含的复制日志中记录的纪元和结束偏移量。快照将存储在主题分区目录中,名称为<SnapshotId.EndOffset>-<SnapshotId.Epoch>.checkpoint. 例如,对于主题 __cluster_metadata、分区 0、快照结束偏移 5120793 和快照 epoch 2,完整文件名将是__cluster_metadata-0/00000000000005120793-00000000000000000002.checkpoint.
快照时期将在订购快照时使用,更重要的LastFetchedEpoch是在 Fetch 请求中设置字段时使用。追随者可能有快照和空日志。在这种情况下,follower 将LastFetchEpoch在 Fetch 请求中设置时使用快照的纪元。
快照文件的磁盘格式将与日志格式的版本 2 相同。这是版本 2 的日志格式供参考:
![]()
RecordBatch => BatchHeader [Record]BatchHeaderBaseOffset => Int64Length => Int32PartitionLeaderEpoch => Int32Magic => Int8CRC => Uint32Attributes => Int16LastOffsetDelta => Int32 // also serves as LastSequenceDeltaFirstTimestamp => Int64MaxTimestamp => Int64ProducerId => Int64ProducerEpoch => Int16BaseSequence => Int32Record =>Length => VarintAttributes => Int8TimestampDelta => VarlongOffsetDelta => VarintKey => BytesValue => BytesHeaders => [HeaderKey HeaderValue]HeaderKey => StringHeaderValue => Bytes
![]()
使用日志格式的版本 2 将允许 Kafka 控制器和元数据缓存压缩记录并识别快照中的损坏记录。即使快照使用日志格式存储此状态,也没有要求:
- 在and中分别使用有效的
BaseOffset和。OffsetDeltaBatchHeaderRecord - 使快照中的记录与复制日志中的记录相匹配。
3.4 快照记录
为了允许 KRaft 实现在不影响 Kafka 控制器和元数据缓存的情况下包含有关快照的附加信息,快照将包含两个控制记录批次。控制记录批次SnapshotHeaderRecord 将始终是快照中的第一个记录批次。控制记录批次SnapshotFooterRecord 将是快照中的最后一个记录批次。这两条记录将具有以下架构。
1.快照头架构
![]()
{"type": "data","name": "SnapshotHeaderRecord","validVersions": "0","flexibleVersions": "0+","fields": [{"name": "Version", "type": "int16", "versions": "0+","about": "The version of the snapshot header record"},{ "name": "LastContainedLogTimestamp", "type": "int64", "versions": "0+","about": "The append time of the last record from the log contained in this snapshot" }]
}
![]()
2.快照脚架构
![]()
{"type": "data","name": "SnapshotFooterRecord","validVersions": "0","flexibleVersions": "0+","fields": [{ "name": "Version", "type": "int16", "versions": "0+","about": "The version of the snapshot footer record" }]
}
![]()