1. 概要说明
SQL SERVER的表分区功能是为了将一个大表(表中含有非常多条数据)的数据根据某条件(仅限该表的主键)拆分成多个文件存放,以提高查询数据时的效率。创建表分区的主要步骤是
1、确定需要以哪一个字段作为分区条件;
2、拆分成多少个文件保存该表;
3、分区函数(拆分条件);
4、分区方案(按拆分函数拆分后需要对应到哪些文件组中去)。
不是企业版的sql server不支持分区;
参考:SQL SERVER 表分区实施步骤_sqlserver表分区步骤_Henry_Wu001的博客-CSDN博客
sql server 分区表 性能 sqlserver分区表实战_mob6454cc77db30的技术博客_51CTO博客
(0.1)SQL Server分区介绍
在SQL Server中,数据库的所有表和索引都视为已分区表和索引,默认这些表和索引值包含一个分区;也就是说表或索引至少包含一个分区。SQL Server中数据是按水平方式分区,是多行数据映射到单个分区。已经分区的表或者索引,在执行查询或者更新时,将被看作为单个逻辑实体;简单说来利用分区将一个表数据分多个表来存储,对于大数据量的表,将表分成多块查询,若只查询某个分区数据将降低消耗提高效率。需要注意的是单个索引或者表的分区必须位于一个数据库中。在使用大量数据管理时,SQL Server使用分区可以快速访问数据子集,减少io提高效率。
同时不同分区可以存放在不同文件组里,文件组若能存放在不同逻辑磁盘上,则可以实现io的并发使用以提高效率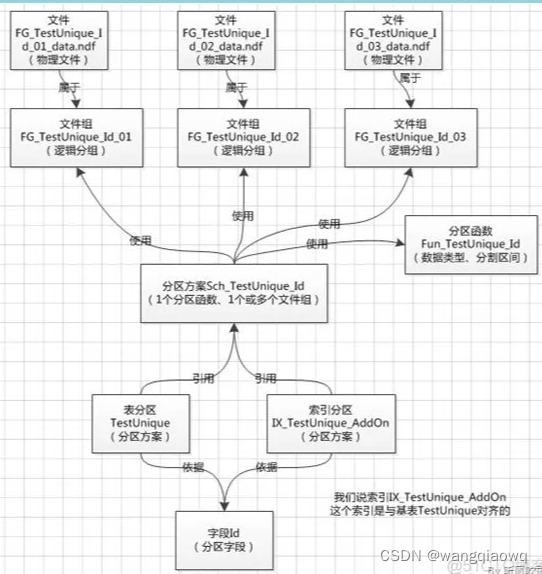
(0.2)SQL Server分区创建概述
创建分区函数:确定分区方式和界点
创建分区架构:将分区函数指定的分区映射到文件组
新建分区表
索引分区知识详解
(0.3)SQL Server分区管理概述
拆分分区(split)
合并分区(merge)
切换分区(switch)
$PARTION
【1】创建表分区
未分区的表,相当于只有一个分区,只能存储在一个FileGroup中;对表进行分区后,每一个分区都存储在一个FileGroup,或分布式存储在不同的FileGroup中。对表进行分区的过程,实际上是将逻辑上完整的一个表,按照特定的字段拆分成多个分区,分散到相同或不同的FileGroup中,每一个部分叫做表的一个分区(Partition),一个分区实际上是一个独立的,内部的物理表。也就是说,分区表在逻辑上是一个表,而在物理上是多个完全独立的表。
分区(Partition)的特性是:
每一个Partition在FileGroup中都独立存储,分区之间是相互独立的
每一个parititon都属于唯一的表对象,
每一个Partition 都有唯一的ID,
每一个Partition都有一个编号(Partition Number),同一个表的分区编号是唯一的,从1开始递增;
Step0,准备工作:构建文件组和文件
登录后复制
--添加文件组
alter database testSplit add filegroup db_fg1
--添加文件到文件组
alter database testSplit add file
(name=N'ById1',filename=N'J:\Work\数据库\data\ById1.ndf',size=5Mb,filegrowth=5mb)
to filegroup db_fg1
一,新建分区表分为三步
Step1, 创建分区函数
要先创建函数
分区函数的作用是提供分区字段的类型和分区的边界值,进而决定分区的数量
CREATE PARTITION FUNCTION [pf_int](int)
AS RANGE LEFT
FOR VALUES (10, 20)
分区函数pf_int 的含义是按照int类型分区,分区的边界值是10,20,left表示边界值属于左边界。两个边界值能够分成三个分区,别是(-infinite,10],(10,20],(20,+infinite)。
Step2,创建分区架构(Scheme)
再创建架构、应用函数
分区架构的作用是为Parition分配FileGroup,在逻辑上,Partition Scheme和FileGroup是等价的,都是数据存储的逻辑空间,只不过Partition Scheme指定的是多个FileGroup。
CREATE PARTITION SCHEME [ps_int]
AS PARTITION [pf_int]
TO ([PRIMARY], [db_fg1], [db_fg1])
不管是在不同的FileGroup中,还是在相同的FileGroup中,分区都是独立存储的。
分区scheme的所有分区都存储到相同的文件组中:
CREATE PARTITION SCHEME [ps_int]
AS PARTITION [pf_int]
ALL TO ([PRIMARY])
Step3,新建分区表
新建分区表,实际上是在创建Table时,使用on子句指定数据存储的逻辑位置是分区架构(Partition Scheme)
create table dbo.dt_test
(
ID int,
code int
)
on [ps_int] (id)
查看分区编号(Partition Number)
分区编号(Partition Number) 从1开始,从最左边的分区向右依次递增+1,边界值最小的分区编号是1,
例如,对于以下分区函数:
CREATE PARTITION FUNCTION pf_int_Left (int)
AS
RANGE LEFT
FOR VALUES (10,20);
分区的边界值(Boundary Value)是10,20, 边界值属于左边界(Range Left),该分区函数 pf_int_Left 划分了三个分区(Partition),范围区间是:(-infinite,10], (10,20], (20,+infinite),(小括号表示不包括边界值,中括号表示包括边界值),系统分配的分区编号分别是:1,2,3。用户可以通过使用$Partition函数 查看分区编号,调用语法格式是:
$Partition.Partition_Function(Partition_Column_Value)
例如,通过$Partition函数 查看分区列值为21时,该行数据所在的分区编号:
select $Partition.pf_int_left(21)
由于分区列值是21, 属于范围(20,+infinite),因此分区编号是:3。
【2】对现有表分区
在SQL Server中,普通表可以转化为分区表,而分区表不能转化为普通表,普通表转化成分区表的过程是不可逆的,将普通表转化为分区表的方法是:
在分区架构(Partition Scheme)上创建聚集索引,就是说,将聚集索引分区。
数据库中已有分区函数(partition function) 和分区架构(Partition scheme):
-- create parition function
CREATE PARTITION FUNCTION pf_int_Left (int)
AS RANGE LEFT
FOR VALUES (10,20);
--determine partition number
select $Partition.pf_int_left(21)
CREATE PARTITION SCHEME PS_int_Left
AS PARTITION pf_int_Left
TO ([primary], [primary], [primary]);
如果在普通表上存在聚集索引,并且聚集索引列是分区列,那么重建聚集索引,就能使表转化成分区表。聚集索引的创建有两种方式:使用clustered 约束(primary key 或 unique约束)创建,使用 create clustered index 创建。
【2.1】在分区架构(Partition Scheme)上,创建聚集索引
如果聚集索引是使用 create clustered index 创建的,并且聚集索引列就是分区列,使普通表转换成分区表的方法是:删除所有的 nonclustered index,在partition scheme上重建clustered index
1,表dbo.dt_partition的聚集索引是使用 create clustered index 创建的,
create table dbo.dt_partition
(
ID int,
Code int
)
create clustered index cix_dt_partition_ID
on dbo.dt_partition(ID)
2,从系统表Partition中,查看该表的分区只有一个
select *
from sys.partitions p
where p.object_id=object_id(N'dbo.dt_partition',N'U')
3,使用partition scheme,重建表的聚集索引
create clustered index cix_dt_partition_ID
on dbo.dt_partition(ID)
with(drop_existing=on)
on PS_int_Left(ID)
4,重建聚集索引之后,表的分区有三个
select *
from sys.partitions p
where p.object_id=object_id(N'dbo.dt_partition',N'U')
【2.4】普通表=》分区表,不可逆
普通表转化成分区表的过程是不可逆的,普通表能够转化成分区表,而分区表不能转化成普通表。
普通表存储的Location是FileGroup,分区表存储的Location是Partition Scheme,在SQL Server中,存储表数据的Location叫做Data Space。
通过在Partition Scheme上创建Clustered Index ,能够将已经存在的普通表转化成partition table,但是,将Clustered index删除,表仍然是分区表,转化过程(将普通表转换成分区表)是不可逆的;
一个Partition Table 是不能转化成普通表的,即使通过合并分区,使Partiton Table 只存在一个Partition,这个表的仍然是Partition Table,这个Table的Data Space 是Partition Scheme,而不会转化成File Group。
从 sys.data_spaces 中查看Data Space ,共有两种类型,分别是FG 和 PS。
FG是File Group,意味着数据表的数据存储在File Group分配的存储空间,一个Table 只能存在于一个FileGroup中。PS 是Partition Scheme,意味着将数据分布式存储在不同的File Groups中,存储数据的File Group是根据Partition column值的范围来分配的。对于分区表,SQL Server从指定的File Group分配存储空间,虽然一个Table只能指定一个Partition Scheme,但是其数据却分布在多个File Groups中,这些File Groups由Partition Scheme指定,可以相同,也可以不同。
【3】分区切换
在SQL Server中,对超级大表做数据归档,使用select和delete命令是十分耗费CPU时间和Disk空间的;
SQL Server必须记录相应数量的事务日志,而使用switch操作归档分区表的老数据,十分高效,switch操作不会移动数据,只是做元数据的置换;
因此,执行分区切换操作的时间是非常短暂的,几乎是瞬间完成,但是,在做分区切换时,源表和靶表必须满足一定的条件:
表的结构相同:列的数据类型,可空性(nullability)相同;
索引结构必须相同:索引键的结构,聚集性,唯一性,列的可空性必须相同;
主键约束:如果源表存在主键约束,那么靶表必须创建等价的主键约束;
唯一约束:唯一约束可以使用唯一索引来实现;
索引键的结构:索引键的顺序,包含列,唯一性,聚集性都必须相同;
存储的数据空间(data space)相同:源表和靶表必须创建在相同的FileGroup或Partition Scheme上;
分区切换是将源表中的一个分区,切换到靶表(target_table)中,靶表可以是分区表,也可以不是分区表,switch操作的语法是:
ALTER TABLE schema_name . table_name
SWITCH [ PARTITION source_partition_number_expression ]
TO target_table [ PARTITION target_partition_number_expression ]
【3.2】源表和目标表的结构必须相同
1,数据列的可空性必须相同(nullability)
2,数据列的数据类型必须相同
1,数据列的可空性必须相同(nullability)
【3.5】交换分区:总结
在执行分区操作时,要求源表和靶表必须满足:
表的结构相同:列的数据类型,可空性(nullability)相同;
索引结构必须相同:索引键的结构,聚集性,唯一性,列的可空性必须相同;
主键约束:如果源表存在主键约束,那么靶表必须创建等价的主键约束;
唯一约束:唯一约束可以使用唯一索引来实现;
索引键的结构:索引键的顺序,包含列,唯一性,聚集性都必须相同;
存储的数据空间(data space)相同:源表和靶表必须创建在相同的FileGroup或Partition Scheme上;
(1)时间分区
代码:现有表转成分区表
-- 创建测试数据,测试表 part_test
use test1;
if object_id('part_test' ) is not null
drop table part_test;
;with t1 as (
select 1 as id,1 as num ,cast('2021-01-01 00:01:01' as datetime) as day_info
union all
select id+1 ,num+1 ,dateadd(day,1,day_info) from t1
where id<=1000000
)
select * into part_test from t1 option(maxrecursion 0)
-- 分区函数
CREATE PARTITION FUNCTION [pf_datetime](datetime)
AS RANGE LEFT for values(
'2021-01-01' ,
'2022-01-01' ,
'2023-01-01' ,
'2024-01-01' ,
'2025-01-01' ,
'2026-01-01' ,
'2027-01-01' ,
'2028-01-01' ,
'2029-01-01' ,
'2030-01-01' ,
'2031-01-01' ,
'2032-01-01' ,
'2033-01-01' ,
'2034-01-01' ,
'2035-01-01' ,
'2036-01-01' ,
'2037-01-01' ,
'2038-01-01' ,
'2039-01-01' ,
'2040-01-01' ,
'2041-01-01' ,
'2042-01-01' ,
'2043-01-01' ,
'2044-01-01' ,
'2045-01-01' ,
'2046-01-01' ,
'2047-01-01' ,
'2048-01-01'
);
-- 分区架构
CREATE PARTITION SCHEME [ps_datetime]
AS PARTITION [pf_datetime]
ALL TO ([PRIMARY])
-- 创建聚集索引和耳机索引
create clustered index PIX_id on part_test(id)
create index ix_dayinfo on part_test(day_info)
-- 查看是否还有二级索引
-- sp_help part_test
-- 删掉二级索引,重建聚集索引并应用分区架构
drop index ix_dayinfo on part_test
-- 重建聚集索引=》现有表改成分区表,分区列必须是在主键内,比如这里的 day_info 就必须在主键内
create clustered index PIX_id
on dbo.part_test(ID,day_info)
with(drop_existing=on)
on [ps_datetime](day_info)
--创建索引对齐分区索引
create index id_p_num on part_test(num) on [ps_datetime](day_info)
create index id_p_dayinfo on part_test(day_info) on [ps_datetime](day_info)
select * from part_test where day_info='2021-01-11 00:01:01.000'
-- 拆分分区(最末尾)
-- 在分区函数中新增一个边界值,即可将一个分区变为2个。一般边界值默认是 left ;放到最前或者最后来拆分就是新增分区
alter partition function pf_datetime()
split range('2049-01-01') --将第二个分区拆为2个分区
-- 归档到历史表
alter table bigorder switch partition 1 to <同表结构、默认值、null约束一致的表>
![[云原生1. ] 使用Docker-compose一键部署Wordpress平台](https://img-blog.csdnimg.cn/75405d5f98484c3283b0807db26530d6.png)