一、AST 抽象语法树
执行一条简单的 SQL 语句 SELECT avg(b) FROM NATION GROUP BY b。NATION 是一张小表,只有 25 条记录;对第 2 列 b 进行取平均值的聚集操作。上述示例中的 SQL 语句经过分析器解析后得到 AST,如下图所示。
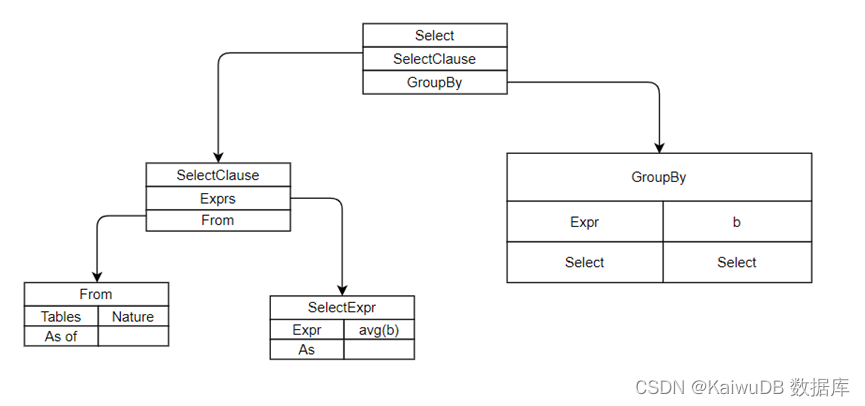
二、逻辑计划
将 AST 转换成一个树状结构的 Plan,称之为逻辑查询计划。抽象语法树中的每一个语法元素都被转换成一个查询逻辑单元,例如 scanNode, sortNode, groupNode 等。
例子中的逻辑计划很简单,就是扫描节点(Scan) 和聚集(Group By)。命令 EXPLAIN SELECT avg(b) FROM NATURE GROUP BY b;显示如下:

三、物理计划
(DistSQLPlanner).PlanAndRun 方法把逻辑计划转换为物理计划,其中递归调用 createPlanForNode 方法生成各个物理算子,交给执行器具体执行。生成物理计划过程是 KaiwuDB 根据底层 KV 数据的分布和预估返回数据集的大小,决定是否需要生成分布式执行计划,该例子为本地执行的物理计划。
在(DistSQLPlanner).PlanAndRun 方法中,逻辑计划会被转换为物理计划,并通过递归调用 createPlanForNode 方法生成各个物理算子,这些算子会被交给执行器具体执行;KaiwuDB 根据底层 KV 数据的分布和预估返回数据集的大小,决定是否需要生成分布式执行计划。
逻辑计划节点和物理计划节点并不是一一对应关系,但是这个例子中,逻辑计划中的 Scan 和 Group 分别对应物理计划中的 TableReader 算子和聚集算子。

四、执行
最后调用 (DistSQLPlanner).Run 方法执行物理计划。执行引擎采用火山模型(Volcano),每一层执行算子通过调用下一层的 Next 方法获取一条记录。
聚集分为两种情况,具体执行过程如下:
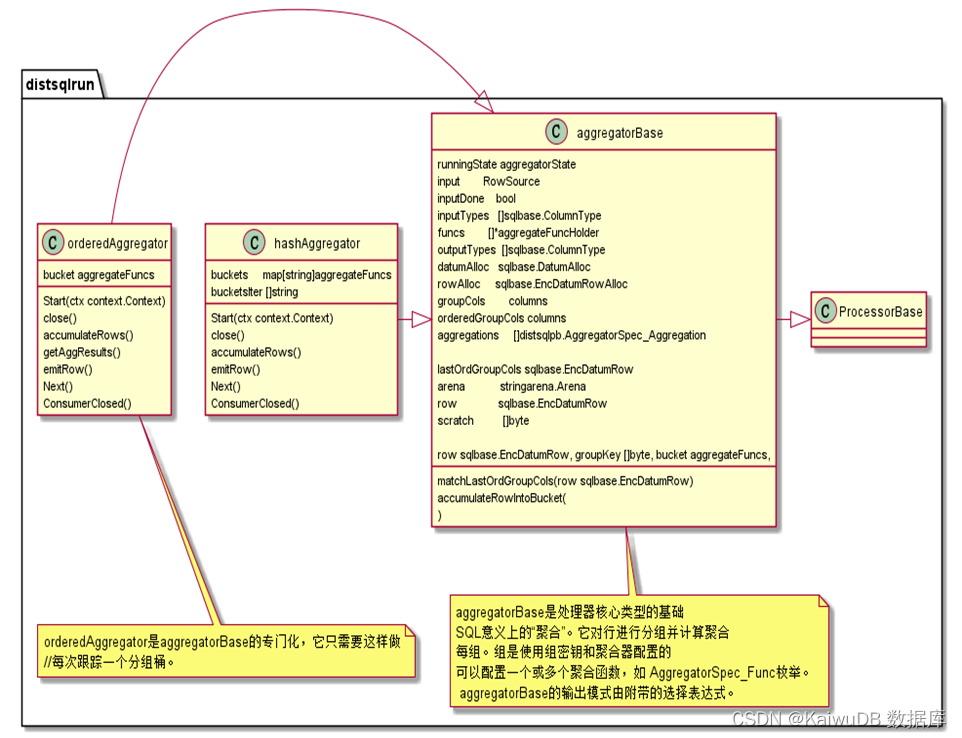
(1)HashAggregater
在 Hash Aggregate 的计算过程中,我们需要维护一个 Hash 表,Hash 表的键为聚合计算的 Group-By 列,若以平均数函数 avg 为例,值为聚合函数的中间结果 sum 和 count。在 Group-By 列 a,求 avg(b) 的例子中,求键为 Group-By 列 b 的值,即 sum(b) 和 count(b)。
计算过程中,只需要根据每行输入数据计算出键,在 Hash 表中找到对应值进行更新即可。
// Next is part of the RowSource interface.
func (ag *hashAggregator) Next() (sqlbase.EncDatumRow, *distsqlpb.ProducerMetadata) {for ag.State == runbase.StateRunning {var row sqlbase.EncDatumRowvar meta *distsqlpb.ProducerMetadataswitch ag.runningState {case aggAccumulating:ag.runningState, row, meta = ag.accumulateRows()case aggEmittingRows:ag.runningState, row, meta = ag.emitRow()default:log.Fatalf(ag.Ctx, "unsupported state: %d", ag.runningState)}if row == nil && meta == nil {continue}return row, meta}return nil, ag.DrainHelper()
}
其中 ag.runningState 为 aggAccumulating:是数据还没有读取完毕,没有算出最终的 agg 结果时的状态,当所有的数据读取完毕后将状态设置为 aggEmittingRows 输出结果。上面的计划就是一个典型的 Hashagg 的例子的逻辑计划。
(2)OrderAggregator 算子
OrderAggregate 的计算需要保证输入数据按照 Group-By 列有序。在计算过程中,每当读到一个新的 Group 的值或所有数据输入完成时,便对前一个 Group 的聚合最终结果进行计算。因为 OrderAggregate 的输入数据需要保证同一个 Group 的数据连续输入,所以 Stream Aggregate 处理完一个 Group 的数据后可以立刻向上返回结果,不用像 HashAggregate 一样需要处理完所有数据后才能正确的对外返回结果。
当上层算子只需要计算部分结果时,比如 Limit,当获取到需要的行数后,可以提前中断 OrderAggregate 后续的无用计算。当 Group-By 列上存在索引时,由索引读入数据可以保证输入数据按照 Group-By 列有序,此时同一个 Group 的数据连续输入 OrderAggregate 算子,可以避免额外的排序操作。如果想要走 Orderagg 则需要将 groupby 列建立索引:create index on nature(b),即可看到计划的转变。

以下是 Hashagg 和 Orderagg 聚集方法类图:
五、优化方法
为了提高聚集算子的执行效率,KaiwuDB 提出了如下两种并行聚焦方法:
(1)HashAggregater 并行
HashAggregater 并行的设计思路是并行计算后,将计算后的结果根据计算时产生的中间统计信息直接汇总 Hash,进行 finalworkers 的汇总。HashAggExec 处理所有聚合函数,根据 Aggragator 计划建造,调用 Next()时,从 Src 读取所有数据并更新 partialagfuncs 中的所有项,直到所有 gorutinee 完成。
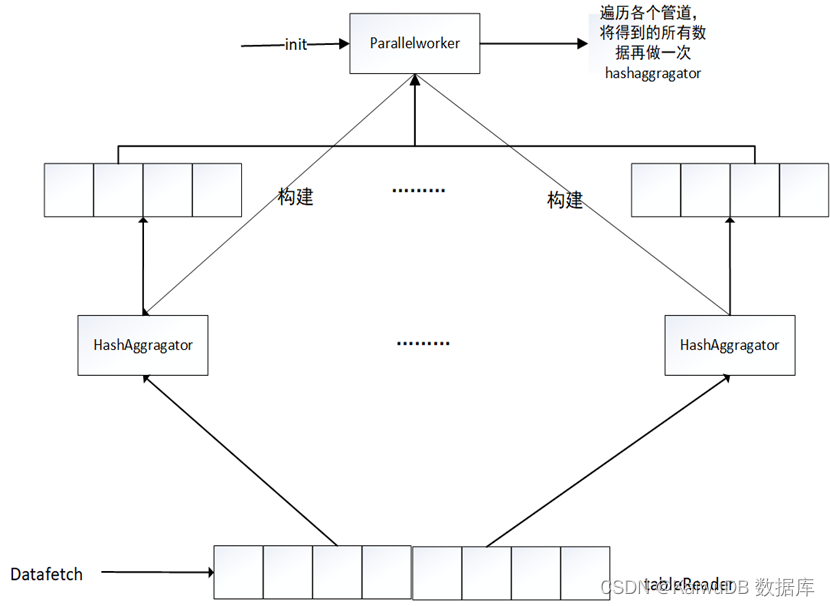
具体修改思路为在上层 Processor 构建一个 Parallelworker 算子(原来 newAggregator 的地方),让它去构建 newAggregator ,即并行计算的 HashAggregator 子算子,构建几个依据设定好的并发度来构建,让构建好的 newAggregator 取 tablereader 的块去读去算,算好的结果不发送,而是传入管道中。最上层的 Parallelworker 算子遍历各个管道,将得到的所有数据再做一次 HashAggragator。最后再将所有结果发送。
(2)OrderAggregator 算子并行
OrderAggregater 并行的总体设计思路与 HashAggregator 基本相同。但因 OrderAggregator 已经有序,所以分发数据时需要分块按序分配给子算子。将计算后的结果根据计算时产生的中间统计信息直接汇总 Hash,按分配块的顺序直接进行 finalworkers 的汇总。其他部分与 HashAggregator 相同,最后再将所有结果发送。
下图是以 HashAggregator 为例的并行运算流程图: